AWS Public Sector Blog
Enabling data sharing through data spaces and AWS

Many Amazon Web Services (AWS) customers are adopting modern data architectures and deploying data lakes to break down data silos within their own organizations. However, many organizations remain siloed within their industries or sectors.
Data spaces can help break down these data silos. Data spaces facilitate a decentralized and secure data exchange across organizations and industries that come together to pool, access, process, and share data. They enable simple, secure, open standards-based, and interoperable data-sharing, while allowing for organizations to maintain full control over their data.
In this blog post, learn how data spaces support simple and secure data-sharing between organizations and sectors, current data space initiatives in Europe and beyond, and how to leverage a data space with AWS.
Data spaces explained
Due to the ever-growing need for inter-organizational data sharing in many areas, such as mobility, smart city, energy, healthcare, research, commercial industry, and more, the need for an interoperable solution for data sharing has emerged. Data spaces help overcome the problem of inter-organizational data integration across heterogeneous technology stacks, environments, and geographies. They reduce the effort of connecting the data while adhering to the rules and policies (i.e., contracts) data providers set on the data they decide to share.
Data spaces are characterized by their participants and their respective roles:
- Data providers, who offer their data to the market.
- Data consumers, who retrieve data from external parties and incorporate them with their own.
- Operators, which are the company or entity that brokers services, such as the data catalog, for data providers to upload a definition of their data assets, and data consumers to look for the data they would like to access and utilize.
All data is registered with the data space (or rather, the data space catalog), but is provided to data space participants in a decentralized way. This means that there is no single platform provider and the data remains at the source where each data provider decides to host it rather than being moved to a large central database.
Data spaces are designed for data control and trusted data sharing. This conceptual design states that data should remain under the control of the data provider who decides, through enforceable contracts attached to their data offerings, who has access to it, for what purpose, and under which conditions their data can be utilized. For example, an EU member state government agency might choose not to share portions of a data asset with other member states, but they would want to share it in full with local agencies within their own member state. Different data consumers are part of the same data space but have different access rights.
Finally, a key aspect of data spaces is the fact that they offer support for an interoperable IT environment for data sharing, allowing for data portability regardless of the platform on which it is hosted or consumed.
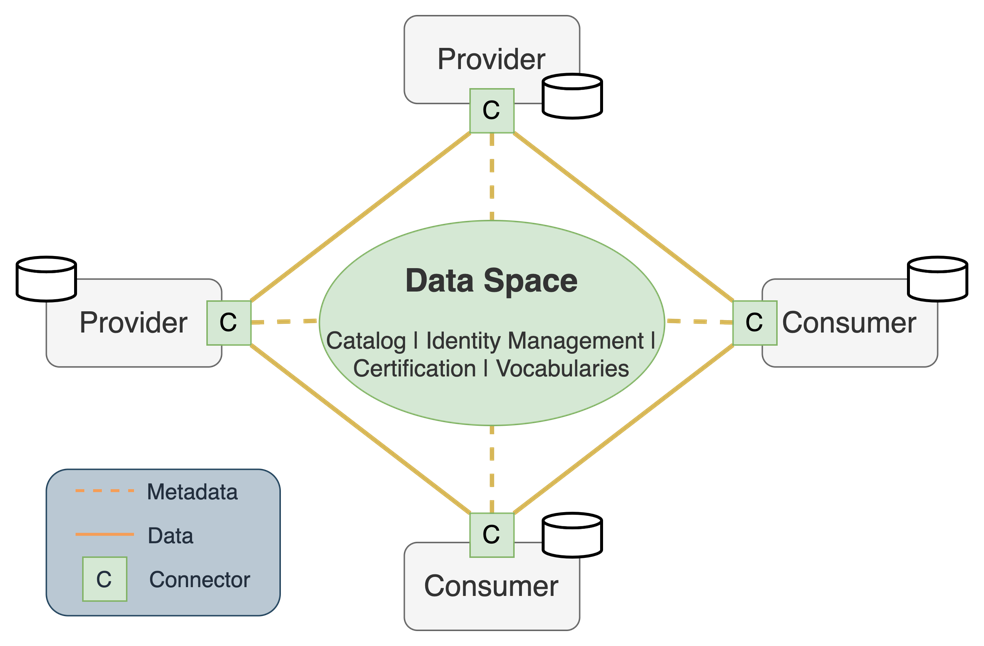
Figure 1. The data space conceptual architecture.
