Artificial Intelligence
Demystifying machine learning at the edge through real use cases
October 2023: Starting in April 26th, 2024, you can no longer access Amazon SageMaker Edge Manager. For more information about continuing to deploy your models to edge devices, see SageMaker Edge Manager end of life.
Edge is a term that refers to a location, far from the cloud or a big data center, where you have a computer device (edge device) capable of running (edge) applications. Edge computing is the act of running workloads on these edge devices. Machine learning at the edge (ML@Edge) is a concept that brings the capability of running ML models locally to edge devices. These ML models can then be invoked by the edge application. ML@Edge is important for many scenarios where raw data is collected from sources far from the cloud. These scenarios may also have specific requirements or restrictions:
- Low-latency, real-time predictions
- Poor or non-existing connectivity to the cloud
- Legal restrictions that don’t allow sending data to external services
- Large datasets that need to be preprocessed locally before sending responses to the cloud
The following are some of many use cases that can benefit from ML models running close to the equipment that generates the data used for the predictions:
- Security and safety – A restricted area where heavy machines operate in an automated port is monitored by a camera. If a person enters this area by mistake, a safety mechanism is activated to stop the machines and protect the human.
- Predictive maintenance – Vibration and audio sensors collect data from a gearbox of a wind turbine. An anomaly detection model processes the sensor data and identifies if anomalies with the equipment. If an anomaly is detected, the edge device can start a contingency measurement in real time to avoid damaging the equipment, like engage the breaks or disconnect the generator from the grid.
- Defect detection in production lines – A camera captures images of products on a conveyor belt and process the frames with an image classification model. If a defect is detected, the product can be discarded automatically without manual intervention.
Although ML@Edge can address many use cases, there are complex architectural challenges that need to be solved in order to have a secure, robust, and reliable design. In this post, you learn some details about ML@Edge, related topics, and how to use AWS services to overcome these challenges and implement a complete solution for your ML at the edge workload.
ML@Edge overview
There is a common confusion when it comes to ML@Edge and Internet of Things (IoT), therefore it’s important to clarify how ML@Edge is different from IoT and how they both could come together to provide a powerful solution in certain cases.
An edge solution that uses ML@Edge has two main components: an edge application and an ML model (invoked by the application) running on the edge device. ML@Edge is about controlling the lifecycle of one or more ML models deployed to a fleet of edge devices. The ML model lifecycle can start on the cloud side (on Amazon SageMaker, for instance) but normally ends on a standalone deployment of the model on the edge device. Each scenario demands different ML model lifecycles that can be composed by many stages, such as data collection; data preparation; model building, compilation, and deployment to the edge device; model loading and running; and repeating the lifecycle.
The ML@Edge mechanism is not responsible for the application lifecycle. A different approach should be adopted for that purpose. Decoupling the ML model lifecycle and application lifecycle gives you the freedom and flexibility to keep evolving them at different paces. Imagine a mobile application that embeds an ML model as a resource like an image or XML file. In this case, each time you train a new model and want to deploy it to the mobile phones, you need to redeploy the whole application. This consumes time and money, and can introduce bugs to your application. By decoupling the ML model lifecycle, you publish the mobile app one time and deploy as many versions of the ML model as you need.
But how does IoT correlate to ML@Edge? IoT relates to physical objects embedded with technologies like sensors, processing ability, and software. These objects are connected to other devices and systems over the internet or other communication networks, in order to exchange data. The following figure illustrates this architecture. The concept was initially created when thinking of simple devices that just collect data from the edge, perform simple local processing, and send the result to a more powerful computing unity that runs analytics processes that help people and companies in their decision-making. The IoT solution is responsible for controlling the edge application lifecycle. For more information about IoT, refer to Internet of things.
