Artificial Intelligence
Category: Learning Levels

Perform generative AI-powered data prep and no-code ML over any size of data using Amazon SageMaker Canvas
Amazon SageMaker Canvas now empowers enterprises to harness the full potential of their data by enabling support of petabyte-scale datasets. Starting today, you can interactively prepare large datasets, create end-to-end data flows, and invoke automated machine learning (AutoML) experiments on petabytes of data—a substantial leap from the previous 5 GB limit. With over 50 connectors, […]

Derive generative AI-powered insights from ServiceNow with Amazon Q Business
This post shows how to configure the Amazon Q ServiceNow connector to index your ServiceNow platform and take advantage of generative AI searches in Amazon Q. We use an example of an illustrative ServiceNow platform to discuss technical topics related to AWS services.

Discover insights from Box with the Amazon Q Box connector
Seamless access to content and insights is crucial for delivering exceptional customer experiences and driving successful business outcomes. Box, a leading cloud content management platform, serves as a central repository for diverse digital assets and documents in many organizations. An enterprise Box account typically contains a wealth of materials, including documents, presentations, knowledge articles, and […]
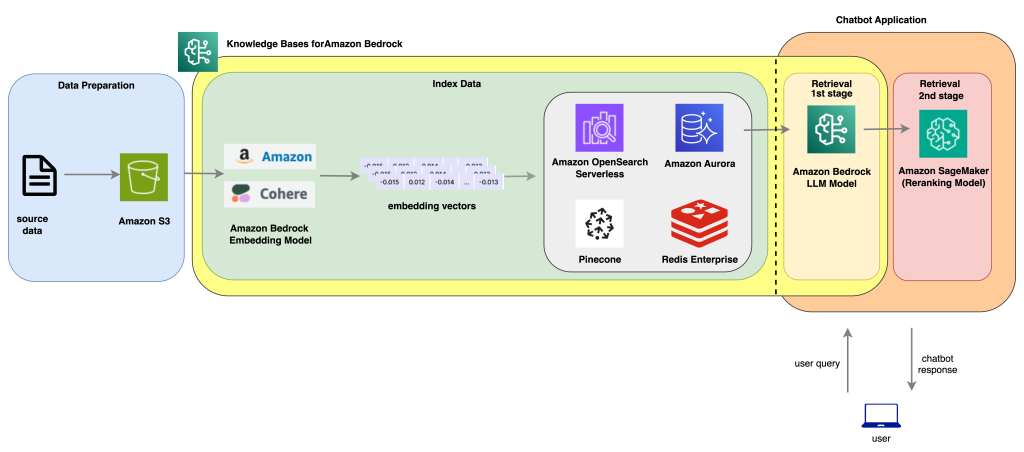
Improve AI assistant response accuracy using Knowledge Bases for Amazon Bedrock and a reranking model
AI chatbots and virtual assistants have become increasingly popular in recent years thanks the breakthroughs of large language models (LLMs). Trained on a large volume of datasets, these models incorporate memory components in their architectural design, allowing them to understand and comprehend textual context. Most common use cases for chatbot assistants focus on a few […]

Automate the machine learning model approval process with Amazon SageMaker Model Registry and Amazon SageMaker Pipelines
This post illustrates how to use common architecture principles to transition from a manual monitoring process to one that is automated. You can use these principles and existing AWS services such as Amazon SageMaker Model Registry and Amazon SageMaker Pipelines to deliver innovative solutions to your customers while maintaining compliance for your ML workloads.

Inference AudioCraft MusicGen models using Amazon SageMaker
Music generation models have emerged as powerful tools that transform natural language text into musical compositions. Originating from advancements in artificial intelligence (AI) and deep learning, these models are designed to understand and translate descriptive text into coherent, aesthetically pleasing music. Their ability to democratize music production allows individuals without formal training to create high-quality […]

Build an end-to-end RAG solution using Amazon Bedrock Knowledge Bases and AWS CloudFormation
Retrieval Augmented Generation (RAG) is a state-of-the-art approach to building question answering systems that combines the strengths of retrieval and foundation models (FMs). RAG models first retrieve relevant information from a large corpus of text and then use a FM to synthesize an answer based on the retrieved information. An end-to-end RAG solution involves several […]

Few-shot prompt engineering and fine-tuning for LLMs in Amazon Bedrock
This blog is part of the series, Generative AI and AI/ML in Capital Markets and Financial Services. Company earnings calls are crucial events that provide transparency into a company’s financial health and prospects. Earnings reports detail a firm’s financials over a specific period, including revenue, net income, earnings per share, balance sheet, and cash flow […]

Use the ApplyGuardrail API with long-context inputs and streaming outputs in Amazon Bedrock
As generative artificial intelligence (AI) applications become more prevalent, maintaining responsible AI principles becomes essential. Without proper safeguards, large language models (LLMs) can potentially generate harmful, biased, or inappropriate content, posing risks to individuals and organizations. Applying guardrails helps mitigate these risks by enforcing policies and guidelines that align with ethical principles and legal requirements.Amazon […]

Configure Amazon Q Business with AWS IAM Identity Center trusted identity propagation
Amazon Q Business comes with rich API support to perform administrative tasks or to build an AI-assistant with customized user experience for your enterprise. With administrative APIs you can automate creating Q Business applications, set up data source connectors, build custom document enrichment, and configure guardrails. With conversation APIs, you can chat and manage conversations with Q Business AI assistant. Trusted identity propagation provides authorization based on user context, which enhances the privacy controls of Amazon Q Business. In this blog post, you will learn what trusted identity propagation is and why to use it, how to automate configuration of a trusted token issuer in AWS IAM Identity Center with provided AWS CloudFormation templates, and what APIs to invoke from your application facilitate calling Amazon Q Business identity-aware conversation APIs.