AWS Storage Blog
How Reuters built easily accessible large-scale news archives on AWS
UPDATE 9/8/2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
My name is Romeo Radanyi and I am a Solutions Architect at global multimedia news agency Thomson Reuters, where I help teams understand and adopt cloud technologies. I am also involved in setting enterprise-level standards, pushing forward our Artificial Intelligence and Machine Learning plans, and building many Reuters news agency systems. In my previous blog post, I explored how Reuters migrated content to Amazon S3 for their breaking news collection and distribution systems.
In this blog post, I further explore Thomson Reuters’ journey with AWS and how we digitized one of the most unique news video archive collections in the world – including videos dating back to 1896.
Challenges we faced with storing data in tape and multiple data silos
As you may know, Reuters produces a wide range of content types. We are particularly proud of our video archive collection, which is available via our award-winning digital platform, Reuters Connect. Using Reuters Connect, customers like the BBC, CNN, The New York Times, The Washington Post, and more (broadcasters and online publishers) can purchase a story, which is delivered as either a single clip or a collection of multiple clips. Traditionally, the video archive collection was stored on physical tapes and managed by a third party on our behalf. However, in the long term, this became cumbersome to manage and limited due to the slow retrieval process and lack of flexibility. It was also not scalable because there was no option to easily produce and distribute a clip or a story in multiple video output formats.
At this time, we also had six years worth of processed content distributed into six vaults and stored in the original Amazon Glacier service, Amazon Glacier Direct – before it officially became an Amazon S3 storage class with support for the S3 APIs. I talk a bit about the distinction between Amazon Glacier Direct and Amazon S3 Glacier in the following section. Anyway, due to these limitations, we knew we had to change this model and reconcile all the content across our various storage locations. We decided on building a dedicated storage location for archived content and creating a media processing headend that could serve our customers within minutes.
The evolution of Amazon Glacier Direct to Amazon S3 Glacier
Amazon S3 was introduced in 2006 as a secure, reliable, highly scalable, low-latency data storage service. AWS introduced Amazon Glacier in 2012, as a separate storage service for secure, reliable, and low-cost data archiving and backups. Amazon Glacier was very appealing to us given its super low cost and simplicity, hence we put 6 years worth of processed content into Glacier Direct. Since then Amazon Glacier officially became an Amazon S3 storage class known as Amazon S3 Glacier (S3 Glacier). Amazon S3 Glacier supports S3 APIs, AWS software development kits (SDKs), and the AWS Management Console. I refer to the original Glacier service as Glacier Direct, as all of the existing Glacier Direct APIs continue to work just as they have.
Building the Reuters video archive
Over time, our knowledge and confidence with AWS grew after a few successful projects and a large-scale content migration. We reached the point where we were determined to pull all of our archived content from cumbersome physical Linear Tape-Open (LTO) tapes, or magnetic tape data storage, and Amazon Glacier Direct. That content would be put into Amazon S3 and its various cost-efficient storage classes to gain complete control over its management and make it more flexible to use for future Reuters products.
We agreed on the following objectives for the project:
- Migrate, digitize, and process all of our tape archives, approximately 700 TB of content comprised of approximately 750,000 news stories and 1,500,000 individual video clips at project start. And also preserve some of our processed content by migrating 6 years worth of processed content from Amazon Glacier Direct to Amazon S3 storage classes.
- Standardize our metadata formats into IPTC standard JSON format for news metadata (ninjs). Metadata had changed a lot since the first archived content from 1896.
- Build as much as possible serverless, as we learned having no servers to manage ourselves is easier to manage in the long term.
- Create a daily ingestion workflow for newly archived content, which is around 1 TB of content every 5 days.
- Create an on-demand video processing workflow supporting various media container formats.
Migrating the data
When we started this project, AWS Snowball, a secure edge computing and storage device perfect for data migrations, wasn’t available as a service yet. Instead, we relied on AWS Direct Connect and the Amazon S3 multipart upload API to push the roughly 700 TB of data that was exported from tapes into Amazon S3. This process took a few weeks due to the volume of content that we digitized.
During this migration and upload process, we standardized our metadata from XML, NSML3, and NewsMLG2 into JSON format using AWS Lambda functions. We stored the metadata in Amazon Elasticsearch Service, a common NoSQL database. We navigated this challenge via AWS’s managed Elasticsearch offering, which allowed us to focus on business objectives rather than setting up and managing Elasticsearch ourselves. We also created a batch workflow to re-encode and compress our raw video content, which reduced storage and delivery costs. In addition, the workflow clipped up the variety of frames accurately as most of the stories were previously stored on tapes. We used hundreds of Amazon EC2 Spot Instances for a few weeks to encode and clip up nearly everything, using everyone’s favorite open source tool, FFmpeg. Using EC2 Spot Instances for batch processing saved us a tremendous amount of money and time due to the parallelization and the scaling capabilities that AWS provided.
