AWS Partner Network (APN) Blog
Best Practices from Provectus for Migrating and Optimizing Amazon EMR Workloads
By Daria Koriukova, Data Solutions Architect – Provectus
By Artur Zaripov, Data Engineer – Provectus
By Alexey Zavialov, Sr. Data Solutions Architect – Provectus
By Kalen Zhang, Global Tech Lead, Partner Solutions Architect – AWS
 |
| Provectus |
 |
As more businesses look to technologies like artificial intelligence (AI), machine learning (ML), and predictive analytics to drive outcomes, they seek to migrate on-premises Apache Spark/Hadoop workloads to the cloud.
Wrestling with rising costs, maintenance uncertainties, and administrative headaches, many turn to Amazon EMR to support big data, Apache Spark, and Apache Hadoop environments.
Provectus, an AWS Premier Tier Services Partner with the Data and Analytics Competency, helps clients resolve issues of their legacy, on-premises data platforms by implementing best practices for the migration and optimization of Amazon EMR workloads. Provectus is also an Amazon EMR Service Delivery Partner.
This post examines the challenges organizations face along the path to a successful migration, and explores best practices for re-architecting and migrating on-premises data platforms to Amazon Web Services (AWS).
Cloud Migration Approaches
Many enterprises today are planning to migrate their legacy, on-premises enterprise data warehouse (EDW), data lake, and extract, transform, load (ETL) jobs to the cloud. While a “lift-and-shift” approach may work for some, others want to look for ways to optimize their current setup.
Below are some tips for a smooth migration that help identify and leverage the optimization of Apache Hadoop, job scheduling and orchestration, and streaming.
Approach #1: Apache Hadoop
On-premises Apache Hadoop clusters come with storage that’s directly attached to dedicated physical servers, but coupled storage and compute can limit scalability. At times of peak workload, optimally managing concurrency and resource contention is challenging, and at off-peak times, computation resource utilization becomes inefficient.
Migrating Apache Hadoop workloads to AWS using Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Simple Storage Service (Amazon S3) enables storage and compute to scale independently. Amazon EMR on Amazon Elastic Kubernetes Service (Amazon EKS) manages resource limits for different teams and jobs, and improves resource utilization. Amazon EMR Serverless mitigates over- or under-provisioning of resources for Apache Hadoop experiments.
Storage Optimization
Amazon S3 is a scalable, cost-efficient cloud alternative for Hadoop Distributed File System (HDFS). It’s used for similar use cases, provides similar levels of consistency, and easily integrates with various AWS services.
Legacy systems hoard vast amounts of data in HDFS, and it becomes too expensive to use lift-and-shift. But as data departments hastily jump on the data gold rush bandwagon, these data lakes become data swamps that provide little actual value—so cloud migration can be a great opportunity to declutter. The data can be examined, and the parts that are useful, well-governed, clean, and actual can be moved to the cloud.
While sifting out the right data is challenging, tools such as the Open Data Discovery (ODD) platform can help discover data lineage and select necessary data pipelines, to save time and resources.
Here are some tips based on the nature of data, data access patterns, and storage best practices:
- Use data partitioning to improve scalability, reduce contention, and optimize performance.
- Use data compression (Snappy, LZO, BZip2) to optimize storage costs.
- Use specific file formats (Parquet, ORC, Avro) for efficient data storage and retrieval.
- Use EMRFS with an Amazon S3-optimized committer to improve application performance by avoiding list-and-rename operations in S3 (during job and task commit).
- Control the size of output files, avoid small files, and merge them to optimize read operations.
Also consider the specifics of storage on Amazon S3—different S3 buckets, different regions—to provide secure, fast, and cheap access.
Compute Optimization
Typical on-premises workloads include Apache Spark jobs and Apache Hive queries written over several years by different engineers. The obsolete codebase can be revisited and optimized according to modern best practices and cloud elasticity standards.
Here are some tips:
- Control the number of files generated by Apache Spark jobs and Apache Hive queries. Without proper settings, jobs processing will slow down (writing and reading millions of small files for a single task), and excessive S3 limits will trigger “Slow Down” errors.
- Merge the already presented small parts of files into files of optimal size, based on the parameters of the jobs.
- For transient Amazon EMR clusters, split large jobs into smaller ones. For older Amazon EMR versions (<= 5.x), data may be lost during the execution of Apache Spark jobs due to decommissioned nodes, requiring job re-execution.
- Avoid using a fixed start date for the data processing scope, as it leads to an instantly growing execution time. If the data needs to be aggregated over a period starting from a fixed date, pre-aggregate it and use the results for future runs.
- Avoid using
get_json_objectwhen working with JSON data in Apache Hive. It parses on every call, which slows down the query. Usejson_tupleinstead, to parse only once.
Those simple actions will help reduce data pipeline execution time by hours, to lower total cost of ownership (TCO), meet SLAs, and elevate customer experience.
Apache Hadoop Cluster
On-premises infrastructures are usually built around one Apache Hadoop cluster that serves all data processing needs. While this helps reduce support and maintenance costs, it also leads to overcomplicated ETL pipelines that contain long execution chains, with spaghetti-style connections between jobs.
Cloud environments remove the disadvantages of multiple clusters, enabling organizations to split giant clusters into smaller ones. Decoupling of data jobs accelerates and facilitates updates, and makes them less error prone. While migrating from a monolith to multiple services that interact with each other is a good practice, management efforts may slightly increase, but they are compensated for by the advantages.
Based on the organization’s experience, future roadmap, and budget, the jobs can be run on:
- Amazon EMR on EKS: This helps avoid resource contention, a challenge of resource management for intensive workloads (such as high job concurrence) on a cluster. Share compute and memory resources across all applications and use one set of Kubernetes tools to monitor and manage the infrastructure.
