Artificial Intelligence
Training and serving H2O models using Amazon SageMaker
Model training and serving steps are two essential pieces of a successful end-to-end machine learning (ML) pipeline. These two steps often require different software and hardware setups to provide the best mix for a production environment. Model training is optimized for a low-cost, feasible total run duration, scientific flexibility, and model interpretability objectives, whereas model serving is optimized for low cost, high throughput, and low latency objectives.
Therefore, a wide-spread approach is to train a model with a popular data science language like Python or R, and create model artifact formats such as Model Object, Optimized (MOJO), Predictive Model Markup Language (PMML) or Open Neural Network Exchange (ONNX) and serve the model on a microservice (e.g., Spring Boot application) based on Open Java Development Kit (OpenJDK).
This post demonstrates how to implement this approach end-to-end using Amazon SageMaker for the popular open-source ML framework H2O. Amazon SageMaker is a fully managed service that provides every developer and data scientist the ability to build, train, and deploy ML models quickly. Amazon SageMaker is a versatile ML service, which allows you to use ML frameworks and programming languages of your choice. H2O was founded by H2O.ai, an AWS Partner Network (APN) Advanced Partner. You can choose from a wide range of options to train and deploy H2O models on the AWS Cloud, and H2O provides some design pattern examples to productionize H2O ML pipelines.
The H2O framework supports three type of model artifacts, as summarized in the following table.
| Dimension | Binary Models | Plain Old Java Object (POJO) | Model Object, Optimized (MOJO) |
| Definition | The H2O binary model is intended for non-production ML experimentation with the features supported by a specific H2O version. | A POJO is an ordinary Java object, not bounded by any special restriction. It’s a way to export a model built in H2O and implement it in a Java application. | A MOJO is also a Java object, but the model tree is out of this object, because it has a generic tree-walker code to navigate the model. This allows model artifacts to be much smaller. |
| Use case | Intended for interactive ML experimentation. | Suitable for production usage. | Suitable for production usage |
| Deployment Restrictions | The model hosting image should run an H2O cluster and the same h2o version as the binary model. | 1 GB maximum model artifact file size restriction for H2O. | No size restriction for H2O. |
| Inference Performance | High latency (up to a few seconds)—not recommended for production. | Only slightly faster than MOJOs for binomial and regression models. Latency is typically in single-digit milliseconds. | Significant inference efficiency gains over POJOs for multi-nominal and large models. Latency is typically in single-digit milliseconds. |
During my trials, I explored some of the design patterns that Amazon SageMaker manages end to end, summarized in the following table.
| ID | Design Pattern | Advantages | Disadvantages |
| A |
Train and deploy the model with the Amazon SageMaker Marketplace algorithm offered by H2O.ai
|
No effort is required to create any custom container and Amazon SageMaker algorithm resource. | An older version of the h2o Python library is available. All other disadvantages in option B also apply to this option. |
| B |
Train using a custom container with h2o Python library. Export the model artifact as H2O binary model format. Serve the model using a custom container running a Flask application and running inference by h2o Python library.
|
It’s possible to use any version of the h2o Python library. | H2O binary model inference latency is significantly higher than MOJO artifacts. It’s prone to failures due to h2o Python library version incompatibility. |
| C |
Train using a custom container with the h2o Python library. Export the model in MOJO format. Serve the model using a custom container running a Flask application and running inference by pyH2oMojo.
|
Because MOJO model format is supported, the model inference latency is lower than option B and it’s possible to use any version of the h2o Python library. | Using pyH2oMojo has a higher latency and it’s prone to failures due to weak support for continuously evolving H2O versions. |