In addition, we had 6 years worth of processed content in six Amazon Glacier Direct vaults. For this content, we used FastGlacier Windows client to get the Glacier Direct journal file (list of content), efficiently manage the parallel retrieval and restoration from the vaults, and then to download the files. We also had to write a small application that took the restored content and decoded the previously base64 encoded files to get the original file names back. Doing so was important for when we uploaded, as otherwise we would have had conflicting file names. Using the same custom application, we then automatically uploaded that retrieved data into the Amazon S3 Standard-Infrequent Access (S3 Standard-IA) storage class (the custom app was relying on the AWS CLI for this).
Before we kicked off the Amazon Glacier Direct retrieval exercise, we carefully planned how much time and money we could invest in file retrieval. Amazon Glacier Direct was priced based on the monthly peak retrieval rate, so it was important to manage the volume of requests to manage costs as much as possible. Although Amazon Glacier Direct was inexpensive for storing content, we prioritized moving our content to Amazon S3 and managing out content via storage classes and S3 Lifecycle policies. Storage classes and S3 Lifecycle policies are examples of features that enabled us to optimize our storage costs based on our access patterns by using multiple S3 storage classes. As the majority of our data was in S3, we stopped using Amazon Glacier Direct in 2016 due to it requiring a different Glacier Direct API than the S3 API. S3 Glacier officially became an S3 storage class in 2018, and now has S3 API support.
The largest obstacle we faced was quickly creating something scalable, low-cost, and primarily serverless that could respond to customer requests while maintaining our media processing business logic in a business-to-business model. As a wholesaler, we provide a variety of media output containers to customers, such as IMX30, AVCi50, and AVCi100. We also create content in a variety of frame rates. The most common ones are 25 frames per second (FPS) – used in Europe, Africa, and Asia – and 29.97 FPS – used in America. Reuters has a long history and experience with frame rate conversions. Such conversions are compute-intensive tasks, and are difficult due to the need to artificially create frames – or at minimum create the differences between them.
The following is a summary of the transcoding jobs we had to support at the time of this project to provide all the permutations of the necessary output media format to our customers.
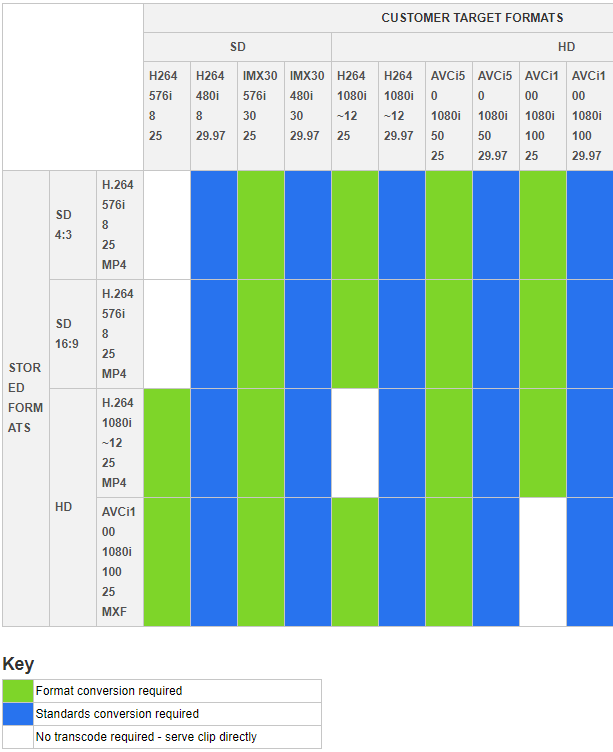
Creating an on-demand archive clip request workflow
To support the various output types reflective of on-demand customer requests, we initially wrote our application around Amazon Simple Workflow Service (Amazon SWF). We used Amazon SWF for a number of years before we ported to AWS Step Functions to be consistent with our greenfield projects. Amazon SWF greatly accelerated our development with its framework and separation of the application components and coordination or business logic. AWS Step Functions largely rely on the fundamental APIs of Amazon SWF, but has flexibility and visualization around workflows, so it was definitely a great upgrade after Amazon SWF.
Our clip request workflow architecture:

Our workflow (starting from the bottom of the preceding diagram):
- Our customers (broadcasters and online publishers) visit the Reuters Connect platform and select their archived content and the rendition they need.
- The backend capabilities of Reuters Connect triggers an API call to our Amazon API Gateway.