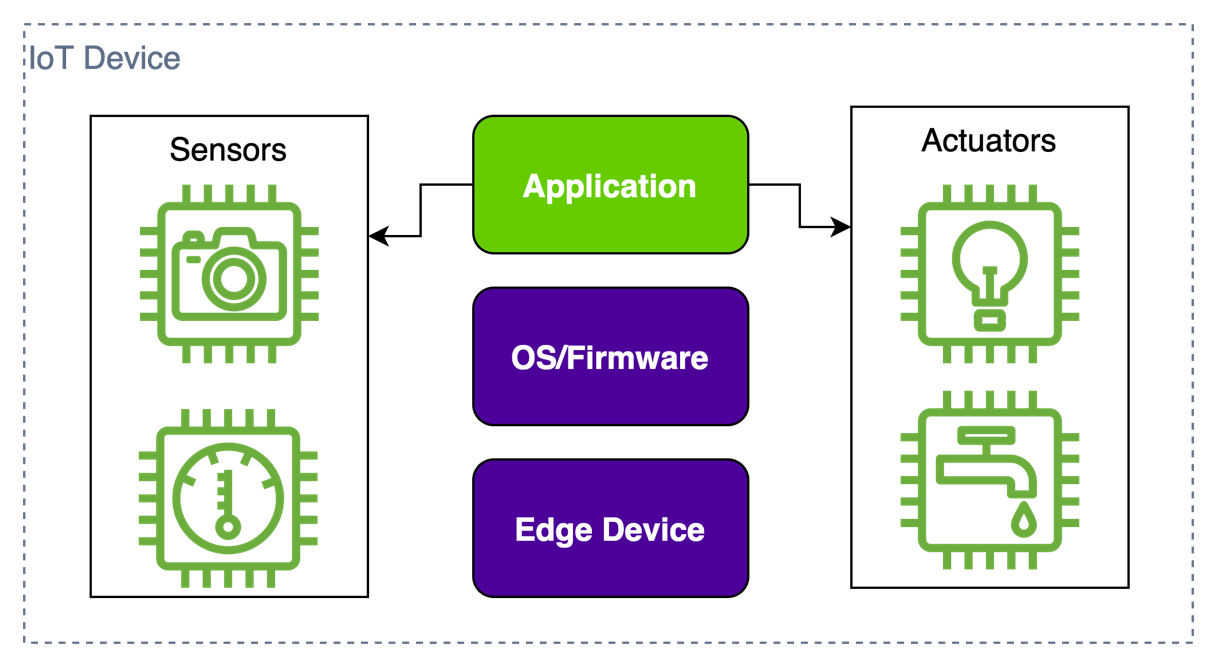
If you already have an IoT application, you can add ML@Edge capabilities to make the product more efficient, as shown in the following figure. Keep in mind that ML@Edge doesn’t depend on IoT, but you can combine them to create a more powerful solution. When you do that, you improve the potential of your simple device to generate real-time insights for your business faster than just sending data to the cloud for later processing.
