AWS Storage Blog
Comparing your on-premises storage patterns with AWS Storage services
Many companies want to move to the cloud, and for most of those companies, moving to the cloud starts with an assessment of existing storage infrastructure. It is useful to know how to map existing storage with AWS Storage options to assess the existing storage infrastructure effectively. Companies that take the time to identify where and how data is stored today have a head start mapping their existing workloads and storage infrastructure to AWS Storage services.
In this blog post, I compare storage patterns observed across AWS with on-premises storage patterns to help customers align their existing patterns with the broad portfolio of AWS Storage services. I provide a storage pattern decision matrix for customers, which accelerates the storage pattern selection process in AWS for diverse application and workload needs.
Why move to the cloud?
AWS has been helping enterprises on their cloud journey for over 14 years. Moving storage workloads to the cloud has been one of the main ways CIOs have been able to address their top strategic priorities:
- Increasing their business agility
- Accelerating their ability to innovate
- Strengthening their security
- Reducing their cost
Enterprises can be more agile in the cloud as they can scale resources to meet their business needs. Modernization is accelerated by eliminating data silos and extracting more value from data by performing large-scale analytics and leveraging machine learning. Companies improve their security posture as they gain far more telemetry on their data when silos are erased and encryption controls are more advanced. AWS customers inherit all of the controls, tools, and certifications designed for even the most security-conscious organizations. Finally, enterprises can reduce costs with a flexible buying model and the elimination of over-provisioning, refresh lifecycles, and the cost of maintaining storage infrastructure. Cloud storage provides countless benefits to the on-premises model and addresses the CIO’s top priorities.
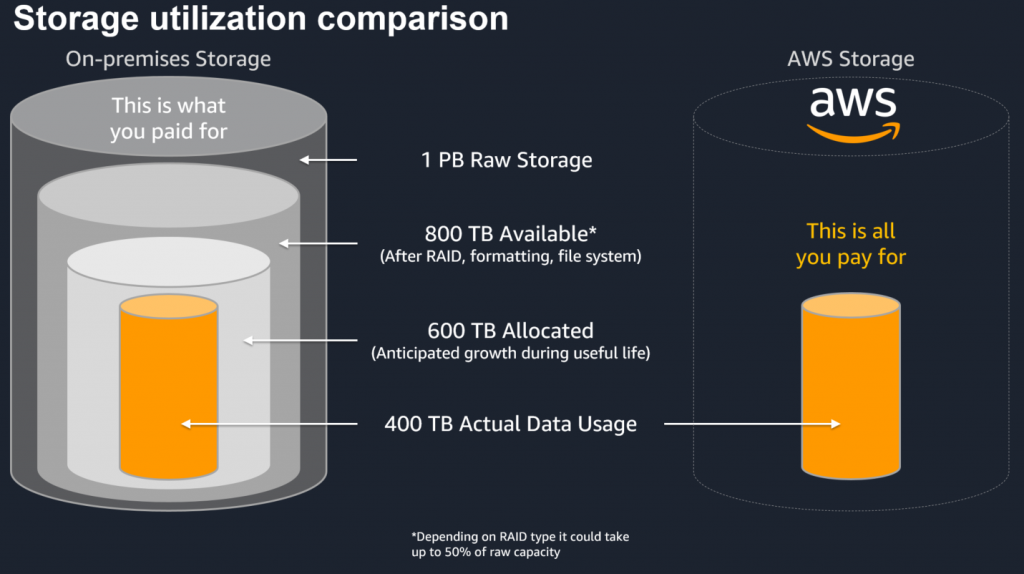
Figure 1: Storage Utilization Comparison
Figure 1 represents a comparison between the capital investment needed for on-premises storage systems with the consumption model of AWS, where customers only pay for what they use. In this example, the customer would have to purchase and pay for 1 PB of raw storage capacity. This is then reduced down to 400 TB for actual data usage after the RAID, formatting, file system overhead, and anticipated capacity growth buffer. With most of the AWS Storage services, customers only pay for the 400-TB capacity that they may actually use (in the case of Amazon EFS and Amazon S3) or 600 TB of allocated capacity (in the case of Amazon EBS and Amazon FSx for Windows File Server). Check out this page to learn more about the benefits of moving to managed file storage with AWS.
