Category: re:Invent
AWS CodeBuild – 완전 관리형 빌드 서비스 출시
모든 개발자는 소스 코드 변경이 일어날 때, 지속적인 통합 빌드(build) 생성 및 테스트를 실행하기 위해 공유 빌드 서버를 설정하고 운영 해야합니다. 유지 관리에 대한 부담으로 인해 다수 개발자들이 로컬 컴퓨터에서만 빌드를 만들어, 정식 서버에서 실행함으로서 한 명의 개발자에게는 동작하는데 다른 개발자에게는 동작하지 않는 상황을 초래합니다. 많은 개발 팀은 지속적 통합(Continuous Integration, CI) 및 배포 (Continuous Deployment, CD) 파이프 라인의 일부를 사용할 수 있습니다. 이러한 빌드팜의 설치 및 유지 보수 비용은 여전히 높으며 전혀 다른 운영 기술이 필요합니다. 사용률이 100%에 도달하고 빌드 요청 백 로그가 증가하는 경우를 제외하고는 가볍게 사용합니다.
AWS CodeBuild 서비스 소개
 오늘 이러한 문제를 해결 해줄 AWS CodeBuild를 출시합니다. 빌드 서버를 설치, 설정 및 확장 및 패치 등에 신경쓰지 않고, CodeBuild를 활용하여 개발 과정에서 유연상을 보장하고 여러 형태의 빌드 상태나 호환성의 불일치 문제를 해결할 수 있습니다.
오늘 이러한 문제를 해결 해줄 AWS CodeBuild를 출시합니다. 빌드 서버를 설치, 설정 및 확장 및 패치 등에 신경쓰지 않고, CodeBuild를 활용하여 개발 과정에서 유연상을 보장하고 여러 형태의 빌드 상태나 호환성의 불일치 문제를 해결할 수 있습니다.
CodeBuild를 사용 하면, 사전에 빌드 서버를 프로비저닝 할 필요가 없으며, 대기중인 빌드를 쌓아 두는 대신에 빌드 볼륨을 활용할 수 있도록 자동으로 확장됩니다. 분당 $0.005부터 시작하는 가격으로 분당 기준으로 빌드 리소스에 비용을 지불하기 때문에 사용한 시간만 비용을 지불합니다.
CodeBuild는 완전 관리형 빌드 서비스로서, 탄력성과 확장 가능하며 사용하기 쉽습니다. 처음 빌드 서비스를 시작하려면 빌드를 수행하는 데 필요한 정보가 들어있는 빌드 프로젝트를 만들기만 하면 됩니다 빌드 프로젝트에 다음 요소가 포함됩니다.
- 소스 레포지터리 – 소스 코드 위치 (AWS CodeCommit, GitHub 또는 S3 bucket).
- 빌드 환경 – 언어 및 런타임 환경 (Android, Java, Python, Ruby, Go, Node.js, Docker).
- IAM 역할 – 다른 AWS 자원으로 부터 CodeBuild 접근 허용.
- 빌드 스펙 – YAML 양식 빌드 명령어.
- 컴퓨팅 사양 – 사용할 컴퓨팅 및 메모리 사양 (최대 8vCPU 및 15 GB 메모리).
CodeBuild는 완전히 격리된 신규 콘테이너 기반 환경에서 각 빌드를 수행합니다. 빌드를 시작하면 아래와 같이 진행합니다.
- CodeBuild는 빌드 프로젝트에서 지정한 빌드 환경을 기반으로 콘테이너를 시작합니다. Android, Java, Python, Ruby, Go, Node.js 및 Docker (Docker 이미지 작성용)에 대한 맞춤형 발드 환경을 제공합니다. Docker 허브 또는 EC2 Container Registry를 참조할 수 있습니다. 선별된 빌드 환경에는 AWS SDK 및 AWS 명령 줄 인터페이스 (CLI)를 사용할 수 있습니다.
- CodeBuild는 빌드 도중 생긴 모든 커맨드 라인을 모아서 AWS 관리 콘솔에서 볼수 있습니다.
- CodeBuild는 빌드 프로젝트에 지정된 소스 저장소에서 코드를 가져옵니다.
- CodeBuild는 빌드 프로젝트에서 지정한 명령을 실행합니다. 각 명령은 프로젝트 빌드 스펙에서 식별된 설치, 사전 빌드, 빌드 및 빌드 후 단계를 포함 할 수 있습니다.
- CodeBuild 생성된 실행 파일 또는 결과물(artfacts)를 S3에 업로드합니다. AWS Key Management Service (KMS) 암호화는 선택 사항입니다.
- CodeBuild는 빌드에 사용 된 콘테이너를 삭제합니다.
AWS CodePipeline 빌드 서비스 공급자 중 하나로 CodeBuild를 사용할 수 있습니다. 기존 CI/CD 프로세스를 도입하고 있는 경우, 개발 프로세스를 완전히 자동화 할 수 있습니다. CodeBuild는 S3 및 AWS Identity and Access Management (IAM)와 같은 다른 AWS 서비스를 사용합니다.
선별된 빌드 환경에는 AWS CLI 및 AWS SDK가 포함됩니다. 이를 통해 CodePipeline 및 AWS SAM를 사용하여 서버가 필요없는 응용 프로그램을 위한 완전 자동화된 CI/CD 워크 플로우를 만들 수 있습니다. npm 또는 pip 패키지를 만들고 AWS CLI를 사용하여 패키징 및 배포할 수 있습니다.
CodeBuild의 모든 기능은 AWS 관리 콘솔, API 또는 AWS 명령 줄 인터페이스(CLI)를 통해 실행할 수 있습니다.
AWS CodeBuild 사용해 보기
우선 전체 빌드 작업을 다 해 보기 보다는 우선 AWS CodeBuild 스크린샷을 통애 주요 기능에 대해 먼저 알려드리겠습니다.
아래는 빌드 목록 입니다.
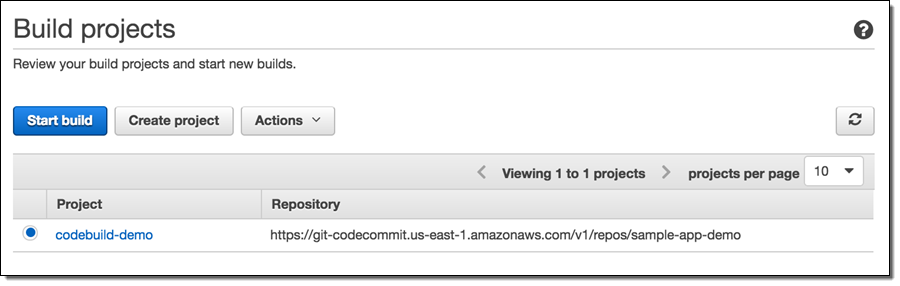
하나의 빌드에 대한 상세 정보를 볼 수 있습니다.
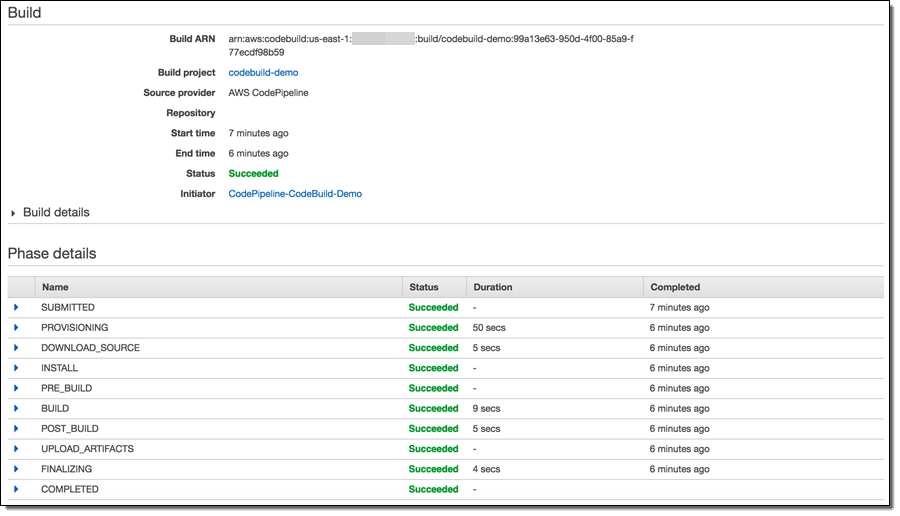
빌드 기록도 볼 수 있습니다.
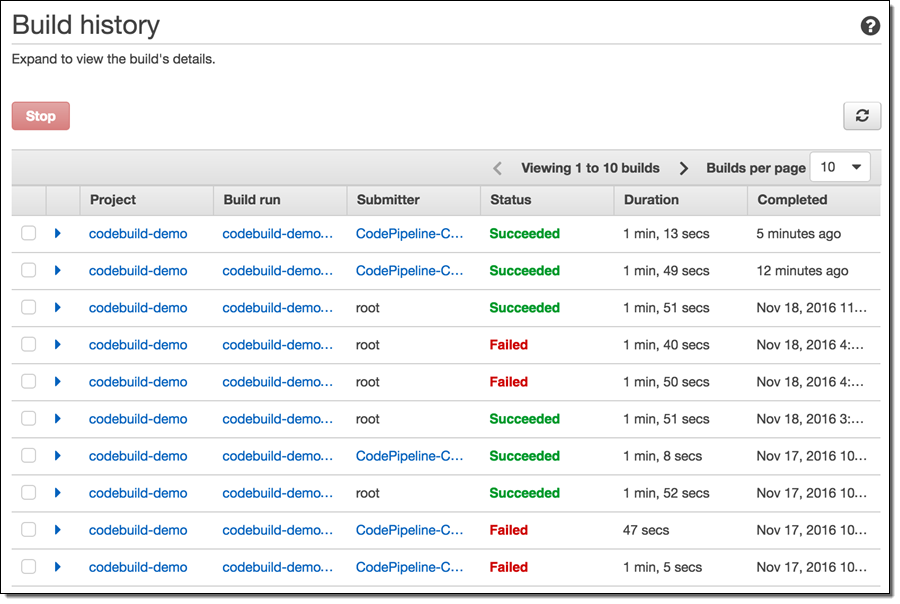
AWS CodeBuild를 AWS CodePipeline 빌드 서비스 제공자로 사용 가능합니다.
정식 출시
AWS CodeBuild는 정식 출시 되어 오늘부터 사용할 수 있습니다. 현재 리눅스 빌드 지원이 되며 향후 윈도 지원도 추가할 예정입니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 AWS CodeBuild – Fully Managed Build Service의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
AWS X-Ray – 분산 애플리케이션 추적 및 디버깅 서비스
지난 11월 미국 대통령상 수상자인 Grace Hopper는 디버깅(Debugging)이라는 용어를 처음으로 사용한 분입니다. 이것은 프로그램에서 오류를 식별하고 제거하는 과정을 말합니다.
저도 컴퓨터에서 실제 버그를 추출하지는 못했지만, 예전에는 어셈블리 언어 프로그램을 디버깅 하는 데 많은 시간을 할애했습니다. 당시 디버깅은 코드를 한 단계 수행하고, 각 단계 전후의 각 프로세서 레지스터 내용을 검사하여 실제로 발생한 상황과 일치하는지 계속 확인했습니다. 상당히 지루한 과정이지만, 버그를 숨기지는 못하며 코드 작동 방식에 대한 심층적인 이해를 할 수 있었다는 보람이었습니다. 나중에 single-stepping은 출력(hello, stderr)을 디버깅하고 거기에서 로그 파일과 로그 분석 도구를 다시 디버깅하였습니다.
{kind=link}
지난 십 년 동안 복잡한 분산 시스템이 등장하면서, 디버깅을 하는 방법도 변화되어 새로운 의미를 가지게 되었습니다. 개별 기능과 모듈이 예상대로 작동하는지 확인하는 단위 테스트와 함께 확장 시 실행 패턴도 검토해야 하는 문제가 있습니다. 클라우드 컴퓨팅, 마이크로 서비스 및 비동기식 알림을 기반한 새로운 아키텍처가 결합되어, 수백 혹은 수천 개의 서비스가 함께 움직이는 분산 시스템이 생겨났습니다. 이러한 복잡한 시스템에서 성능 문제를 확인해야 하는 문제는 점점 커지고 있는데, 이는 개별 서비스 수준에서 관찰한 결과를 의미있는 최상위 결과로 집계하는 데 어려움이 있기 때문입니다. 개발자가 EC2 인스턴스, ECS 컨테이너, 마이크로 서비스, AWS 데이터베이스 및 메시징 서비스를 통과 할 때 “스레드를 따라 갈(follow-the-thread)” 수 있는 쉬운 방법은 없었습니다.
이 문제를 해결해 봅시다!
AWS X-Ray 서비스 소개
오늘 AWS X-Ray 에 대해 소개합니다. 이를 통해 앞서 언급했던 모든 부분에서 처음부터 끝까지 요청을 추적 할 수 있습니다. 분산 시스템을 이해하고 확장하려는 경우, 발생하는 문제를 해결하고 이를 수행하기 위해 필요한 정보와 인사이트를 제공합니다.
X-Ray는 EC2 인스턴스 (ECS 컨테이너 포함), AWS Elastic Beanstalk, Amazon API Gateway에서 실행되는 코드를 추적하고 데이터를 캡처합니다. 쓰레드 추적(follow-the-thread)을 위해 HTTP 헤더 (고유 ID 포함)를 추가하고, 다음 번 티어에 요청 처리 시 헤더를 전달하는 방식으로 구현합니다. 각 엔드포인트에서 수집 된 데이터는 세그먼트(Segment)라고하며, JSON 데이터로 저장합니다.
각 세그먼트는 작업 단위를 나타내며, 요청 및 응답 타이밍과 더 작은 작업 단위를 나타내는 선택적 하위 세그먼트 (적절한 도구를 제공 할 경우, 프로그램 코드까지)를 포함합니다. 통계적으로 의미있는 세그먼트 샘플은 AWS X-Ray (데몬 프로세스가 EC2 인스턴스 및 컨테이너 내부에서 처리)에서 트레이스(Trace, 공통 ID를 공유하는 세그먼트 그룹)를 만듭니다. 트레이스와 세그먼트는 서비스간 관계를 시각적으로 표시하는 그래프 를 만들기 위해 사용됩니다.
위의 모든 것이 잘 구성되어 있는 지 보려면, X-Ray 콘솔을 살펴 보면 됩니다. 콘솔이 제공하는 몇 가지 샘플 앱을 사용할 수 있습니다.
