AWS Partner Network (APN) Blog
Migrating Netezza Workloads to AWS Using Amazon EMR and Amazon Redshift
By Pinkesh Kothana, Solution Architect – Infosys
By Abhijit Vaidya, Sr. Partner Solutions Architect – AWS
 |
| Infosys |
 |
Data warehouse modernization has been a key aspect of many customers’ broader cloud transformation stories. With data warehouse modernization, customers can unlock new insights while substantially improving query and data load performance, increasing scalability, and reducing costs.
Legacy data warehouse systems, however, present many challenges when dealing with today’s enterprise data needs. They lack the flexibility to scale according to business needs and achieve business agility, and they also lack built-in predictive analytics solutions.
Amazon Web Services (AWS) offers a wide range of services and tools in the data and analytics space, which facilitate faster migration and make AWS a highly scalable, performant, and cost-effective platform.
In this post, you will learn how AWS and Infosys collaborated to transform a legacy Netezza platform on AWS for a large retail customer.
Infosys is an AWS Premier Consulting Partner and Managed Service Provider (MSP) that offers different tools and accelerators for a smoother and faster transformation journey to AWS. With Infosys tools, processes, and industry knowledge, the collaboration between AWS and Infosys enables customers to transform their analytics platforms.
Netezza Migration to AWS
Most Netezza customers have an almost decade-old enterprise data warehouse (EDW). Over time, more and more decision-making processes are developed on EDW, making it increasingly complex and hard to re-platform.
For successful migration, it’s critical to have in-depth understanding of current workloads and the corresponding services on AWS. Learn more about Analytics on AWS, which can help organizations quickly get from data to answers by providing mature and integrated services ranging from cloud data warehouses to serverless data lakes.
The migration of Netezza to AWS involves the following phases:
- Assessment/discovery
- Planning
- Migration (data/scripts)
- Testing/validation
- Deployment/cutover
Assessment Phase
The assessment phase is broadly classified into the following four categories:
- Understanding current infrastructure and environment
- Understanding batch/near-real-time workload
- Understanding reporting/consumption patterns
- Orchestration/interdependencies
As a part of understanding the infrastructure, CPU utilization over time (CPU capacity and average CPU utilization), memory utilization (capacity and average memory utilization over time), and storage (max capacity and data volume growth over time) are captured.
For example, the customer had a Netezza Striper with 896 cores and 3.5 TB memory. Netezza stores the data in compressed format, but it’s important to consider data size in uncompressed format (consider 6x Netezza storage). This information helps in right-sizing the AWS infrastructure, especially Amazon Redshift.
The assessment of workloads also involves understanding the number of sources, various ingestion patterns (for example, batch vs. real time), load/compute patterns (such as NZ SQL vs. ETL tools like Informatica), consumption patterns, as well as daily ingested and processed volume.
Consumption assessment provides information about consumption patterns, such as reporting, cubes, data extraction, number of users, and number of reports. In this process, we also need to capture the peak reporting workload along with maximum concurrent users and maximum concurrent reports.
Lastly, the orchestration assessment must be done to obtain the number of batch jobs during weekdays/weekends, maximum/average duration of batch jobs, maximum parallel jobs running during peak workload, and timing of peak load. This information will help in identifying the correct compute mechanism.
Discovery Phase
The objective of the discovery phase is to validate the end-to-end architecture by performing various proofs of concept (POCs) for any potential roadblocks or concerns. This step helps unearth any components that may not be supported or may not be performing as expected.
After the POC validation is complete, the next big exercise is to determine the architecture based on various ingestion, compute, and consumption patterns. The foundation of the architecture is based on the Infosys metadata-driven boundaryless data lake solution on AWS.
A typical architecture on Amazon EMR-PySpark with data lake in Amazon Simple Storage Service (Amazon S3) and reporting on top of Amazon Redshift is depicted here:

Figure 1 – Typical architecture of Netezza to AWS migration.
