AWS Partner Network (APN) Blog
Accelerating Machine Learning Development with Data Science as a Service from Change Healthcare
By Matt Turner, VP Product Management – Change Healthcare Data Solutions
By Andy Schuetz, PhD, Sr. Startup Solutions Architect – AWS
 |
There is broad acceptance that artificial intelligence (AI) and machine learning (ML) will help improve health outcomes for patients, and make healthcare more affordable.
Accurate and reliable AI/ML solutions require a complete and unbiased picture of patients and populations. Clinical data, such as claims and Electronic Medical Records (EMRs), only provide a portion of the necessary view. Incorporating information about patients’ experiences outside of the care setting is vital to creating more robust insights.
More than 80 percent of health and well-being can be explained by Social Determinants of Health (SDoH). These include factors such as economic stability, education level, transportation, and geospatial proximity to services and healthy food.
Generating a complete and accurate picture of patients and populations necessitates modeling based on multiple, de-identified data sources, and incorporating SDoH. Unfortunately, combining data sets—while adding untold value—adds exponential complexity and an increased risk of patient re-identification.
Data Science as a Service (DSaaS) from Change Healthcare is a secure, managed, healthcare data science platform, loaded with permissioned data at scale, with always-on compliance certification. Customers can leverage the embedded datasets and load their own datasets to be linked to deliver transformative and compliant insights.
In this post, we will show you how AWS ISV Partner Change Healthcare built DSaaS to address the needs of practitioners developing AI/ML algorithms for healthcare, life sciences, and other use cases. We’ll also illustrate the power of DSaaS by demonstrating a real-life use case, training a COVID-19 mortality risk model.
We’ll conclude by sharing how researchers at Duke University School of Medicine are using DSaaS to better understand the COVID-19 pandemic.
Snapshot of Healthcare in America
Data Science as a Service is pre-loaded with de-identified payer, provider, hospital, laboratory, dentist, and pharmacy claims, as well as payment data from all parts of the U.S. healthcare ecosystem.
The data, de-identified to protect privacy, is culled from Change Healthcare’s processing of more than $2 trillion in annual healthcare claims. The result is a unique body of information describing the U.S. healthcare ecosystem that spans geographies, care settings, therapeutic areas, and reimbursement models.
The de-identified data is collected daily, in an unbiased manner. It comprises tens of billions of de-identified healthcare events, including diagnoses, medical procedures, prescriptions, and SDoH. The data is suitable for generating timely insight into trends and opportunities to improve the quality of healthcare products and services.
DSaaS makes this data asset available under rigorous governance, compliance, and security attributes. As a result, the data provided by DSaaS can be used safely and responsibly, leveraging a fully managed analytic platform.
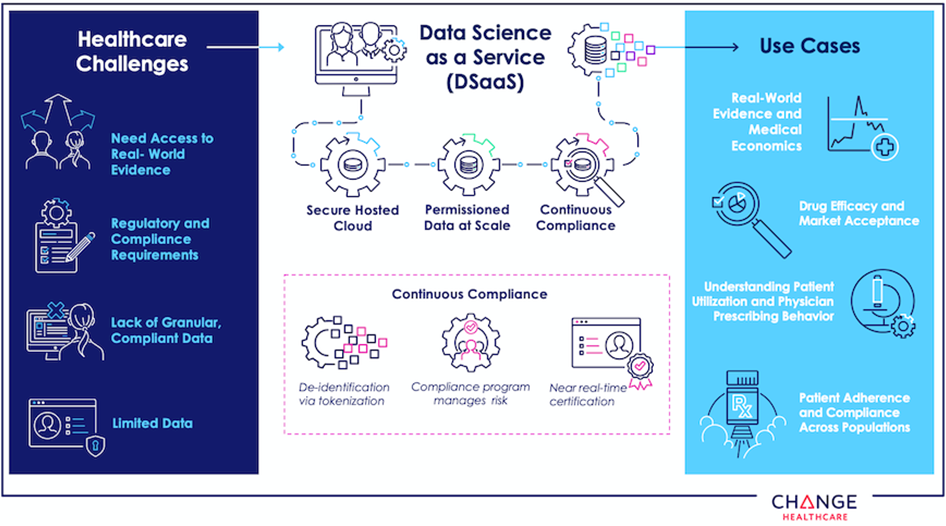
Figure 1 – Overview of the DSaaS solution from Change Healthcare.