- The API call triggers a simple AWS Lambda function to create an AWS Step Functions job.
- Using custom Amazon CloudWatch metrics, we determine if sufficient resources are available based on the current number of active jobs. If there are not sufficient resources available, instances and containers are provisioned or scaled up.
- Reuters Connect finds the location of the video in Amazon S3, downloads it, and starts the transcoding job based on the metadata stored in Amazon Elasticsearch for that story.
- Once finished, the processed video is put back into S3 and provided to the customer via Amazon CloudFront, a fast content delivery network (CDN).
- The status of the processing jobs can be tracked via additional API calls. The calls are made by the Reuters Connect backend applications against the same API Gateway that is used to trigger the video processing jobs.
- Depending on the size of the job, customers would receive an email notification triggered by an Amazon S3 event (
s3:ObjectCreated:*) and managed via Amazon SNS.
These processes are simple, yet flexible scalable. This is driven by the fact that we got our content through Amazon S3, making it both easily accessible and usable.
Optimizing our storage cost using Amazon S3 storage classes
Another key benefit of using Amazon S3 for both our breaking news and archived content is our ability to use storage classes to support various access patterns with corresponding rates. We use the following Amazon S3 storage classes:
- S3 Standard: We store all of our breaking news for at least 30 days then they automatically become part of the archive and move to S3 Standard-IA. We also keep all the processed archive content after our customers purchased them – these are all done on-demand.
- S3 Standard-IA: We store all of our archived video content in this class, which is ready to be processed and can be requested for on-demand processing and consumption.
- S3 Glacier Deep Archive: We keep all of our original source content that we digitized from tapes in S3 Glacier Deep Archive. This archive is also a backup, securely stored in a separate bucket.
With simple S3 Lifecycle rules like the one in the following screenshot, we can easily transition our content from one storage class to another on a petabyte scale. This saves us around 95% of our storage costs each month compared to storing ~700 TB in S3 Standard.

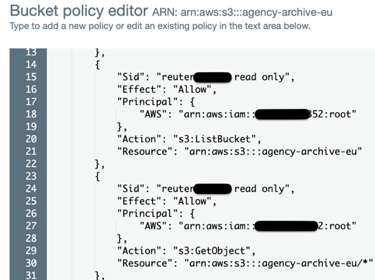
Also, with simple bucket policies, we can reuse the production data in lower environments (like development, QA, or preproduction environments) by setting up read-only cross account permissions. This saves us 75% of our storage cost for the whole video archive, as we don’t need to have two or more copies of the same datasets. Better yet, bucket policies enable us to still have a production-like system for development and quality assurance purposes.
Launching Reuters Audio
A recent study by the Reuters Institute found that there has been a 32% increase in the number of news podcasts since 2019. Within that upwards trend, 20% of the most popular podcasts were categorized as “news.” With consumers listening more than ever, Reuters decided it was time to embrace the audio renaissance and announced the launch of Reuters Audio on June 17, 2020. The Reuters Audio processing backend was able to reuse the workflows we designed for the Reuters video archive, as I explained in the preceding section. By simply adding an extra rendition type to the list of outputs, we could easily produce sound bites or audio files upon customer request.