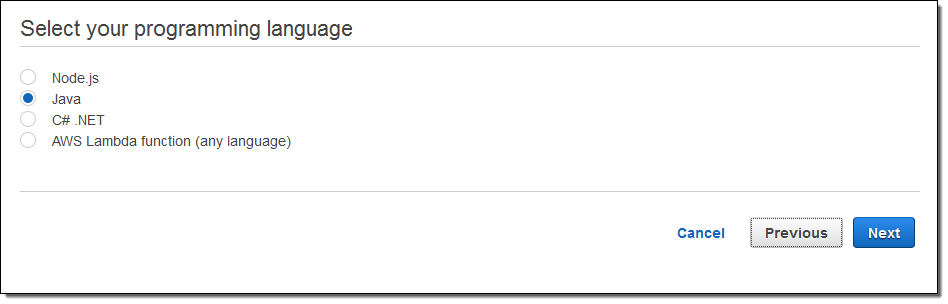
각 샘플 앱은 AWS CloudFormation 템플릿에 의해 실행할 수 있습니다. 위의 앱은 최신 AWS SDK를 사용합니다. 이 SDK는 X-Ray를 인식하고 엑스레이 세그먼트를 수집 및 저장하는 프로세스에 참여합니다. Java, Node.js 및 .NET SDK에서 X-Ray 지원이 됩니다. 나중에 가능한 한 빨리 업데이트 할 것입니다.
자신의 애플리케이션을 측정하고 실행할 준비가 되면, X-Ray Console에서 수행해야 할 작업을 표시합니다.
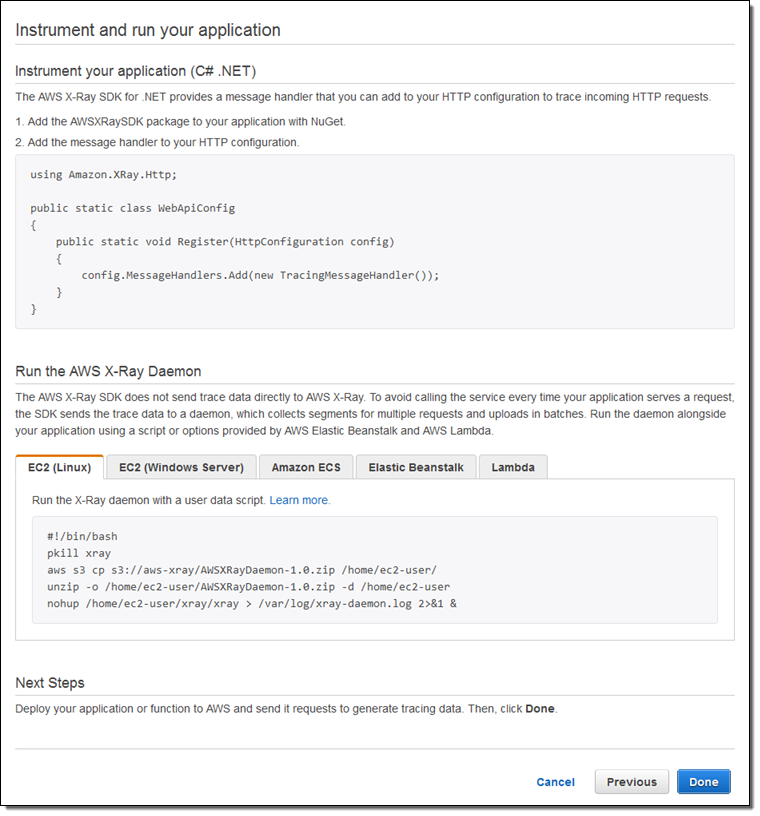
우선 두 개의 앱을 출시하고, 잠시 실행 한 다음 X-Ray 콘솔로 넘어 가서 무슨 일이 일어나고 있는지 확인했습니다. 아래 Service Map은 최상위 레벨 구성도를 제공합니다.
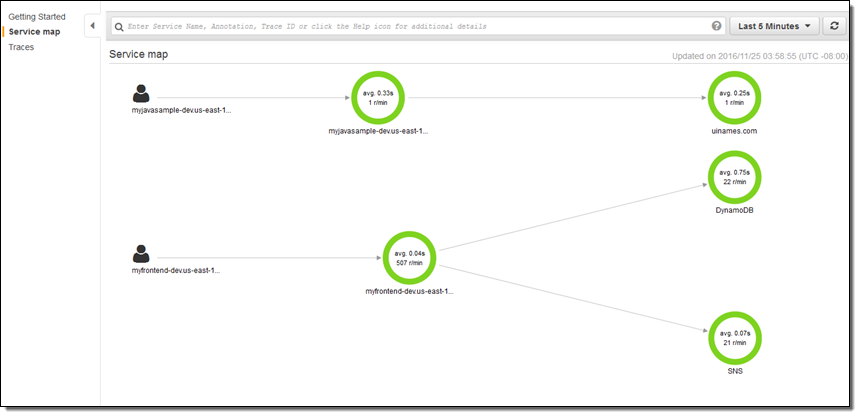
날짜 / 시간 범위 선택기를 사용하여 관심 있는 시간 프레임을 볼 수 있습니다.
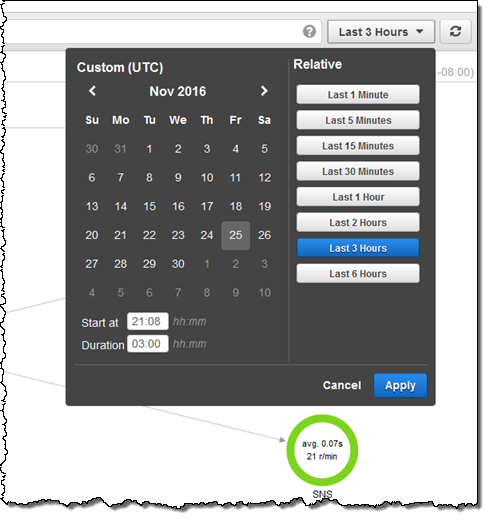
그래프의 모든 노드를 클릭하여 그 뒤에 있는 흔적을 살펴볼 수 있습니다.
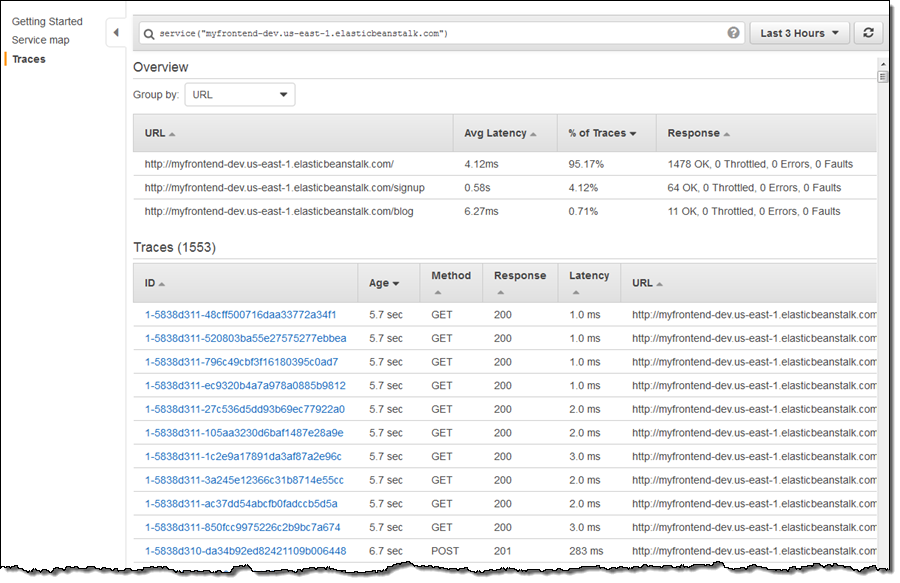
페이지 상단에 보면, 회원 가입이 적고 (4.12 %) 다른 두 작업보다 대기 시간이 더 길다는 것을 알 수 있습니다. 먼저 URL별로 정렬하여 회원 가입을 그룹화 한 다음, 특정 트레이스에 기여하는 세그먼트를 모니터링 합니다. 다음은 DynamoDB 및 SNS에 대한 호출을 포함하는 예제입니다.
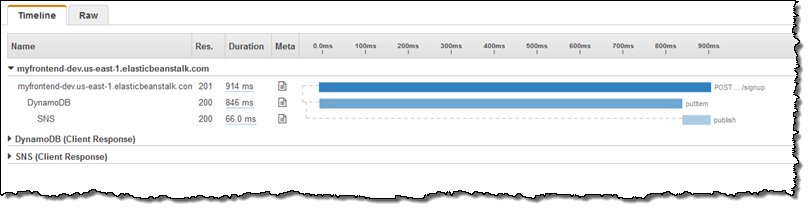
위에서 보면 특정 진입 점에서 호출 될 때 DynamoDB에 대한 호출이 오래 걸리는 것을 나타냅니다. DynamoDB에 대한 호출은 한 자리 밀리 초 단위로 실행되므로 자세히 살펴 봐야합니다. 메타 열에 초점을 맞추고 문서 아이콘을 클릭 한 다음 리소스 탭을 검토하여 진행 상황을 확인합니다.
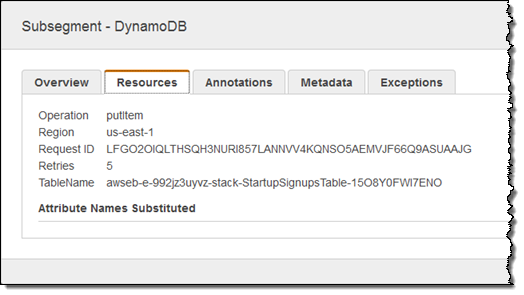
클라이언트 SDK는 재시도 중에 일부를 수행하는 것처럼 보입니다. 대부분의 경우 테이블에 추가 읽기 또는 쓰기 처리량이 제공되어야 하기 때문입니다.
X-Ray UI는 필터식 개념을 기반으로 합니다. 몇 가지 주요 기능을 위한 전용 UI 요소가 있지만 나머지 부분은(개발자 지향 도구에 적합) 페이지 상단의 텍스트 상자에 간단히 입력하는 자유 형식 필터로 제공됩니다. 다음은 몇 가지 간단한 예제입니다.
responsetime > 5– Response time more than 5 seconds.duration >= 5 AND duration <= 8– Duration between 5 and 8 seconds.service("dynamodb")– Requests that include a call to DynamoDB.
또한, 날짜, 추적 ID, HTTP 메소드 및 상태 코드, URL, 사용자 에이전트, 클라이언트 IP 주소 등이 포함됩니다. 지금까지 본 것보다 더 많은 기능은 X-Ray API 및 AWS CLI를 참조하십시오. 이를 통해 많은 종류의 고급 도구, 시각화 및 파트너 기회가 열립니다.
정식 출시
AWS X-Ray는 오늘 부터 12개의 모든 공개 AWS 리전에서 미리보기 형식으로 제공합니다.
— Jeff
이 글은 AWS re:Invent 2016 신규 출시 소식으로 AWS X-Ray – See Inside of Your Distributed Application의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
AWS Snowmobile – 엑사 바이트(Exabyte) 데이터를 몇 주 만에 클라우드로
클라우드 이전 중 기존 데이터 센터 혹은 회사에 대용량 데이터가 있다면, 이전이 매우 어려울 수 있습니다. 고속 인터넷을 통해서도 영상 파일, 금융 기록, 위성 이미지 등 페타바이트에서 엑사 바이트(Exabyte)에 이르는 데이터를 옮기는 건 매우 어렵고, 간단히 계산을 해봐도 수년에서 수십 년이 걸릴 수 있습니다.
작년에 AWS Snowball (출시 뉴스 참고)를 통해 손쉽게 대용량 장치를 통해 마이그레이션을 하기 위한 첫 단계를 밟았습니다. 80TB의 스토리지를 담은 전용 스토리지 장치를 배송 받아 데이터를 클라우드로 업로드 하는 방식을 통해 많은 고객들이 도움을 받고 있습니다.
그러나 여전히 엑사 바이트급 데이터를 운용하는 경우라면, 80TB 장치 관점에서 보면 엄청나게 많은 수의 장비와 이동에 대한 곤란한 점이 많습니다.
AWS Snowmobile 저장 콘테이너
이러한 고객들의 요구 사항에 맞추어, 오늘 Snowmobile을 출시합니다. 최고 100PB의 데이터를 실을 수 있는 전용 트럭을 통해 몇 주 안에 엑사 바이트 데이터를 AWS로 이전할 수 있습니다. 금융 서비스, 미디어 및 엔터테인먼트, 과학 및 기타 산업에서 고객의 요구를 충족 시키도록 설계된 Snowmobile은 네트워크에 연결되어 로컬 NFS 마운트 볼륨으로 보이게 됩니다. 기존 백업 및 아카이브 도구를 사용하여 Amazon Simple Storage Service (S3) 또는 Amazon Glacier에 데이터를 채울 수 있습니다.

Snowmbile은 길이 45 피트, 높이 9.6 피트, 너비 8 피트의 견고한 변조 방지를 지원하는 선적용 콘테이너입니다. 방수 기능이 있으며 기후에 영향을 받지 않으며 기존 데이터 센터에 인접해, 지붕이 있는지 상관없이 주차 할 수 있습니다. 각 Snowmbile은 약 350KW의 AC 전원을 소비합니다. 현장에 충분한 용량이 없는 경우 발전기를 마련 할 수 있습니다.
보안 측면에서 Snowmobile은 보관성(chain-of-custody) 추적 및 비디오 감시와 같은 여러 단계의 논리적 및 물리적 보안을 통합적으로 제공합니다. 여러분의 데이터를 쓰기 전에 AWS Key Management Service (KMS) 키로 암호화합니다. 각 콘테이너에는 GPS 추적 기능이 포함되어 있으며, 셀룰러 또는 위성 연결을 통해 AWS에 다시 연결합니다. Snowmobile이 운송 중일 때 보안 차량 호위를 준비 할 것입니다. Snowmobile이 구내에있는 동안 전용 경비원을 배치 할 수도 있습니다.
각 Snowmobile에는 초당 40Gb의 다중 연결을 통해 초당 1Tb의 데이터 전송을 지원하는 고속 스위치에 연결된 네트워크 케이블을 포함합니다. 해당 네트워크에서 이 속도로 데이터를 전송할 수 있다고 가정하면, 약 10 일 후에 Snowmobile을 채울 수 있습니다.
Snowmobile 실제 보기
엑사 데이터 규모의 데이터 센터도 본 적이 없고, 저희 집에 45 피트 길이의 콘테이너를 보관할 수 있는 공간도 없기 때문에, Snowmobile을 준비하고 사용하는 과정을 설명하기 해 LEGO 테이블에 앉아 (Doc Brown 전통에 따라) 작은 모형을 만들었습니다 . 레고 기반의 스토리 텔링을 즐기시기 바랍니다!