Planning Phase
After all of this information has been evaluated and the architecture has been finalized, a proper migration strategy can be planned. The following migration strategies must be considered:
- Big bang vs. minimum viable product (MVP) approach: An MVP approach is always preferred, because it allows for a quick win, as well as refinement of the architecture and components as you progress. The strategy also depends on interdependencies of the components and feasibility of segregating the workload.
- Lift and shift vs. retrofit vs. re-engineering vs. hybrid:
- Lift and shift: Migrating the on-premises process with no changes.
- Retrofit: Migrating with minimal changes like storage components and functions compatible to the AWS environment.
- Re-engineering: Redesigning to achieve benefits of the AWS platform.
- Hybrid: Migrating with a mix of the above approaches.
Migration Phase
The AWS Schema Conversion Tool (SCT) and AWS Data Migration Service (DMS) can be used to quickly convert Netezza schema to Amazon Redshift, as well as to perform planned-for migration of small-to-medium volume data from Netezza. High-volume historical data migration (> 1TB) can be planned through AWS Snowball.
The migration of batch scripts involves many predefined, reusable Infosys templates and migration accelerators. Following are key considerations for migrating each of the workload modules or subject areas:
- AWS service considerations (AWS Glue vs. Amazon EMR vs. AWS Lambda)
- Amazon EMR cluster considerations (transient vs. persistent)
- Data lake in Amazon S3 with proper lifecycle policy and encryption
- Amazon Redshift table design and data load pattern
- Performance considerations:
- Aggregate tables
- Materialized views
Netezza has very limited functionality of materialized views, whereas Amazon Redshift materialized views are much more powerful. Thus, it’s important to consider opportunities for moving workloads to materialized views.
In case of MVP-based phased migration, be sure to create a process to refresh from Netezza as well. Your migration strategy should consider the surrogate key conversion process, as surrogate keys will be generated in both Netezza and Redshift but would mean different things in each environment.
Testing Phase
