AWS Big Data Blog
Category: AWS Glue

Accelerate Amazon Redshift Data Lake queries with AWS Glue Data Catalog Column Statistics
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. In this post, we highlight the performance improvements we observed using industry standard TPC-DS benchmarks. Overall execution time of TPC-DS 3 TB benchmark improved by 3x. Some of the queries in our benchmark experienced up to 12x speed up.

The AWS Glue Data Catalog now supports storage optimization of Apache Iceberg tables
The AWS Glue Data Catalog now enhances managed table optimization of Apache Iceberg tables by automatically removing data files that are no longer needed. Along with the Glue Data Catalog’s automated compaction feature, these storage optimizations can help you reduce metadata overhead, control storage costs, and improve query performance. Iceberg creates a new version called […]

Migrate Delta tables from Azure Data Lake Storage to Amazon S3 using AWS Glue
Organizations are increasingly using a multi-cloud strategy to run their production workloads. We often see requests from customers who have started their data journey by building data lakes on Microsoft Azure, to extend access to the data to AWS services. Customers want to use a variety of AWS analytics, data, AI, and machine learning (ML) […]

Use the AWS CDK with the Data Solutions Framework to provision and manage Amazon Redshift Serverless
In this post, we demonstrate how to use the AWS CDK and DSF to create a multi-data warehouse platform based on Amazon Redshift Serverless. DSF simplifies the provisioning of Redshift Serverless, initialization and cataloging of data, and data sharing between different data warehouse deployments.

Accelerate data integration with Salesforce and AWS using AWS Glue
To meet the demands of diverse data integration use cases, AWS Glue now supports SaaS connectivity for Salesforce. This enables users to quickly preview and transfer their customer relationship management (CRM) data, fetch the schema dynamically on request, and query the data. This post explores the new Salesforce connector for AWS Glue and demonstrates how to build a modern extract, transform, and load (ETL) pipeline with AWS Glue ETL scripts.
Introducing job queuing to scale your AWS Glue workloads
Today, we are pleased to announce the general availability of AWS Glue job queuing. Job queuing increases scalability and improves the customer experience of managing AWS Glue jobs. With this new capability, you no longer need to manage concurrency of your AWS Glue job runs and attempt retries just to avoid job failures due to high concurrency. This post demonstrates how job queuing helps you scale your Glue workloads and how job queuing works.

Copy and mask PII between Amazon RDS databases using visual ETL jobs in AWS Glue Studio
In this post, I’ll walk you through how to copy data from one Amazon Relational Database Service (Amazon RDS) for PostgreSQL database to another, while scrubbing PII along the way using AWS Glue. You will learn how to prepare a multi-account environment to access the databases from AWS Glue, and how to model an ETL data flow that automatically masks PII as part of the transfer process, so that no sensitive information will be copied to the target database in its original form.

Unlock scalable analytics with a secure connectivity pattern in AWS Glue to read from or write to Snowflake
In today’s data-driven world, the ability to seamlessly integrate and utilize diverse data sources is critical for gaining actionable insights and driving innovation. As organizations increasingly rely on data stored across various platforms, such as Snowflake, Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these […]

Implement data quality checks on Amazon Redshift data assets and integrate with Amazon DataZone
In this post, we show how to capture the data quality metrics for data assets produced in Amazon Redshift. With Amazon DataZone, the data owner can directly import the technical metadata of a Redshift database table and views to the Amazon DataZone project’s inventory. As these data assets gets imported into Amazon DataZone, it bypasses the AWS Glue Data Catalog, creating a gap in data quality integration. This post proposes a solution to enrich the Amazon Redshift data asset with data quality scores and KPI metrics.
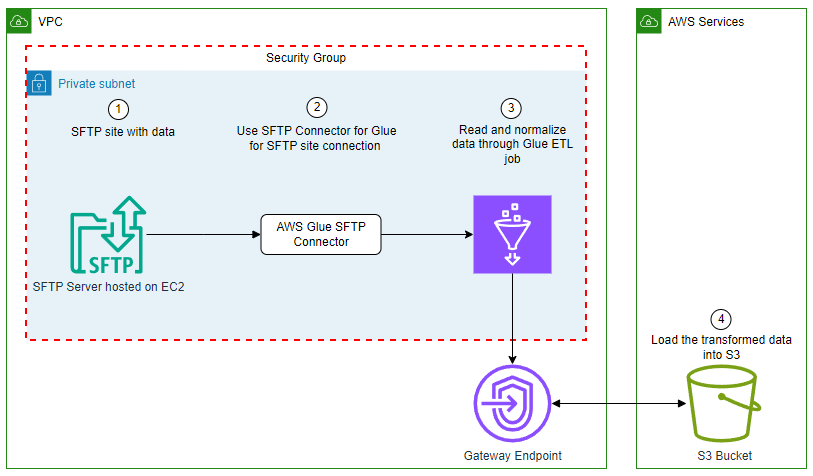
Use AWS Glue to streamline SFTP data processing
In this blog post, we explore how to use the SFTP Connector for AWS Glue from the AWS Marketplace to efficiently process data from Secure File Transfer Protocol (SFTP) servers into Amazon Simple Storage Service (Amazon S3), further empowering your data analytics and insights.