먼저 데이터 센터에서 시작해보겠습니다. 건물 안에 랙은 다수의 디스크 및 테이프 드라이브로 가득 차 있습니다. 각 드라이브에는 중요한 데이터를 저장합니다. 여러분 동료들은 바닥을 열어 많은 시간을 들여 케이블을 짜고 이를 연결하려고 노력 하고 있습니다.

관리자는 너무 일이 힘들어 다음에 무엇을 해야 할지 걱정부터 앞섭니다.

다행히 동료 중 한 명이 AWS 블로그를 읽고 공부를 해서 무엇을 해야 할지 알게 되었습니다.

홈페이지의 연락하기를 통해 AWS와 연결이 되어 미팅 일정을 잡습니다.

모두 모여서 AWS에 대해 배우고, 대용량 데이터 마이그레이션을 위한 Snowmobile에 대한 이점을 알고 계획을 세우기 시작합니다.

Snowmobile의 확장 모델에 대해 많은 관심이 가지고 (심지어 강아지까지 보러 왔네요!). 신기해서 사진도 한 장 남깁니다.

이제 Snowmobile이 데이터 센터로 와서 주차를 합니다.

AWS 프로페셔널 서비스에서 어떻게 연결을 하고 데이터 전송을 하는지 알려줍니다.

작업이 완료되면 Snowmobile은 AWS로 돌아가 바로 클라우드로 데이터 이동을 시작합니다.
DigitalGlobe의 Snowmobile 활용 사례
저희 고객사인 DigitalGlobe는 100PB의 위성 이미지를 AWS로 옮기기 위해 Snowmobile을 사용했습니다. Jay Littlepage (VP of Infrastructure & Operations at DigitalGlobe) 다음과 같이 언급했습니다.
 “많은 대기업과 마찬가지로 저희도 IT 운영에 있어 기존 데이터 센터에서 AWS로 마이그레이션하는 과정에 있습니다. 대용량 지리 공간 데이터 플랫폼 인 GBDX는 처음부터 AWS에 기반을 두고 있습니다. 그러나, 지구 표면의 60억 제곱 킬로미터를 시각화하는 고해상도 위성 이미지는 16 년 동안 저희 시설내 백업 아카이브에 저장되었습니다. 아카이브 내 데이터를 AWS로 서서히 옮겨 왔지만, 그 과정은 느리고 비효율적이었습니다. 위성 및 항성 데이터는 더 많은 지구 이미지를 생성합니다 (10 PB).
“많은 대기업과 마찬가지로 저희도 IT 운영에 있어 기존 데이터 센터에서 AWS로 마이그레이션하는 과정에 있습니다. 대용량 지리 공간 데이터 플랫폼 인 GBDX는 처음부터 AWS에 기반을 두고 있습니다. 그러나, 지구 표면의 60억 제곱 킬로미터를 시각화하는 고해상도 위성 이미지는 16 년 동안 저희 시설내 백업 아카이브에 저장되었습니다. 아카이브 내 데이터를 AWS로 서서히 옮겨 왔지만, 그 과정은 느리고 비효율적이었습니다. 위성 및 항성 데이터는 더 많은 지구 이미지를 생성합니다 (10 PB).
우리는 100 PB 아카이브를 이동할 수있는 방법이 필요했지만, AWS Snowmobile은 지금까지 찾지 못했던 해법이었습니다. DigitalGlobe는 한 번의 Snowmobile 전송을 통해 Amazon Raw Glacier Vault로 직접 전체 원본 이미지 아카이브를 마이그레이션하고 있습니다. AWS Snowmobile는 운영자가 기본 구성, 모니터링 및 물류 관리만을 담당하면 되는 맞춤형 서비스를 제공합니다. Snowmobile의 데이터 전송 기능을 사용하면, 시간이 지나면 계속 생성되는 이미지 아카이브를 보다 신속하게 클라우드로 가져와 고객 및 파트너가 방대한 데이터 세트에 접근할 수 있습니다. GBDX 내에서 AWS의 탄력적인 컴퓨팅 플랫폼을 사용함으로서, 빠른 속도와 경제적인 방식에 따라 인프라에 대한 통찰력을 얻은 다음 분산 이미지 분석을 수행할 수 있습니다. Snowmobile을 통해서 짧은 시간에 대량의 데이터를 전송하고, 고객에게 새로운 비즈니스 기회를 창출 할 수 있었습니다. 스노우 모빌은 진정한 게임 체인저입니다!”
알아두기
마지막으로 Snowmobile에대해 알아 두면 좋을 몇 가지만 소개합니다.
- 데이터 내보내기 – 초기에는 데이터 가져 오기 (온-프레미스에서 AWS)에만 집중합니다. 저희도 일부 고객이 재해 복구 (DR) 사례를 중심으로 데이터 내보내기에 관심을 갖고 있음을 알고 있습니다.
- 가용성 – Snowmobile은 모든 AWS 지역에서 사용할 수 있습니다. 이전에 언급해서 아시겠지만, 본 서비스는 셀프 서비스가 아닙니다. AWS 영업 및 기술 담당자들이 데이터 가져 오기 요구 사항에 대해 여러분과 상의한 후 제공 됩니다.
- 가격 책정 – 아직은 공유할 수 있는 가격 정보가 없습니다. 그러나 Snowmobile은 네트워크 기반 데이터 전송 모델을 사용하는 것보다는 훨씬 빠르고 비용이 적게 듭니다.
참고로 레고 기반 스토리 텔링에 대한 고화질 이미지를 보시려면, Snowmobile Photo Album을 참고하세요. 특별히 마지막 작업과 사진 촬영에 도움을 준 Matt Gutierrez (Symbionix)에게 감사하게 생각합니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 AWS Snowmobile – Move Exabytes of Data to the Cloud in Weeks의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
AWS Snowball Edge – 클러스터링 및 용량 추가, 로컬 엔드포인트와 Lambda 함수 지원
작년에 AWS Snowball을 출시(블로그 참고) 한 뒤, 많은 업데이트가 있었습니다. 물리적 50TB 데이터 전송 저장 장치로 보안 및 운송의 편리성을 통한 클라우드 데이터 이동에 대한 아주 간단한 해법으로서 그 이후에도, 용량 확대 및 리전 추가 지원 (80 TB), 작업 관리 API 및 S3 어댑터, HIPAA 호환, HDFS 가져오기 지원 등의 업데이트가 이루어졌습니다.
위의 모든 개선 사항 역시 중요했지만, 제품 기본 특성은 변경하지 않았습니다. 지난 1년간 많은 AWS 고객이 Snowball을 활용하여 다양한 유형의 대용량 데이터 이전, 유전학 데이터 수집 작업 등에서 물리적 환경에 필요한 다양한 작업을 진행하였습니다. 그 와중에 좀 더 기능적으로 필요한 몇 가지 여지가 있음을 알게 되었습니다.
어떤 고객은 네트워크 연결이 제한적이거나 아예 존재하지 않는 극단적인 상황에서도 많은 양의 데이터 (수백 테라 바이트)를 생성하기도 합니다. 예를 들어, 농장, 공장, 병원, 항공기 및 석유 시추 위치에서 생성하는 데이터를 수집할 필요가 있습니다. 각 작업 현장 측정 위치에서 비디오 감시, IoT 장치로 수집 된 정보에 이르기까지 고객은 개별 데이터 저장 및 수집에 넘어서서 데이터가 도착할 때 일부 로컬 처리를 수행 가능한 모델에 관심이 있습니다. 수집한 데이터를 필터링, 정리, 분석, 구성, 추적, 요약 및 모니터링하여, 특정 패턴이나 이슈에 대해 들어오는 데이터를 검색하여, 흥미로운 것이 발견되면 신속하게 경고를 하는 경우가 있습니다.
신규 Snowball Edge 디바이스
 오늘 Snowball Edge라는 새로운 저장 장치를 추가로 제공합니다. 이 장치는 기존 Snowball 기능에 더해 연결성, 스토리지, 클러스터링을 통한 수평적 확장, 기존 S3 및 NFS 클라이언트, Lambda 기반 처리를 통한 신규 스토리지 엔드포인트 지원이 가능합니다.
오늘 Snowball Edge라는 새로운 저장 장치를 추가로 제공합니다. 이 장치는 기존 Snowball 기능에 더해 연결성, 스토리지, 클러스터링을 통한 수평적 확장, 기존 S3 및 NFS 클라이언트, Lambda 기반 처리를 통한 신규 스토리지 엔드포인트 지원이 가능합니다.
물리적으로 Snowball Edge는 집에서 부터 아주 열악한 환경인 농장, 군대 및 항공 분야에서도 사용 가능합니다. 새로운 랙 마운트 장착용으로 클러스터 기능이 있는 것이 장점입니다.
몇 가지 새로운 기능을 살펴 보겠습니다.
연결성 확대
다양한 고속 네트워크 연결에 대한 선택 사항이 높아졌습니다. 10GBase-T, 10 또는 25 Gb SFP28, 또는 40 Gb QSFP+를 사용 가능합니다. IoT 기기가 데이터 업로드를 할 수 있도록 3G 모바일 혹은 Wi-Fi를 지원합니다 또한, 기타 IoT 기기를 위한 Zigbee, USB 3.0 포트, PCIe 확장 포트 등 다양한 접속 방법도 지원 합니다.
Snowball Edge에 데이터를 복사 할 수 있는 대역폭은 초당 최대 14Gb까지 확보 할 수 있습니다. 따라서, 19 시간 내에 100TB를 복사 할 수 있습니다. 시작부터 끝까지 (S3에서 사용 가능한 데이터로 전송 시작) 전체 과정은 배송 및 처리 과정을 포함하여 일주일이 소요됩니다.
스토리지 용량 확대
Snowball Edge는 100 TB 스토리지를 포함합니다.
클러스터링을 통한 수평적 확장 기능Snowball Edge 어플라이언스 두 개 이상을 클러스터로 쉽게 구성하여 용량을 늘리고 내구성을 높이는 동시에 모든 스토리지에 단일 엔드 포인트를 통해 접근할 수 있습니다. 예를 들어, 6개의 기기를 클러스터링을 하면 400TB의 스토리지와 99.999%의 내구성을 갖춘 고가용성 클러스터를 생성합니다. 이를 통해 2개의 기기를 제외하고 데이터 보호를 할 수 있습니다.
클러스터링을 통해 페타 바이트 단위로 용량을 확장 할 수 있으며, 손쉽게 클러스터에서 기기 추가 및 제거가 가능합니다. 클러스터는 자체 관리가 가능하므로 소프트웨어 업데이트 등에 대해 걱정할 필요가 없습니다.
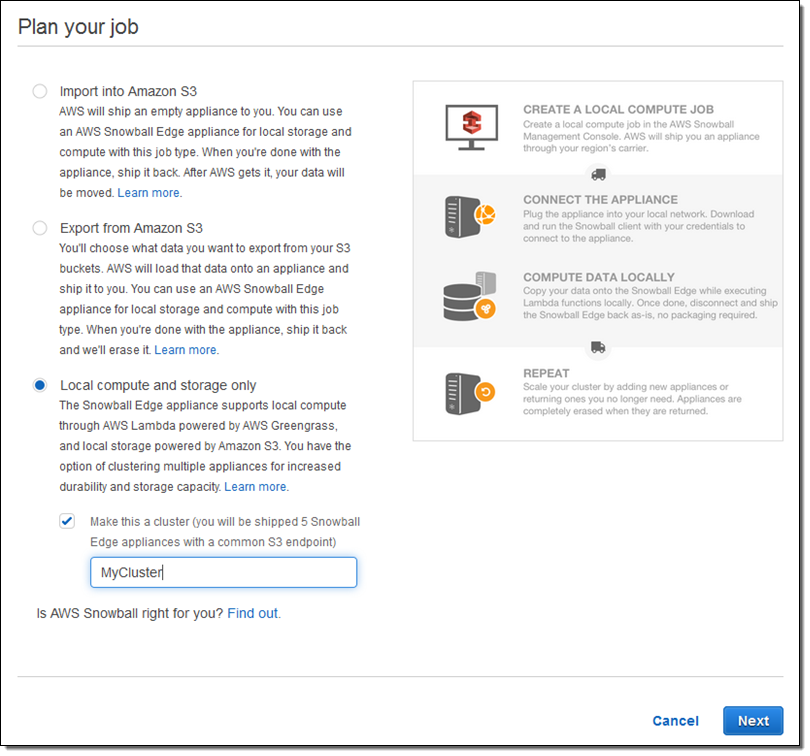
Local compute and storage only를 체크하여 클러스터를 주문하고, Make this a cluster를 통해 작업을 설정하시면 됩니다.
신규 스토리지 엔드 포인트 (S3 및 NFS)
기존 데이터 백업 및 아키이빙, 데이터 전송을 위해 S3나 NFS를 사용하여 Snowball Edge를 활용할 수 있습니다. 2개 이상의 기기로 클러스터를 만들어도, 같은 엔드 포인트를 사용 가능합니다. 클러스터를 로컬 네트워크 저장 장치로 사용할 수 있습니다.
Snowball Edge 는 S3 API, 즉 LIST, GET, PUT, DELETE, HEAD, Multipart Upload 등을 지원 하며, NFS v3 및 NFS 4.1. 역시 지원합니다.
Snowball Edge를 파일 스토리지 게이트웨이로 만들어 NFS로 접근 가능합니다. 이러한 기능을 활용하여 데이터 이전, AWS Storage Gateway 연동, 온-프레미스 앱에서 온-프레미스 데이터를 처리 가능합니다.
Lambda 기반 로컬 작업 지원
AWS Lambda 함수를 사용하여 Snowball Edge를 S3 버킷으로 연계해서 업로드가 가능합니다.
본 기능을 통해 (앞서 언급한 대로) 수집한 데이터를 필터링, 정리, 분석, 구성, 추적, 요약 및 모니터링하여, Snowball Edge를 좀 더 지능적이고 스마트하게 데이터 수집 및 처리를 할 수 있도록 해줍니다
우선 S3 PUT 에 대해 버킷당 하나의 함수를 사용 가능합니다. 함수는 Python 언어로 작성해야 하고 128 MB 메모리로 람다 함수 실행 환경을 설정하면 됩니다.
아래와 같이 Snowball Edge 환경 설정에 람다 함수를 지정하면 됩니다.
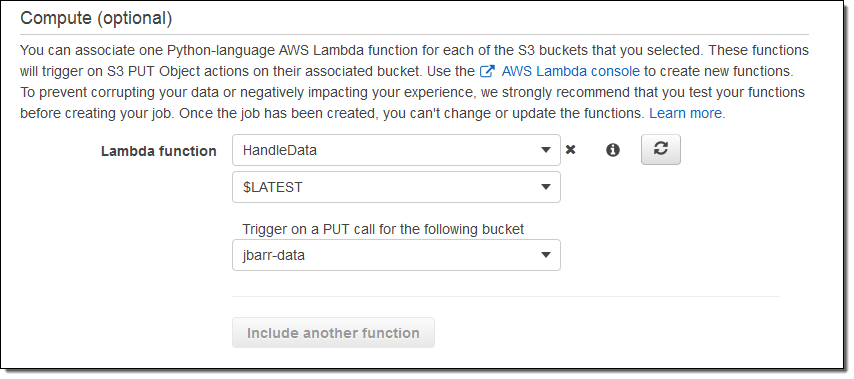
주문하기 전에 클라우드에서 기능을 테스트하는 것을 권장합니다.