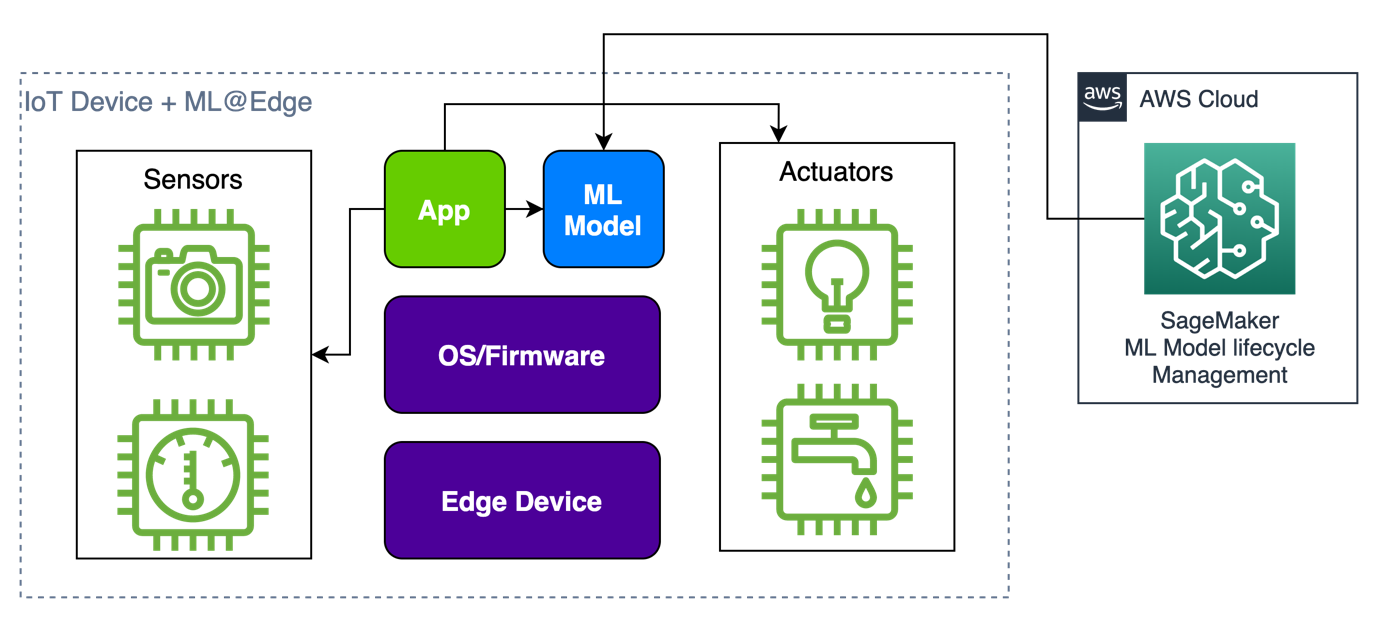
If you’re creating a new edge solution from scratch with ML@Edge capabilities, it’s important to design a flexible architecture that supports both the application and ML model lifecycles. We provide some reference architectures for edge applications with ML@Edge later in this post. But first, let’s dive deeper into edge computing and learn how to choose the correct edge device for your solution, based on the restrictions of the environment.
Edge computing
Depending on how far the device is from the cloud or a big data center (base), three main characteristics of the edge devices need to be considered to maximize performance and longevity of the system: computing and storage capacity, connectivity, and power consumption. The following diagram shows three groups of edge devices that combine different specifications of these characteristics, depending on how far from they are from the base.
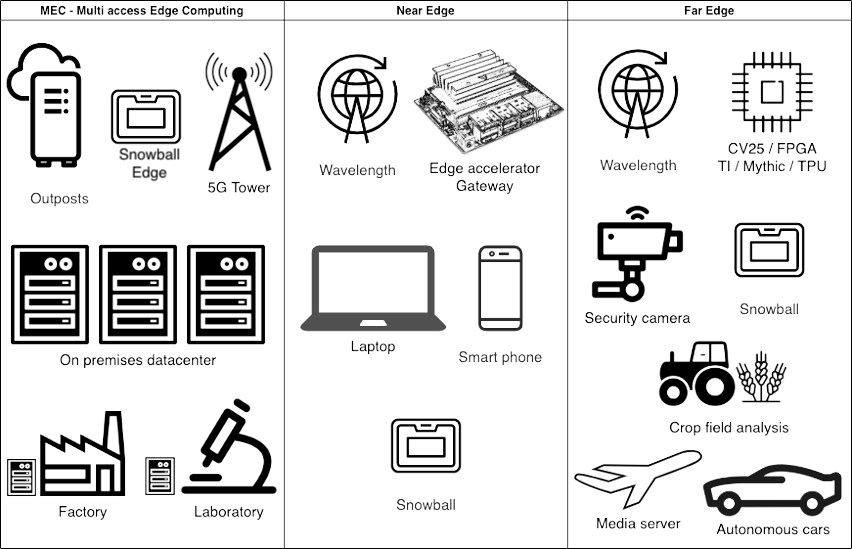
The groups are as follows:
- MECs (Multi-access Edge Computing) – MECs or small data centers, characterized by low or ultra-low latency and high bandwidth, are common environments where ML@Edge can bring benefits without big restrictions when compared to cloud workloads. 5G antennas and servers at factories, warehouses, laboratories, and so on with minimal energy constraints and with good internet connectivity offer different ways to run ML models on GPUs and CPUs, virtual machines, containers, and bare-metal servers.