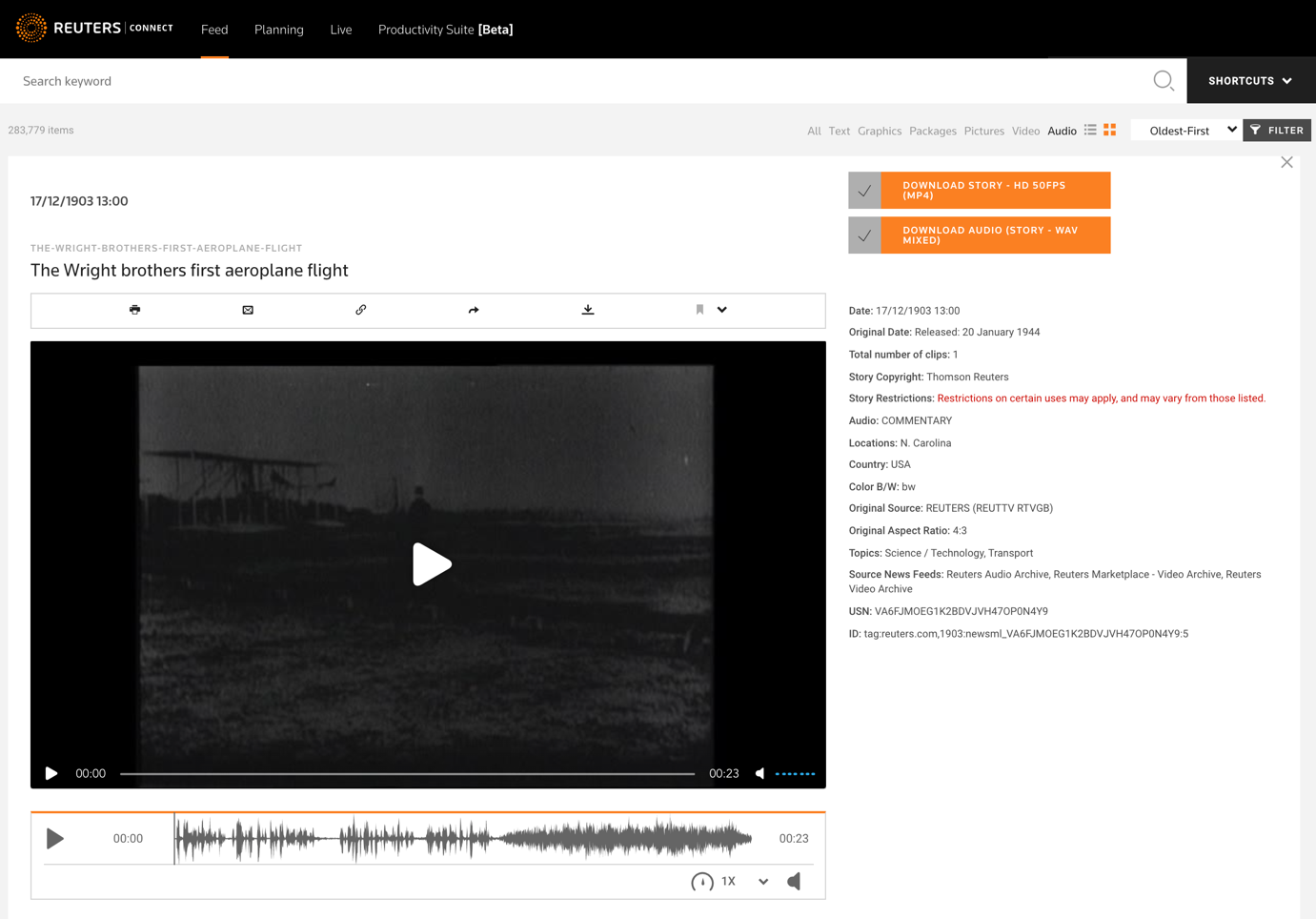
The complexities that arose revolved primarily around finding all the clips in the video archive that contained some audio. Remember, we had already built a workflow that could easily identify speech or natural sound in the videos using machine learning. So, all we had to do was start a batch processing exercise to tag all of the content with additional metadata based on the audio. We classified the content as containing either speech, natural sounds, or no sounds helpful toward determining if there was audio to be sold. We added all of the additional metadata to the news metadata JSON files that we stored in AWS Elasticsearch. This drives which archive clip’s audio tracks are available via Reuters Connect. Then if clients want to purchase those sound bites, we kick off the previously mentioned clip request workflow. We produce and serve out the audio track within seconds, which we then store in Amazon S3.
Here is an example of an archive clip with its audio track available for purchase on Reuters Connect:
Conclusion
With Amazon S3 being our core multimedia storage solution since 2015, moving and building an archive solution a year later on AWS using serverless technologies and managed services was drastically simpler. We managed to do a large-scale batch processing job of 700 TB of content for a fraction of the cost and time compared to doing it on-premises. We were able to set up a scalable, cost-efficient, and rapid clip-request workflow with a wide range of outputs for our customers to use, in addition to a daily ingestion workflow for newly archived content. In summary, we made a more robust, more cost efficient, and more feature-rich solution to better serve our customers with a very unique set of content.
Using and integrating AWS services like Amazon S3, AWS Lambda, Amazon API Gateway, AWS Step Functions, among others, allowed for rapid development and innovation regardless of business complexities or requirements. It laid down the foundations to build on our archive capabilities and add more features in the future for our customers. We were able to reuse many of our initial solutions and applied them to our Reuters Audio offering, a global collection of sound bites spanning more than 100 years. In addition, features like Amazon S3’s various storage classes and the wide variety of instance types and scaling options on Amazon EC2 kept our costs down, which would have been significantly more expensive if we were to build it on premises.
I hope sharing our AWS Cloud experience at Reuters helps you with your own AWS journey, building and managing your content, and providing the best service for your customers. Thanks for reading, and please comment with any questions you may have! The following video recording of my presentation at AWS re:Invent 2019 offers further details on our us of Amazon S3 for the Reuters video archive.
How Thomson Reuters built the Reuters video archive on AWS:
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.