Artificial Intelligence
Generate high-quality meeting notes using Amazon Transcribe and Amazon Comprehend
Organizations are continuing to evaluate remote working arrangements and explore moving to a hybrid workforce model. Emerging trends suggest that not only has the number of online meetings attended by employees on a day-to-day basis increased, but also the number of attendees per meeting. One of the key challenges with online meetings is ensuring efficient dissemination of information to all the attendees after the meeting. There could be loss of information, either due to ad hoc, overlapping communication between the attendees, or due to technical challenges, like network disruption or bandwidth constraints. You can overcome such challenges by using AWS artificial intelligence (AI) and machine learning (ML) technologies to generate meeting artifacts automatically, such as summaries, call-to-action items, and meeting transcriptions.
In this post, we demonstrate a solution that uses the Amazon Chime SDK, Amazon Transcribe, Amazon Comprehend, and AWS Step Functions to record, process, and generate meeting artifacts. Our proposed solution is based on a Step Functions workflow that starts when the meeting bot stores the recorded file in an Amazon Simple Storage Service (Amazon S3) bucket. The workflow contains steps that transcribe and derive insights from the meeting recording. Lastly, it compiles the data into an email template and sends it to meeting attendees. You can easily adapt this workflow for different use cases, such as web conferencing solutions.
Solution overview
The application is primarily divided into two parts: the conferencing solution built using the Amazon Chime SDK, and the AI/ML-based processing workflow implemented using Amazon Transcribe and Amazon Comprehend. The following diagram illustrates the architecture.
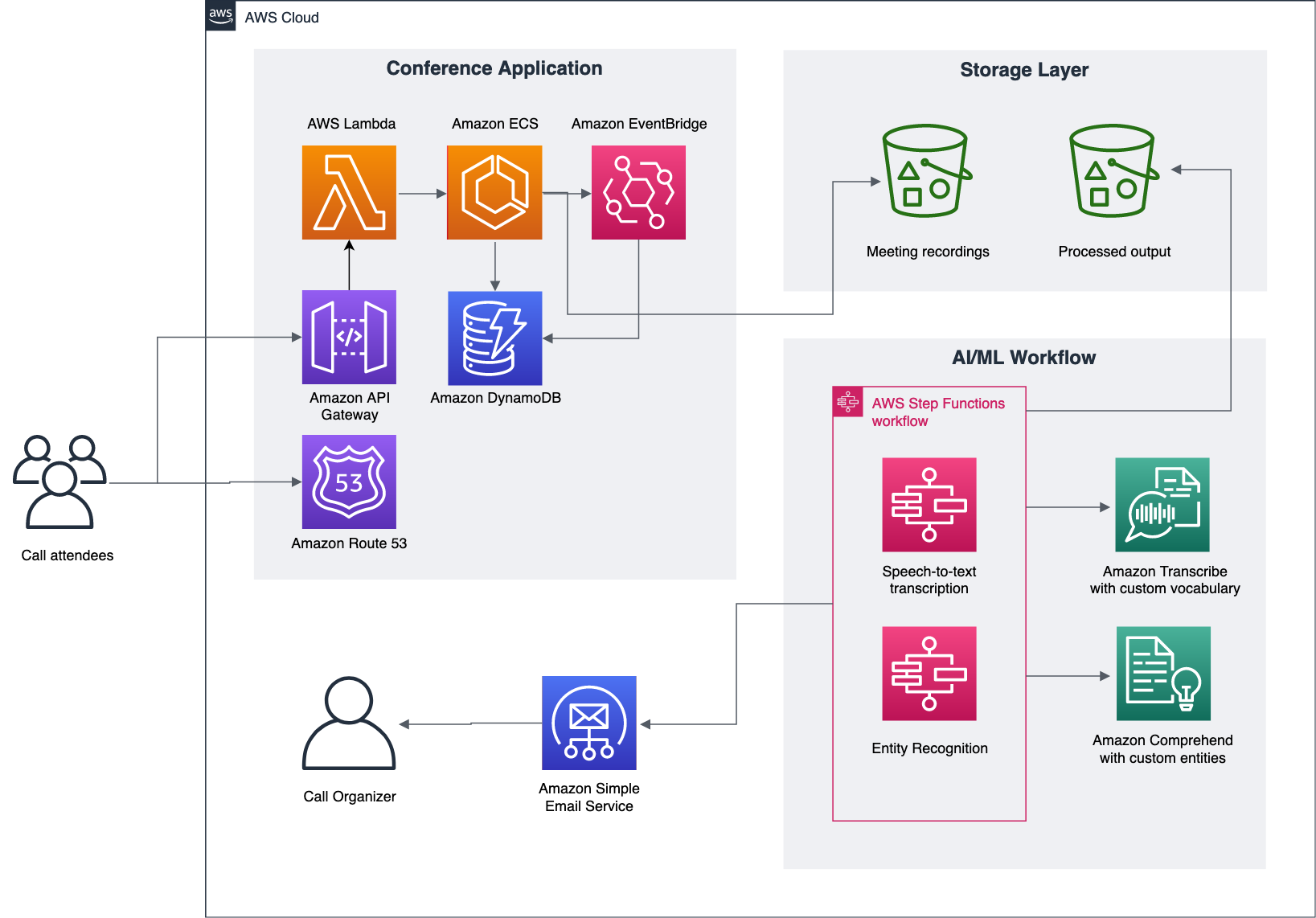
Amazon Chime conferencing application
The conferencing application is a web-based application built using the Amazon Chime JS SDK and hosted using a combination of Amazon Elastic Container Service (Amazon ECS), AWS Lambda, and Amazon API Gateway. Session information for the meetings is stored in Amazon DynamoDB tables. During a conference call, the session information is captured using an Amazon EventBridge connector for the Amazon Chime SDK, and written to the DynamoDB tables. The following features are available on the web application:
- Start or join a call – When a user requests to join or start a call, the request invokes the Amazon Chime SDK to start or join a meeting. A unique
MeetingIdis generated and passed along with the request, and other participants can use thisMeetingIdto join the same call. - Record call – When the
record callaction is initiated, it starts an Amazon ECS task, which acts as the meeting recorder bot. This bot runs a headless Firefox browser and joins the call as an attendee. The headless browser is screen recorded in the Amazon ECS task using FFMPEG and virtual audio routers. - Stop recording – When this action is initiated, it stops the Amazon ECS task running the headless browser. During the shutdown process, the Amazon ECS task writes the video recording into an S3 bucket.