| D | Train using a custom container with the h2o Python library. Export the model in MOJO format. Serve the model using a custom container based on Amazon Corretto running a Spring Boot application and h2o-genmodel Java library. | It’s possible to use any version of h2o Python library and h2o-genmodel libraries. It offers the lowest model inference latency. | The majority of data scientists prefer using only scripting languages. |
It’s possible to add a few more options to the preceding list, especially if you want to run distributed training with Sparkling Water. After testing all these alternatives, I have concluded that design pattern D is the most suitable option for a wide range of use cases to productionize H2O. Design pattern D is built by a custom model training container with the h2o Python library and a custom model inference container with Spring Boot application and h2o-genmodel Java library. This post shows how to build an ML workflow based on this design pattern in the subsequent sections.
Problem and dataset
You can use the Titanic Passenger Survival dataset, which is publicly available thanks to Kaggle and encyclopedia-titanica, to build a predictive model that answers what kind of people are more likely to survive in a catastrophic shipwreck. It uses 11 independent variables such as age, gender, and passenger class to predict the binary classification target variable Survived. For this post, we split the original training dataset 80%/20% to create train.csv and validation.csv input files. The datasets are located under the /examples directory of the parent repository. This dataset requires features preprocessing operations like data imputation of null values for the Age feature and string indexing for Sex and Embarked features to train a model using the Gradient Boosting Machines (GBM) algorithm using the H2O framework.
Overview of solution
The solution in this post offers an ML training and deployment process orchestrated by AWS Step Functions and implemented with Amazon SageMaker. The following diagram illustrates the workflow.
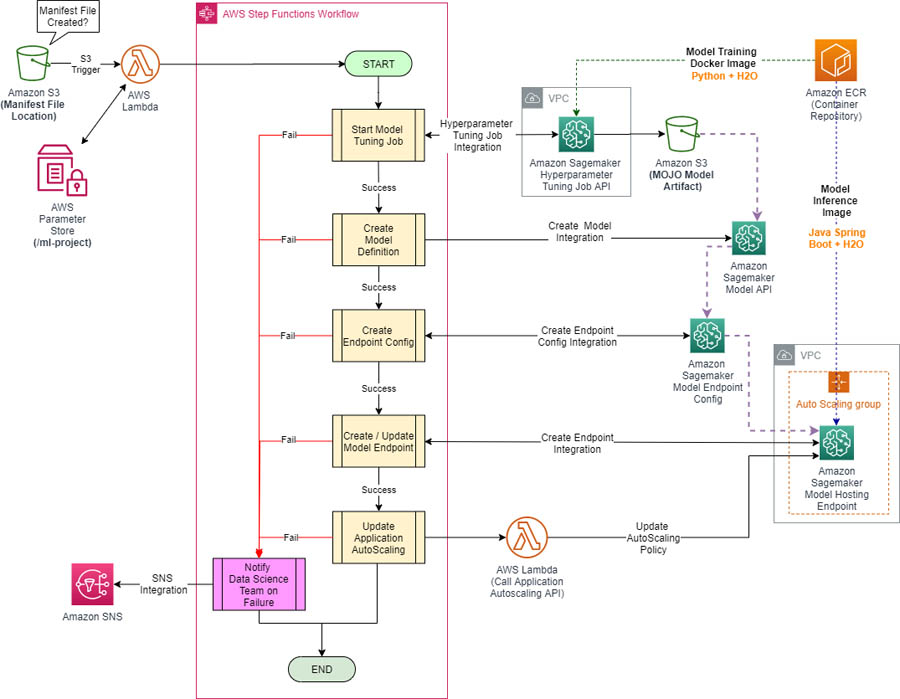
This workflow is developed using a JSON-based language called Amazon State Language (ASL). The Step Functions API provides service integrations to Amazon SageMaker, child workflows, and other services.
Two Amazon Elastic Container Registry (Amazon ECR) images contain the code mentioned in design pattern D:
- h2o-gbm-trainer – H2O model training Docker image running a Python application
- h2o-gbm-predictor – H2O model inference Docker image running a Spring Boot application
The creation of a manifest.json file in an Amazon Simple Storage Service (Amazon S3) bucket initiates an event notification, which starts the pipeline. This file can be generated by a prior data preparation job, which creates the training and validation datasets during a periodical production run. Uploading this file triggers an AWS Lambda function, which collects the ML workflow run duration configurations from the manifest.json file and AWS Systems Manager Parameter Store and starts the ML workflow.
Prerequisites
Make sure that you complete all the prerequisites before starting deployment. Deploying and running this workflow involves two types of dependencies:
- ML workflow infrastructure deployment:
- S3 bucket (
<s3bucket>) - ml-parameters.json file
- hyperparameters.json file
- S3 bucket (
- Dependencies for ML workflow execution:
- Training and inference images created in Amazon ECR
- Amazon SageMaker algorithm resource
- Training and validation datasets
- manifest.json file
Deploying the ML workflow infrastructure
The infrastructure required for this post is created with an AWS CloudFormation template compliant to AWS Serverless Application Model (AWS SAM), which simplifies how to define functions, state machines, and APIs for serverless applications. I calculated the cost for a test run is less than $1 in the eu-central-1 Region. For installation instructions, see Installation.
The deployment takes approximately 2 minutes. When it’s complete, the status switches to CREATE_COMPLETE for all stacks.