정식 출시 및 가격 정보
Snowball Edge는 플러그앤 플레이 기반으로 배포합니다. 현장에서 이를 다루는 분은 설정을 할 필요는 없으며, LCD 보드를 통해 상태 정보나 설정 동영상을 볼 수 있습니다. 보드 상에 설정 코드는 자동으로 업데이트되고 소프트웨어 업데이트 관리도 필요 없습니다. AWS 관리 콘솔 (API 또는 CLI 접근 가능)을 통해 상태를 확인하고 배치 된 장비에 대한 최신 구성 변경 사항을 작성할 수 있습니다.
각 Snowball Edge은 배송료 포함 $300 입니다. 10일까지 장비를 사용할 수 있으며, 그 이후로는 일 $30이 추가됩니다. 로컬에서 Lambda 함수 실행은 무료입니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 AWS Snowball Edge – More Storage, Local Endpoints, Lambda Functions의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
AWS Greengrass – 유비쿼터스 및 실세계 컴퓨팅 서비스
데이터 센터나 사무실 안에서 컴퓨팅 작업이나 및 데이터 처리는 용이합니다. 기본적으로 양호한 네트워크 연결성과 지속적인 전력 공급을 기대할 수 있으며, 가능한 만큼 온 – 프레미스 또는 클라우드 기반 스토리지에 접근하여 컴퓨팅 성능을 활용할 수 있습니다. 하지만, 밖으로 나오면 상황이 매우 다릅니다. 네트워크 연결은 간헐적이거나 신뢰할 수 없으며, 속도와 확장면에서 제한적일 수 있습니다. 전원 공급은 저장 용량 및 컴퓨팅 성능을 제한 할 수 있습니다.
따라서, 현실에서 흥미롭고 잠재적으로 가치 있는 많은 데이터가 수집 및 처리하여, 지능형 서비스를 제공하는 것은 매우 중요합니다. 이러한 데이터는 자원 채굴 현장이나 병원이나 공장 또는 심지어 (Curiosity)가 있는 화성처럼) 다른 행성, 지구 표면 아래 몇 마일 떨어진 해저 등에서도 얻어야 할 수 있습니다.
지금까지 많은 고객은 AWS 클라우드의 서비스 규모와 성능을 활용하여, 이러한 열악한 조건에서 로컬 처리를 시도할 수 있도록 다양한 피드백을 주셨습니다. 먼저, 데이터를 측정, 감지 및 제어하는 시스템을 로컬에 구축합니다. 그런 다음, 클라우드와 유사한 로컬 환경에 데이터를 저장하고 로컬 내부에서 독립적으로 수행하도록 일단 구성을 합니다. 이런 작업을 위해서는 로컬 프로세싱 및 스토리지 자원을 구성하고 활용하는 동시에 특수 센서 및 주변 장치에 연결할 수 있어야 합니다.
AWS Greengrass 소개
AWS Greengrass라는 서비스는 AWS 프로그래밍 모델을 작고 단순한 필드 기반 장치로 확장하여 위에서 설명한 문제점을 해결할 수 있도록 설계되었습니다.

Greengrass는 AWS IoT 및 AWS Lambda를 기반으로 하며 다른 AWS 서비스에도 접근할 수 있습니다. 오프라인 작업을 위해 제작되었으며, 로컬에서 프로그래밍 구현을 단순하게 만들어 주게 됩니다. 현장에서 실행되는 프로그램 코드를 통해 데이터를 새로 수집, 필터링 및 집계한 후 장기적으로 저장하고, 추가 분석을 할 수 있도록 클라우드로 전송할 수 있습니다. 또한, 현장에서 실행되는 프로그램 코드는 클라우드에 대한 연결을 일시적으로 사용할 수 없는 경우에도 매우 신속하게 조치를 취할 수 있습니다.
고객이 소형 장치용 임베디드 시스템을 이미 개발 중인 경우, 최신 클라우드 기반의 개발 도구 및 워크 플로를 활용할 수 있습니다. 클라우드에서 코드를 작성하고 테스트 한 다음, 로컬에서 배포 할 수 있습니다. 디바이스 이벤트에 응답하는 Python 코드를 작성할 수 있으며 MQTT 기반 pub/sub 메시징을 사용하여 통신 할 수 있습니다.
Greengrass에는 GreenGrass Core (GGC)와 IoT Device SDK의 두 가지 구성 요소가 있습니다. 이 두 구성 요소는 현장에서 직접 하드웨어에서 실행됩니다.
Greengrass Core는 128MB 이상의 메모리와 1GHz 이상의 x86 또는 ARM CPU를 갖춘 장치에서 실행되도록 설계되었으며, 필요한 경우 추가 리소스를 이용할 수 있습니다. AWS Lambda 기능을 로컬에서 실행하고, AWS 클라우드와 상호 작용하면서도 보안 및 인증을 관리하면서 주변의 다른 디바이스와 통신할 수 있습니다.
IoT Device SDK는 (일반적으로 LAN 또는 기타 로컬 연결된) 코어를 호스팅하는 디바이스장치에서 실행하는 응용 프로그램을 개발하는 데 사용합니다 . 이런 애플리케이션은 센서에서 데이터를 캡쳐하고, MQTT 토픽를 구독하며 AWS IoT 디바이스 섀도우를 사용하여 상태 정보를 저장 및 검색합니다.
AWS GreenGrass 사용
AWS Management Console, AWS APIs, AWS Command Line Interface (CLI)를 통해 Greengrass의 여러 측면을 설정하고 관리 할 수 있습니다.
새 허브 장치를 등록한 후, 원하는 람다 함수를 구성하며 디바이스에 전달할 배포 패키지를 만들 수 있습니다. 여기에서 경량 디바이스와 허브와 연결 시킬 수 있습니다.
미리 보기 출시
오늘 AWS Greengrass 미리보기를 시작합니다. 참여하고 싶으시다면, 가입하신 후 기다리시면 초대해 드립니다. 각 AWS 고객은 1 년 동안 3 개의 기기를 무료로 사용할 수 있습니다. 그 이후에는 각 활성 Greengrass Core의 월간 비용은 최대 10,000 개의 장치에 대해 $ 0.16 (연간 $ 1.49)입니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 AWS Greengrass – Ubiquitous, Real-World Computing의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
Amazon Aurora 업데이트 – PostgreSQL 호환 서비스 출시
2년전 Amazon Aurora 발표를 통해 RDS 팀에서 생각한 클라우드에서 관계형 데이터베이스의 모델을 설명한 신선한 아이디어를 제공한 바 있습니다.
이후 많은 고객으로 부터 정말 가슴 따뜻한 피드백을 받았습니다. MySQL 호환성을 유지하면서도, 고가용성 및 기본 암호화 기능에 대해 만족하고 있으며, Aurora를 통해 빠른 장애 복구와 10GB부터 64 TB까지 자체 스토리지 확장 등의 기능 등에 전적인 신뢰를 보여주셨습니다. Aurora는 6개의 복제본을 세 개의 가용 영역(AZ)에 분산 저장하여 가용성이나 성능 영향 없이 S3를 스토리지 공간으로 사용하고 있습니다. 확장이 필요할 때, 15개의 낮은 지연 속도의 읽기 복제본을 만들수도 있습니다. 더 자세한 사항은 Amazon Aurora 성능 평가 정보를 참고해 주시기 바랍니다.
고객들이 서비스에 대해 다양한 요구를 하고 있기 때문에 이에 대해 바르게 이해하고, 아래와 같이 고객의 피드백에 부합하는 기능을 계속해서 출시해 왔습니다.
- 11월 – 개발 및 테스트용 신규 T2.Medium DB 인스턴스 타입 추가
- 10월 – Lambda Function 호출 및 S3 데이터 읽기 지원
- 9월 – 신규 읽기 엔드 포인트 기능 (로드 밸런싱 및 고가용성 제공)
- 9월 – 병렬 미리 읽기, 고속 인덱싱 , NUMA 인식 등
- 7월 – MySQL 백업에서 클러스터 구축 기능 제공
- 6월 – 리전간 Read Replica 추가 가능
- 5월 – 계정간 스냅샷 기능 추가
- 4월 – Cluster View in RDS Console.
- 3월 – Additional Failover Control.
- 3월 – Local Time Zone Support.
- 3월 – 서울 리전 출시!
- 2월 – Availability in Asia Pacific (Sydney).
PostgreSQL 호환 서비스 출시
 기능적인 측면 뿐만 아니라 추가적인 데이터베이스 엔진 호환성에 대한 요청도 많이 받았습니다. 그 가장 우선 목록이 바로 PostgreSQL호환 서비스입니다. 20년 이상 개발되어온 오픈 소스 데이터베이스 엔진으로서 많은 엔터프라이즈 기업 및 스타트업에서 사용해 오고 있습니다. 특히, 고객들이 (SQL 서버나 오라클이 제공하는) 엔터프라이즈 기능과 성능 이점, PostgreSQL과 연계한 지리 정보 데이터 처리 기능에 만족하고 있는데, 이제 이들 기능을 Aurora가 제공하는 다양한 이점과 함께 활용해 볼 수 있게 되었습니다.
기능적인 측면 뿐만 아니라 추가적인 데이터베이스 엔진 호환성에 대한 요청도 많이 받았습니다. 그 가장 우선 목록이 바로 PostgreSQL호환 서비스입니다. 20년 이상 개발되어온 오픈 소스 데이터베이스 엔진으로서 많은 엔터프라이즈 기업 및 스타트업에서 사용해 오고 있습니다. 특히, 고객들이 (SQL 서버나 오라클이 제공하는) 엔터프라이즈 기능과 성능 이점, PostgreSQL과 연계한 지리 정보 데이터 처리 기능에 만족하고 있는데, 이제 이들 기능을 Aurora가 제공하는 다양한 이점과 함께 활용해 볼 수 있게 되었습니다.
오늘 Amazon Aurora용 PostgreSQL 호환 서비스를 미리보기로 출시합니다. 위에 언급한 장점과 함께, 높은 내구성과 고가용성 그리고 빠르게 읽기 복제본을 생성 및 배포할 수 있게 됩니다. 여기에 몇 가지 여러분이 좋아할 만한 사항을 소개합니다.
성능 – Aurora는 기존 환경에서 보다 2배까지 PostgreSQL 성능을 높였습니다.
호환성 – Aurora는 PostgreSQL (version 9.6.1) 오픈 소스 버전과 완벽하게 호환됩니다. 스토어드 프로시저에서도 Perl, pgSQL, Tcl, JavaScript (V8 자바스크립트 엔진 기반)을 지원할 예정입니다. 또한, Amazon RDS for PostgreSQL에서 제공하는 모든 확장 기능 및 플러그인 역시 지원할 예정입니다.
클라우드 네이티브 – Aurora를 통해 기존 AWS 서비스를 충분히 활용할 수 있으며, 아래의 서비스와 직접 연동이 가능합니다.
- AWS Key Management Service (KMS) – 암호화 기능 지원
- AWS Identity and Access Management (IAM) – 세부적인 Aurora API 및 자원 접근 제어
- Amazon Simple Storage Service (S3) –지속적으로 데이터베이스를 백업하고, 빠르게 복구 가능
- Amazon Relational Database Service (RDS) – 프로비저닝, 백업 관리, 모니터링, 컴퓨팅 자원 확장 및 데이터베이스 설정 관리
- AWS Database Migration Service – 기존 데이터센터 혹은 EC2에서 운용 중이던 PostgreSQL, Oracle, SQL Server의 손쉬운 이전 지원
- AWS Schema Conversion Tool – 데이터베이스 스키마에 대한 손쉬운 이전 지원
RDS 콘솔에서 이제 Aurora 중에서 PostgresSQL Compatible 을 선택할 수 있습니다.
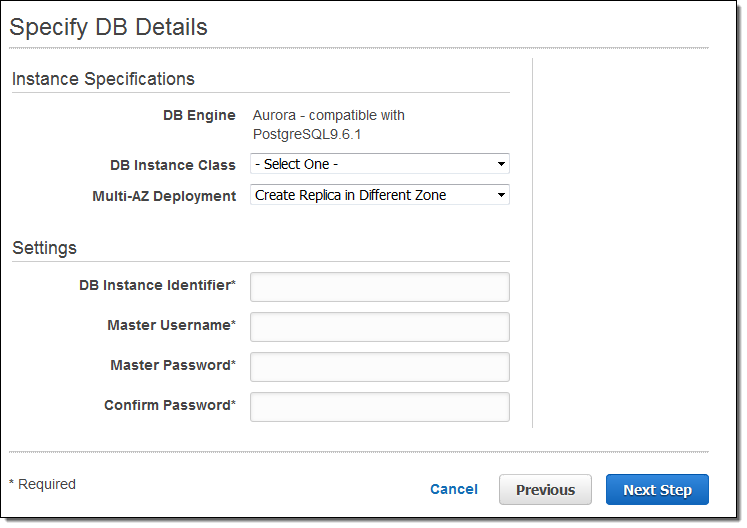
그 다음 DB 인스턴스 타입과 멀티 AZ 배포 조건을 선택하고, 데이터베이스 인스턴스의 이름과 아이디와 암호를 설정합니다.
Amazon Aurora용 PostgreSQL 호환 서비스는 오늘 부터 US East (Northern Virginia) 리전에서 미리 보기로 사용 가능하며, 미리 보기 신청을 통해 바로 써 보실 수 있습니다!
몇 가지 성능 비교 사항
Dave Wein는 Amazon Aurora용 PostgreSQL 호환 서비스와 PostgreSQL 9.6.1를 비교하는 몇 가지 테스트를 진행했습니다. 비교를 위해 m4.16xlarge 인스턴스 기반 데이터베이스 서버와 c4.8xlarge 인스턴스 기반 클라이언트를 사용했습니다.
PostgreSQL는 ext4 파일 시스템 기반 15K IOPS EBS 볼륨 세 개로 이루어진 45K의 Provisioned IOPS 스토리지로 구성하고, WAL 압축 기능 및 오토 버큠(Autovacuum)을 사용하여 양쪽의 같은 워크로드로 성능 테스트를 하였습니다.
우선 쓰기 기반 Sysbench 워크 로드 (20GB 데이터베이스- 250 테이블 및 15만개 열)에서 시작해서, 매회 데이터베이스 재생성을 진행하여 시간이 지남에 따라 아래와 같은 결과를 얻었습니다.