- Near edge – This is when mobility or data aggregation are requirements and the devices have some constraints regarding power consumption and processing power, but still have some reliable connectivity, although with higher latency, with limited throughput and more expensive than “close to the edge.” Mobile applications, specific boards to accelerate ML models, or simple devices with capacity to run ML models, covered by wireless networks, are included in this group.
- Far edge – In this extreme scenario, edge devices have severe power consumption or connectivity constraints. Consequently, processing power is also restricted in many far edge scenarios. Agriculture, mining, surveillance and security, and maritime transportation are some areas where far edge devices play an important role. Simple boards, normally without GPUs or other AI accelerators, are common. They are designed to load and run simple ML models, save the predictions in a local database, and sleep until the next prediction cycle. The devices that need to process real-time data can have big local storages to avoid losing data.
Challenges
It’s common to have ML@Edge scenarios where you have hundreds or thousands (maybe even millions) of devices running the same models and edge applications. When you scale your system, it’s important to have a robust solution that can manage the number of devices that you need to support. This is a complex task and for these scenarios, you need to ask many questions:
- How do I operate ML models on a fleet of devices at the edge?
- How do I build, optimize, and deploy ML models to multiple edge devices?
- How do I secure my model while deploying and running it at the edge?
- How do I monitor my model’s performance and retrain it, if needed?
- How do I eliminate the need of installing a big framework like TensorFlow or PyTorch on my restricted device?
- How do I expose one or multiple models with my edge application as a simple API?
- How do I create a new dataset with the payloads and predictions captured by the edge devices?
- How do I do all these tasks automatically (MLOps plus ML@Edge)?
In the next section, we provide answers to all these questions through example use cases and reference architectures. We also discuss which AWS services you can combine to build complete solutions for each of the explored scenarios. However, if you want to start with a very simple flow that describes how to use some of the services provided by AWS to create your ML@Edge solution, this is an example:
With SageMaker, you can easily prepare a dataset and build the ML models that are deployed to the edge devices. With Amazon SageMaker Neo, you can compile and optimize the model you trained to the specific edge device you chose. After compiling the model, you only need a light runtime to run it (provided by the service). Amazon SageMaker Edge Manager is responsible for managing the lifecycle of all ML models deployed to your fleet of edge devices. Edge Manager can manage fleets of up to millions of devices. An agent, installed to each one of the edge devices, exposes the deployed ML models as an API to the application. The agent is also responsible for collecting metrics, payloads, and predictions that you can use for monitoring or building a new dataset to retrain the model if needed. Finally, with Amazon SageMaker Pipelines, you can create an automated pipeline with all the steps required to build, optimize, and deploy ML models to your fleet of devices. This automated pipeline can then be triggered by simple events you define, without human intervention.
Use case 1
Let’s say an airplane manufacturer wants to detect and track parts and tools in the production hangar. To improve productivity, all the required parts and correct tools need to be available for the engineers at each stage of production. We want to be able to answer questions like: Where is part A? or Where is tool B? We have multiple IP cameras already installed and connected to a local network. The cameras cover the entire hangar and can stream real-time HD video through the network.
AWS Panorama fits in nicely in this case. AWS Panorama provides an ML appliance and managed service that enables you to add computer vision (CV) to your existing fleet of IP cameras and automate. AWS Panorama gives you the ability to add CV to your existing Internet Protocol (IP) cameras and automate tasks that traditionally require human inspection and monitoring.
