Artificial Intelligence
Category: Storage

How Formula 1® uses generative AI to accelerate race-day issue resolution
In this post, we explain how F1 and AWS have developed a root cause analysis (RCA) assistant powered by Amazon Bedrock to reduce manual intervention and accelerate the resolution of recurrent operational issues during races from weeks to minutes. The RCA assistant enables the F1 team to spend more time on innovation and improving its services, ultimately delivering an exceptional experience for fans and partners. The successful collaboration between F1 and AWS showcases the transformative potential of generative AI in empowering teams to accomplish more in less time.

Accelerate digital pathology slide annotation workflows on AWS using H-optimus-0
In this post, we demonstrate how to use H-optimus-0 for two common digital pathology tasks: patch-level analysis for detailed tissue examination, and slide-level analysis for broader diagnostic assessment. Through practical examples, we show you how to adapt this FM to these specific use cases while optimizing computational resources.

Embodied AI Chess with Amazon Bedrock
In this post, we demonstrate Embodied AI Chess with Amazon Bedrock, bringing a new dimension to traditional chess through generative AI capabilities. Our setup features a smart chess board that can detect moves in real time, paired with two robotic arms executing those moves. Each arm is controlled by different FMs—base or custom. This physical implementation allows you to observe and experiment with how different generative AI models approach complex gaming strategies in real-world chess matches.

How Crexi achieved ML models deployment on AWS at scale and boosted efficiency
Commercial Real Estate Exchange, Inc. (Crexi), is a digital marketplace and platform designed to streamline commercial real estate transactions. In this post, we will review how Crexi achieved its business needs and developed a versatile and powerful framework for AI/ML pipeline creation and deployment. This customizable and scalable solution allows its ML models to be efficiently deployed and managed to meet diverse project requirements.

Multilingual content processing using Amazon Bedrock and Amazon A2I
This post outlines a custom multilingual document extraction and content assessment framework using a combination of Anthropic’s Claude 3 on Amazon Bedrock and Amazon A2I to incorporate human-in-the-loop capabilities.

Build a reverse image search engine with Amazon Titan Multimodal Embeddings in Amazon Bedrock and AWS managed services
In this post, you will learn how to extract key objects from image queries using Amazon Rekognition and build a reverse image search engine using Amazon Titan Multimodal Embeddings from Amazon Bedrock in combination with Amazon OpenSearch Serverless Service.

Implement Amazon SageMaker domain cross-Region disaster recovery using custom Amazon EFS instances
In this post, we guide you through a step-by-step process to seamlessly migrate and safeguard your SageMaker domain from one active Region to another passive or active Region, including all associated user profiles and files.

Use Amazon SageMaker Studio with a custom file system in Amazon EFS
In this post, we explore three scenarios demonstrating the versatility of integrating Amazon EFS with SageMaker Studio. These scenarios highlight how Amazon EFS can provide a scalable, secure, and collaborative data storage solution for data science teams.
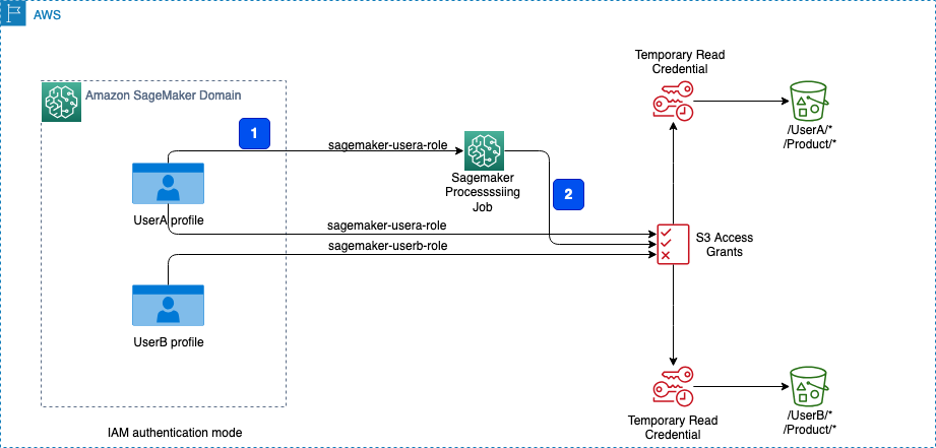
Control data access to Amazon S3 from Amazon SageMaker Studio with Amazon S3 Access Grants
In this post, we demonstrate how to simplify data access to Amazon S3 from SageMaker Studio using S3 Access Grants, specifically for different user personas using IAM principals.

Making traffic lights more efficient with Amazon Rekognition
In this blog post, we show you how Amazon Rekognition can mitigate congestion at traffic intersections and reduce operations and maintenance costs.