The nested stacks create three serverless applications:
- ml-parameter-provider manages parameters required by ML workflows
- sagemaker-model-tuner manages model tuning and training process
- sagemaker-endpoint-deployer manages the auto-scaling model endpoint creation and update process.

Creating a model training Docker image
Amazon SageMaker launches this Docker image on Amazon SageMaker training instances in the runtime. It’s a slightly modified version of the open-sourced Docker image repository by our partner H2O.AI, which extends the Amazon Linux 2 Docker image. Only the training code and its required dependencies are preserved; the H2O version is upgraded and a functionality to export MOJO model artifacts is added.
Navigate to h2o-gbm-trainer repository in your command line. Optionally, you can test it in your local PC. Build and deploy the model training Docker image to Amazon ECR using the installation command.
Creating a model inference Docker image
Amazon SageMaker launches this Docker image on Amazon SageMaker model endpoint instances in the runtime. The Amazon Corretto Docker Image (amazoncorretto:8) is extended to provide dependencies with Amazon Linux 2 Docker image and Java settings required to launch a Spring Boot application.
Depending on an open-source distribution of OpenJDK has several drawbacks, such as backward incompatibility between minor releases, delays in bug fixing, security vulnerabilities like backports, and suboptimal performance for a production service. Therefore, I used Amazon Corretto, which is a no-cost, multiplatform, secure, production-ready downstream distribution of the OpenJDK. In addition, Corretto offers performance improvements (AWS Online Tech Talk) with respect to OpenJDK (openjdk:8-alpine), which are observable during the Spring Boot application launch and model inference latency. The Spring Boot framework is preferred to build the model hosting application for the following reasons:
- It’s easy to build a standalone production-grade microservice
- It requires minimal Spring configuration and easy deployment
- It’s easy to build RESTful web services
- It scales the system resource utilization according to the intensity of the model invocations
The following image is the class diagram of the Spring Boot application created for the H2O GBM model predictor.

SagemakerController class is an entry point of this Spring Boot Java application, launched by SagemakerLauncher class in the model inference Docker image. SagemakerController class initializes the service in init() method by loading the H2O MOJO model artifact from Amazon S3 with H2O settings to impute the missing model scoring input features and loading a predictor object.
SagemakerController class also provides the /ping and /invocations REST API interfaces required by Amazon SageMaker, which are called by asynchronous and concurrent HTTPS requests to Amazon SageMaker model endpoint instances in the runtime. Amazon SageMaker reserves the /ping path for health checks during the model endpoint deployment. The /invocations path is mapped to the invoke() method, which forwards the incoming model invocation requests to the predict() method of the predictor object asynchronously. This predict() method uses Amazon SageMaker instance resources dedicated to the model inference Docker image efficiently thanks to its non-blocking asynchronous and concurrent calls.
Navigate to the h2o-gbm-predictor repository in your command line. Optionally, you can test it in your local PC. Build and deploy the model inference Docker image to Amazon ECR using the installation command.
Creating a custom Amazon SageMaker algorithm resource
After publishing the model training and inference Docker images on Amazon ECR, it’s time to create an Amazon SageMaker algorithm resource called h2o-gbm-algorithm. As displayed in the following diagram, an Amazon SageMaker algorithm resource contains training and inference Docker image URIs, Amazon SageMaker instance types, input channels, supported hyperparameters, and algorithm evaluation metrics.