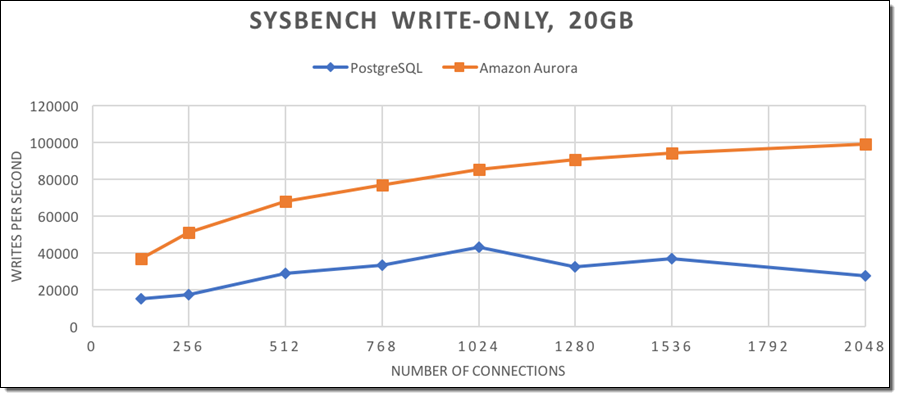
각 실행 시 전체 소요 시간은 아래와 같습니다.
progress: 1791.0 s, 34248.7 tps, lat 29.143 ms stddev 12.233
progress: 1792.0 s, 36696.2 tps, lat 27.363 ms stddev 10.882
progress: 1793.0 s, 26287.4 tps, lat 37.549 ms stddev 20.430
progress: 1794.0 s, 31377.7 tps, lat 31.993 ms stddev 17.408
progress: 1795.0 s, 36219.6 tps, lat 27.522 ms stddev 10.942
progress: 1796.0 s, 35786.4 tps, lat 27.731 ms stddev 11.262
progress: 1797.0 s, 34926.6 tps, lat 29.108 ms stddev 12.176
progress: 1798.0 s, 35663.6 tps, lat 27.766 ms stddev 11.544
progress: 1799.0 s, 36472.6 tps, lat 27.608 ms stddev 10.923
progress: 1800.0 s, 34215.3 tps, lat 28.999 ms stddev 12.095
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 2000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 1800 s
number of transactions actually processed: 61665153
latency average = 29.175 ms
latency stddev = 14.011 ms
tps = 34250.027914 (including connections establishing)
tps = 34267.524614 (excluding connections establishing)
또한 비슷한 실행의 마지막 40 분을 다루는 초당 처리량 그래프를 아래와 같이 공유했습니다.
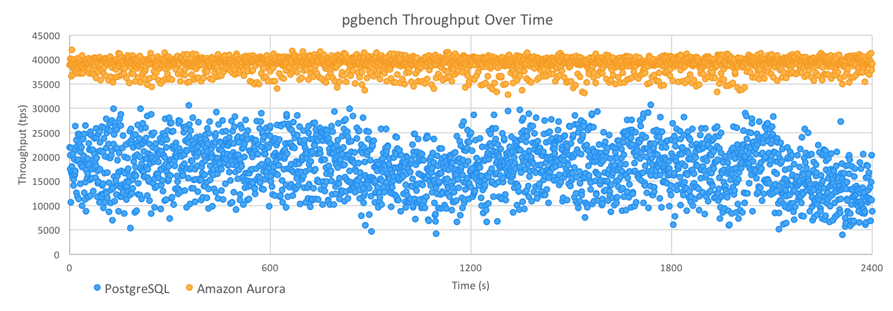
위에서 보시다시피, Amazon Aurora는 PostgreSQL보다 높은 처리량을 제공하여 지터의 1/3 (표준 편차는 각각 1395 TPS 및 5081 TPS)입니다.
David와 Grant는 2017 년 초에 보다 자세한 결과물을 공유하기 위해 데이터를 수집하고 있습니다.
곧 출시 – 성능 확인 기능
앞으로 아주 다양한 측면에서 데이터베이스 성능을 이해할 수 있도록 디자인한 새로운 도구를 출시할 예정입니다. 각 질의에 대한 세부적인 사항과 데이터베이스가 어떻게 질의를 처리하는지 상세히 볼 수 있습니다. 아래는 미리보기 스크린샷입니다.
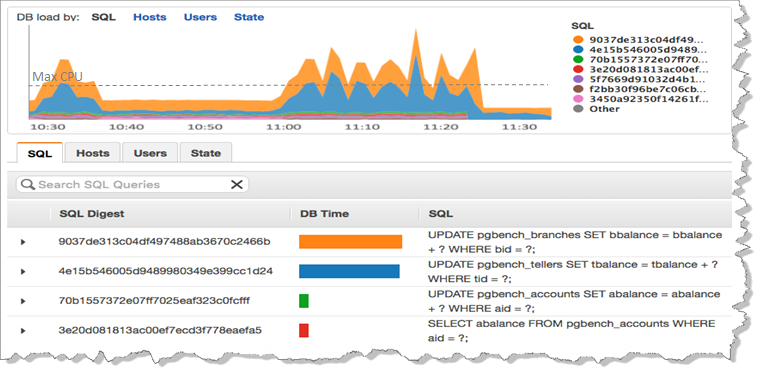
본 미리 보기 기능에 새로운 성능 보고 기능을 포함할 예정이고, 계속해서 관련 소식을 본 블로그를 통해 전달해 드리겠습니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 Amazon Aurora Update – PostgreSQL Compatibility의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
Amazon Rekognition – 딥러닝을 기반한 이미지 탐지 및 인식 서비스
아래 사진이 무엇으로 보이시나요?

당연히 여러분은 동물이라고 인지하실 겁니다. 또한, 애완견으로서 골드리트리버 종이죠. 위의 그림과 이러한 메타 정보가 결합되는 것은 여러분의 뇌에서 바로 인지하기 때문입니다. 이는 여러분이 이미 수백 수천번 이러한 이미지와 데이터 간의 훈련을 통해 학습을 한 것입니다. 이런 방식으로 식물과 동물의 차이, 개와 고양이의 차이 그리고 골드 리트리버와 다른 견종과의 차이를 인지하는 것입니다.
이미지 인식을 위한 딥러닝(Deep Learning)
컴퓨터를 통해 인간과 동일한 수준의 이해력을 요구하는 것은 매우 어려운 작업임이 입증되었습니다. 수십 년 동안 컴퓨터 과학자들이 이 문제에 대해 여러 가지 다른 접근 방식을 취해 왔습니다. 오늘날 이 난제를 해결할 수 있는 가장 좋은 방법은 딥러닝 학습(deep learning)이라는 점에 공감대가 형성되었습니다. 딥러닝은 추상화와 신경망 결합을 사용하여 (Arthur C. Clarke가 말한 것처럼) 마술과 구별할 수 없는 결과를 산출합니다. 그러나 상당한 비용이 듭니다. 첫째, 데이터 훈련 단계에 많은 작업을 투입해야 합니다. 학습 네트워크에 다양한 텍스트 예제 (“this is a dog”, “this is a pet” 등)를 표시하여 이미지의 특징을 라벨과 연관 지어야 합니다. 이 단계에서 신경망의 크기와 다층 적 특성으로 인해 계산 비용이 많이 들게 되는 거죠. 트레이닝 단계가 완료된 후, 트레이닝 네트워크에서 새 이미지가 들어왔을 때 평가하기가 용이합니다. 쉽습니다. 그 결과는 일반적으로 신뢰 수준 (0-100%)으로 표현됩니다. 이를 통해 응용 프로그램에 적합한 정밀성 정도를 결정할 수 있습니다.
Amazon Rekognition 서비스 소개
오늘 Amazon Rekognition 서비스를 공개합니다. 딥러닝 기술을 이용하여 컴퓨터 비전 연구팀이 수 년에 거쳐 수십 억장의 이미지를 매일 훈련 시키는 완전 관리형 서비스입니다. 정확히 훈련된 수 천개의 객체와 장면에 대한 정보를 여러분의 애플리케이션에 사용할 수 있습니다. Rekognition 데모를 통해 사용 방법 및 샘플 코드를 보실 수 있고, 더 자세한 사항은 Rekognition API를 참고하실 수 있습니다.
Rekognition은 확장성을 고려해서 설계되었습니다. 각종 장면, 객체, 얼굴 등을 인식하여 이에 해당하는 레이블(Lavel) 정보를 반환해 주게 됩니다. 이미지에 하나 이상의 얼굴이 포함되어 있다면, 각 얼굴 경계선에 대한 정보를 제공합니다. 아래는 위의 골드 리트리버 이미지에 대한 정보입니다.
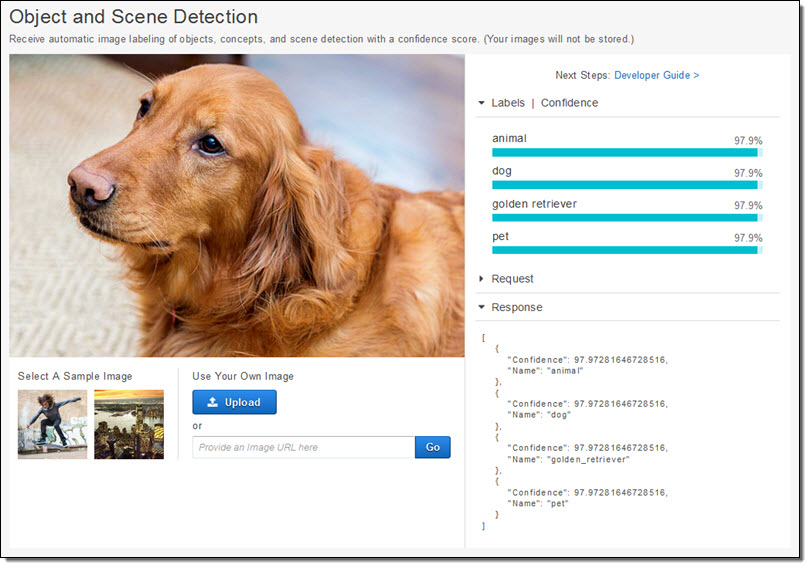
보시다시피 Rekognition을 통해 animal, dog, pet, golden retriever 등의 높은 신뢰 수준의 정보를 제공합니다. 이러한 정보들은 독립적이고 서로 명시적 관계성 없이 각자 딥러닝 모델을 통해 생성되는 것입니다. 예를 들어 개와 동물은 완전히 다른 트레이닝 결과입니다. 다만, Rekognition 결과 중 두 레이블이 동시에 강아지 중심의 훈련 자료에 동시에 나타나기도 합니다.
이제 제 와이프와 제가 찍은 사진을 한번 올려 보겠습니다.
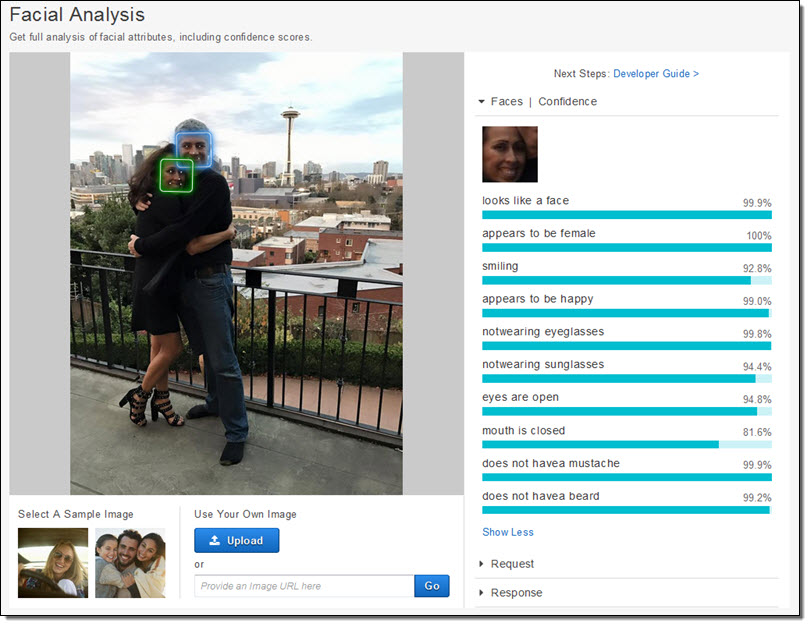
Amazon Rekognition를 통해 두 사람의 얼굴과 경계선을 얻을 수 있습니다. 와이프가 행복한 표정을 짓고 있다는 것도 알려주네요. (이 사진은 와이프 생일날 찍은 것입니다.)
또한, Rekognition는 얼굴을 비교하고 해당 이미지 인식을 요청한 많은 얼굴 중 하나가 포함되어 있는지 확인합니다.
모든 기능은 API 함수를 통해 더 자세하게 제공됩니다. (콘솔에서는 간단한 데모를 보시는데 좋습니다.) 예를 들어, DetectLabels로 첫 번째 예제를 프로그래밍으로 처리하고, 두번째로 DetectFaces를 실행합니다. Rekognition에서 IndexFaces을 여러 번 호출해서 인식할 이미지를 준비시킬 수도 있습니다. 실행 할 때마다, 몇 기지 주요 정보(face vectors)를 이미지에서 추출해서 벡터로 저장하고 이미지를 없앱니다. 하나 이상의 인식용 모음을 만들어서 각각 페이스 벡터의 관련 그룹에 저장할 수 있습니다.
Rekognition는 Amazon Simple Storage Service (S3)에 있는 이미지를 직접 가져올 수도 있습니다. AWS Lambda 함수를 통해 새로 업로드 되는 이미지 인식 작업을 수행할 수 있는데, 이 때 AWS Identity and Access Management (IAM)으로 Rekognition API 접근을 하게 하고 AWS CloudTrail로 API 사용 로그를 남길 수도 있습니다.
Rekognition 애플리케이션
이미지 인식 서비스에 대한 응용 분야는 무궁무진합니다. 만일 많은 사진 정보가 있다면 Amazon Rekognition를 통해 태깅 및 색인 작업을 할 수 있습니다. Rekognition은 클라우드 서비스로서 저장 인프라 설치와 처리 그리고 확장성에 염려할 필요가 없기 때문입니다. 이미지 검색 기능, 태그 기반 브라우징 등 어떤 종류의 대화형 검색 서비스에 적합니다.
또한, 다양한 인증 및 보안 서비스에도 활용할 수 있습니다. 웹캠을 통해 신분증 정보를 확인하거나, 사무실 출입이나 보안 영역 출입 허가를 할 수도 있고, 시각적 감시를 수행하고, 관심 있는 대상 및 사람들을 위해 안면 검사를 할 수도 있습니다. 궁극적으로 영화에 나오는 것 같은 얼굴 인식 정보를 통한 “스마트” 광고판을 만들어 볼 수도 있을 것입니다.