DSaaS Architecture
Change Healthcare built DSaaS using AWS services to help provide a secure, compliant, and performant platform for data science with health data. The following diagram provides an overview of the solution architecture.
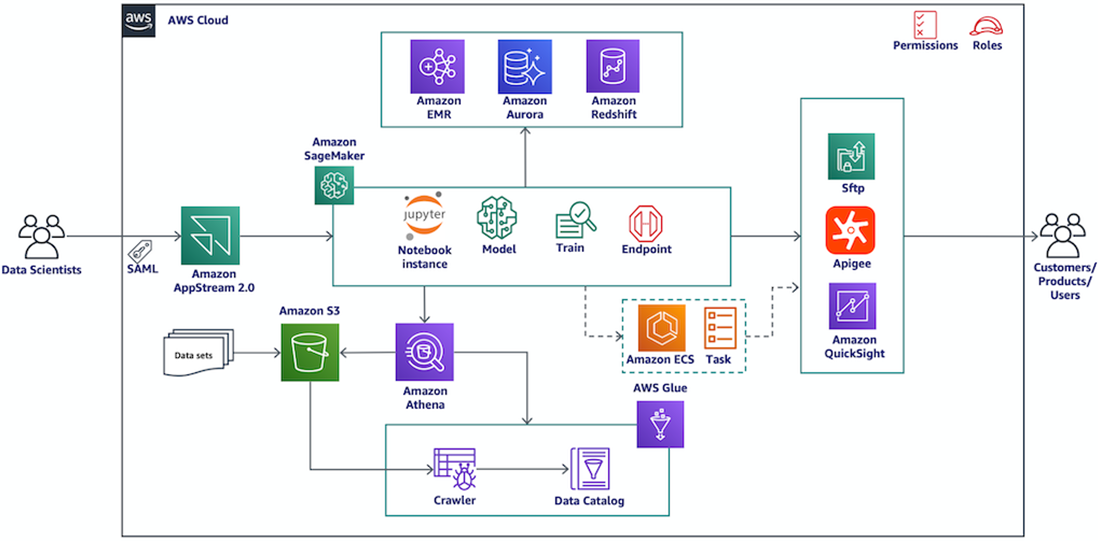
Figure 2 – DSaaS architecture.
The key AWS services used to by the DSaaS platform are:
- Amazon AppStream 2.0 provides secure access to the workbench environment.
- Amazon SageMaker Notebook Instances are backed by the ml.m5.xlarge instance type by default.
- Amazon Simple Storage Service (Amazon S3) securely stores the DSaaS data sets, and any customer data.
- AWS Glue enables serverless data integration and the creation of user-friendly data catalogs.
- Amazon Athena provides a serverless, interactive query service with familiar SQL API.
- Amazon CloudWatch, AWS CloudTrail, AWS Config, and Amazon GuardDuty are used in conjunction with network activity monitoring with virtual private cloud (VPC) flow logs, Amazon S3 access logging, and application logs sent to CloudWatch for security and compliance.
Each DSaaS user is provisioned a private analysis environment, securely accessed through Amazon AppStream 2.0, with SAML support for single sign-on (SSO) via the customer’s identity provider service.
Egress of sensitive data is prevented by permitting user access only through Amazon AppStream 2.0, and by employing administrative controls that disable download, print, and copy/paste actions.
Once authenticated, users have access to an array of popular data science tools within the workbench environment. Most DSaaS users utilize Jupyter notebooks backed by an Amazon SageMaker Notebook Instance. Additional tools like RStudio, a Python terminal, and a bash shell are also available by default.
Upon request, customers can have Amazon EMR clusters, Amazon Redshift data warehouses, and Amazon Aurora provisioned in their environment.
The Change Healthcare DSaaS data sets, and any customer data sets are stored in Amazon S3. All data in S3 is encrypted using server-side encryption with customer master keys (CMKs) stored in AWS Key Management Service (KMS), ensuring protection of all data at rest.
AWS Glue crawlers generate user-friendly data catalogs of the data stored in S3, which are organized in a DSaaS Data Library that users can leverage during their analyses.
Analytic results generated with DSaaS can be exported from the workbench following review to protect privacy. Alternatively, models developed in DSaaS can be hosted on an Amazon SageMaker endpoint, or as a custom container run on Amazon Elastic Container Service (Amazon ECS) within DSaaS, for real-time, production inference.
Doing Data Science with DSaaS
The fully managed DSaaS workbench enables data scientists to quickly begin development with modern tools and unique, patient-level data. To show you how, we’ll step through building a COVID-19 mortality risk model.
