AWS Big Data Blog
Category: *Post Types
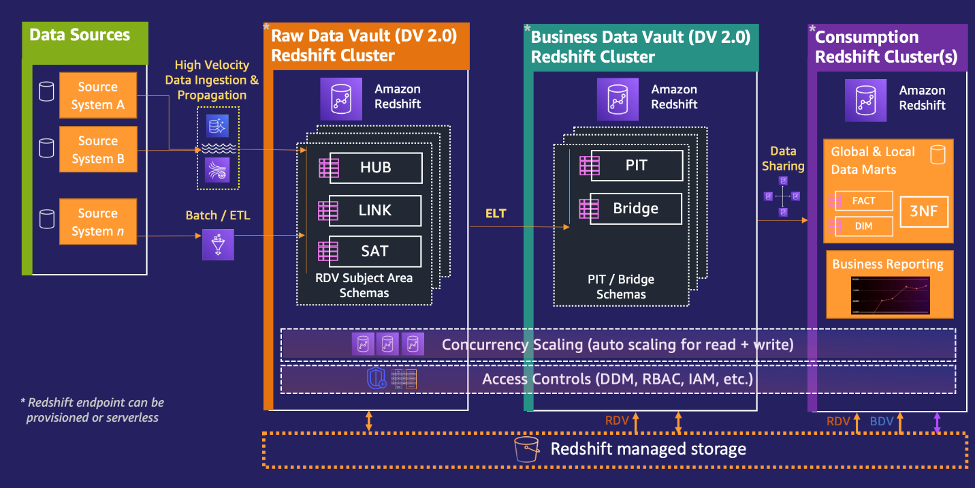
Power enterprise-grade Data Vaults with Amazon Redshift – Part 2
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x better price-performance than any other cloud data warehouses. As with all […]

Decentralize LF-tag management with AWS Lake Formation
In today’s data-driven world, organizations face unprecedented challenges in managing and extracting valuable insights from their ever-expanding data ecosystems. As the number of data assets and users grow, the traditional approaches to data management and governance are no longer sufficient. Customers are now building more advanced architectures to decentralize permissions management to allow for individual […]
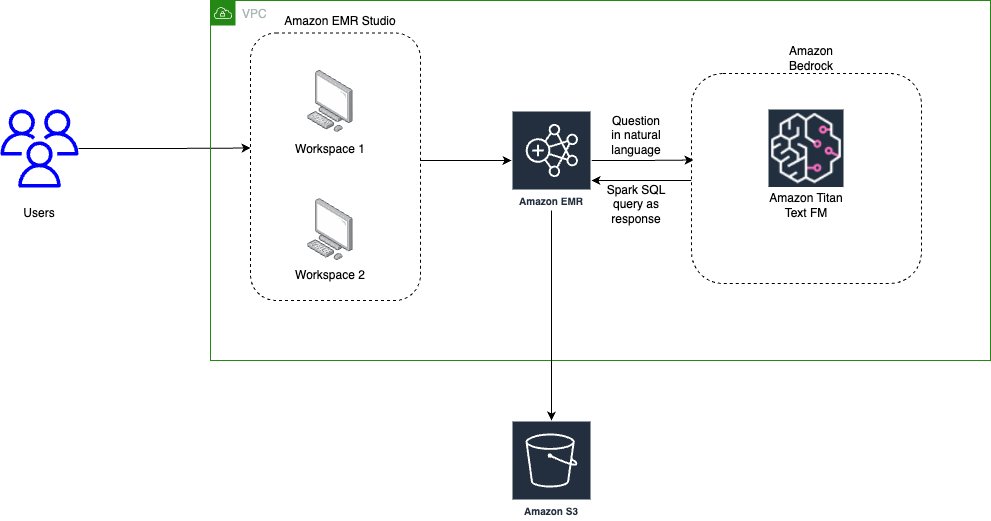
Use generative AI with Amazon EMR, Amazon Bedrock, and English SDK for Apache Spark to unlock insights
In this era of big data, organizations worldwide are constantly searching for innovative ways to extract value and insights from their vast datasets. Apache Spark offers the scalability and speed needed to process large amounts of data efficiently. Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine […]

