Amazon Web Services ブログ
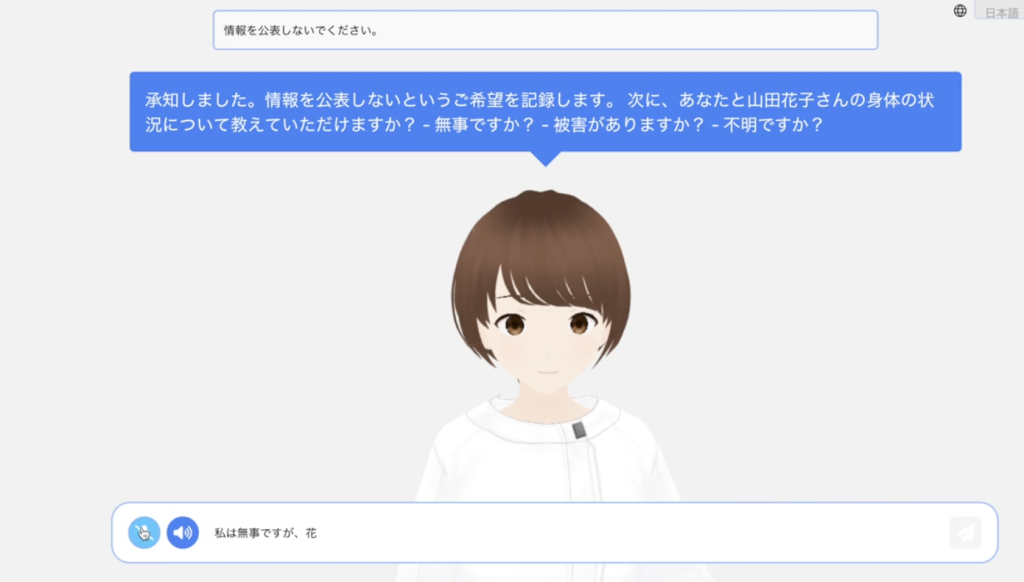
[AWS Summit Japan 2025] 生成 AI を用いた自治体向けソリューションデモのご紹介
自治体においては、労働人口減少に伴い職員数の確保が難しくなっていることや住民へのインターネットの普及率の向上か […]

株式会社情報戦略テクノロジー様の AWS 生成 AI 活用事例 : Amazon Bedrock を活用し社員一人ひとりに寄り添いともに成長するAIエージェント秘書「パイオにゃん」 を開発。情報探索業務を83%改善、社員の成長の可視化を実現。
本ブログは株式会社情報戦略テクノロジー様とAmazon Web Services Japan 合同会社が共同で […]

第一三共、AWSと連携しAIエージェント統合型創薬基盤の構築を開始 ー AI・クラウド・実験自動化技術の融合で次世代創薬研究プロセスを実現
第一三共株式会社(以下、第一三共)はAWSとの連携を強化し、AIエージェントシステムを統合した創薬研究基盤の構 […]

日本のヘルスケア・ライフサイエンス業界における戦略的ビジョン「Journey for 2030 データがつながる、価値を生む」を発表
データの分断を超えて、革新的な患者体験へ ヘルスケア・ライフサイエンス業界はセキュリティが極めて重要な業界であ […]

治せない未来を変えるために——日本の医療を支えるすべてのBuilderたちへ
「先生、この薬は本当に使えないのですか?」 40代の母親がそう尋ねたとき、主治医は言葉を失いました。 効果があ […]

ヘルスケア・ライフサイエンスの意思決定と業務の高度化を実現する HealthData x Agent を発表
ヘルスケア・ライフサイエンス業界では、患者ケアの質の向上とイノベーションの加速が強く求められています。一方で、 […]

