Artificial Intelligence
Perform medical transcription analysis in real-time with AWS AI services and Twilio Media Streams
Medical providers often need to analyze and dictate patient phone conversations, doctors’ notes, clinical trial reports, and patient health records. By automating transcription, providers can quickly and accurately provide patients with medical conditions, medication, dosage, strength, and frequency.
Generic artificial intelligence-based transcription models can be used to transcribe voice to text. However, medical voice data often uses complex medical terms and abbreviations. Transcribing such data needs medical/healthcare-specific machine learning (ML) models. To address this issue, AWS launched Amazon Transcribe Medical, an automatic speech recognition (ASR) service that makes it easy for you to add medical speech-to-text capabilities to your voice-enabled applications.
Additionally, Amazon Comprehend Medical is a HIPAA-eligible service that helps providers extract information from unstructured medical text accurately and quickly. To transcribe voice in real time, providers need access to raw audio from the call while in-progress. Twilio, an AWS partner, offers real-time telephone voice integration.
In this post, we show you how to integrate Twilio Media Streams with Amazon Transcribe Medical and Amazon Comprehend Medical to transcribe and analyze data from phone calls. For non-healthcare industries, you can use this same solution with Amazon Transcribe and Amazon Comprehend.
Twilio Media Streams works in the context of a traditional Twilio voice application, like an Interactive Voice Response (IVR), that serves customers directly, as well as a contact center, like Twilio Flex, where agents are serving consumers. You have discrete control over your voice data within your contact center to build the experience your customers prefer.
Amazon Transcribe Medical is an ML service that makes it easy to quickly create accurate transcriptions between patients and physicians. Amazon Comprehend Medical is a natural language processing (NLP) service that makes it easy to use ML to extract relevant medical information from unstructured text. You can quickly and accurately gather information (such as medical condition, medication, dosage, strength, and frequency), from a variety of sources (like doctors’ notes, clinical trial reports, and patient health records). Amazon Comprehend Medical can also link the detected information to medical ontologies such as ICD-10-CM or RxNorm so downstream healthcare applications can use it easily.
The following diagram illustrates how Amazon Comprehend Medical supports medical named entity and relationship extractions.

Amazon Transcribe Medical, Amazon Comprehend Medical, and Twilio Media Streams are all managed platforms. This means that data scientists and healthcare IT teams don’t need to build services from the ground up. Voice integration is provided by Twilio and AWS ML services APIs, and only requires a simple plug-and-play with AWS and Twilio services to build the end-to-end workflow.
Solution overview
Our solution uses Twilio Media Streams to provide telephony service to the customer. This service provides a telephone number and backend to media services to integrate it with REST API-based web applications. In this solution, we build a Node.js web app and deploy it with AWS Amplify. Amplify helps front-end web and mobile developers build secure, scalable, full stack applications. The web app interfaces with Twilio Media Streams to receive phone calls in voice format, and uses Amazon Transcribe Medical to convert voice to text. Upon receiving the transcription, the application interfaces with Amazon Comprehend Medical to extract medical terms and insights from the transcription. The insights are displayed on the web app and stored in an Amazon DynamoDB table for further analysis. The solution also uses Amazon Simple Storage Service (Amazon S3) and an AWS Cloud9 environment.
The following diagram illustrates the solution architecture.

