AWS Big Data Blog

Joulica unifies real-time and historical customer experience analytics with Amazon QuickSight
This is a guest post by Tony McCormack from Joulica. Joulica is an Ireland-based startup in the contact center industry. Our founders previously led contact center research and development for a global contact center technology provider, and we founded Joulica because we saw that the shift to the cloud and growing demand for data and […]

AWS Glue streaming application to process Amazon MSK data using AWS Glue Schema Registry
Organizations across the world are increasingly relying on streaming data, and there is a growing need for real-time data analytics, considering the growing velocity and volume of data being collected. This data can come from a diverse range of sources, including Internet of Things (IoT) devices, user applications, and logging and telemetry information from applications, […]
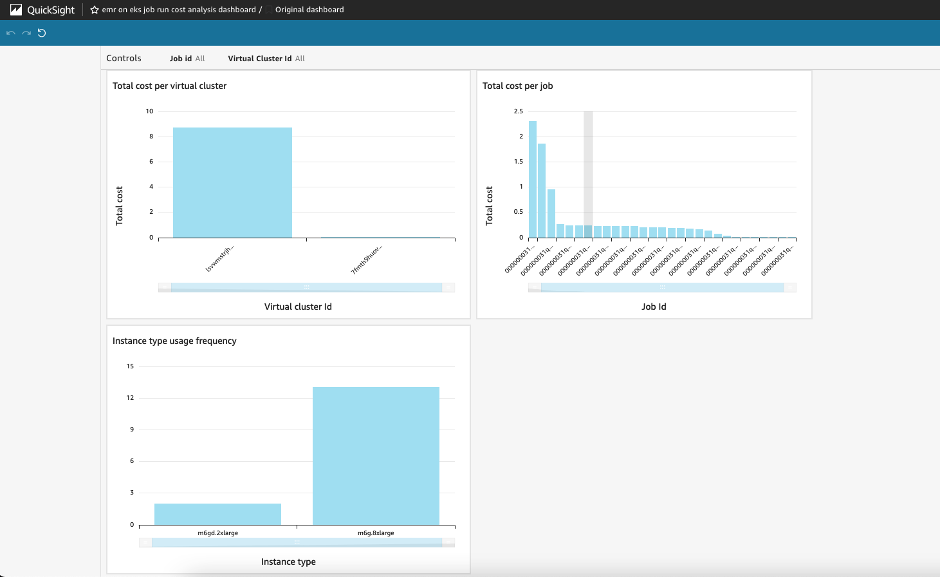
Cost monitoring for Amazon EMR on Amazon EKS
Amazon EMR is the industry-leading cloud big data solution, providing a collection of open-source frameworks such as Spark, Hive, Hudi, and Presto, fully managed and with per-second billing. Amazon EMR on Amazon EKS is a deployment option allowing you to deploy Amazon EMR on the same Amazon Elastic Kubernetes Service (Amazon EKS) clusters that is […]

Choosing an open table format for your transactional data lake on AWS
August 2023: This post was updated to include Apache Iceberg support in Amazon Redshift. Disclaimer: Due to rapid advancements in AWS service support for open table formats, recent developments might not yet be reflected in this post. For the latest information on AWS service support for open table formats, refer to the official AWS service […]

Implement alerts in Amazon OpenSearch Service with PagerDuty
In today’s fast-paced digital world, businesses rely heavily on their data to make informed decisions. This data is often stored and analyzed using various tools, such as Amazon OpenSearch Service, a powerful search and analytics service offered by AWS. OpenSearch Service provides real-time insights into your data to support use cases like interactive log analytics, […]

Automate and accelerate your Amazon QuickSight asset deployments using the new APIs
Business intelligence (BI) and IT operations (BIOps) teams often need to automate and accelerate the deployment of BI assets to ensure business continuity. We heard that you wanted an automated and scalable way to deploy, back up, and replicate Amazon QuickSight assets at scale so that BIOps teams within your organization can work in an […]

How Cargotec uses metadata replication to enable cross-account data sharing
This is a guest blog post co-written with Sumesh M R from Cargotec and Tero Karttunen from Knowit Finland. Cargotec (Nasdaq Helsinki: CGCBV) is a Finnish company that specializes in cargo handling solutions and services. They are headquartered in Helsinki, Finland, and operates globally in over 100 countries. With its leading cargo handling solutions and […]

Introducing Amazon EMR on EKS job submission with Spark Operator and spark-submit
Amazon EMR on EKS provides a deployment option for Amazon EMR that allows organizations to run open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). With EMR on EKS, Spark applications run on the Amazon EMR runtime for Apache Spark. This performance-optimized runtime offered by Amazon EMR makes your Spark jobs run fast […]

AWS Glue Data Quality is Generally Available
We are excited to announce the General Availability of AWS Glue Data Quality. Our journey started by working backward from our customers who create, manage, and operate data lakes and data warehouses for analytics and machine learning. To make confident business decisions, the underlying data needs to be accurate and recent. Otherwise, data consumers lose […]

Visualize data quality scores and metrics generated by AWS Glue Data Quality
AWS Glue Data Quality allows you to measure and monitor the quality of data in your data repositories. It’s important for business users to be able to see quality scores and metrics to make confident business decisions and debug data quality issues. AWS Glue Data Quality generates a substantial amount of operational runtime information during […]