AWS Big Data Blog

Connect Kafka client applications securely to your Amazon MSK cluster from different VPCs and AWS accounts
You can now use Amazon Managed Streaming for Apache Kafka (Amazon MSK) multi-VPC private connectivity (powered by AWS PrivateLink) and cluster policy support for MSK clusters to simplify connectivity of your Kafka clients to your brokers. Amazon MSK is a fully managed service that makes it easy for you to build and run applications that […]

Use the Amazon Redshift Data API to interact with Amazon Redshift Serverless
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools. Tens of thousands of customers use Amazon Redshift to process exabytes of data per […]
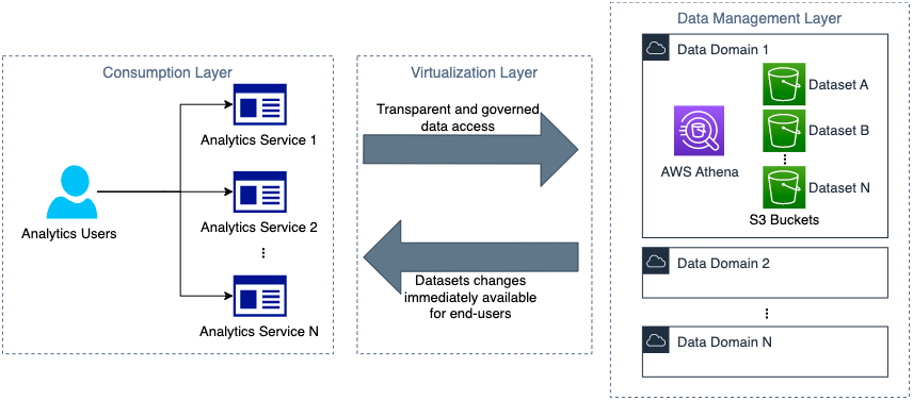
How Novo Nordisk built distributed data governance and control at scale
This is a guest post co-written with Jonatan Selsing and Moses Arthur from Novo Nordisk. This is the second post of a three-part series detailing how Novo Nordisk, a large pharmaceutical enterprise, partnered with AWS Professional Services to build a scalable and secure data and analytics platform. The first post of this series describes the […]

Monitor and optimize cost on AWS Glue for Apache Spark
AWS Glue is a serverless data integration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. You can use AWS Glue to create, run, and monitor data integration and ETL (extract, transform, and load) pipelines and catalog your assets across multiple data stores. One of […]

Top strategies for high volume tracing with Amazon OpenSearch Ingestion
Amazon OpenSearch Ingestion is a serverless, auto-scaled, managed data collector that receives, transforms, and delivers data to Amazon OpenSearch Service domains or Amazon OpenSearch Serverless collections. OpenSearch Ingestion is powered by Data Prepper, an open-source, streaming ETL (extract, transform, and load) solution that’s part of the OpenSearch project. When you use OpenSearch Ingestion, you don’t […]

Perform upserts in a data lake using Amazon Athena and Apache Iceberg
Amazon Athena supports the MERGE command on Apache Iceberg tables, which allows you to perform inserts, updates, and deletes in your data lake at scale using familiar SQL statements that are compliant with ACID (Atomic, Consistent, Isolated, Durable). Apache Iceberg is an open table format for data lakes that manages large collections of files as […]

Working with percolators in Amazon OpenSearch Service
Amazon OpenSearch Service is a managed service that makes it easy to secure, deploy, and operate OpenSearch and legacy Elasticsearch clusters at scale in the AWS Cloud. Amazon OpenSearch Service provisions all the resources for your cluster, launches it, and automatically detects and replaces failed nodes, reducing the overhead of self-managed infrastructures. The service makes it […]

How the BMW Group analyses semiconductor demand with AWS Glue
This is a guest post co-written by Maik Leuthold and Nick Harmening from BMW Group. The BMW Group is headquartered in Munich, Germany, where the company oversees 149,000 employees and manufactures cars and motorcycles in over 30 production sites across 15 countries. This multinational production strategy follows an even more international and extensive supplier network. Like many automobile companies across the world, the […]

How Huron built an Amazon QuickSight Asset Catalogue with AWS CDK Based Deployment Pipeline
This is a guest blog post co-written with Corey Johnson from Huron. Having an accurate and up-to-date inventory of all technical assets helps an organization ensure it can keep track of all its resources with metadata information such as their assigned owners, last updated date, used by whom, how frequently, and more. It helps engineers, […]

How Dafiti made Amazon QuickSight its primary data visualization tool
This is a guest post by Valdiney Gomes, Hélio Leal, and Flávia Lima from Dafiti. Data and its various uses is increasingly evident in companies, and each professional has their preferences about which technologies to use to visualize data, which isn’t necessarily in line with the technological needs and infrastructure of a company. At Dafiti, […]