We begin by logging into the DSaaS platform through Amazon AppStream 2.0, launching an Amazon SageMaker Notebook Instance with the click of a button, and creating a new Jupyter notebook.
We’ll begin our notebook by building a connection to Amazon Athena, as shown below. This enables us to query the DSaaS Data Library directly from our notebook.
Our model will quantify the associations between an individual’s demographics, selected social determinants of health, and mortality due to COVID-19. Thus, we will assemble data from diagnosis tables, SDoH tables, and patient meta-data tables using SQL queries executed with Amazon Athena.
For brevity’s sake, we’ll skip the SQL statements required to join the tables, and start with a denormalized table called df_1_sdoh.
The df_1_sdoh table contains a column label that indicates whether the individual expired from COVID-19 (1 indicating expired, and 0 otherwise). The table also includes demographics like age, sex, and race, along with a rich set of SDoH variables.
We renamed some of the features to be more self-explanatory, which will make post-training analysis of feature importance more convenient.
Next, we generated some descriptive statistics to help us understand the data, such as quantifying correlations between features, using the pandas-profiling library.
The pandas-profiling library presents results in a polished report format.
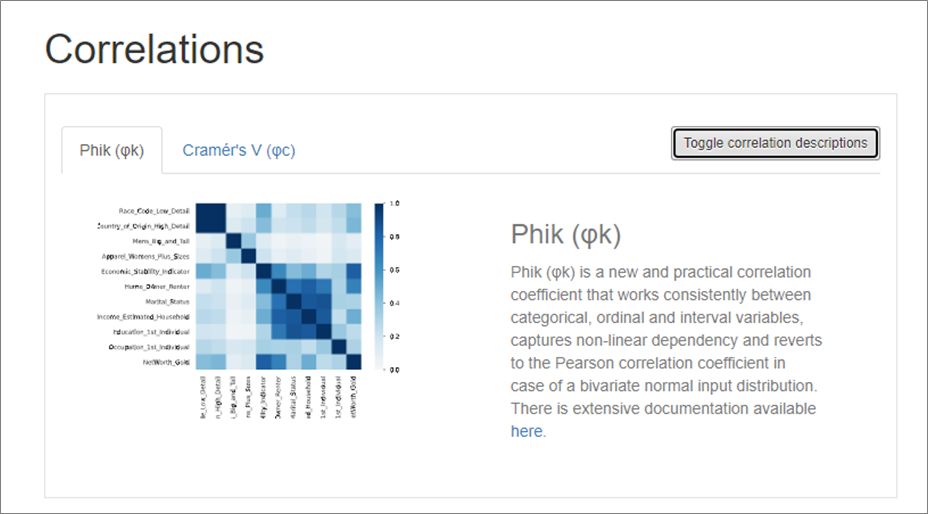
Figure 3 – Report showing correlations between features helps describe relationships within the data.
Comfortable with the data, we can prepare the features for model training. We’ll encode the categorical SDoH feature describing net worth, and one-hot encode ordinal features.
We next split our data into training and test sets, reserving 20 percent of the data for testing.
Now, we can train our COVID-19 mortality risk model as a classifier, using the XGBoost algorithm.
With training complete, we evaluate the performance of our model on the test set by plotting an receiver operating characteristic (ROC ) curve, precision and recall, and F1-score.
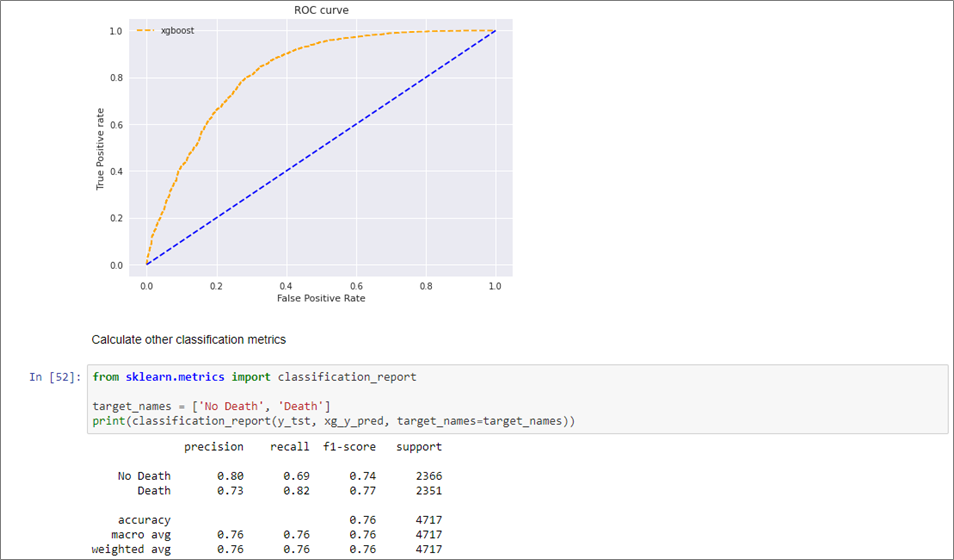
Figure 4 – ROC curve, precision and recall, and F1-score for the trained model.
