Artificial Intelligence
How Marubeni is optimizing market decisions using AWS machine learning and analytics
This post is co-authored with Hernan Figueroa, Sr. Manager Data Science at Marubeni Power International.
Marubeni Power International Inc (MPII) owns and invests in power business platforms in the Americas. An important vertical for MPII is asset management for renewable energy and energy storage assets, which are critical to reduce the carbon intensity of our power infrastructure. Working with renewable power assets requires predictive and responsive digital solutions, because renewable energy generation and electricity market conditions are continuously changing. MPII is using a machine learning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability.
In this post, you will learn how Marubeni is optimizing market decisions by using the broad set of AWS analytics and ML services, to build a robust and cost-effective Power Bid Optimization solution.
Solution overview
Electricity markets enable trading power and energy to balance power supply and demand in the electric grid and to cover different electric grid reliability needs. Market participants, such as MPII asset operators, are constantly bidding power and energy quantities into these electricity markets to obtain profits from their power assets. A market participant can submit bids to different markets simultaneously to increase the profitability of an asset, but it needs to consider asset power limits and response speeds as well as other asset operational constraints and the interoperability of those markets.
MPII’s bid optimization engine solution uses ML models to generate optimal bids for participation in different markets. The most common bids are day-ahead energy bids, which should be submitted 1 day in advance of the actual trading day, and real-time energy bids, which should be submitted 75 minutes before the trading hour. The solution orchestrates the dynamic bidding and operation of a power asset and requires using optimization and predictive capabilities available in its ML models.
The Power Bid Optimization solution includes multiple components that play specific roles. Let’s walk through the components involved and their respective business function.
Data collection and ingestion
The data collection and ingestion layer connects to all upstream data sources and loads the data into the data lake. Electricity market bidding requires at least four types of input:
- Electricity demand forecasts
- Weather forecasts
- Market price history
- Power price forecasts
These data sources are accessed exclusively through APIs. Therefore, the ingestion components need to be able to manage authentication, data sourcing in pull mode, data preprocessing, and data storage. Because the data is being fetched hourly, a mechanism is also required to orchestrate and schedule ingestion jobs.
Data preparation
As with most ML use cases, data preparation plays a critical role. Data comes from disparate sources in a number of formats. Before it’s ready to be consumed for ML model training, it must go through some of the following steps:
- Consolidate hourly datasets based on time of arrival. A complete dataset must include all sources.
- Augment the quality of the data by using techniques such as standardization, normalization, or interpolation.
At the end of this process, the curated data is staged and made available for further consumption.
Model training and deployment
The next step consists of training and deploying a model capable of predicting optimal market bids for buying and selling energy. To minimize the risk of underperformance, Marubeni used the ensemble modeling technique. Ensemble modeling consists of combining multiple ML models to enhance prediction performance. Marubeni ensembles the outputs of external and internal prediction models with a weighted average to take advantage of the strength of all models. Marubeni’s internal models are based on Long Short-Term Memory (LSTM) architectures, which are well documented and easy to implement and customize in TensorFlow. Amazon SageMaker supports TensorFlow deployments and many other ML environments. The external model is proprietary, and its description cannot be included in this post.
In Marubeni’s use case, the bidding models perform numerical optimization to maximize the revenue using a modified version of the objective functions used in the publication Opportunities for Energy Storage in CAISO.
SageMaker enables Marubeni to run ML and numerical optimization algorithms in a single environment. This is critical, because during the internal model training, the output of the numerical optimization is used as part of the prediction loss function. For more information on how to address numerical optimization use cases, refer to Solving numerical optimization problems like scheduling, routing, and allocation with Amazon SageMaker Processing.
We then deploy those models through inference endpoints. As fresh data is ingested periodically, the models need to be retrained because they become stale over time. The architecture section later in this post provides more details on the models’ lifecycle.
Power bid data generation
On an hourly basis, the solution predicts the optimal quantities and prices at which power should be offered on the market—also called bids. Quantities are measured in MW and prices are measured in $/MW. Bids are generated for multiple combinations of predicted and perceived market conditions. The following table shows an example of the final bid curve output for operating hour 17 at an illustrative trading node near Marubeni’s Los Angeles office.
| Date | Hour | Market | Location | MW | Price |
| 11/7/2022 | 17 | RT Energy | LCIENEGA_6_N001 | 0 | $0 |
| 11/7/2022 | 17 | RT Energy | LCIENEGA_6_N001 | 1.65 | $80.79 |
| 11/7/2022 | 17 | RT Energy | LCIENEGA_6_N001 | 5.15 | $105.34 |
| 11/7/2022 | 17 | RT Energy | LCIENEGA_6_N001 | 8 | $230.15 |
This example represents our willingness to bid 1.65 MW of power if the power price is at least $80.79, 5.15 MW if the power price is at least $105.34, and 8 MW if the power price is at least $230.15.
Independent system operators (ISOs) oversee electricity markets in the US and are responsible for awarding and rejecting bids to maintain electric grid reliability in the most economical way. California Independent System Operator (CAISO) operates electricity markets in California and publishes market results every hour prior to the next bidding window. By cross-referencing current market conditions with their equivalent on the curve, analysts are able to infer optimal revenue. The Power Bid Optimization solution updates future bids using new incoming market information and new model predictive outputs
AWS architecture overview
The solution architecture illustrated in the following figure implements all the layers presented earlier. It uses the following AWS services as part of the solution:
- Amazon Simple Storage Service (Amazon S3) to store the following data:
- Pricing, weather, and load forecast data from various sources.
- Consolidated and augmented data ready to be used for model training.
- Output bid curves refreshed hourly.
- Amazon SageMaker to train, test, and deploy models to serve optimized bids through inference endpoints.