In the following reference architecture, we show the major components of the application running on an AWS Panorama Appliance. The Panorama Application SDK makes it easy to capture video from camera streams, perform inference with a pipeline of multiple ML models, and process the results using Python code running inside a container. You can run models from any popular ML library such as TensorFlow, PyTorch, or TensorRT. The results from the model can be integrated with business systems on your local area network, allowing you to respond to events in real time.

The solution consists of the following steps:
- Connect and configure an AWS Panorama device to the same local network.
- Train an ML model (object detection) to identify parts and tools in each frame.
- Build an AWS Panorama Application that gets the predictions from the ML model, applies a tracking mechanism to each object, and sends the results to a real-time database.
- The operators can send queries to the database to locate the parts and tools.
Use case 2
For our next use case, imagine we’re creating a dashcam for vehicles capable of supporting the driver in many situations, such as avoiding pedestrians, based on a CV25 board from Ambaralla. Hosting ML models on a device with limited system resources can be difficult. In this case, let’s assume we already have a well-established over-the-air (OTA) delivery mechanism in place to deploy the application components needed on to the edge device. However, we would still benefit from ability to do OTA deployment of the model itself, thereby isolating the application lifecycle and model lifecycle.
Amazon SageMaker Edge Manager and Amazon SageMaker Neo fit well for this use case.
Edge Manager makes it easy for ML edge developers to use the same familiar tools in the cloud or on edge devices. It reduces the time and effort required to get models to production, while allowing you to continuously monitor and improve model quality across your device fleet. SageMaker Edge includes an OTA deployment mechanism that helps you deploy models on the fleet independent of the application or device firmware. The Edge Manager agent allows you to run multiple models on the same device. The agent collects prediction data based on the logic that you control, such as intervals, and uploads it to the cloud so that you can periodically retrain your models over time. SageMaker Edge cryptographically signs your models so you can verify that it wasn’t tampered with as it moves from the cloud to edge device.