We can see that our first model generates signal, and predicts mortality risk reasonably well. A confusion matrix helps further evaluate model performance, and we create one with the scikit-learn library.
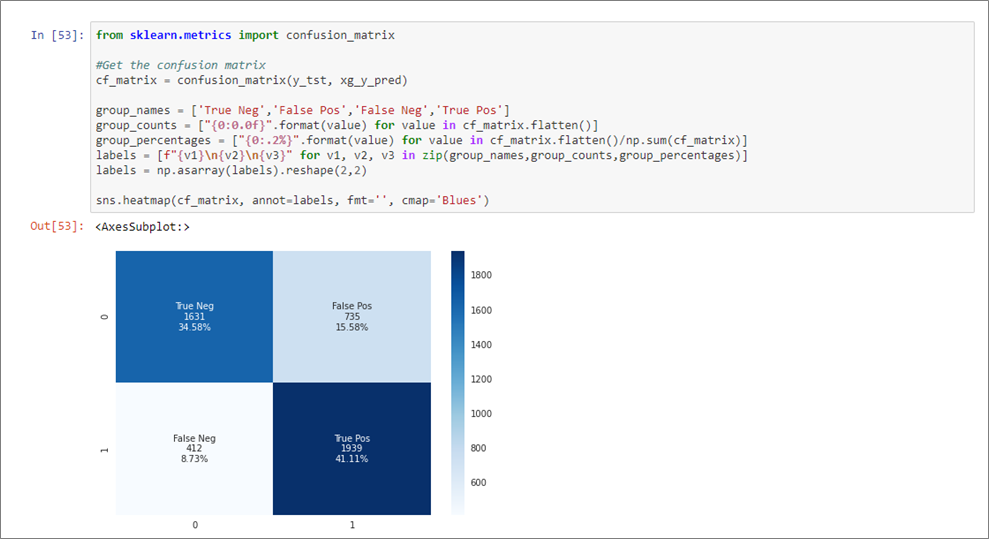
Figure 5 – Confusion matrix summarizing performance of the trained model.
“Explainability,” or an understanding of why an ML model performs well, is often important in the healthcare and life sciences domain, because such models may impact the wellbeing of patients.
We’ll calculate feature importance metrics to explain how the input variables are linked to a COVID-19 mortality prediction. In this case, we use the Shapely Additive Explanations (ShAP) approach to evaluate feature importance, using an open source library.
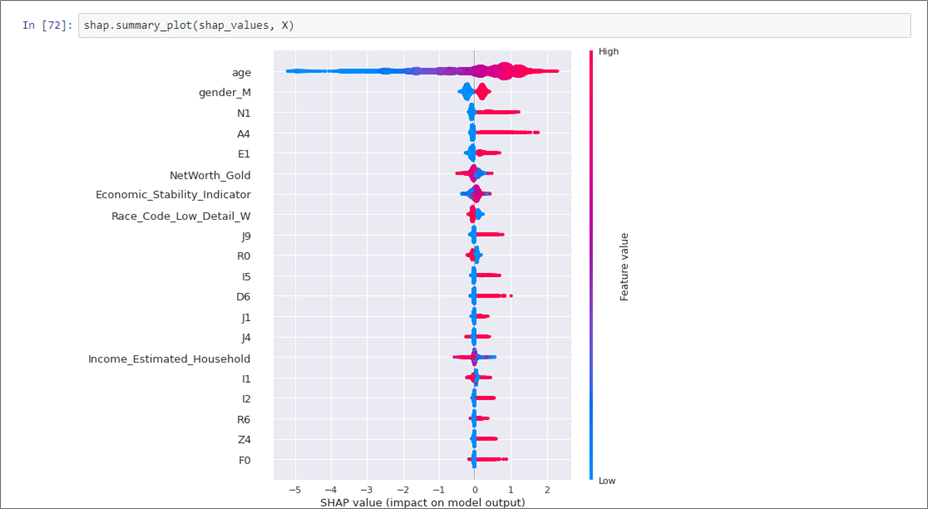
Figure 6 – ShAP estimates of feature importance providing model explainability.