The key technical component in every data space is the connector. The connector component provides capabilities to finely adjust how the data is shared. The connector negotiates contracts and enforces the rules set by data space participants. It also manages the process of transferring data using existing data protocols and APIs like Java Database Connectivity (JDBC), Amazon Simple Storage Service (Amazon S3), HTTP(S), and more. The supported data protocols can be extended to other data sources and targets as required within the data space.
Other components in a data space are the shared services, and this is where the data space operator(s) come into play. Services such as identity management, catalog, and registration/validation can be either managed in a centralized or decentralized manner in each data space. It is up to the data space operating company (OpCo) to decide which approach is more appropriate from an effort, control, and requirements perspective. The OpCo is usually a consortium of organizations that participate in and operate the data space’s shared services, such as registration, validation, catalog, and identity management.
If needed, other shared services can be added to the stack, such as data anonymization, personal identifiable information (PII) obfuscation, or data asset monetization.
Global initiatives for data spaces
Gaia-X is an initiative that aims to bring together representatives from business, science, and politics in Europe to help define requirements for the next generation of data infrastructure, which includes an open, transparent, and secure digital ecosystem in which data and services can be made available, collated, and shared in an environment of trust.
AWS is a day-1 member of the Gaia-X association, actively supporting the initiative and involved in multiple Gaia-X working groups. AWS joined Gaia-X to help European customers and partners accelerate cloud-driven innovation in Europe in a secure and federated digital ecosystem that fosters openness and transparency. You can learn more about this initiative in Gaia-X publications.
During the Gaia-X Summit held in November 2022, AWS announced the inclusion of 52 services in the Gaia-X demonstrator service catalogue. This helps AWS customers and partners know that they can use AWS services to support their data-sharing projects while meeting applicable security, privacy, and interoperability needs.
The International Data Spaces Association (IDSA) is a coalition of more than 130 member companies that share a vision of a world in which all companies self-determine usage rules and realize the full value of their data in secure, trusted, and equal collaborations. They aim to develop a reference architecture for international data spaces (IDS), including a governance model and adoption strategy. IDSA is also a day-1 member of, and contributes its knowledge to, Gaia-X. Among the IDSA publications, you can find reports about the available data space connectors based on the IDSA standards and an overview of the existing data spaces projects.
One of the most progressed global data space projects is Catena-X. Catena-X is the first collaborative, open data ecosystem for the automotive industry, linking global players into end-to-end value chains. AWS has joined the ecosystem at the beginning of 2023, to increase the pace of industry innovation while simultaneously working to solve challenges from supply chain, to warranty, sustainability, and more. AWS will use the experience from this engagement to serve customers and partners from commercial and public sectors.
Technical overview of data spaces and the connector component
Data spaces sit in-between the infrastructure (e.g., data stores), and the application or service platforms (e.g., data analytics, business intelligence, and machine learning applications).

Figure 2. Components involved in the data exchange process. Image credit to dataspace components.
Some of the core components of a data space include the following.
- Connector: Connects the participant to a data space and its shared services.
- Registration service: A shared service to register and validate new participants.
- Identity provider: Shared service to provide control for access and authorization.
- Catalog: Shared service to register new and review the existing offerings and data assets.
- Policy engine: Manages contracts between parties before exchanging data and enforces the policies that have been agreed upon as part of the negotiation.
Data spaces are based on a flexible and decentralized architecture. The data stays with the producers alongside the connector which provides the technical capability to connect the producer and a consumer of the data.
A data-sharing system requires a protocol implementation to connect different participants and orchestrate the flow of data, all while enforcing the data usage policies agreed among participants.
Different initiatives for data spaces connectors components are developing, some of them open source. The IDSA has compiled a report on data space connectors. Many of them are compatible with IDSA guidelines and strive for interoperability, which is a welcomed feature in the data spaces community.
One of the most visible projects is the Eclipse Dataspace Components (EDC), an open-source project hosted by the Eclipse Foundation which is actively developed by several organizations with additional support and contributions from the community.
EDC aims to provide a scalable and extensible architecture that will implement the IDS standard as well as relevant protocols and requirements associated with the Gaia-X project and thereby provide implementation and feedback to these initiatives. The connector is extensible so that it can support alternative protocols and accommodate different underlying hosting and data storage infrastructure services. At the same time, the EDC connector takes care of the communication among data space participants, irrespective of the infrastructure it is hosted on.
AWS is an official contributor to the EDC Connector GitHub repository. AWS’s involvement in the EDC development comes in response to requests from AWS customers who are already building or participating in data spaces that will use EDC. AWS can help extend EDC functionality to fulfill each data space’s goal where appropriate.
