AWS Big Data Blog
Category: AWS Lambda

Setting up automated data quality workflows and alerts using AWS Glue DataBrew and AWS Lambda
Proper data management is critical to successful, data-driven decision-making. An increasingly large number of customers are adopting data lakes to realize deeper insights from big data. As part of this, you need clean and trusted data in order to gain insights that lead to improvements in your business. As the saying goes, garbage in is […]

Best practices for consuming Amazon Kinesis Data Streams using AWS Lambda
November 2024: This post was reviewed and updated for accuracy. Many organizations are processing and analyzing clickstream data in real time from customer-facing applications to look for new business opportunities and identify security incidents in real time. A common practice is to consolidate and enrich logs from applications and servers in real time to proactively […]

Detect change points in your event data stream using Amazon Kinesis Data Streams, Amazon DynamoDB and AWS Lambda
The success of many modern streaming applications depends on the ability to sequentially detect each change as soon as possible after it occurs, while continuing to monitor the data stream as it evolves. Applications of change point detection range across genomics, marketing, and finance, to name a few. In genomics, change point detection can help […]

Building an event-driven application with AWS Lambda and the Amazon Redshift Data API
Event–driven applications are becoming popular with many customers, where applications run in response to events. A primary benefit of this architecture is the decoupling of producer and consumer processes, allowing greater flexibility in application design and building decoupled processes. An example of an even-driven application is an automated workflow being triggered by an event, which […]

Event-driven refresh of SPICE datasets in Amazon QuickSight
Businesses are increasingly harnessing data to improve their business outcomes. To enable this transformation to a data-driven business, customers are bringing together data from structured and unstructured sources into a data lake. Then they use business intelligence (BI) tools, such as Amazon QuickSight, to unlock insights from this data. To provide fast access to datasets, […]
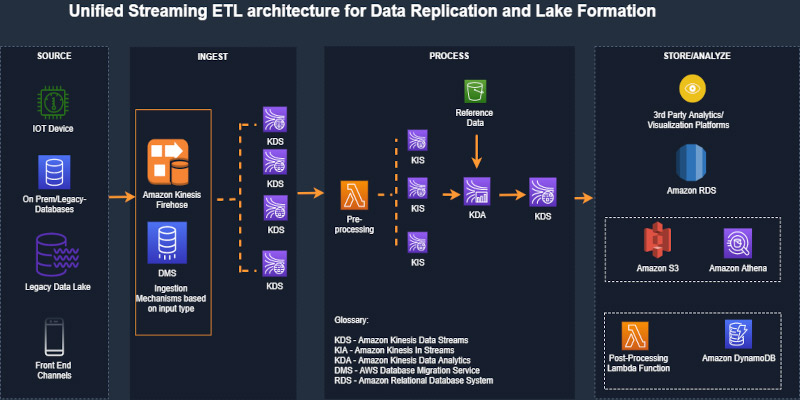
Unified serverless streaming ETL architecture with Amazon Kinesis Data Analytics
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Businesses across the world […]

Automating bucketing of streaming data using Amazon Athena and AWS Lambda
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. In today’s world, data plays a vital role in helping businesses understand and improve their processes and services to reduce cost. You can use several tools to […]
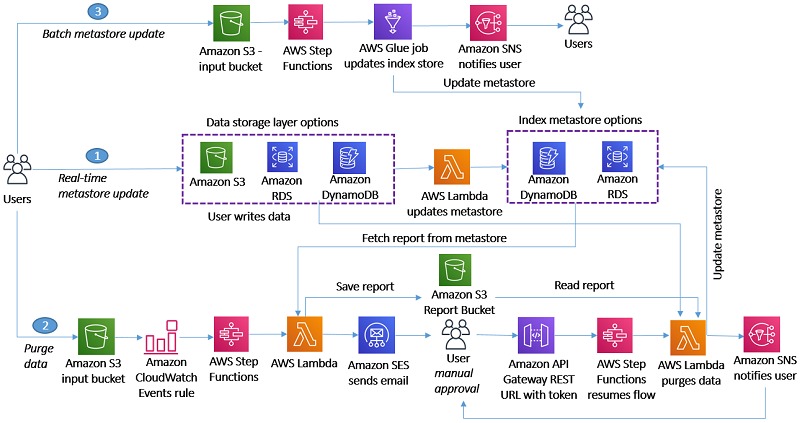
How to delete user data in an AWS data lake
General Data Protection Regulation (GDPR) is an important aspect of today’s technology world, and processing data in compliance with GDPR is a necessity for those who implement solutions within the AWS public cloud. One article of GDPR is the “right to erasure” or “right to be forgotten” which may require you to implement a solution […]
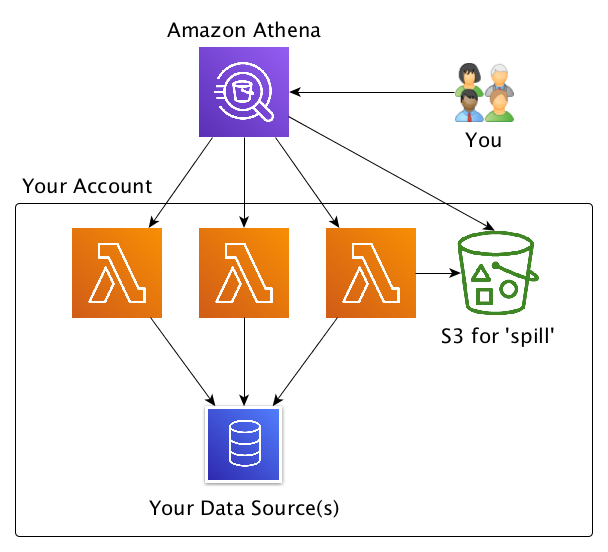
Configure and optimize performance of Amazon Athena federation with Amazon Redshift
This post provides guidance on how to configure Amazon Athena federation with AWS Lambda and Amazon Redshift, while addressing performance considerations to ensure proper use.
Stream, transform, and analyze XML data in real time with Amazon Kinesis, AWS Lambda, and Amazon Redshift
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. When we look at […]