BMW Cloud Efficiency Analytics powered by Amazon QuickSight and Amazon Athena
This post is written in collaboration with Philipp Karg and Alex Gutfreund from BMW Group. Bayerische Motoren Werke AG (BMW) is a motor vehicle manufacturer headquartered in Germany with 149,475 employees worldwide and the profit before tax in the financial year 2022 was € 23.5 billion on revenues amounting to € 142.6 billion. BMW Group is one of the […]

Implement Apache Flink real-time data enrichment patterns
You can use several approaches to enrich your real-time data in Amazon Managed Service for Apache Flink depending on your use case and Apache Flink abstraction level. Each method has different effects on the throughput, network traffic, and CPU (or memory) utilization. For a general overview of data enrichment patterns, refer to Common streaming data enrichment patterns in Amazon Managed Service for Apache Flink. This post covers how you can implement data enrichment for real-time streaming events with Apache Flink and how you can optimize performance. To compare the performance of the enrichment patterns, we ran performance testing based on synthetic data. The result of this test is useful as a general reference. It’s important to note that the actual performance for your Flink workload will depend on various and different factors, such as API latency, throughput, size of the event, and cache hit ratio.

Clean up your Excel and CSV files without writing code using AWS Glue DataBrew
Managing data within an organization is complex. Handling data from outside the organization adds even more complexity. As the organization receives data from multiple external vendors, it often arrives in different formats, typically Excel or CSV files, with each vendor using their own unique data layout and structure. In this blog post, we’ll explore a […]

How Wallapop improved performance of analytics workloads with Amazon Redshift Serverless and data sharing
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it straightforward and cost-effective to analyze all your data at petabyte scale, using standard SQL and your existing business intelligence (BI) tools. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift. Amazon Redshift Serverless makes it effortless to run and […]
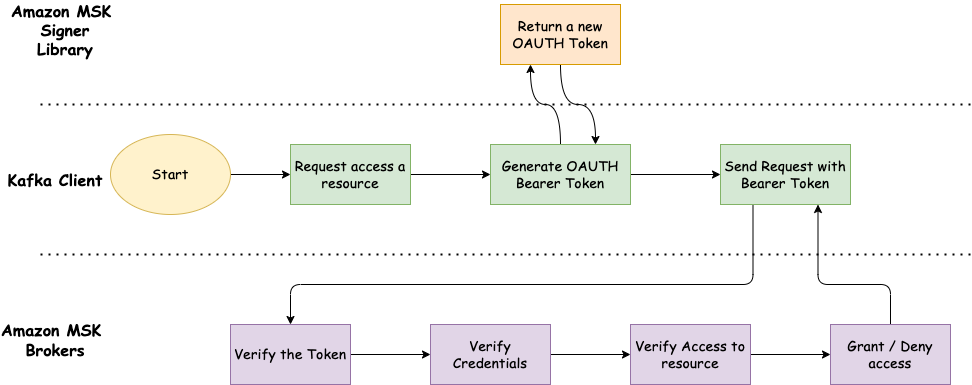
Amazon MSK IAM authentication now supports all programming languages
The AWS Identity and Access Management (IAM) authentication feature in Amazon Managed Streaming for Apache Kafka (Amazon MSK) now supports all programming languages. Administrators can simplify and standardize access control to Kafka resources using IAM. This support is based on SASL/OUATHBEARER, an open standard for authorization and authentication. Both Amazon MSK provisioned and serverless cluster […]

How Gameskraft uses Amazon Redshift data sharing to support growing analytics workloads
This post is co-written by Anshuman Varshney, Technical Lead at Gameskraft. Gameskraft is one of India’s leading online gaming companies, offering gaming experiences across a variety of categories such as rummy, ludo, poker, and many more under the brands RummyCulture, Ludo Culture, Pocket52, and Playship. Gameskraft holds the Guinness World Record for organizing the world’s […]

Simplifying data processing at Capitec with Amazon Redshift integration for Apache Spark
This post is co-written with Preshen Goobiah and Johan Olivier from Capitec. Apache Spark is a widely-used open source distributed processing system renowned for handling large-scale data workloads. It finds frequent application among Spark developers working with Amazon EMR, Amazon SageMaker, AWS Glue and custom Spark applications. Amazon Redshift offers seamless integration with Apache Spark, […]