- Session metadata – For the duration of the conference call, meeting metadata is streamed by an Amazon EventBridge Connector for Amazon Chime. The EventBridge rule is configured with a Lambda target and writes the data to a DynamoDB table.
The preceding features allow users to start, attend, and record conference calls. The call recording generates a video file that is delivered to an S3 bucket. The S3 bucket is configured with an Amazon S3 event notification for the s3:ObjectCreated:Put event, and initiates the AI/ML processing workflow. These solutions are available as demos on the Amazon Chime JS SDK page on GitHub.
AI/ML processing workflow
The AI/ML processing workflow built with Step Functions uses Amazon Transcribe and Amazon Comprehend. The output of this processing workflow is a well-crafted email that is sent to the conference call owner using Amazon Simple Email Service (Amazon SES). The following sequence of steps is involved in the AI/ML workflow:
- Speech to text – The location of the recorded file in Amazon S3 is passed as a parameter to the Amazon Transcribe
start_transcription_jobAPI that creates the asynchronous transcription job. Amazon Transcribe automatically converts the recorded speech to text accurately. If Amazon Transcribe needs to recognize domain-specific words and phrases such as product or brand names, technical terminology, or names of people, there are two options: using the custom vocabulary feature or using custom language models. Custom vocabulary enhances speech recognition for a discrete list of out-of-lexicon terms. Custom language models allow you to use pre-existing domain-specific text or audio transcripts to build a custom speech engine. You can also build a custom vocabulary specific for your organization. The following is a sample code using Boto3 APIs to start an asynchronous transcription job with custom vocabulary:
- Identify custom entities – After the transcribed text has been generated, use the custom entity recognition feature in Amazon Comprehend to extract meeting highlights, follow-up actions, and questions asked. You can train a model to identify a new entity. Use ACTIONS to identify the follow-up action items from the meeting. Use QUESTIONS to identify the questions asked by the attendees in the meeting. You can also build a custom entity recognizer using Amazon Comprehend. You could use the text from your past meeting notes, e-mails, and technical documents for training the model. These could be PDFs, Word, and plaintext documents. They will need to be stored in an S3 bucket. Annotations allow you to provide the location of the custom entities within these documents. You could also list the entities in plaintext documents using Entity Lists. Amazon Comprehend will learn about the kind of documents and the context where the entities occur to build the recognizer. Below is a sample CSV file for Entity Lists having the custom entities QUESTIONS and ACTIONS.
The following is a sample code using the Boto3 SDKs for starting an asynchronous entity detection from the transcribed output:
- Send email – The processing from the previous step generates data that is saved in an S3 bucket and a DynamoDB table. Lastly, these results are collated by a Lambda function, formatted into an email, and sent across to the meeting attendees using Amazon SES.
The entire AI/ML processing workflow is shown in the following figure.

Output
The following figure shows a sample email that is sent out to the meeting attendees by the AI/ML processing workflow. The email provides details such as the meeting title, attendees, key discussion points, and the action items.

Summary
In this post, we demonstrated how you can use AWS AI services such as Amazon Transcribe and Amazon Comprehend along with the Amazon Chime SDK to generate high-quality meeting artifacts. We demonstrated the custom vocabulary feature of Amazon Transcribe and the custom entities feature of Amazon Comprehend that allow you to customize the artifacts based on your business requirements.
Learn more about AWS AI services and get started building your own custom processing workflow using AWS Step Functions and Amazon Chime SDK.
About the Authors
 Rajdeep Tarat is a Senior Solutions Architect at AWS. He lives in Bengaluru, India, and helps customers architect and optimize applications on AWS. In his spare time, he enjoys music, programming, and reading.
Rajdeep Tarat is a Senior Solutions Architect at AWS. He lives in Bengaluru, India, and helps customers architect and optimize applications on AWS. In his spare time, he enjoys music, programming, and reading.
 Venugopal Pai is a Solutions Architect at AWS. He lives in Bengaluru, India, and helps digital native customers scale and optimize their applications on AWS.
Venugopal Pai is a Solutions Architect at AWS. He lives in Bengaluru, India, and helps digital native customers scale and optimize their applications on AWS.