정식 출시
Rekognition은 오늘 부터 US East (Northern Virginia), US West (Oregon), EU (Ireland) 리전에서 서비스를 시작합니다. AWS 프리티어(무료 체험판)을 통해 한달에 5,000개의 이미지는 비용 없이 분석 가능하고 일년에 1,000 개의 페이스 벡터를 저장할 수 있습니다. 그 이상에 대해서는 이미지량과 저장 볼륨에 따라 금액이 책정됩니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 Amazon Rekognition – Image Detection and Recognition Powered by Deep Learning의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
Amazon Polly – 클라우드 기반 24개 언어 47개 음성 합성 서비스
어린 시절 (TV를 많이 보던 때)로 돌아가면, 1960년대와 70년대 매우 유명한 로봇 소리가 다시 기억이 납니다. 특히, HAL-9000, B9 (Lost in Space), 오리지널 Star Trek Computer, 밋 Rosie (The Jetsons)과 같은 영화에서 익숙한 음성이 생각나실 것입니다. 그 때는 기계적으로 생성된 음성이 인간의 감정과 표현을 그대로 재현한다는 것은 불가능하다고 생각했습니다.
세월이 흘러 이제는 컴퓨터가 생성하는 음성을 사용하는 다양한 애플리케이션과 사용 사례가 있고, 흔히 TTS(Text-to-Speech)라고 알려진 음성 합성은 게임, 알림, 이러닝, 화상 통화 및 고객 센터 응대 등에서 많이 활용되고 있습니다. 이러한 애플리케이션 중 상당수는 연결성이 뛰어나고, 로컬 프로세싱 성능 및 스토리지가 최상의 수준인 모바일 환경에 매우 적합합니다.
Amazon Polly 서비스 소개
이러한 사용 사례를 지원하기 위해 오늘 Amazon Polly 서비스를 출시합니다. Polly는 여러분의 애플리케이션 및 도구에서 활용가능한 클라우드 기반 음성 합성 서비스입니다. 현재 47개의 남성 혹은 여성 목소리와 24개 언어를 지원하고, 추가적으로 더 다양한 언어 및 음성을 서비스할 계획입니다.
Polly는 다양한 음성 합성의 기술적 도전을 극복하고 있습니다. 예를 들어, “I live in Seattle”에서 live(리브)와 “Live from New York.”에서 Live(라이브)를 구별합니다. 같은 단어가 다른 맥락에서 사용될 때의 발음 방식에 대해 정보를 가지고 있습니다. “St.”의 경우도 맥락에 따라 “street” 또는 “saint.”로 발음됩니다. 또한, Polly는 단위, 약자, 화폐 단위, 날짜, 시간 등 언어별로 다른 부분에 대해 유연하게 처리합니다.
이를 위해 전문적인 모국어 구사자들과 함께 작업을 하고, 각 언어 구사자들에게 개별 언어 내 무수히 많은 대표적인 단어와 어구를 발음하도록 요청한 다음, 그 오디오를 diphone이라고하는 음원으로 분해합니다.
Polly는 일반 텍스트를 전달 받아, 문맥과 내용에 따라 가장 정확하고 자연스러운 음성을 오디오 파일로 전환하여 스트리밍으로 제공하게 됩니다. 좀 더 다양한 기능을 추가하고 싶다면, SSML (Speech Synthesis Markup Language) 정보를 제공할 수 있습니다. 예를 들어, 하나의 문장에 영어와 프랑스어 단어가 섞여 있다던지, 어구 강조를 한다던지 하는 부분에 대한 SSML 의미적 태깅을 통해 음성이 달리 변환됩니다.
본 블로그에 음성 파일을 임베딩할 수 없지만, Polly Console에 가셔서, 여러분이 원하는 텍스트를 직접 입력 한 후 Listen to speech를 눌러 들을 수 있습니다.
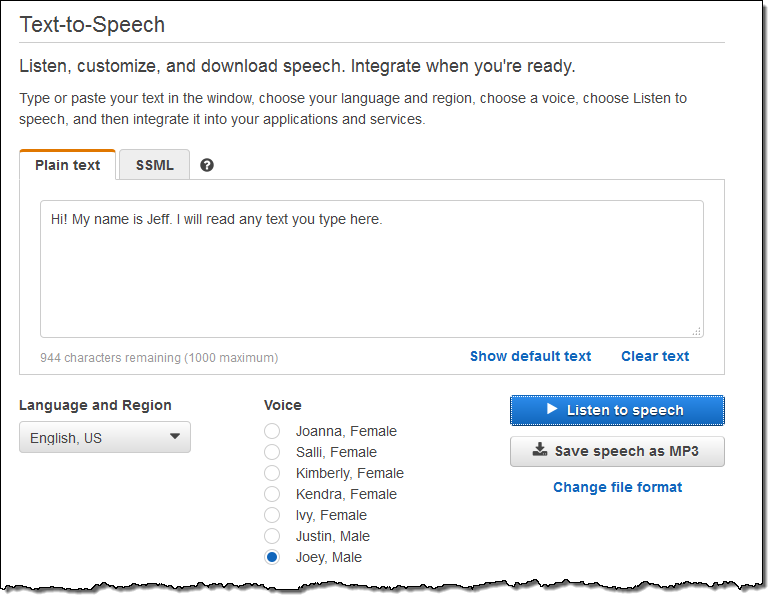 MP3 파일로 저장하여 애플리케이션에서 사용할 수 있습니다.
MP3 파일로 저장하여 애플리케이션에서 사용할 수 있습니다.
Language and Region 메뉴를 누르면, 지원 하는 언어 및 국가를 보실 수 있습니다.
API 및 기술적 세부 정보
Polly 콘솔 뿐만 아니라 다양한 방식으로 자유롭게 서비스를 이용하려면, 텍스트 및 SSML을 SynthesizeSpeech API로 호출 하면 됩니다. 결과를 사용자에게 스트리밍으로 전달하거나, MP3 혹은 OGG 파일로 생성해서 원할 때 제공할 수 있습니다. MP3 또는 Vorbis 포맷의 고품질 오디오 (최대 22 kHz 샘플링) 및 PCM 포맷의 전화 음성 (8 kHz)을 지원합니다.
AWS Command Line Interface (CLI) 를 사용할 수도 있습니다.
$ aws polly synthesize-speech \
--output-format mp3 --voice-id Joanna \
--text "Hello my name is Joanna." \
joanna.mp3Polly는 모든 전송 데이터를 SSL을 통해 암호화 합니다. 제공된 텍스트는 Polly의 성능을 유지하기 위해 6개월까지 암호화 된 상태로 저장됩니다.
정식 출시 및 가격
Amazon Polly는 월 5백만자 까지 무료로 제공됩니다. 그 이상의 경우, 한 자당 $0.000004 per 또는 제작된 오디오 분당 $0.004로 과금 됩니다. 본 블로그의 영문 포스트의 경우, 약 $0.018 이고, Adventures of Huckleberry Finn이라는 책 원문 전체는 약$2.4 정도 됩니다.
Polly는 US East (Northern Virginia), US West (Oregon), US East (Ohio), EU (Ireland) 리전에서 지금 바로 사용할 수 있습니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 Polly – Text to Speech in 47 Voices and 24 Languages의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
Amazon Lex – 대화형 음성 및 텍스트 인터페이스 개발 서비스
컴퓨터를 통해 말하도록 하는 것도 좋지만, 사람의 소리를 듣고 반응하는 것은 훨씬 색다릅니다. Amazon Echo를 사용해 보셨다면, Alexa 기반 상호 작용 모델이 얼마나 간단하고, 유용하며, 강력한지 알 수 있습니다.
저희는 대화형 프로그램에서 Amazon Alexa를 사용할 수 있도록 동일한 딥러닝 기술 즉 ASR(자동 음성 인식) 및 NLU(자연어 이해) 등을 만들고 있습니다. 오늘 공개하는 Amazon Lex 를 사용하여 채팅봇 및 다양한 유형의 모바일 웹앱을 제작할 수 있습니다. 매력적이고 생생한 상호 작용을 지원하는 모바일 애플리케이션. 채팅봇을 통해 정보를 제공하고, 애플리케이션과 업무 환경에 상호 소통 기능 추가, 로봇, 드론 및 장난감에 대한 제어 메커니즘을 제공 할 수 있습니다.
Amazon Lex를 통해 바로 시작할 수 있습니다. Lex Console에서 대화 방식을 설계하고, Lex에 자연어 처리 모델을 작성하는 데 필요한 몇 가지 샘플 구문을 제공합니다. 그런 다음 Amazon Lex봇을 공개하여 사용자와 텍스트 또는 음성 대화를 처리할 수 있습니다. Amazon Lex는 완전 관리형 서비스이므로 모든 인프라를 설정하고 관리 또는 확장하는 데 시간을 낭비 할 필요가 없습니다.
여러분이 챗봇을 만들면 Facebook Messenger 에 오늘 바로 연결할 수 있습니다. Slack 및 Twilio와의 통합도 마찬가지입니다. AWS 측면에서는 AWS Lambda, AWS Mobile Hub, Amazon CloudWatch를 사용합니다. 또한 데이터 저장 및 인증을 위해 Amazon DynamoDB, Amazon Cognito 및 기타 서비스를 이용할 수 있습니다.
Amazon Lex를 사용하면 AWS Lambda 함수를 사용하여 엔터프라이즈급 응용 프로그램 및 데이터 연결을 포함하여 챗봇용 비즈니스 로직을 구현할 수 있습니다. 얼마전 공개한 AWS Mobile Hub의 SaaS 통합 방식과 함께, 이미 사용중인 SaaS 애플리케이션에 저장된 계정, 연락처, 리드(Lead) 정보 및 기타 엔터프라이즈 데이터에 대하여 대화식 인터페이스를 제공하는 높은 생산성을 제공하는 채팅봇을 구축 할 수 있습니다.
이들을 통합하여 모바일 응용 프로그램에서 시작하여 비지니스 로직까지 완벽히 조합된 통합 솔루션을 구축하는 데 필요한 모든 레고 블럭을 사용할 수 있습니다.
Amazon Lex의 기본 개념
잠시 Amazon Lex에서 사용하는 기본 개념들을 알아보겠습니다.
- Bot – 봇은 대화의 모든 구성 요소를 포함합니다.
- Intent – 봇 사용자가 달성하고자 하는 목표를 나타냅니다 (예를 들어, 비행기 표를 구입하거나, 예약하거나 일기 예보를 받기 등.)
- Utterance – 의도를 실행하도록 하는 단어 또는 입력된 구문 입니다. “호텔을 예약하고 싶어”또는 “꽃 주문해줘”는 와 같은 것입니다.
- Slots – 각 슬롯은 사용자 의도를 수행하기 위해 제공해야 하는 작은 데이터입니다. 여행용 봇이라면 도시, 주 또는 공항 정보를 목록화 한 후 이용할 수 있습니다.
- Prompt – 사용자가 의도를 수행하는 데 필요한 일부 데이터 (슬롯 용)를 제공하도록 요청하는 질문입니다.
- Fulfillment – 사용자의 의도를 전달하는 비즈니스 로직입니다. Lex 결과 제공을 위해 람다 함수 사용을 지원합니다.
Bots, intents, slots은 여러 개발 환경에서 코딩, 테스트, 스테이지 서버 배포 및 정식 서비스 간에 명확한 선을 그릴 수 있도록 각각 버전을 지정할 수 있습니다. 각 봇에 대해 여러 개의 별칭을 만들어 특정 버전의 구성 요소에 매핑 할 수 있습니다.
채팅 봇 만들어 보기
Lex 봇을 정의하고 Lex 콘솔에서 모든 구성 요소를 설정할 수 있습니다. 샘플 중 하나를 시작하거나 사용자 정의 봇을 만들 수 있습니다.
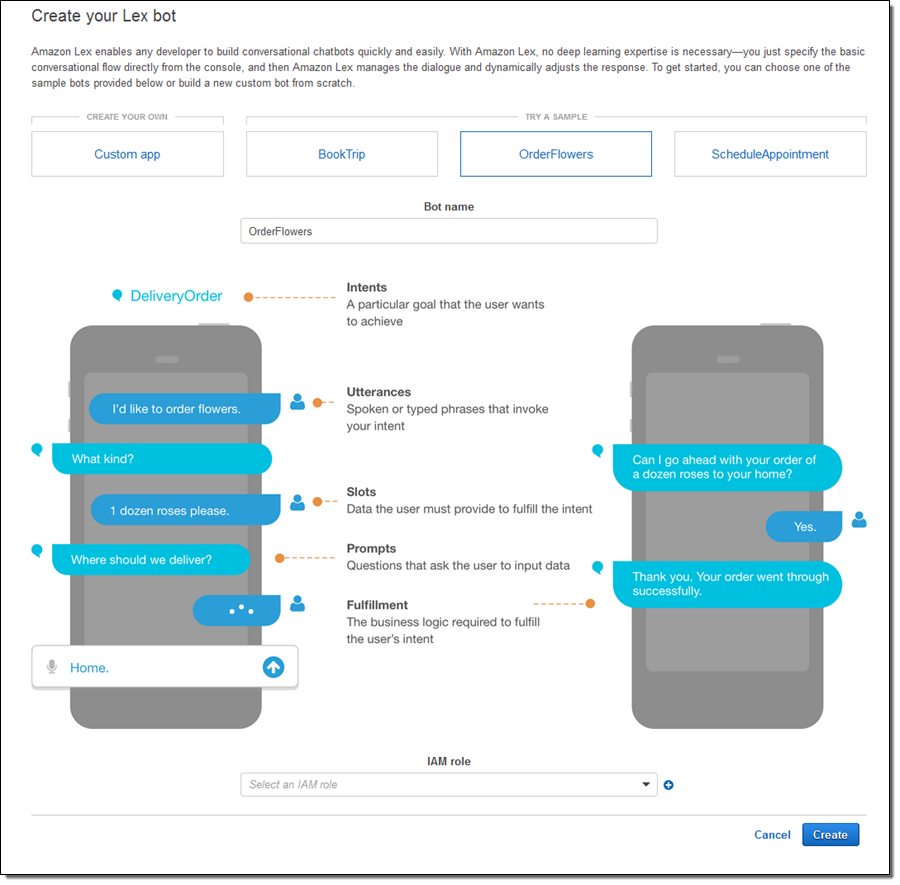
원하는 utterances 및 관련 slots을 설정할 수 있습니다.