Typical on-premises storage patterns
Typical on-premises storage patterns follow workloads running on fibre channel storage area network (FC SAN) storage, iSCSI SAN storage, network-attached storage (NAS), and object storage. In this section, I review the on-premises data storage to uncover the workload patterns created as customers serve their application and user data storage needs.
Fibre channel (FC) SAN storage
SAN is a storage networking technology that allows block storage resources to be shared over a dedicated high-speed FC network. Additionally, Fiber Channel Protocol (FCP) is a mapping of the SCSI protocol over FC networks. Mostly, SCSI commands and data blocks are wrapped up in FC frames and delivered over an FC network/fabric. Examples of applications that use FC SAN include ERP, CRM, SAP, SQL, Oracle, DB2, MSSQL, and more.
iSCSI SAN storage
iSCSI is a storage networking technology that enables the sharing of storage resources over an IP network. Often, disk resources are the storage resources shared on an iSCSI SAN. However, iSCSI is a mapping of the SCSI protocol over TCP/IP. The same way that SCSI has been mapped over other transports such as FC, it is theoretically possible for any SCSI devices to be shared over an iSCSI SAN. Examples of applications that use iSCSI are the same types of applications that use FC SAN, but over an IP networking infrastructure (for example, ERP, CRM, SAP, SQL, Oracle, etc.).
Network attached storage (NAS)
NAS file systems are shared file storage assets and are often referred to as unstructured or file storage. These file systems use protocols such as Network File Storage (NFS) for Linux workloads and server message block (SMB) or common internet file system (CIFS) for Windows workloads to share data. NAS storage is often used for storing file data such as shared folders and document repositories for users and applications.
According to SNIA.org (Storage Networking Industry Association):
“NAS is a term used to refer to storage devices that connect to a network and provide file access services to computer systems.” These NAS devices typically implement the file services with metadata and file/folder hierarchy on which data is stored. NAS clients use standard protocols (NFS or SMB/CIFS) to access data stored on NAS devices. Enterprises use NAS systems as an effective, low-cost, and scalable storage solution. NAS storage is used to support email systems, accounting databases, payroll, video recording and editing, data logging, business analytics, and more.
Object storage
Object storage enables customers to store their data in its native format, thus any type of data can be stored in an object store. Objects are often identified by long (for example, 64-bit) unique identifiers that are derived from the content of the object, plus an arbitrary hashing scheme. Mostly, objects are kept in a single, large, flat namespace without any hierarchy or tree structure as there is with a traditional filesystem. These flat namespaces enable the massive scalability inherent in object storage systems. Object storage devices (OSDs) are accessed via API operations such as REST, SOAP, and XAM.
According to SNIA.org:
“Object storage is the third major way of organizing data on disk. Objects are addressed by an object ID or a key-value rather than addressing the data by byte, and organizing it into named files, or by block and asking for it by block number. We ask for an object by an object ID, which can be a key. The data is then returned, and it can be any length from anything from zero bytes all the way up to substantial quantities.”
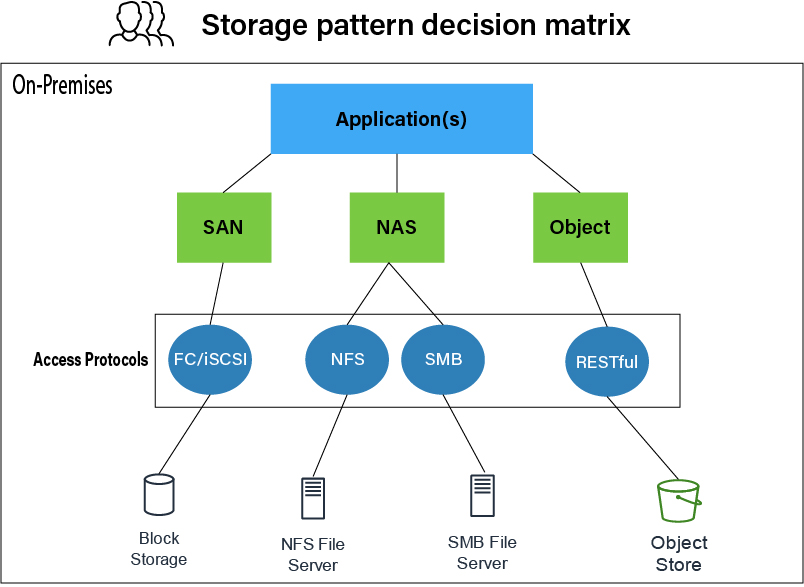
Figure 2: On-premises storage decision matrix
Figure 2 represents how on-premises users and applications access and connect to data storage. In the preceding example, the applications may leverage either SAN, NAS, or object storage via their supported protocols. Along with performance, security, and scalability, access protocols that the applications support are the key element of deciding which storage type (SAN, NAS, or Object) to use in the backend. This is the case as each storage access protocol has its advantages and limitations.
