Artificial Intelligence
Category: AWS CloudFormation

Accelerate agentic application development with a full-stack starter template for Amazon Bedrock AgentCore
In this post, you will learn how to deploy Fullstack AgentCore Solution Template (FAST) to your Amazon Web Services (AWS) account, understand its architecture, and see how to extend it for your requirements. You will learn how to build your own agent while FAST handles authentication, infrastructure as code (IaC), deployment pipelines, and service integration.

Build AI agents with Amazon Bedrock AgentCore using AWS CloudFormation
Amazon Bedrock AgentCore services are now being supported by various IaC frameworks such as AWS Cloud Development Kit (AWS CDK), Terraform and AWS CloudFormation Templates. This integration brings the power of IaC directly to AgentCore so developers can provision, configure, and manage their AI agent infrastructure. In this post, we use CloudFormation templates to build an end-to-end application for a weather activity planner.
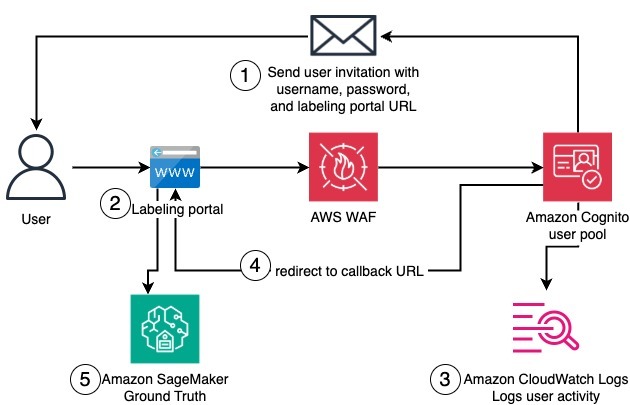
Create a private workforce on Amazon SageMaker Ground Truth with the AWS CDK
In this post, we present a complete solution for programmatically creating private workforces on Amazon SageMaker AI using the AWS Cloud Development Kit (AWS CDK), including the setup of a dedicated, fully configured Amazon Cognito user pool.

Accelerate IaC troubleshooting with Amazon Bedrock Agents
This post demonstrates how Amazon Bedrock Agents, combined with action groups and generative AI models, streamlines and accelerates the resolution of Terraform errors while maintaining compliance with environment security and operational guidelines.

Accelerate digital pathology slide annotation workflows on AWS using H-optimus-0
In this post, we demonstrate how to use H-optimus-0 for two common digital pathology tasks: patch-level analysis for detailed tissue examination, and slide-level analysis for broader diagnostic assessment. Through practical examples, we show you how to adapt this FM to these specific use cases while optimizing computational resources.

Build a read-through semantic cache with Amazon OpenSearch Serverless and Amazon Bedrock
This post presents a strategy for optimizing LLM-based applications. Given the increasing need for efficient and cost-effective AI solutions, we present a serverless read-through caching blueprint that uses repeated data patterns. With this cache, developers can effectively save and access similar prompts, thereby enhancing their systems’ efficiency and response times.

Create a multimodal chatbot tailored to your unique dataset with Amazon Bedrock FMs
In this post, we show how to create a multimodal chat assistant on Amazon Web Services (AWS) using Amazon Bedrock models, where users can submit images and questions, and text responses will be sourced from a closed set of proprietary documents.

Architecture to AWS CloudFormation code using Anthropic’s Claude 3 on Amazon Bedrock
In this post, we explore some ways you can use Anthropic’s Claude 3 Sonnet’s vision capabilities to accelerate the process of moving from architecture to the prototype stage of a solution.

Build an end-to-end RAG solution using Amazon Bedrock Knowledge Bases and AWS CloudFormation
Retrieval Augmented Generation (RAG) is a state-of-the-art approach to building question answering systems that combines the strengths of retrieval and foundation models (FMs). RAG models first retrieve relevant information from a large corpus of text and then use a FM to synthesize an answer based on the retrieved information. An end-to-end RAG solution involves several […]

The Weather Company enhances MLOps with Amazon SageMaker, AWS CloudFormation, and Amazon CloudWatch
In this post, we share the story of how The Weather Company (TWCo) enhanced its MLOps platform using services such as Amazon SageMaker, AWS CloudFormation, and Amazon CloudWatch. TWCo data scientists and ML engineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively. TWCo reduced infrastructure management time by 90% while also reducing model deployment time by 20%.