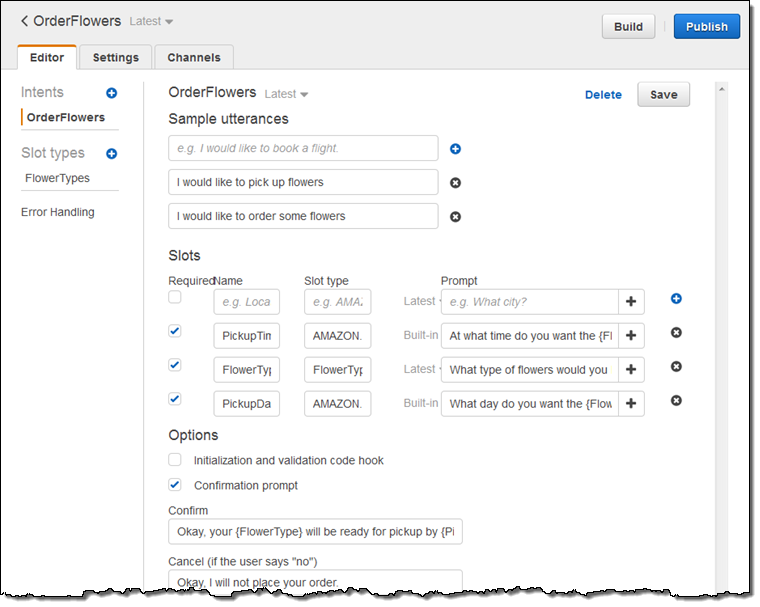
각종 맞춤 설정을 할 수 있습니다.
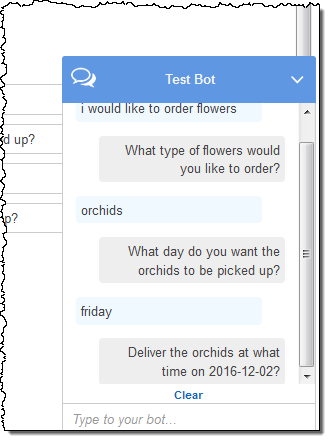
대화 방식으로 잘 작동하는지 봇을 테스트하고 수정할 수 있습니다.
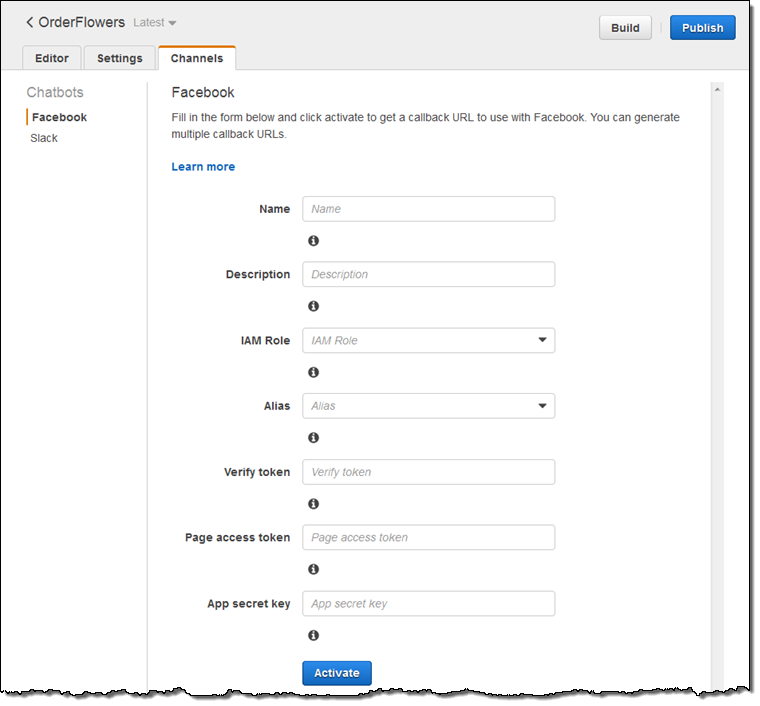
Facebook (및 기타 연결 앱)에서 사용할 콜백 URL을 생성 할 수 있습니다.
좀 더 자세한 사항은 re:Invent 행사가 끝나고 나서 좀 더 자세하게 알려드리겠습니다.
정식 출시 및 가격
Amazon Lex 은 US East (Northern Virginia) 리전에서 미리 보기 기능으로 오늘 출시합니다.
미리 보기 등록 후, 첫 12개월 동안 월 10,000번의 텍스트 요청 및 5,000회 음성 요청을 프리티어로 제공합니다. 그 이후 부터는 1,000 음성 요청 당 $4.00와 1,000 텍스트 요청당 $0.75 입니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 Amazon Lex – Build Conversational Voice & Text Interfaces의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.
Amazon Athena – 초단위 페타바이트급 동적 데이터 질의 서비스
(과거 1.44MB 플로피 디스크를 썼던 경험이 무색하게) 매일 우리는 매우 빠른 데이터량 성장에 놀라게 됩니다. 일상적으로 대량의 로그를 쌓고 질의하는 작업과 정형 혹은 반정형 데이터의 크기는 이미 페타바이트 규모입니다. 우리는 데이터의 위치를 찾아 로딩한 후 인덱싱을 통해 검색하는 일련의 과정을 빠르게 작업할 수 있는 방법을 찾고 있습니다. 이를 위해 높은 수준의 클라우드 솔루션을 가지고 있으며 모든 것이 수 분안에 처리될 수 있습니다.
Amazon Athena 소개
Amazon Athena는 Amazon S3에 저장되어 있는 페타데이터 규모의 데이터를 별도의 클러스터 구성 및 관리를 하지 않더라도 동적 질의를 할 수 있는 신규 서비스입니다. Amazon S3에 위치한 데이터를 지정만 하면, 내부 필드를 자동으로 인지해서 질의를 수행할 수 있습니다. 데이터를 옮기거나 별도 인덱스를 구성할 필요 없이 한 곳에서 할 수 있습니다.
Athena는 동적 질의 편집기를 통해 여러분이 손쉽게 작업을 할 수 있도록 도움을 주고 있으며, 표준 ANSI SQL 및 JOIN, 윈도 함수 등 고급 기능을 수행할 수 있습니다. Athena는 페이스북이 공개한 Presto를 기반으로 대부분 DDL (Data Definition Language)을 포함하는 PrestoSQL 역시 지원합니다.
Athena 서비스에 이면에서는 여러분이 보낸 질의를 병렬적으로 수백 또는 수천개의 코어를 통해 작업하여 결과를 (동적 혹은 JDBC/ODBC 커넥터를 통해) 초단위로 제공합니다.
Athana가 S3에 저장된 데이터를 직접 참조함으로서, 확장성 및 유연성 그리고 데이터 내구성, 데이터 보호 관점에서 이점을 얻을 수 있습니다. 예를 들어 KMS를 기반한 서버사이드 암호화를 통해 데이터 접근을 위해 IAM 정책을 정할 수 있습니다.
또한, Apache 로그, CSV, TSV, 일반 텍스트, JSON, Orc, Parquet 등 다양한 데이터 포맷을 지원할 뿐만 아니라 하나 이상의 S3 객체를 테이블로 지정할 수 있습니다. 각 Athena 데이터베이스는 하나 이상의 테이블로 구성되어 있는데 카탈로그 매니저를 통해 데이터 소스를 파악하고 추적할 수 있습니다.
Athena 사용해 보기
AWS 관리 콘솔을 통해 Amazon Athena 서비스를 선택하면, 아래와 같이 질의 편집기를 처음 보실 수 있습니다.
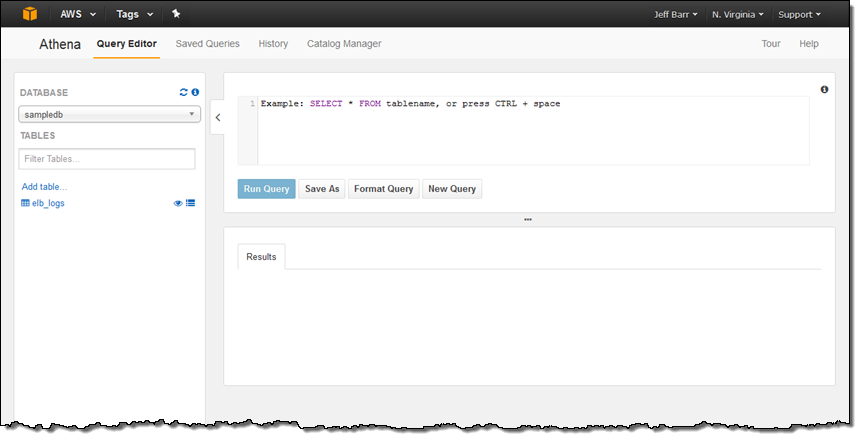
저의 계정은 이미 샘플 데이터베이스를 설정을 하였고, 데이터 베이스 내에는 elb_logs라는 테이블이 있습니다. 이제 간단한 질의문를 선택해서 Run Query를 누르면 됩니다. 몇 초 안에 결과가 바로 콘솔에 보이는 것을 보실 수 있습니다. 이제 결과를 CSV 파일 형태로 다운로드 할 수도 있습니다.
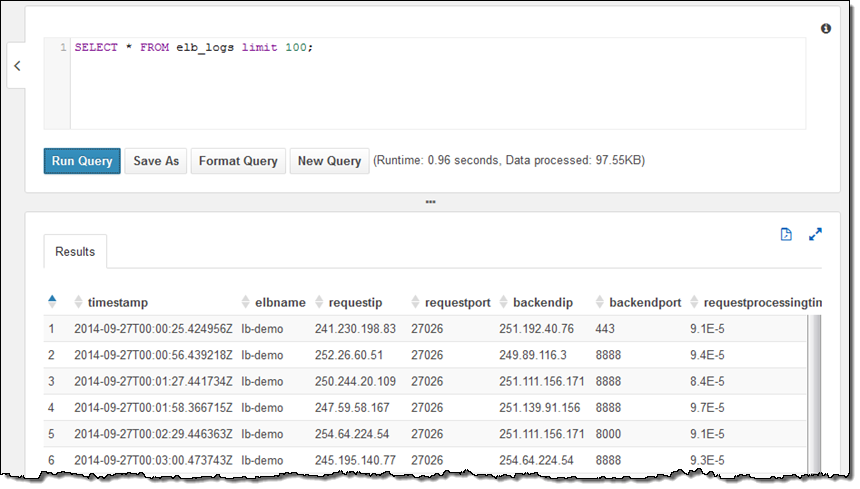
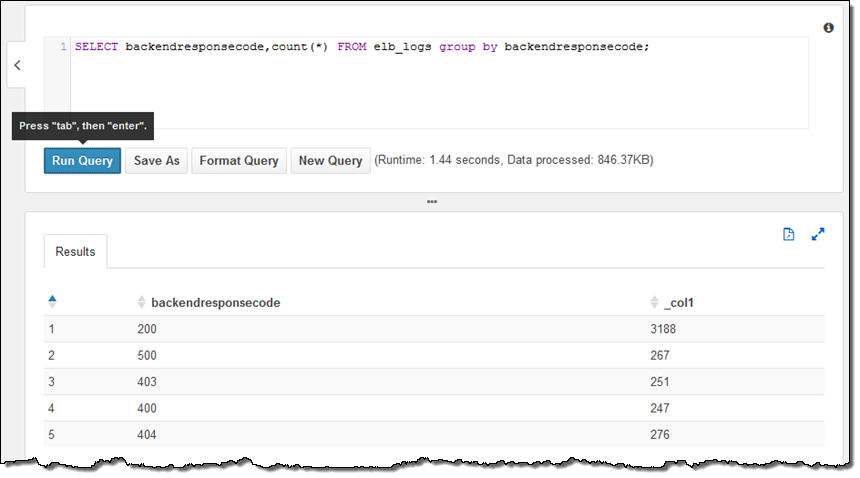
샘플 테이블은 Elastic Load Balancing의 로그 파일로서 HTTP 상태 코드로 분석할 수 있습니다.
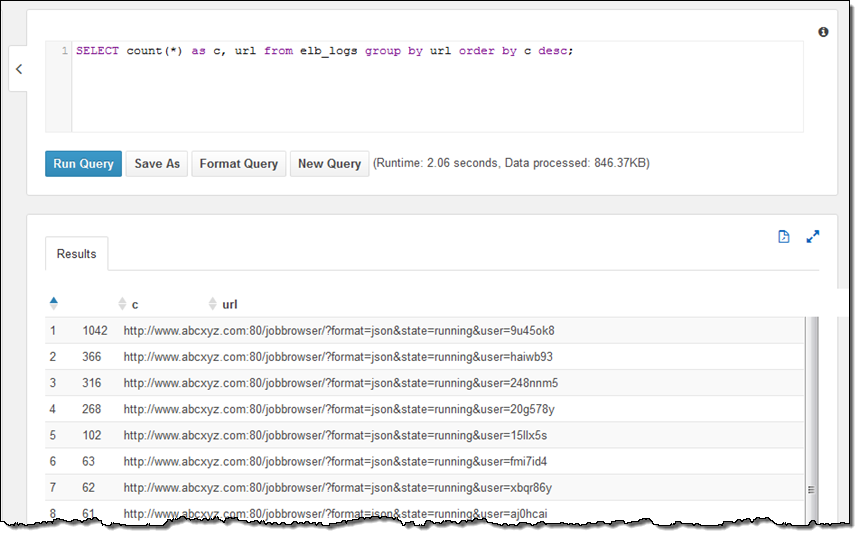
URL은 아래와 같습니다.
테이블 정의 지점은 S3 버킷이고 버킷 내 모든 객체를 encompass 합니다. 만일 새로운 로그 파일이 동적 세션에 들어오게 되면, 자동으로 순서에 따라 질의가 포함됩니다. (테이블 정의에 대해서는 아래에서 설명하겠습니다.)
콘솔에서 테이블 설명을 하기 위한 질의문을 실행 해보겠습니다. 그리고, 테이블과 필드명을 선택해서 질의에 값을 넣을 수 있습니다.
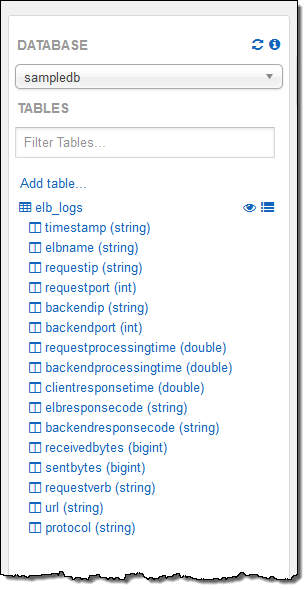
질의문을 저장하여 제가 원하는 작업을 마칩니다.