To implement the solution, we complete the following high-level steps:
- Create a trial Twilio account.
- Create an AWS Identity and Access Management (IAM) user.
- Create an AWS Cloud9 integrated development environment (IDE).
- Clone the GitHub repo.
- Create a secured HTTPS tunnel using ngrok and set up Twilio phone number’s voice configuration.
- Run the application.
Create a trial Twilio account
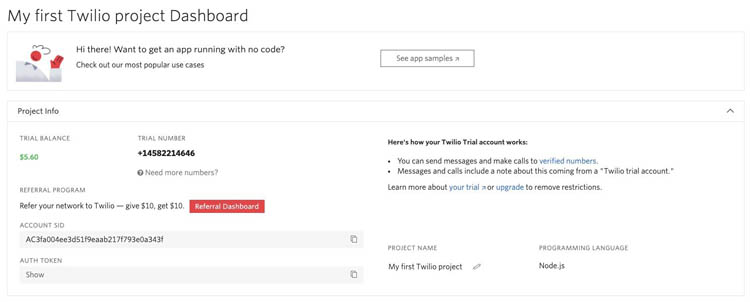
Before getting started, make sure to sign up for a trial Twilio account (https://www.twilio.com/try-twilio), if you don’t already have one.
Create an IAM user
To create an IAM user, complete the following steps:
- On the IAM console, under Access management, choose Users.
- Choose Add user.
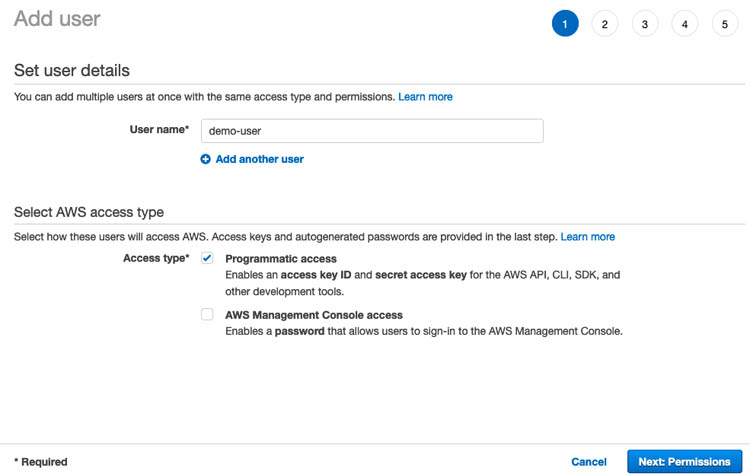
- On the Set user details page, for User name¸ enter a name.
- For Access type, select Programmatic access.
- Choose Next: Permissions.
- On the Set permissions page, choose Attach existing policies directly.
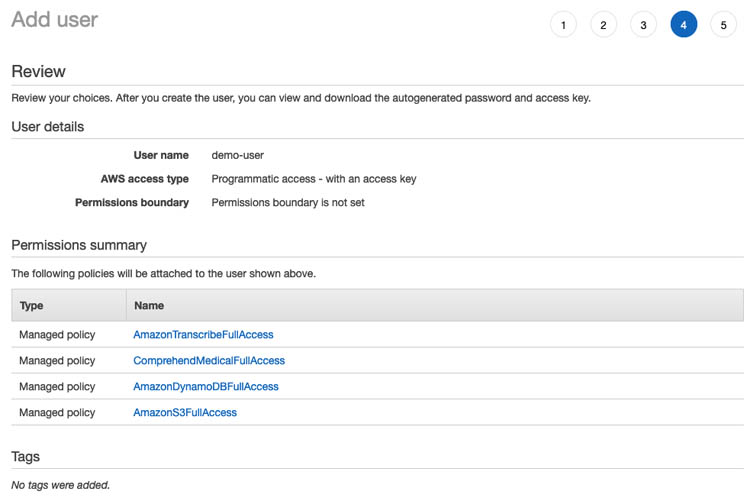
- Select the following AWS Managed Policies, AmazonTranscribeFullAccess, ComprehendMedicalFullAccess, AmazonDyanmoDBFullAccess, and AmazonS3FullAccess.
- Choose Next: Tags.
- Skip adding tags and choose Next: Review.
- Review the IAM user details and attached policies and choose Create user.
- On the next page, copy the access key ID and secret access key to your clipboard or download the CSV file.
We use these credentials for testing the Node.js application.

Create an S3 Bucket
To create your Amazon S3 Bucket, complete the following steps.
- On the Amazon S3 console, choose Create bucket.
- For Bucket name, enter a name for the Amazon S3 bucket.
- For Block Public Access settings for this bucket check Block all public access.
- Review the settings and choose Create bucket.
Create an Amazon DynamoDB Table
To create your Amazon DynamoDB table, complete the following steps.
- On the Amazon DynamoDB console, choose Create table.
- For Table name, enter a name for the Amazon DynamoDB Table.
- For Primary key, enter ROWID for the primary key.
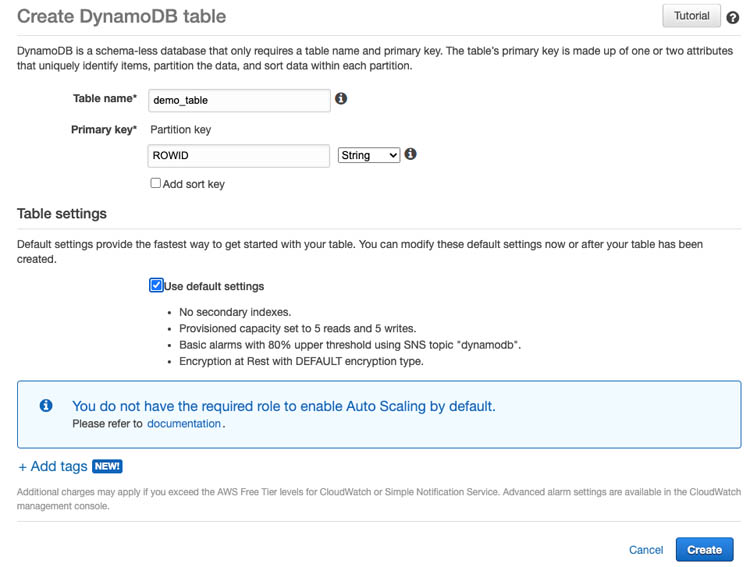
- Review the Amazon DynamoDB table settings and choose
Create an AWS Cloud9 environment
To create your AWS Cloud9 environment, complete the following steps.
- On the AWS Cloud9 console, choose Environments.
- Choose Create environment.
- For Name, enter a name for the environment.
- For Description, enter an optional description.
- Choose Next step.

- On the Configure Settings page, select Ubuntu Server 18.04 LTS for Platform and leave the other settings as default.

- Review the settings and choose Create environment.
The AWS Cloud9 IDE tab opens on your browser; you may have to wait a few minutes for the environment creation process to complete.