For data warehouse migration, testing is one of the most critical activities, as typically it involves a three-way reconciliation between Netezza, the source systems, and AWS environment with dollar-to-dollar match.
The process also requires continuous validation for a prolonged period—from unit testing (UT) to system integration testing (SIT) to user acceptance testing (UAT) to post-migration reconciliation.
The use of Infosys Data Services Suite (iDSS) and Infosys Testing Data Workbench (iTDW) can accelerate this journey and facilitate automated data reconciliation, as seen in the following image:
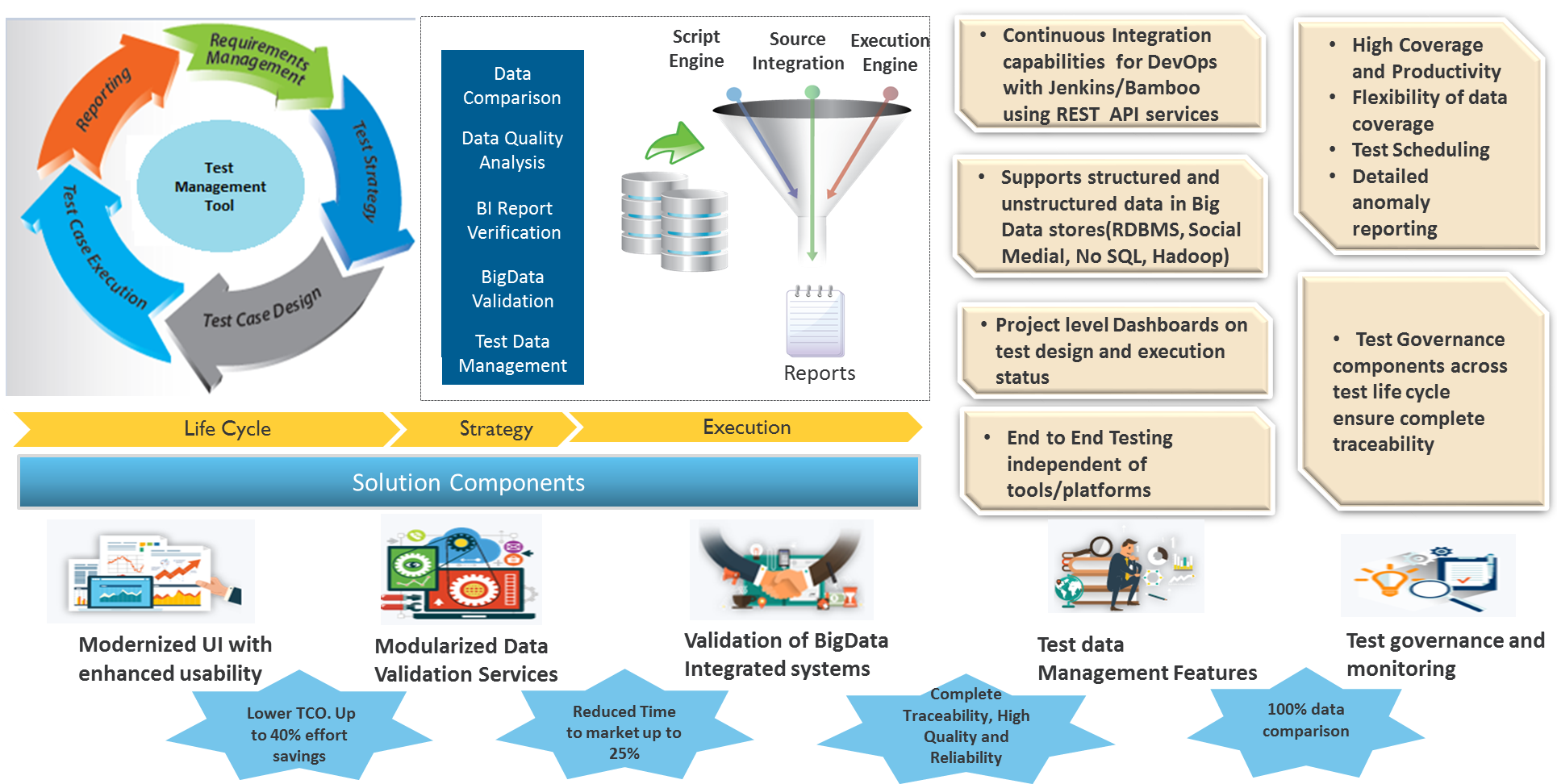
Figure 2 – Testing phase of the Netezza to AWS migration.
Performance Testing
Another key element of the process is to do performance testing much earlier in the migration journey. The Infosys Performance Testing tool enables testing at various levels of peak loads.
The following testing scenarios would help to arrive at or validate the Amazon Redshift cluster size. All of these scenarios can be tested with various node sizes of Amazon Redshift.
| Test scenario | Scenario description |
| Load test 1 | 25%, 50%, 75%, and 100% of peak database reporting load |
| Load test 2 | Load test 1 + cube build |
| Load test 3 | Load test 2 + ETL loads + DB maintenance (grooming, vacuum, etc.) |
| Load test 4 | Load test 3 + real-time loads |
| Load test 5 | 125% peak load (ETL + reporting) + cube build |
Deployment Phase
The deployment phase determines the success of the whole modernization effort. Here, you need to make sure all dependencies are set correctly and all jobs on the critical path are optimized and exceeding or meeting the service level agreement (SLA).
Another key part of deployment is to put mechanisms in place for proper monitoring and alerting. Automated alerts and integration of alerts with failure tickets help minimize risks.
Plan for integration with Amazon Simple Notification Service (SNS) and Amazon Simple Email Service (SES) services for alerting. Automated reconciliation alerts help you proactively work on issues and thereby provide a better user experience.
Post Deployment Phase
A key activity after the deployment phase is to monitor Amazon EMR and Amazon Redshift for resource utilization.