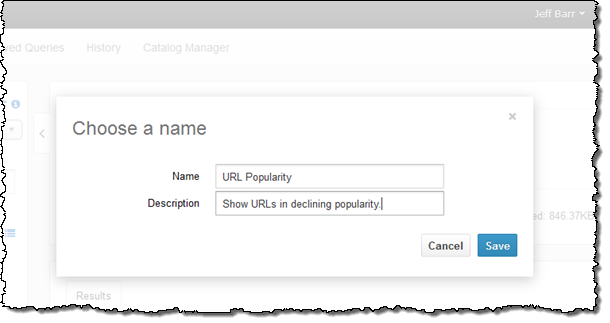
다음으로는 어떻게 데이터베이스를 만들고, 직접 데이터를 참조시키는지에 대해 배워 보겠습니다. 여기에는 두 가지 방법이 있습니다. 하나는 DDL 정의를 하는 것과 단계적 마법사 기능입니다. 동료로 부터 아래와 같은 간단한 샘플 DDL을 받았습니다.
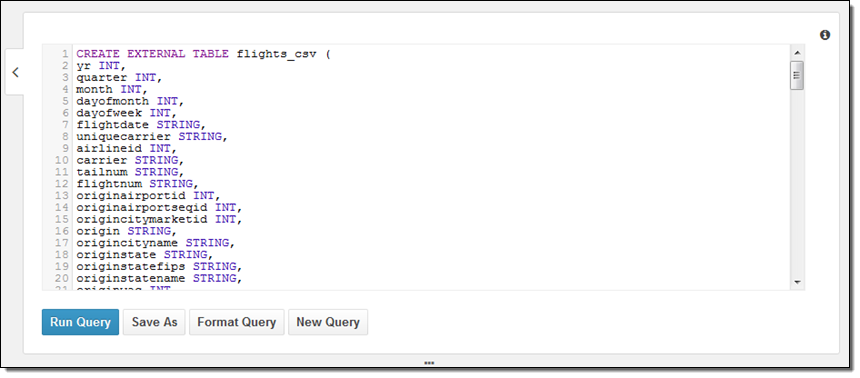
더 관심 있는 것은 질의문이구요. 아래와 같이 구성할 수 있습니다.
PARTITIONED BY (year STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION 's3://us-east-1.elasticmapreduce.samples/flights/cleaned/gzip/';
데이터는 연간으로 분리되어 있기 때문에, 메타 데이터 설정을 마무리하기 위해 아래 부속 질의를 하나 더 해야 합니다.
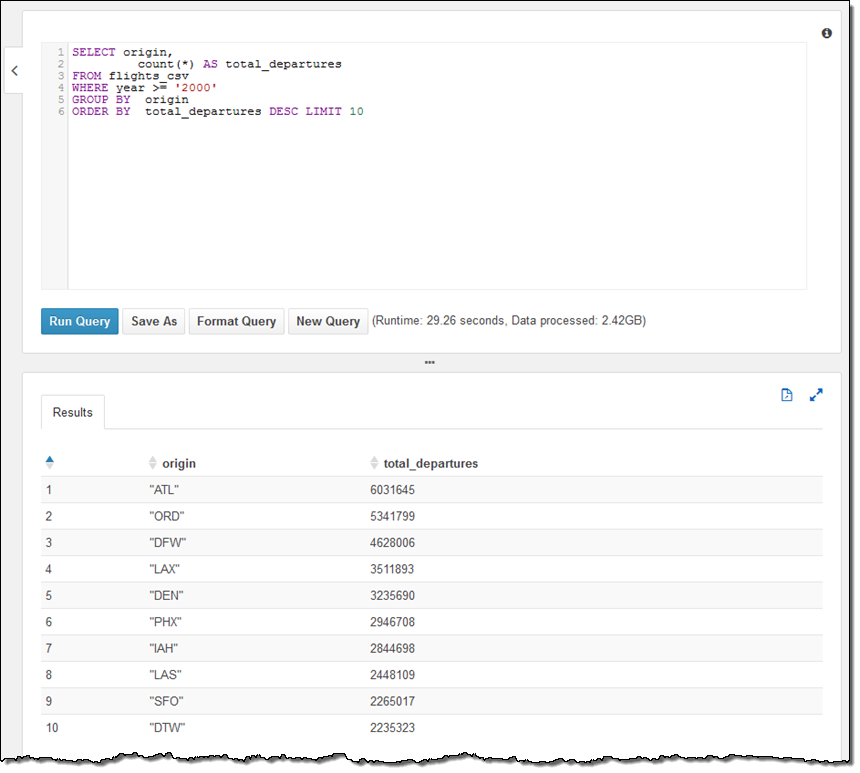
MSCK REPAIR TABLE flights_csv;위 예제는 2000년 부터 지금까지 가장 인기 있는 출발 공항이 있는 도시 10개를 추출하는 질의문입니다.
또한, Athena가 제공하는 테이블 마법사를 통해 (Catalog Manager에서 접근 가능) 테이블을 생성할 수 있습니다. 이 경우, 테이블 이름과 원하는 위치를 지정해주면 됩니다.
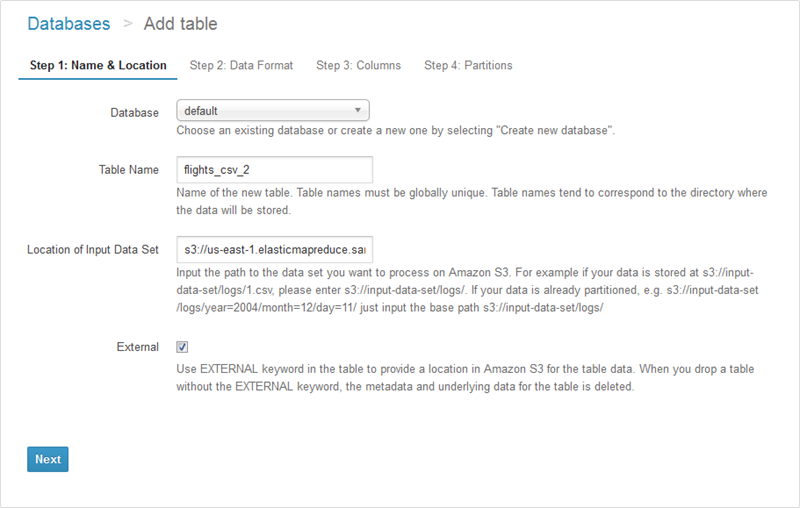
그다음 포맷을 지정합니다.
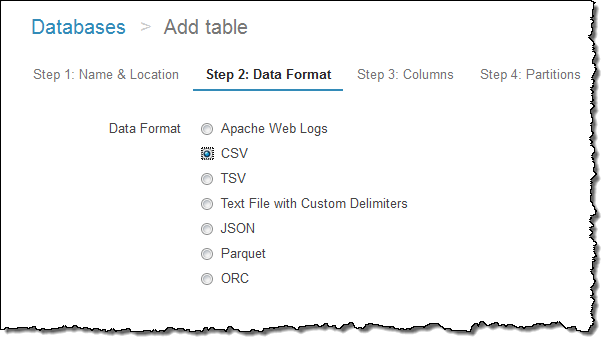
각 컬럼의 이름과 형식을 지정합니다.
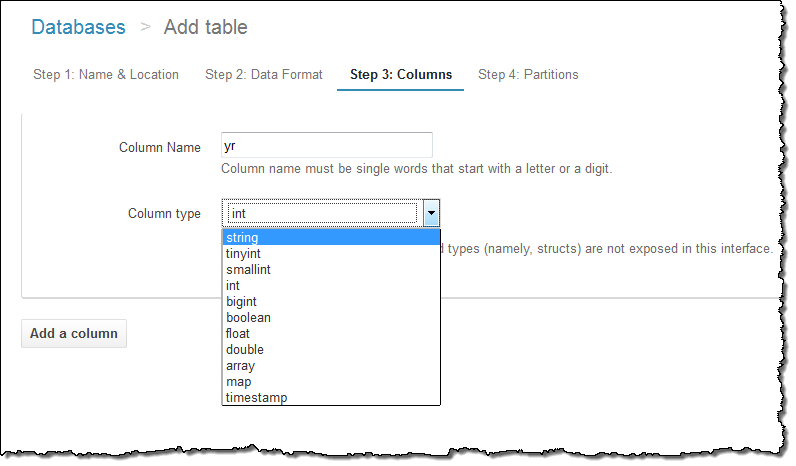
파티션 모델을 지정합니다.
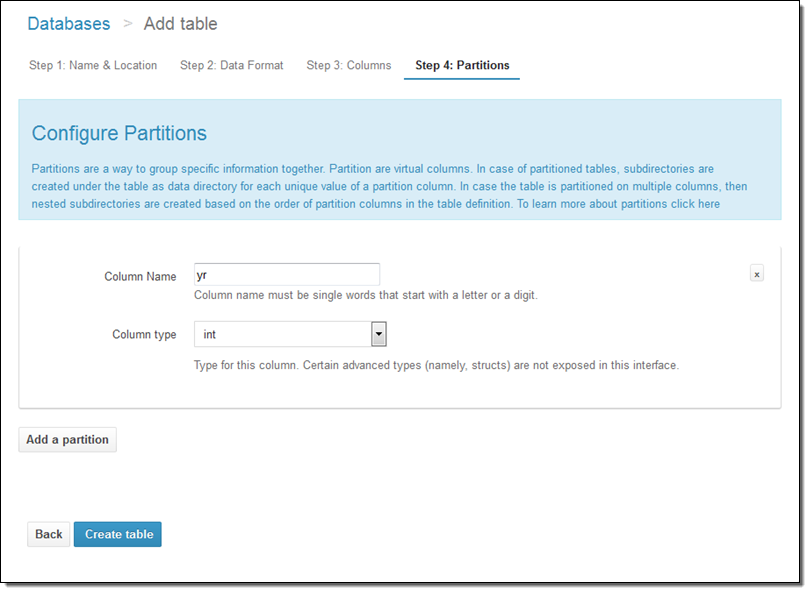
Athena는 그 밖에도 많은 신선한 기능이 있는데, 향후에 더 자세히 알려드릴려고 합니다. 우선 그 중에서도 질의 저장 기능, 질의 기록, 및 Catalog Manager에 대해서만 잠깐 살펴 보겠습니다.
앞에서 보셨다시피 Saved Queries를 누르면, 질의 시 저장했던 질의문을 모두 보실 수 있습니다.
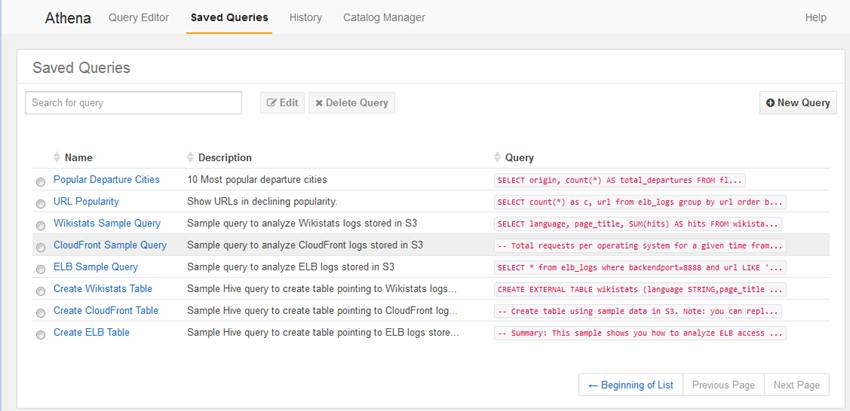
그대로 사용할 수도 있고, 편집해서 다시 질의할 수도 있습니다.
History를 누르면, 이전 질의 기록 뿐만 아니라 생성된 데이터 다운로드도 가능합니다.
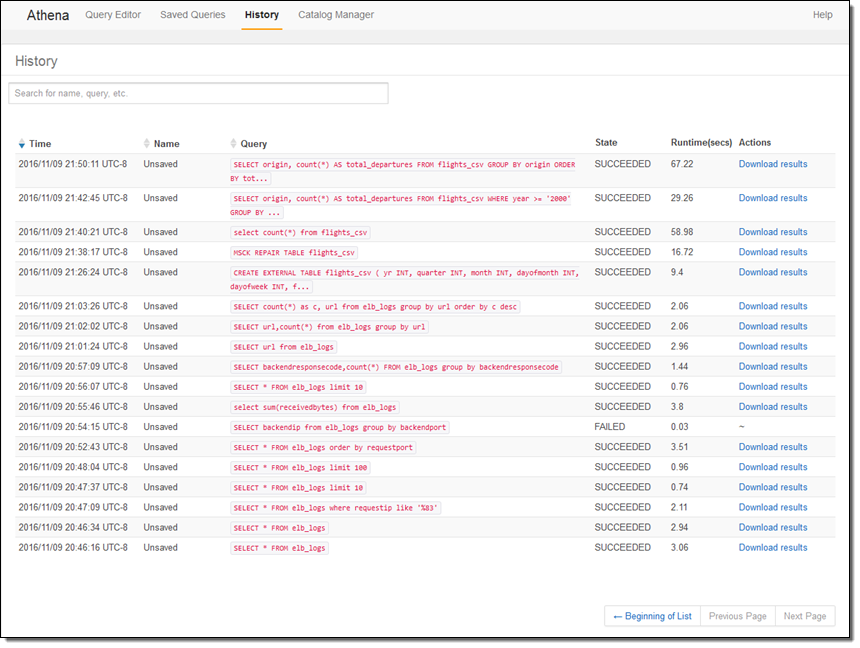
Catalog Manager에서는 기존 데이터베이스 및 신규 데이테베이스 및 테이블 생성이 가능합니다.
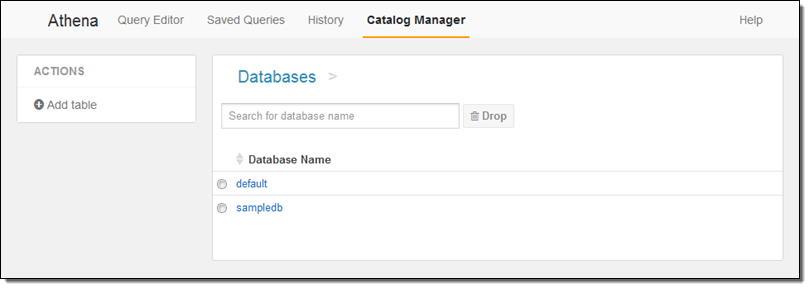
이 블로그 글에서 주로 화면으로 보이는 동적 기능 측면만 언급했지만, JDBC나 ODBC 커넥터를 통해 여러분이 지금 사용중인 비지니스 인텔리전스 분석 도구와 결합할 수 있다는 점을 염두해 주시기 바랍니다.
정식 출시
Amazon Athena는 US East (Northern Virginia), US West (Oregon), EU (Ireland)에 오늘 정식 출시합니다. (다른 AWS 리전에 대해서는 가능한 빠르게 출시가 가능하도록 지속적으로 확대해 나갈 예정입니다.)
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 Amazon Athena – Interactively Query Petabytes of Data in Seconds의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.