AWS Storage service patterns
In this section, I cover a high-level overview of the AWS Storage services that replace on-premises storage patterns in the cloud.
Amazon Elastic Block Store (Amazon EBS)
Amazon EBS is an easy-to-use, high-performance block storage service. Amazon EBS is designed for use with Amazon EC2 for both throughput and transaction-intensive workloads at any scale. A broad range of workloads, such as relational and non-relational databases, enterprise applications, containerized applications, big data analytics engines, file systems, and media workflows, are widely deployed on Amazon EBS.
Amazon EBS serves application workloads that were traditionally serviced by on-premises iSCSI or FC SAN storage arrays.
Amazon Elastic File System (Amazon EFS)
Amazon EFS provides a simple, scalable, fully managed elastic NFS file system for use with AWS Cloud services and on-premises resources. It is built to scale on-demand to petabytes without disrupting applications, growing and shrinking automatically as you add and remove files, eliminating provisioning and managing capacity to accommodate growth. Amazon EFS is a regional service that delivers single-digit millisecond latency while storing data across at least three Availability Zones and is designed for 99.999999999% (11 9’s) of durability.
Amazon EFS serves application and user workloads that were traditionally serviced by on-premises NFS protocol-based NAS storage arrays.
Amazon FSx for Windows File Server
Amazon FSx for Windows File Server provides fully managed, highly reliable, and scalable file storage that is accessible over the industry-standard SMB protocol. It is built on Windows Server, delivering a wide range of administrative features such as user quotas, end-user file restores, and Microsoft Active Directory integration. It offers Single-AZ and Multi-AZ deployment options, fully managed backups, and encryption of data at rest and in transit. Amazon FSx file storage is accessible from Windows, Linux, and macOS compute instances and devices running on AWS or on-premises. You can optimize cost and performance for your workload needs with SSD and HDD storage options.

Figure 3: Amazon FSx for Windows File Server features
Figure 3 highlights the features of FSx for Windows File Server, and its support for protocols, OS, compute, networking, availability, durability, backups, performance, scalability, cost optimization, security, and compliance. Amazon FSx for Windows File Server serves application and user workloads that were traditionally serviced by on-premises CIFS/SMB protocol-based NAS storage arrays.
Amazon Simple Storage Service (Amazon S3)
Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. These capabilities enable customers to store and protect any amount of data for a range of use cases, including websites, mobile applications, backup and restore, archive, enterprise applications, IoT devices, and big data analytics. Amazon S3 provides easy-to-use management features so you can organize your data and configure finely tuned access controls to meet your specific business, organizational, and compliance requirements. Amazon S3 is designed for 99.999999999% (11 9’s) of durability, and stores data for millions of applications for companies all around the world.
Amazon S3 offers a range of storage classes designed for different use cases. These include S3 Standard for general-purpose storage of frequently accessed data; S3 Intelligent-Tiering for data with unknown or changing access patterns; S3 Standard-Infrequent Access (S3 Standard-IA) and S3 One Zone-Infrequent Access (S3 One Zone-IA) for long-lived, easily recreatable, but less frequently accessed data; and Amazon S3 Glacier and Amazon S3 Glacier Deep Archive for long-term archive and digital preservation. Amazon S3 also offers capabilities to manage your data throughout its lifecycle. Once an S3 Lifecycle policy is set, your data automatically transfers to a different storage class without any changes to your application.
