Artificial Intelligence
Category: Amazon Simple Storage Service (S3)
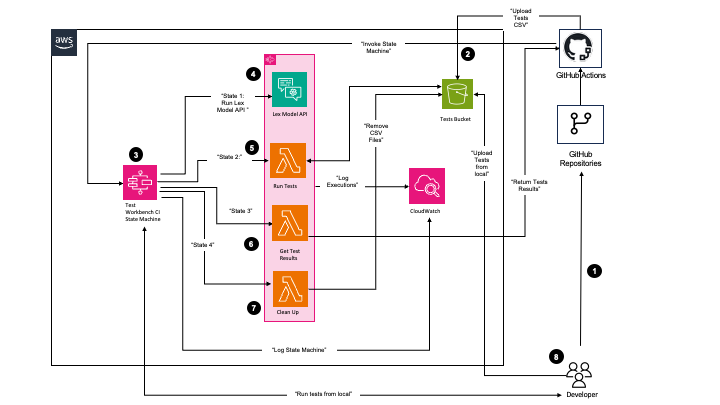
Principal Financial Group accelerates build, test, and deployment of Amazon Lex V2 bots through automation
In the post Principal Financial Group increases Voice Virtual Assistant performance using Genesys, Amazon Lex, and Amazon QuickSight, we discussed the overall Principal Virtual Assistant solution using Genesys Cloud, Amazon Lex V2, multiple AWS services, and a custom reporting and analytics solution using Amazon QuickSight.

Splash Music transforms music generation using AWS Trainium and Amazon SageMaker HyperPod
In this post, we show how Splash Music is setting a new standard for AI-powered music creation by using its advanced HummingLM model with AWS Trainium on Amazon SageMaker HyperPod. As a selected startup in the 2024 AWS Generative AI Accelerator, Splash Music collaborated closely with AWS Startups and the AWS Generative AI Innovation Center (GenAIIC) to fast-track innovation and accelerate their music generation FM development lifecycle.

Build an AI assistant using Amazon Q Business with Amazon S3 clickable URLs
In this post, we demonstrate how to build an AI assistant using Amazon Q Business that responds to user requests based on your enterprise documents stored in an S3 bucket, and how the users can use the reference URLs in the AI assistant responses to view or download the referred documents, and verify the AI responses to practice responsible AI.

Enabling customers to deliver production-ready AI agents at scale
Today, I’m excited to share how we’re bringing this vision to life with new capabilities that address the fundamental aspects of building and deploying agents at scale. These innovations will help you move beyond experiments to production-ready agent systems that can be trusted with your most critical business processes.

Build secure RAG applications with AWS serverless data lakes
In this post, we explore how to build a secure RAG application using serverless data lake architecture, an important data strategy to support generative AI development. We use Amazon Web Services (AWS) services including Amazon S3, Amazon DynamoDB, AWS Lambda, and Amazon Bedrock Knowledge Bases to create a comprehensive solution supporting unstructured data assets which can be extended to structured data. The post covers how to implement fine-grained access controls for your enterprise data and design metadata-driven retrieval systems that respect security boundaries. These approaches will help you maximize the value of your organization’s data while maintaining robust security and compliance.

Uphold ethical standards in fashion using multimodal toxicity detection with Amazon Bedrock Guardrails
In the fashion industry, teams are frequently innovating quickly, often utilizing AI. Sharing content, whether it be through videos, designs, or otherwise, can lead to content moderation challenges. There remains a risk (through intentional or unintentional actions) of inappropriate, offensive, or toxic content being produced and shared. In this post, we cover the use of the multimodal toxicity detection feature of Amazon Bedrock Guardrails to guard against toxic content. Whether you’re an enterprise giant in the fashion industry or an up-and-coming brand, you can use this solution to screen potentially harmful content before it impacts your brand’s reputation and ethical standards. For the purposes of this post, ethical standards refer to toxic, disrespectful, or harmful content and images that could be created by fashion designers.

Using Amazon SageMaker AI Random Cut Forest for NASA’s Blue Origin spacecraft sensor data
In this post, we demonstrate how to use SageMaker AI to apply the Random Cut Forest (RCF) algorithm to detect anomalies in spacecraft position, velocity, and quaternion orientation data from NASA and Blue Origin’s demonstration of lunar Deorbit, Descent, and Landing Sensors (BODDL-TP).

Fast-track SOP processing using Amazon Bedrock
When a regulatory body like the US Food and Drug Administration (FDA) introduces changes to regulations, organizations are required to evaluate the changes against their internal SOPs. When necessary, they must update their SOPs to align with the regulation changes and maintain compliance. In this post, we show different approaches using Amazon Bedrock to identify relationships between regulation changes and SOPs.

A generative AI prototype with Amazon Bedrock transforms life sciences and the genome analysis process
This post explores deploying a text-to-SQL pipeline using generative AI models and Amazon Bedrock to ask natural language questions to a genomics database. We demonstrate how to implement an AI assistant web interface with AWS Amplify and explain the prompt engineering strategies adopted to generate the SQL queries. Finally, we present instructions to deploy the service in your own AWS account.

WordFinder app: Harnessing generative AI on AWS for aphasia communication
In this post, we showcase how Dr. Kori Ramajoo, Dr. Sonia Brownsett, Prof. David Copland, from QARC, and Scott Harding, a person living with aphasia, used AWS services to develop WordFinder, a mobile, cloud-based solution that helps individuals with aphasia increase their independence through the use of AWS generative AI technology.