Neo is a compiler as a service and an especially good fit in this use case. Neo automatically optimizes ML models for inference on cloud instances and edge devices to run faster with no loss in accuracy. You start with an ML model built with one of supported frameworks and trained in SageMaker or anywhere else. Then you choose your target hardware platform, (refer to the list of supported devices). With a single click, Neo optimizes the trained model and compiles it into a package that can be run using the lightweight SageMaker Edge runtime. The compiler uses an ML model to apply the performance optimizations that extract the best available performance for your model on the cloud instance or edge device. You then deploy the model as a SageMaker endpoint or on supported edge devices and start making predictions.
The following diagram illustrates this architecture.
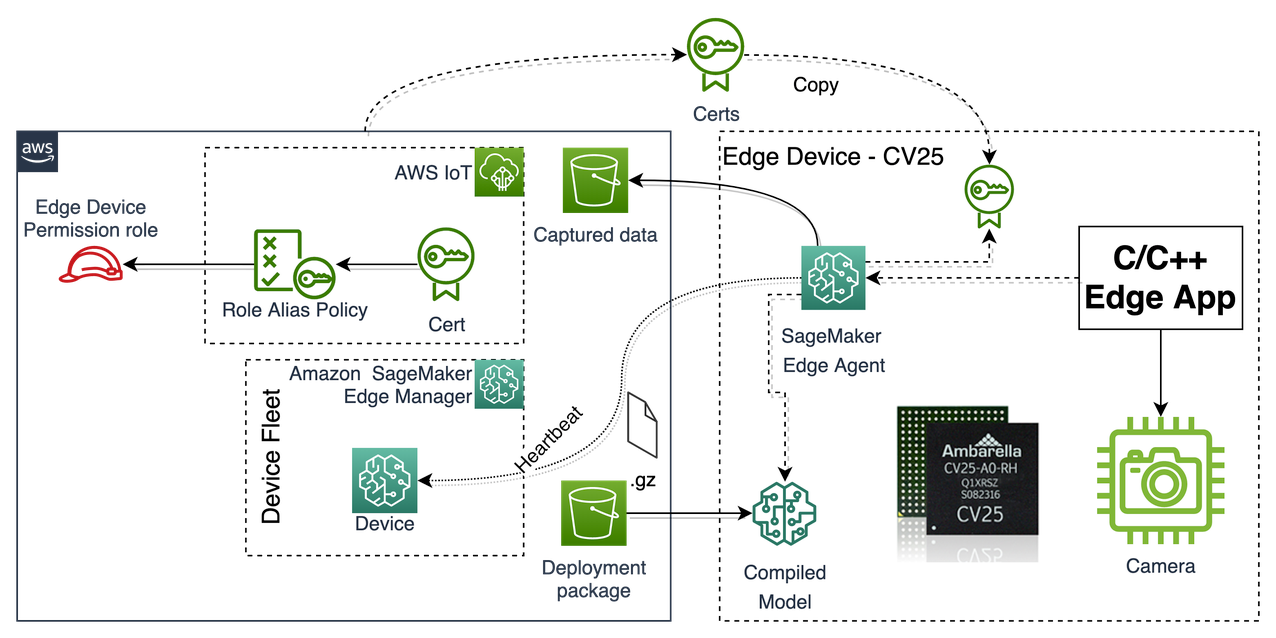
The solution workflow consists of the following steps:
- The developer builds, trains, validates, and creates the final model artefact that needs to be deployed to the dashcam.
- Invoke Neo to compile the trained model.
- The SageMaker Edge agent is installed and configured on the Edge device, in this case the dashcam.
- Create a deployment package with a signed model and the runtime used by the SageMaker Edge agent to load and invoke the optimized model.
- Deploy the package using the existing OTA deployment mechanism.
- The edge application interacts with the SageMaker Edge agent to do inference.
- The agent can be configured (if required) to send real-time sample input data from the application for model monitoring and refinement purposes.
Use case 3
Suppose your customer is developing an application that detects anomalies in the mechanisms of a wind turbine (like the gearbox, generator, or rotor). The goal is to minimize the damage on the equipment by running local protection procedures on the fly. These turbines are very expensive and located in places that aren’t easily accessible. Each turbine can be outfitted with an NVIDIA Jetson device to monitor sensor data from the turbine. We then need a solution to capture the data and use an ML algorithm to detect anomalies. We also need an OTA mechanism to keep the software and ML models on the device up to date.
AWS IoT Greengrass V2 along with Edge Manager fit well in this use case. AWS IoT Greengrass is an open-source IoT edge runtime and cloud service that helps you build, deploy, and manage IoT applications on your devices. You can use AWS IoT Greengrass to build edge applications using pre-built software modules, called components, that can connect your edge devices to AWS services or third-party services. This ability of AWS IoT Greengrass makes it easy to deploy assets to devices, including a SageMaker Edge agent. AWS IoT Greengrass is responsible for managing the application lifecycle, while Edge Manager decouples the ML model lifecycle. This gives you the flexibility to keep evolving the whole solution by deploying new versions of the edge application and ML models independently. The following diagram illustrates this architecture.