Amazon S3 serves application and user workloads that were traditionally serviced by on-premises object-based and many file-based storage arrays.
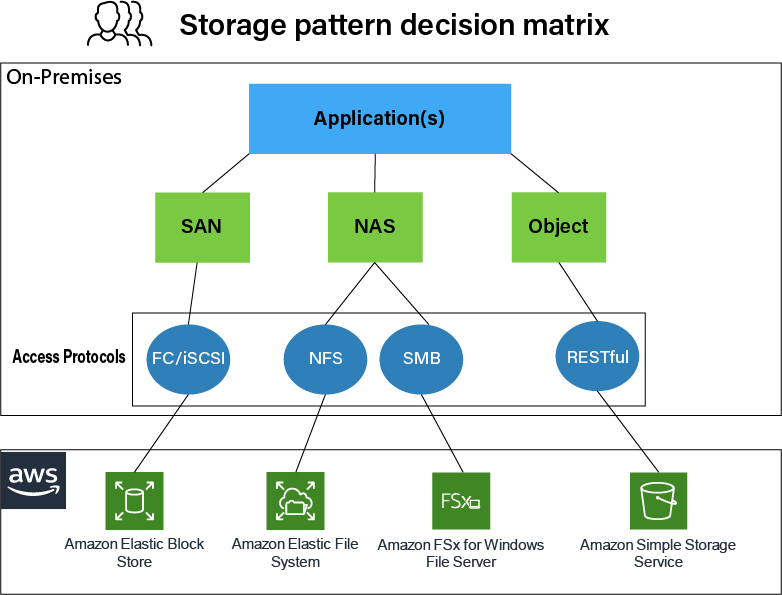
Figure 4: AWS Storage pattern decision matrix
Figure 4 represents the storage decision pattern matrix for applications that are already migrated to AWS or were born in the cloud. In this decision matrix, the storage access protocols, performance requirements, and scalability requirements of the workloads play a crucial role. Alternately, with on-premises applications, most AWS Storage services can be accessed over a low latency AWS Direct Connect or VPN connection from on-premises.
Data storage migration and hybrid cloud storage access
There are several options at AWS that customers can leverage to migrate on-premises data storage to AWS. In this blog, I review the online migrations via AWS DataSync and offline storage migrations using the AWS Snow Family of services.
AWS DataSync for online storage migrations
AWS DataSync makes it fast and straightforward to move large amounts of data online between on-premises storage and Amazon S3, Amazon EFS, or Amazon FSx for Windows File Server. Manual tasks related to data transfers can slow down migrations and burden IT operations. DataSync eliminates or automatically handles many of these tasks, including scripting copy jobs, scheduling, and monitoring transfers, validating data, and optimizing network utilization. The DataSync software agent connects to your NFS and SMB storage, so you don’t have to modify your applications. DataSync can transfer hundreds of terabytes and millions of files at speeds up to 10 times faster than open-source tools, over the internet or AWS Direct Connect links. You can use DataSync to migrate active datasets or archives to AWS, transfer data to the cloud for timely analysis and processing, or replicate data to AWS for business continuity.
AWS Snow Family for offline storage migrations
The AWS Snow Family includes AWS Snowcone and AWS Snowball. AWS Snowcone and AWS Snowball are small, rugged, and secure portable storage and edge computing devices for data collection, processing, and migration. These devices are purpose-built for use in edge locations where network capacity is constrained or nonexistent and provide storage and computing capabilities in harsh environments. Using AWS Snowcone integration with AWS DataSync, customers can now transfer data online from edge locations.
Hybrid cloud storage access with AWS Storage Gateway
Customer can leverage their existing AWS Direct Connect in addition to VPN connections from on-premises data centers to access their data in AWS. AWS offers several options via AWS Storage Gateway for different types of data access patterns, along with local caching capabilities for faster reads and writes to most frequently accessed data.
AWS Storage Gateway is a hybrid cloud storage service that gives you on-premises access to virtually unlimited cloud storage. Customers use Storage Gateway to simplify storage management and reduce costs for critical hybrid cloud storage use cases. These include moving backups to the cloud, using on-premises file shares backed by cloud storage, and providing low latency access to data in AWS for on-premises application.