- Amazon EMR Serverless: This enables you to automatically provision and manage underlying compute and memory resources.
Approach #2: Job Scheduling and Orchestration
Legacy workload scheduling and automation software can be replaced by modern cloud-native solutions: Amazon Managed Workflows for Apache Airflow (MWAA) and AWS Step Functions.
Managed and serverless services remove the complexities of maintaining the underlying infrastructure and reduce operational costs. Switching frameworks can seem scary because it requires pipeline re-implementation (new abstractions and paradigms), so let’s focus on how to minimize effort while also delivering great return on investment (ROI).
Provectus has seen clients migrating workloads from Luigi or TaskForest to Amazon MWAA, AWS Step Functions, AWS Glue, and AWS Lambda. In some cases, core business logic blocks were intact, being wrapped to the right target envelope of the Airflow Operator or the Lambda function body.
In other cases, Provectus had to migrate hundreds of jobs with complicated topologies. The team automated migration by implementing a code auto generator tool that traversed existing structures to output DAG Python code. That helped minimize migration time and kept the data engineering team happy.
Approach #3: Streaming
In cases when HDFS is populated with clickstreams or transactional data from a relational database management service (RDBMS), there are cloud services that can simplify streaming to a cloud data lake: AWS Database Migration Service (AWS DMS), Amazon Managed Streaming for Apache Kafka (Amazon MSK), and Amazon Kinesis.
AWS DMS helps replicate changes of a source relational database to cloud destinations, like Amazon S3 or Amazon Relational Database Service (Amazon RDS).
On-premises Apache Kafka can be migrated to Amazon MSK. A fully managed service, it builds and runs applications that use Apache Kafka to process streaming data without the overhead of managing Apache Kafka infrastructure. It enables organizations to scale existing clusters by adding additional brokers without affecting cluster availability. In addition, it scales brokers by adding Amazon Elastic Block Store (Amazon EBS) storage without affecting broker availability.
In existing Apache Kafka workloads, events can be seamlessly transitioned from on premises to cloud by using MirrorMaker2. This consumes messages from old clusters and produces the same events in Amazon MSK, to eliminate processing downtime. MirrorMaker2 can be deployed on the EC2 instance, with proper permissions to both clusters.
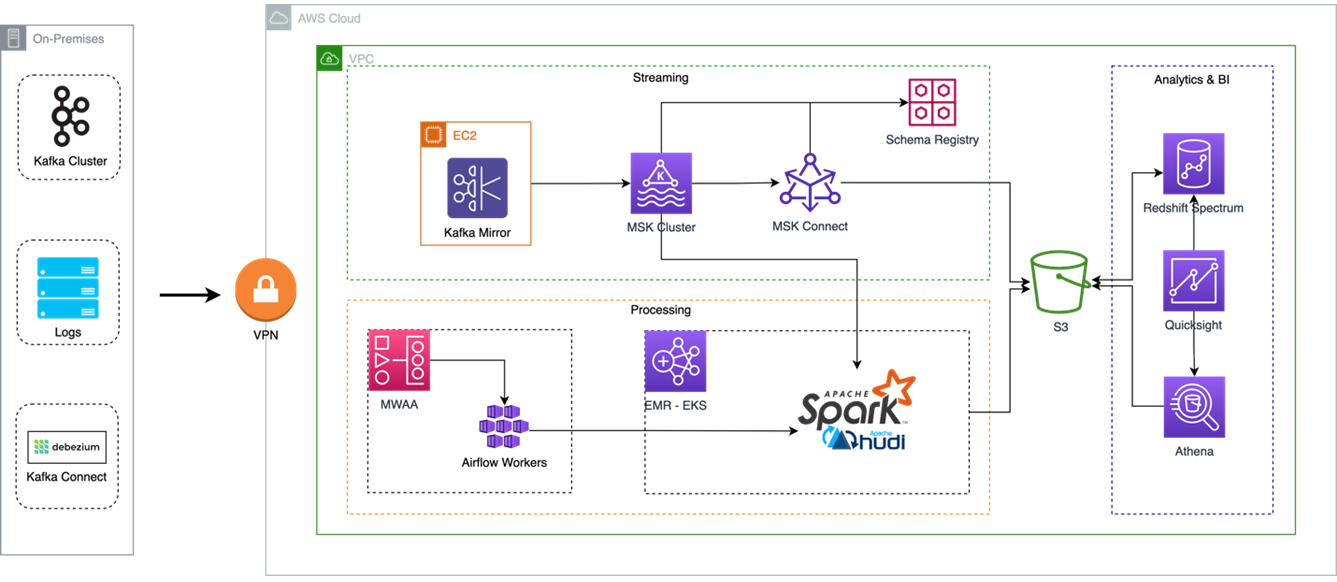
Figure 1 – Provectus big data analytics workloads migration on AWS.
Summary
Migration from on-premises servers to the cloud is a complex process that requires a lot of architecture decisions. Following best practices during the migration is key to success, and crucial for the process overall.
The main benefit of long-term usage, which is growing over time, is eliminating the need for server support. Provectus solutions demonstrate how, with this knowledge, legacy on-premises architecture can be transformed into a modern, scalable, and cost-efficient solution on AWS.
Learn more about the Provectus Amazon EMR migration practice and watch the webinar to dive deep. If you’re interested in migrating and optimizing EMR workloads, apply for Provectus’ Amazon EMR Migration Acceleration Program.
.

.
Provectus – AWS Partner Spotlight
Provectus is an AWS Data and Analytics Competency Partner and AI-first transformation consultancy and solutions provider helping design, architect, migrate, or build cloud-native applications on AWS. Provectus is an Amazon EMR Service Delivery Partner.