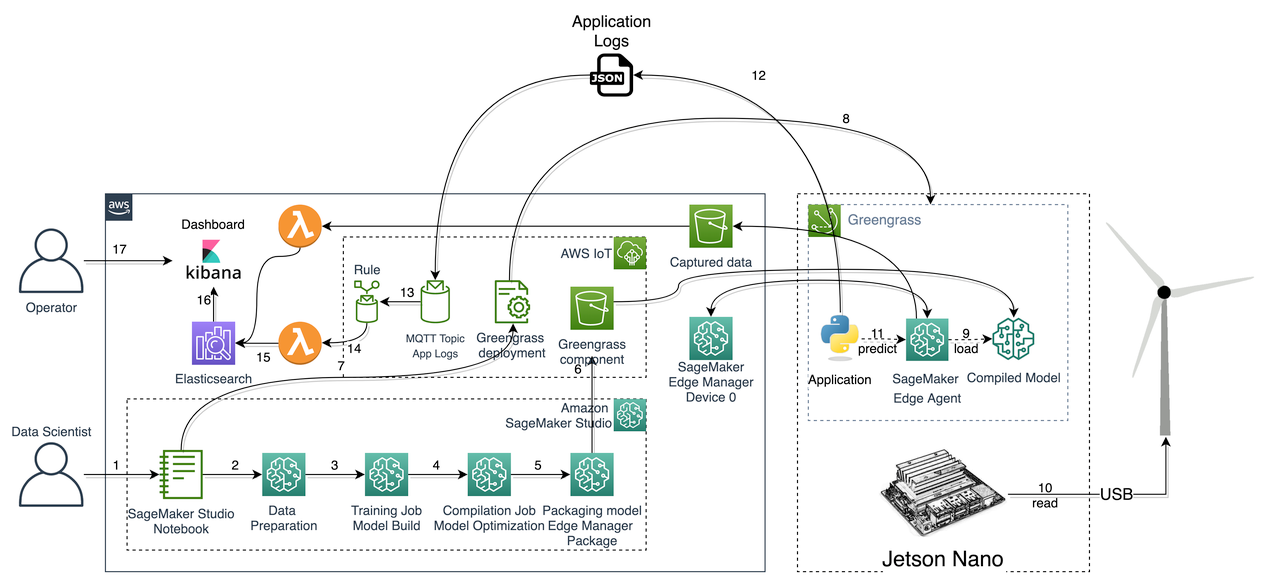
The solution consists of the following steps:
- The developer builds, trains, validates, and creates the final model artefact that needs to be deployed to the wind turbine.
- Invoke Neo to compile the trained model.
- Create a model component using Edge Manager with AWS IoT Greengrass V2 integration.
- Set up AWS IoT Greengrass V2.
- Create an inference component using AWS IoT Greengrass V2.
- The edge application interacts with the SageMaker Edge agent to do inference.
- The agent can be configured (if required) to send real-time sample input data from the application for model monitoring and refinement purposes.
Use case 4
For our final use case, let’s look at a vessel transporting containers, where each container has a couple of sensors and streams a signal to the compute and storage infrastructure deployed locally. The challenge is that we want to know the content of each container, and the condition of the goods based on temperature, humidity, and gases inside each container. We also want to track all the goods in each one of the containers. There is no internet connectivity throughout the voyage, and the voyage can take months. The ML models running on this infrastructure should preprocess the data and generate information to answer all our questions. The data generated needs to be stored locally for months. The edge application stores all the inferences in a local database and then synchronizes the results with the cloud when the vessel approaches the port.
AWS Snowcone and AWS Snowball from the AWS Snow Family could fit very well in this use case.
AWS Snowcone is a small, rugged, and secure edge computing and data migration device. Snowcone is designed to the OSHA standard for a one-person liftable device. Snowcone enables you to run edge workloads using Amazon Elastic Compute Cloud (Amazon EC2) computing, and local storage in harsh, disconnected field environments such as oil rigs, search and rescue vehicles, military sites, or factory floors, as well as remote offices, hospitals, and movie theaters.
Snowball adds more computing when compared to Snowcone and therefore may be a great fit for more demanding applications. The Compute Optimized feature provides an optional NVIDIA Tesla V100 GPU along with EC2 instances to accelerate an application’s performance in disconnected environments. With the GPU option, you can run applications such as advanced ML and full motion video analysis in environments with little or no connectivity.
On top of the EC2 instance, you have the freedom to build and deploy any type of edge solution. For instance: you can use Amazon ECS or other container manager to deploy the edge application, Edge Manager Agent and the ML model as individual containers. This architecture would be similar to Use Case 2 (except that it will work offline most of the time), with the addition of a container manager tool.
The following diagram illustrates this solution architecture.