The following storage pattern represents hybrid cloud storage access pattern:
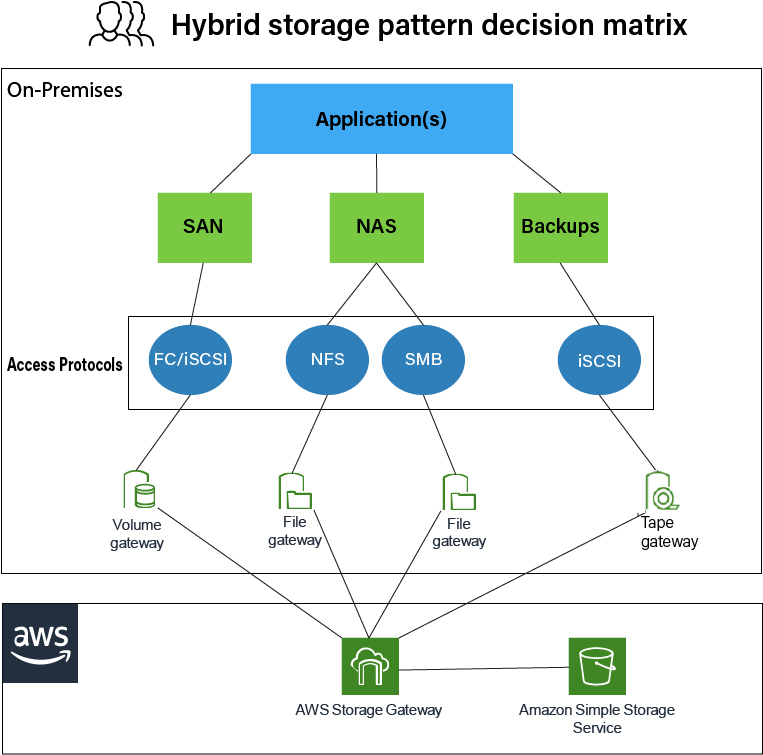
Figure 5: Hybrid storage pattern decision matrix
Figure 5 represents the storage decision pattern matrix for applications that may be required to stay on-premises. These applications can also take advantage of all the benefits of the cloud while leveraging local read/write caching for even lower latency for their active working sets. Figure 5 also shows the decision matrix for applications or users that can leverage their preferred storage protocols to access the working set of their overall data stored locally. In those scenarios, access to the cloud can provide limitless scaling for applications in minutes.
In the decision matrix shown in Figure 5, the storage access protocols, performance requirements, and scalability requirements of the workloads play a crucial role. This decision matrix also accommodated additional use cases, like leveraging AWS Storage Gateway’s Tape Gateway to tier-off the long-term backups (tape backup replacement) to an archival tier of Amazon S3.
Conclusion
Whether you’re starting a migration from scratch or bursting into the cloud, AWS offers services that help you every step of the way. By moving from an on-premises storage environment to a cloud-based solution, your organization becomes more agile and innovative. Migration of on-premises data storage to AWS Storage services may also help your organization with improved scalability, security, and infrastructure costs.
Enterprise IT leaders realize that AWS affords opportunities to securely harness new workflows and services that were not available to them before. This was the case for TransferWise, an AWS customer that leveraged AWS Storage Gateway, Amazon EBS, and AWS Backup to easily migrate and manage databases and backups with AWS. TransferWise has now moved hundreds of databases into AWS, leveraging Amazon Relational Database Service (Amazon RDS) and Amazon EC2. TransferWise was able to address its on-premises scalability issues while extending its global reach by moving to AWS.
“Using AWS, we can spin up compute and storage resources where and when we need to, much faster than we ever could before. AWS will help us continue to drive our global expansion.” ~Thomas Hewer, TransferWise
An easy way to learn more about what we’ve covered in this blog is to deploy a DataSync agent and move a test workload to AWS Storage services to test any of the services mentioned above and test your operational, security, and performance requirements. If you are looking for additional resources for moving your file-based applications to AWS, explore our move to managed file storage resources page.
Thanks for reading this blog post! If you have any comments or questions, please don’t hesitate to leave them in the comments section.