Navigate to the h2o-gbm-algorithm-resource repository in your command line. Then run the installation command to create your algorithm resource.
After a few seconds, an algorithm resource is created.

Because all the required infrastructure components are now deployed, it’s time to run the ML pipeline to train and deploy H2O models.
Running the ML workflow
To start running your workflow, complete the following steps:
- Upload the train.csv and validation.csv files to their dedicated directories in the <s3bucket> bucket (replace <s3bucket> with the S3 bucket name in the manifest.json file):
- Upload the file under the s3://<s3bucket>/manifests directory located in the same S3 bucket specified during the ML workflow deployment:
As soon as the manifest.json file is uploaded to Amazon S3, Step Functions puts the ML workflow in a Running state.
Training the H2O model using Amazon SageMaker
To train your H2O model, complete the following steps:
- On the Step Functions console, navigate to
ModelTuningWithEndpointDeploymentStateMachineto find it inRunningstate and observe the Model Tuning Job step.

- On the Amazon SageMaker console, under Training, choose Hyperparameter tuning jobs.
- Drill down to the tuning job in progress.

After 4 minutes, all training jobs and the model tuning job change to Completed status.

The following screenshot shows the performance and configuration details of the best training job.

- Navigate to the Amazon SageMaker model link to display the model definition in detail.

The following screenshot shows the detailed settings associated with the created Amazon SageMaker model resource.

Deploying the MOJO model to an auto-scaling Amazon SageMaker model endpoint
To deploy your MOJO model, complete the following steps:
- On the Step Functions console, navigate to
ModelTuningWithEndpointDeploymentStateMachineto find it inRunningstate. - Observe the ongoing Deploy Auto-scaling Model Endpoint step.

The following screenshot shows the Amazon SageMaker model endpoint during the deployment.

Auto-scaling model endpoint deployment takes approximately 5–6 minutes. When the endpoint is deployed, the Step Functions workflow successfully concludes.

- Navigate to the model endpoint that is in
InServicestatus; it’s now ready to accept incoming requests.

- Drill down to the model endpoint details and observe the endpoint runtime settings.

This model endpoint can scale from one to four instances, which are all behind Amazon SageMaker Runtime.
Testing the Amazon SageMaker model endpoint
For Window users, enter the following code to invoke the model endpoint:
For Linux and macOS users, enter the following code to invoke the model endpoint:
As displayed in the following model endpoint response, this unfortunate third-class male passenger didn’t survive (prediction is 0) according to the trained model:
The invocation round-trip latency might be higher in the first call, but it decreases in the subsequent calls. This latency measurement from your PC to the Amazon SageMaker model endpoint also involves the network overhead of the local PC to AWS Cloud connection. To have an objective evaluation of model invocation performance, a load test based on real-life traffic expectations is essential.
Cleaning up
To stop incurring costs to your AWS account, delete the resources created in this post. For instructions, see Cleanup.
Conclusion
In this post, I explained how to use Amazon SageMaker to train and serve models for an H2O framework in a production-scale design pattern. This approach uses custom containers running a model training application built with a data science scripting language and a separate model hosting application built with a low-level language like Java, and has proven to be very robust and repeatable. You could also adapt this design pattern and its artifacts to other ML use cases. You can test out the open-source code on your own by checking out the code in the Github repo. For further resources on H2O, check out these other blog posts.
4 Steps to Train and Deploy Machine Learning Models on AWS Using H2O
Predict Billboard Top 10 Hits Using RStudio, H2O and Amazon Athena
About the Author
 As a Machine Learning Prototyping Architect, Anil Sener builds prototypes on Machine Learning, Big Data Analytics, and Data Streaming, which accelerates the production journey on AWS for top EMEA customers. He has two masters degrees in MIS and Data Science.
As a Machine Learning Prototyping Architect, Anil Sener builds prototypes on Machine Learning, Big Data Analytics, and Data Streaming, which accelerates the production journey on AWS for top EMEA customers. He has two masters degrees in MIS and Data Science.