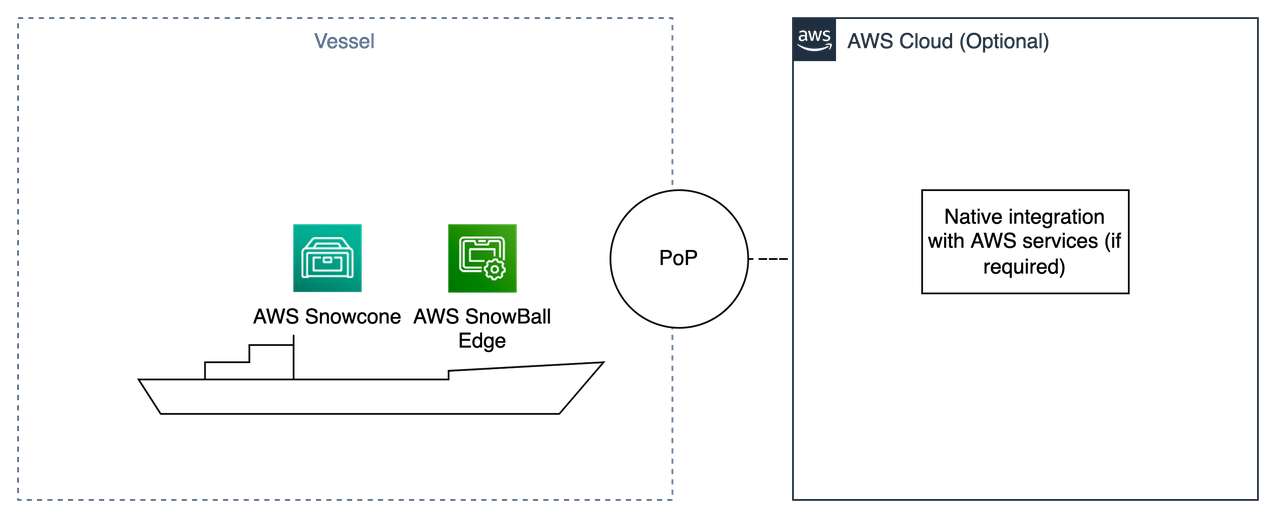
To implement this solution, simply order your Snow device from the AWS Management Console and launch your resources.
Conclusion
In this post, we discussed the different aspects of edge that you may choose to work with based on your use case. We also discussed some of the key concepts around ML@Edge and how decoupling the application lifecycle and the ML model lifecycle gives you the freedom to evolve them without any dependency on each other. We emphasized how choosing the right edge device for your workload and asking the right questions during the solution process can help you work backward and narrow down the right AWS services. We also presented different use cases along with reference architectures to inspire you to create your own solutions that will work for your workload.
About the Authors
 Dinesh Kumar Subramani is a Senior Solutions Architect with the UKIR SMB team, based in Edinburgh, Scotland. He specializes in artificial intelligence and machine learning. Dinesh enjoys working with customers across industries to help them solve their problems with AWS services. Outside of work, he loves spending time with his family, playing chess and enjoying music across genres.
Dinesh Kumar Subramani is a Senior Solutions Architect with the UKIR SMB team, based in Edinburgh, Scotland. He specializes in artificial intelligence and machine learning. Dinesh enjoys working with customers across industries to help them solve their problems with AWS services. Outside of work, he loves spending time with his family, playing chess and enjoying music across genres.
 Samir Araújo is an AI/ML Solutions Architect at AWS. He helps customers creating AI/ML solutions which solve their business challenges using AWS. He has been working on several AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. He likes playing with hardware and automation projects in his free time, and he has a particular interest for robotics.
Samir Araújo is an AI/ML Solutions Architect at AWS. He helps customers creating AI/ML solutions which solve their business challenges using AWS. He has been working on several AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. He likes playing with hardware and automation projects in his free time, and he has a particular interest for robotics.