AWS Big Data Blog
Tag: AWS Glue

Modernize your legacy databases with AWS data lakes, Part 2: Build a data lake using AWS DMS data on Apache Iceberg
This is part two of a three-part series where we show how to build a data lake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional data lake (Apache Iceberg) using AWS Glue. We show how to build data pipelines using AWS Glue jobs, optimize them for both cost and performance, and implement schema evolution to automate manual tasks. To review the first part of the series, where we load SQL Server data into Amazon Simple Storage Service (Amazon S3) using AWS Database Migration Service (AWS DMS), see Modernize your legacy databases with AWS data lakes, Part 1: Migrate SQL Server using AWS DMS.

Demystify data sharing and collaboration patterns on AWS: Choosing the right tool for the job
Adoption of data lakes and the data mesh framework emerges as a powerful approach. By decentralizing data ownership and distribution, enterprises can break down silos and enable seamless data sharing. In this post, we discuss how to choose the right tool for building an enterprise data platform and enabling data sharing, collaboration and access within your organization and with third-party providers. We address three business use cases using AWS Glue, AWS Data Exchange, AWS Clean Rooms, and Amazon DataZone through three different use cases.

The AWS Glue Data Catalog now supports storage optimization of Apache Iceberg tables
The AWS Glue Data Catalog now enhances managed table optimization of Apache Iceberg tables by automatically removing data files that are no longer needed. Along with the Glue Data Catalog’s automated compaction feature, these storage optimizations can help you reduce metadata overhead, control storage costs, and improve query performance. Iceberg creates a new version called […]

Unlock scalable analytics with a secure connectivity pattern in AWS Glue to read from or write to Snowflake
In today’s data-driven world, the ability to seamlessly integrate and utilize diverse data sources is critical for gaining actionable insights and driving innovation. As organizations increasingly rely on data stored across various platforms, such as Snowflake, Amazon Simple Storage Service (Amazon S3), and various software as a service (SaaS) applications, the challenge of bringing these […]

AWS Glue mutual TLS authentication for Amazon MSK
In today’s landscape, data streams continuously from countless sources such as social media interactions to Internet of Things (IoT) device readings. This torrent of real-time information presents both a challenge and an opportunity for businesses. To harness the power of this data effectively, organizations need robust systems for ingesting, processing, and analyzing streaming data at […]

Detect and handle data skew on AWS Glue
October 2024: This post was reviewed and updated for accuracy. AWS Glue is a fully managed, serverless data integration service provided by Amazon Web Services (AWS) that uses Apache Spark as one of its backend processing engines (as of this writing, you can use Python Shell or Spark). Data skew occurs when the data being […]

Use multiple bookmark keys in AWS Glue JDBC jobs
AWS Glue is a serverless data integrating service that you can use to catalog data and prepare for analytics. With AWS Glue, you can discover your data, develop scripts to transform sources into targets, and schedule and run extract, transform, and load (ETL) jobs in a serverless environment. AWS Glue jobs are responsible for running […]

Detect, mask, and redact PII data using AWS Glue before loading into Amazon OpenSearch Service
Many organizations, small and large, are working to migrate and modernize their analytics workloads on Amazon Web Services (AWS). There are many reasons for customers to migrate to AWS, but one of the main reasons is the ability to use fully managed services rather than spending time maintaining infrastructure, patching, monitoring, backups, and more. Leadership […]

Create, train, and deploy Amazon Redshift ML model integrating features from Amazon SageMaker Feature Store
Amazon Redshift is a fast, petabyte-scale, cloud data warehouse that tens of thousands of customers rely on to power their analytics workloads. Data analysts and database developers want to use this data to train machine learning (ML) models, which can then be used to generate insights on new data for use cases such as forecasting […]
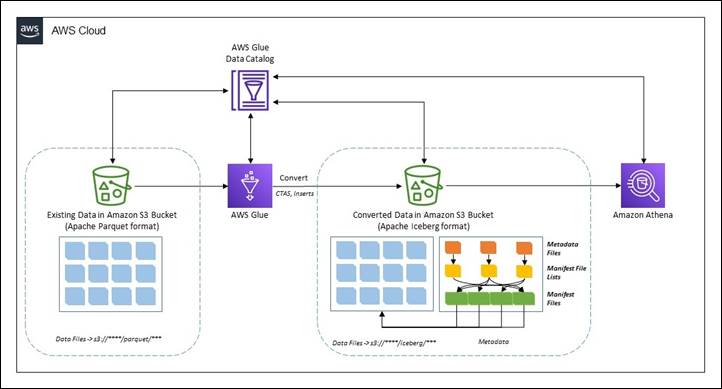
Migrate an existing data lake to a transactional data lake using Apache Iceberg
A data lake is a centralized repository that you can use to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data and then run different types of analytics for better business insights. Over the years, data lakes on Amazon Simple Storage […]