Amazon Connect アップデート まとめ – 2025年9月
こんにちは、Amazon Connect ソリューションアーキテクトの坂田です。ようやく過ごしやすい季節になっ […]
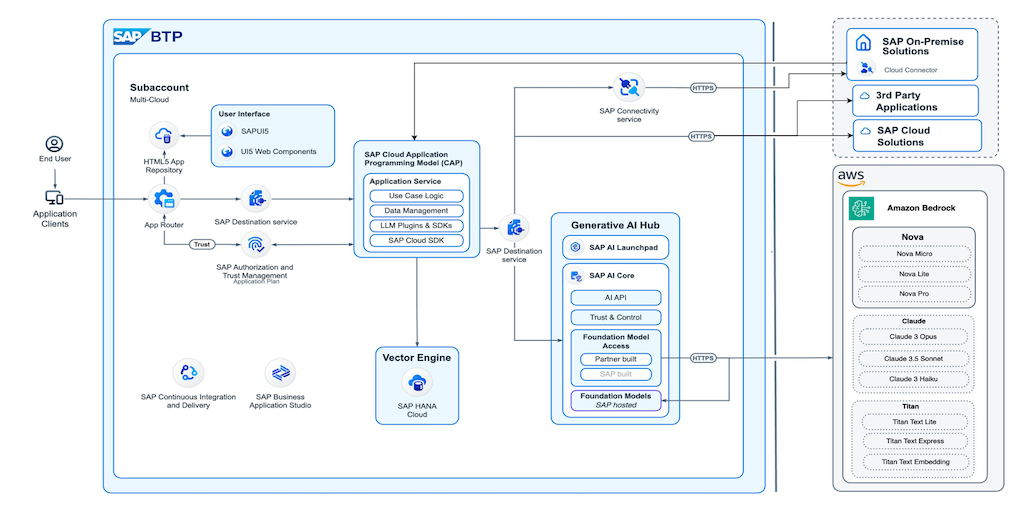
生成AIで起こるSAP技術文書変革:Amazon BedrockでSAP Notesのナレッジ生成を加速
SAP for MeチームはAWSとパートナーシップを組みました。Amazon Bedrockを使用して、SAP NotesとKBAのAI生成要約を特徴とするモバイルアプリの新バージョンを開発しました。この革新により、ユーザーは簡潔で自動生成された要約を通じて技術文書を迅速にナビゲートし、理解できるようになります。
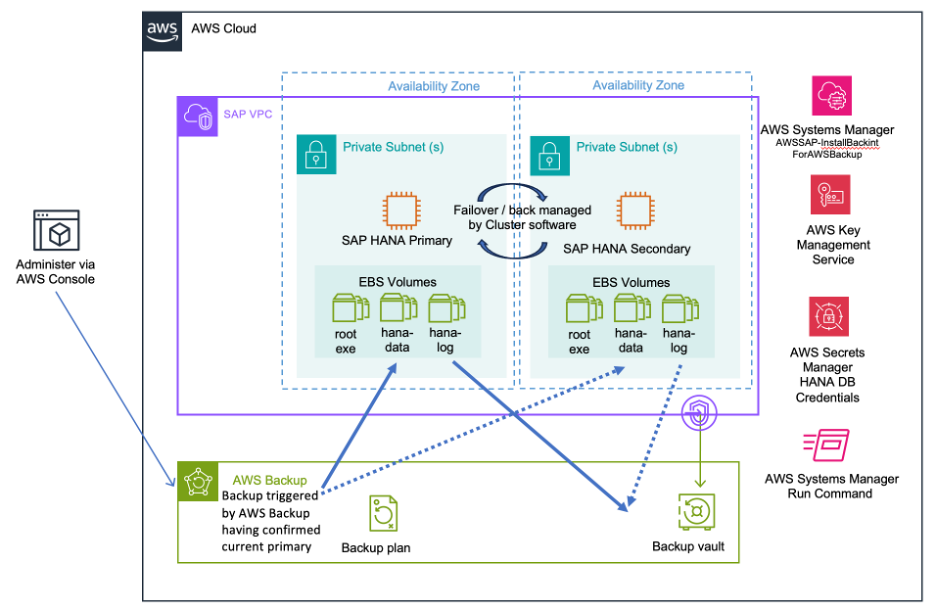
Amazon Backup for SAP HANA により SAP HANA 高可用性構成のレジリエンスとデータ保護を強化
このブログでは、組織がHAデプロイでAWS BackupによるSAP HANAデータベースの堅牢なバックアップ戦略をどのように実装しているかについて学習します。このブログでは、データ保護とWell-Architected Framework SAP Lensの信頼性の柱と運用のベストプラクティスについても説明します。

Dell および HPE との AWS Outposts サードパーティーストレージ統合の発表
画期的なパフォーマンスとスケーラビリティを備えた第 2 世代 AWS Outposts ラックを 4 月に発表 […]