Clone the GitHub repo
In the AWS Cloud9 environment, close the Welcome and AWS Toolkit – QuickStart tabs. To clone the GitHub repository, on the bash terminal, enter the following code:
Edit the config.json file under the project directory. Replace the values with your Amazon S3 Bucket and Amazon DynamoDB table.
Set up ngrok and the Twilio phone number
Before we start the Node.js application, we need to start a secured HTTPS tunnel using ngrok and set up the Twilio phone number’s voice configuration.
- On the terminal, choose the +
- Choose New Terminal.

- On the terminal, install ngrok:
- After ngrok is installed, run the following code to expose the local Express Node.js server to the internet:
- Copy the public HTTPS URL.
You use this URL for the Twilio phone number’s voice configuration.

- Sign in to your Twilio account.
- On the dashboard, choose the … icon to open the Settings

- Choose Phone Numbers.

- On the Phone Numbers page, choose your Twilio phone number.

- In the Voice section, for A Call Comes In, choose Webhook.
- Enter the ngrok tunnel followed by
/twiml. - Save the configuration.

Run the application
Let’s now run the Twilio Media Streams, Amazon Transcribe Medical, and Amazon Comprehend Medical services by entering the following code:

We can preview the application in AWS Cloud9. In the environment, on the Preview menu, choose Preview Running Application.
You can copy the public URL to view the application in another browser tab.
Enter the IAM user access ID and secret key credentials, and your Twilio account SID, auth token, and phone number.

Demonstration
In this section, we use two sample recordings to demonstrate real-time audio transcription with Twilio Media Streams.
After you enter your IAM and Twilio credentials, choose Submit Credentials.
![]()
The following screenshot shows the transcription for our first audio file, sample-1.mp4.
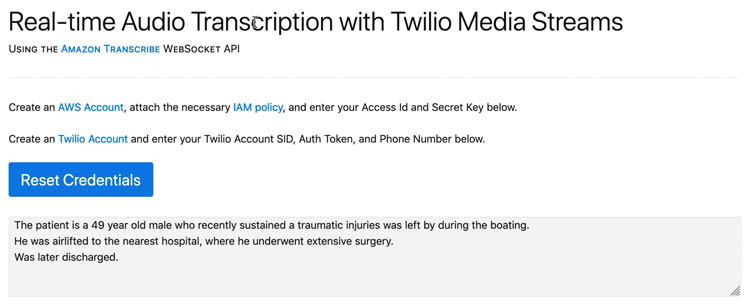
The following screenshot shows the transcription for our second file, sample-3.mp4.

This application uses Amazon Transcribe Medical to transcribe media content in real time, and stores the output in Amazon S3 for further analysis. The application then uses Amazon Comprehend Medical to detect the following entities:
- ANATOMY – Detects references to the parts of the body or body systems and the locations of those parts or systems
- MEDICAL_CONDITION – Detects the signs, symptoms, and diagnosis of medical conditions
- MEDICATION – Detects medication and dosage information for the patient
- PROTECTED_HEALTH_INFORMATION – Detects the patient’s personal information
- TEST_TREATMENT_PROCEDURE – Detects the procedures that are used to determine a medical condition
- TIME_EXPRESSION – Detects entities related to time when they are associated with a detected entity
These entities are stored in the DynamoDB table. Healthcare providers can use this data to create patient diagnosis and treatment plan.

You can further analyze this data through services such as Amazon OpenSearch Service and Amazon Kendra.
Clean up your resources
The AWS services used in this solution are part of the AWS Free Tier. If you’re not using the Free Tier, clean up the following resources to avoid incurring additional charges:
- AWS Cloud9 environment
- Amazon S3 Bucket
- Amazon DynamoDB Table
- IAM user
Conclusion
In this post, we showed how to integrate Twilio Media Streams with Amazon Transcribe Medical and Amazon Comprehend Medical to transcribe and analyze medical data from audio files. You can also use this solution in non-healthcare industries to transcribe information from audio.
We invite you to check out the code in the GitHub repo and try out the solution, and even expand on the data analysis with Amazon ES or Amazon Kendra.
About the Author
 Mahendra Bairagi is a Principal Machine Learning Prototyping Architect at Amazon Web Services. He helps customers build machine learning solutions on AWS. He has extensive experience on ML, Robotics, IoT and Analytics services. Prior to joining Amazon Web Services, he had long tenure as entrepreneur, enterprise architect and software developer.
Mahendra Bairagi is a Principal Machine Learning Prototyping Architect at Amazon Web Services. He helps customers build machine learning solutions on AWS. He has extensive experience on ML, Robotics, IoT and Analytics services. Prior to joining Amazon Web Services, he had long tenure as entrepreneur, enterprise architect and software developer.
 Jay Park is a Prototyping Solutions Architect for AWS. Jay is focused on helping AWS customers speed their adoption of cloud-native workloads through rapid prototyping
Jay Park is a Prototyping Solutions Architect for AWS. Jay is focused on helping AWS customers speed their adoption of cloud-native workloads through rapid prototyping