We can see that age and gender are the most important features for predicting mortality from COVID-19. We also see a number of the SDoH features contribute to the model’s predictions.
In this example, DSaaS helped us bypass months of data acquisition, compliance program investment, and infrastructure development. With DSaaS, we were able to dive right into the modeling with patient-level data. Since DSaaS supports popular open source tools, we used the tools we are comfortable with.
Finally, the model we trained incorporated SDoH features to accurately describe the risk of mortality from COVID-19.
Enabling Innovation While Helping Ensure Compliance
One of Change Healthcare’s highest priorities is preserving patient and customer trust through the responsible use of de-identified patient data. Change Healthcare secures appropriate permissions in business-associate agreements with its clients to de-identify and use data for secondary uses.
Aligned with the HIPAA obligation to protect individuals’ Protected Health Information (PII), Change Healthcare is committed to:
- Preserving transparency about the collection, use, and disclosure of patient data.
- Following rigorous policies and procedures concerning how data will be used and shared.
To that end, only de-identified data is made available within DSaaS, so that information about specific patients is always protected. Change Healthcare de-identifies the data in accordance with 45 CFR § 164.514(b) under the HIPAA Privacy Rule using expert determination method.
The de-identification approach, all technical safeguards, and any artifacts exported from the environment are certified by independent expert statisticians.
Change Healthcare works diligently to help ensure every customer’s use of data within DSaaS is compliant with applicable regulation. DSaaS’s always-on compliance ensures the data within the platform cannot be re-identified as a result of modeling/querying.
DSaaS implements technical, physical, and administrative safeguards to protect data, leveraging the AWS Business Associate Addendum (BAA) and AWS Shared Responsibility Model. The solution regularly undergoes audits—and may require customers to do the same—to protect privacy, and adhere to Change Healthcare’s policies and procedures.
No patient data is reachable from the internet. In fact, all patient data within DSaaS resides in a private subnet of the Amazon VPC, with only the AppStream instance accessible from the whitelisted source IP addresses of customers.
The DSaaS solution employs a continuous compliance approach, whereby the compliance of all user activity is continuously evaluated. DSaaS logs all user activity and the logs are available for audit. Automated scanning of logs scours for suspicious activity and raises alerts if found.
DSaaS clients are required to create automated application logs as defined by expert statisticians for enabling technical safeguards. Automated scanning of these logs checks for compliance with defined thresholds.
Similarly, all artifacts that clients need to take out of the environment (aggregated reports or analytics, for example) are checked using automation to ensure that they adhere to defined criteria.
Customer Story
The Duke University School of Medicine uses the Data Science as a Service platform to explore differences in COVID-19 disease progression, pre-existing conditions, and intervention effectiveness for various ethnic and social determinants of health populations.
“Our work on COVID highlights how comparative research needs to better incorporate ethnicity and social determinants to truly assess real world evidence,” says Michael Pencina, Vice Dean for Data Science and Information Technology at Duke University School of Medicine. “DSaaS provides a powerful data science environment with familiar tools for us to do this work.
“Prior to DSaaS,” he adds, “the speed of our research would have been defined by the pace of our independent statistician’s ability to ensure compliance. But the DSaaS environment addresses this automatically, and vastly reduces speed to insight.”
Conclusion
In this post, we showed you how Change Healthcare built its Data Science as a Service (DSaaS) solution on AWS. It comes pre-loaded with de-identified claims and payment data from all parts of the U.S. healthcare ecosystem.
DSaaS also provides granular Social Determinants of Health (SDoH) data that describes the environment of patients and populations.
The DSaaS’s solution’s always-on compliance system ensures data security, and simplifies governance. As result, DSaaS accelerates and reinvents healthcare and life science customers’ development of advanced analytics.
.

.
Change Healthcare – AWS Partner Spotlight
Change Healthcare is an AWS ISV Partner that’s focused on insights, innovation, and accelerating the transformation of the U.S. healthcare system.
Contact Change Healthcare | Partner Overview | AWS Marketplace
*Already worked with Change Healthcare? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.