AWS for data spaces
In the context of data spaces, AWS aims for a simple-to-use integration between the connecting technology required to participate in a data space and AWS services, enabling customers to share data in a standardized manner while providing them with the services and tools to make the most of their own data, as well as third-party data. Data spaces address the discovery and transfer of data assets based on agreements between the participants of a data exchange; the underlying AWS infrastructure enables participants to run the required data space connector in a secure, scalable, and reliable way, but also provides services to support consuming and analyzing the data after transfer.
The extensible nature of many data space connectors makes it simple for different parties to develop extensions and integrations that can use the capabilities AWS offers to provide a secure, scalable, and cost-effective infrastructure to make the most of their data assets.
The role of AWS in data spaces is that of the trusted infrastructure and data services provider, contributing with the building blocks for customers to create, manage, and use data spaces.
There is further value in using AWS for the processing of the data shared through a data space. For example, you can use services like AWS Glue, Amazon Athena, and Amazon QuickSight to process and understand data. Amazon SageMaker enables machine learning (ML) capabilities and data exploration. Also, AWS makes it simple to use security services to keep the data encrypted, as well as provide fine-grained access control while constantly monitoring the activity of the exchange process. Customers can control their data and the access to it by using services including AWS Identity and Access Management (IAM), AWS Key Management Service (AWS KMS) for data encryption key management, AWS Lake Formation to build secure data lakes, and AWS Control Tower for governance of multi-account environments.
Figure 3 depicts a high-level reference architecture displaying the interaction of data space connectors across organizational boundaries and the usage of native AWS services for analytics and ML.

Figure 3. Data space connectors on AWS combined with storage, analytics, and AI and ML managed services.
In this reference architecture, the data space connector is deployed on docker containers and may use different orchestration technologies like Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS) to deploy these containers on top of a serverless compute engine such as AWS Fargate. For data sources and data targets, in this case, Figure 3 shows a combination of Amazon S3 and Amazon Relational Database Service (Amazon RDS).
AWS analytics and ML services can provide additional value in processing and analyzing the data needed by the business. With AWS Glue DataBrew, you can extract, load, and transform (ETL) the data without coding skills. The processed data can be later be used to generate business intelligence dashboards using Amazon QuickSight. With Amazon SageMaker, you can run predictive analysis by training models on a larger set of combined data from the data space. By having access to more data with potentially additional variables and features, ML models can be more accurate and developed more quickly.
All these components can be run on serverless, Amazon Elastic Compute Cloud (Amazon EC2) on-demand, or spot compute infrastructure, which can offer virtually unlimited compute capacity. Plus, customers inherit comprehensive compliance controls; AWS supports 98 security standards and compliance certifications, more than any other offering, including PCI-DSS, HIPAA/HITECH, FedRAMP, GDPR, FIPS 140-2, and NIST 800-171, helping satisfy compliance requirements for virtually every regulatory agency around the globe.
For the interaction across all the services described that require network connectivity, the traffic can be made private using Amazon Virtual Private Cloud (Amazon VPC). Amazon VPC provides a logically isolated virtual network, with only the specific services that need to be published made accessible via Elastic Load Balancing.
Conclusion
Data spaces can help support the public and private sector in innovating faster by breaking down data silos across organizations and industries, while supporting secure and protected data exchange. Many initiatives in Europe and beyond are bringing together government, research, and business organizations to support open standards-based data spaces around the world. These organizations can use AWS for not only connecting to and storing data from data spaces, but also integrating this data with analytics, ML, and business intelligence services to put this data into action – all while supporting data security.
Learn more about AWS’s participation in the Gaia-X initiative. Plus, at the latest AWS re:Invent, AWS announced the AWS Digital Sovereignty Pledge, which is a commitment to help customers meet their digital sovereignty requirements. Learn more about the AWS Digital Sovereignty Pledge here.
Are you curious to learn more about how you can work with data spaces with AWS? Reach out to your account representative, or start a conversation with us today.
Read related stories on the AWS Public Sector Blog:
- How researchers can meet new open data policies for federally-funded research with AWS
- Using big data to help governments make better policy decisions
- How Fred Hutch unlocks siloed data with AWS and open-source software
- Designing an educational big data analysis architecture with AWS
Subscribe to the AWS Public Sector Blog newsletter to get the latest in AWS tools, solutions, and innovations from the public sector delivered to your inbox, or contact us.
Please take a few minutes to share insights regarding your experience with the AWS Public Sector Blog in this survey, and we’ll use feedback from the survey to create more content aligned with the preferences of our readers.