Amazon Redshift provides the capability to elastic resize. Based on usage patterns of Amazon Redshift, you should plan to scale up during peak loads and scale down after peak loads.
Another important parameter for Amazon Redshift is workload management (WLM). You can analyze memory spills, query slot usage (concurrency), and continue to refine WLM.
Additional considerations include:
- Use of AWS Auto Scaling for Amazon EMR.
- Use of Amazon EC2 Spot instances.
- Amazon EMR and Amazon Redshift query performance monitoring and tuning.
Migration Best Practices
- Proof of concept first: Make sure to perform an end-to-end POC involving key components. This ensures conformance and early refinement of the architecture.
- Processing in data lake: Moving processing of data to a data lake (through AWS Lambda/AWS Glue/Amazon EMR) instead of Amazon Redshift has multiple advantages, such as complete processed data availability in the data lake, reduced batch load on Amazon Redshift, database-agnostic processing, and tapping unlimited scaling of the data lake.
- Design patterns: Identify design patterns of various batch loads and create common reusable components for each design pattern; for example, a common component for ELT-based loads.
- MVP-based phased migration: An MVP-based migration is always preferred over the big bang approach, as it helps to stay focused on the limited scope of work and provides the ability to leverage lessons for subsequent migrations.
- Performance: Early simulated performance testing enables right-sizing of the platform and highlights areas for optimization.
- Amazon Redshift WLM and table design: These are key areas that require special focus for the success of your migration. Resource usage must also be monitored post deployment for further refinement of WLM settings.
Customer Success Story
For a large retail customer, Infosys and AWS collaborated to migrate Netezza Striper (EDW) and TwinFin (real-time operational database) to the AWS platform with more than 120 TB of uncompressed data from more than 30 sources and 10,000 reports.
The architecture on AWS used Amazon EMR, Amazon Redshift, Amazon S3, and Amazon Aurora services to process all data and build a data lake for the customer.
Infosys, using various tools and accelerators, implemented the project, which resulted in the following benefits for the customer:
- Three to six times improvement in average response time of reports.
- Combined real-time and batch loads into a single cluster, which was not possible in Netezza due to concurrency limitation.
- Enabled the platform for advanced analytics, such as demand forecasting and clickstream analytics.
- Created a data lake that can be used as a base for all future analytics workloads.
- Retired Netezza appliance and saved annual support and maintenance costs.
The Infosys Way
Infosys seamlessly migrated the large amount of data (120+ TB) and scripts (1,200 NZSql scripts and 1,500 Informatica mappings) from the Netezza environment to AWS. Infosys also performed the following tasks to help the customer mitigate migration risks:
- Leveraged a metadata-based framework for common design patterns.
- Built automated data reconciliation using the Infosys ASWA tool.
- Developed custom-built scripts for automated test environment provisioning with data refresh.
- Automated Amazon Redshift elastic resize and WLM setting changes based on demand and consumption.
Conclusion
Transforming a legacy Netezza data warehouse to AWS native services can be a challenging task. With the right planning, tools, and deep knowledge, AWS and Infosys successfully migrated Netezza to the AWS platform (using Amazon Redshift and Amazon EMR).
The data warehouse now running on AWS allows the customer to scale operations per business needs. Furthermore, the data lake built as a part of this initiative allows the customer to explore new artificial intelligence (AI) and machine learning (ML) capabilities to generate more insights from the data.
Additional Reading
- Infosys Positioned as a Leader in The Forrester Wave: Multicloud Managed Service Providers, Q4 2020
- Big Data Platform Implementation on Amazon Web Services for Norway’s Largest Bank
.

.
Infosys – AWS Partner Spotlight
Infosys is an AWS Premier Consulting Partner and MSP that helps enterprises transform through strategic consulting, operational leadership, and co-creation of solutions in mobility, sustainability, big data, and cloud computing.
Contact Infosys | Partner Overview
*Already worked with Infosys? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.