- AWS Step Functions to orchestrate both the data and ML pipelines. We use two state machines:
- One state machine to orchestrate data collection and ensure that all sources have been ingested.
- One state machine to orchestrate the ML pipeline as well as the optimized bidding generation workflow.
- AWS Lambda to implement ingestion, preprocessing, and postprocessing functionality:
- Three functions to ingest input data feeds, with one function per source.
- One function to consolidate and prepare the data for training.
- One function that generates the price forecast by calling the model’s endpoint deployed within SageMaker.
- Amazon Athena to provide developers and business analysts SQL access to the generated data for analysis and troubleshooting.
- Amazon EventBridge to trigger the data ingestion and ML pipeline on a schedule and in response to events.

In the following sections, we discuss the workflow in more detail.
Data collection and preparation
Every hour, the data preparation Step Functions state machine is invoked. It calls each of the data ingestion Lambda functions in parallel, and waits for all four to complete. The data collection functions call their respective source API and retrieve data for the past hour. Each function then stores the received data into their respective S3 bucket.
These functions share a common implementation baseline that provides building blocks for standard data manipulation such as normalization or indexation. To achieve this, we use Lambda layers and AWS Chalice, as described in Using AWS Lambda Layers with AWS Chalice. This ensures all developers are using the same base libraries to build new data preparation logics and speeds up implementation.
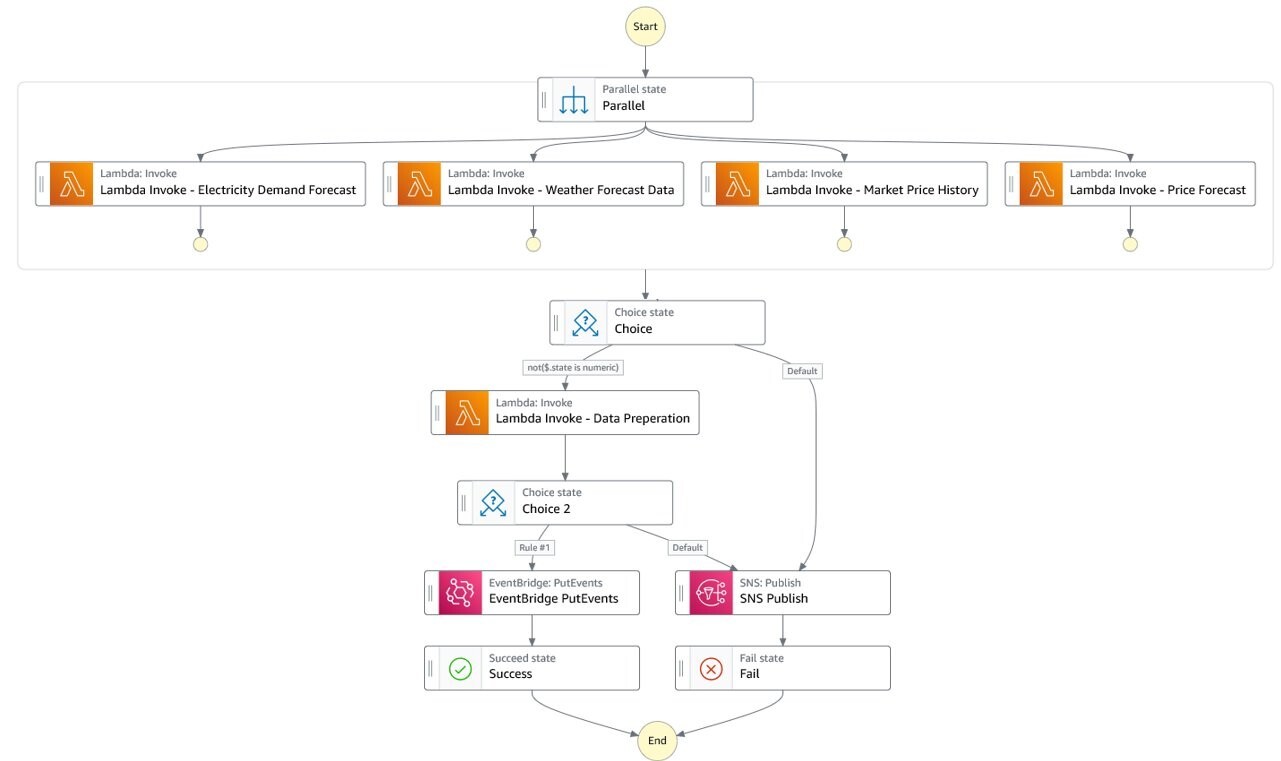
After all four sources have been ingested and stored, the state machine triggers the data preparation Lambda function. Power price, weather, and load forecast data is received in JSON and character delimited files. Each record part of each file carries a timestamp that is used to consolidate data feeds into one dataset covering a time frame of 1 hour.
This construct provides a fully event-driven workflow. Training data preparation is initiated as soon as all the expected data is ingested.
ML pipeline
After data preparation, the new datasets are stored into Amazon S3. An EventBridge rule triggers the ML pipeline through a Step Functions state machine. The state machine drives two processes:
- Check if the bid curve generation model is current
- Automatically trigger model retraining when performance degrades or models are older than a certain amount of days
If the age of the currently deployed model is older than the latest dataset by a certain threshold—say 7 days—the Step Functions state machine kicks off the SageMaker pipeline that trains, tests, and deploys a new inference endpoint. If the models are still up to date, the workflow skips the ML pipeline and moves on to the bid generation step. Regardless of the state of the model, a new bid curve is generated upon delivery of a new hourly dataset. The following diagram illustrates this workflow. By default, the StartPipelineExecution action is asynchronous. We can have the state machine wait for the end of the pipeline before invoking the bids generation step by using the ‘Wait-for callback‘ option.
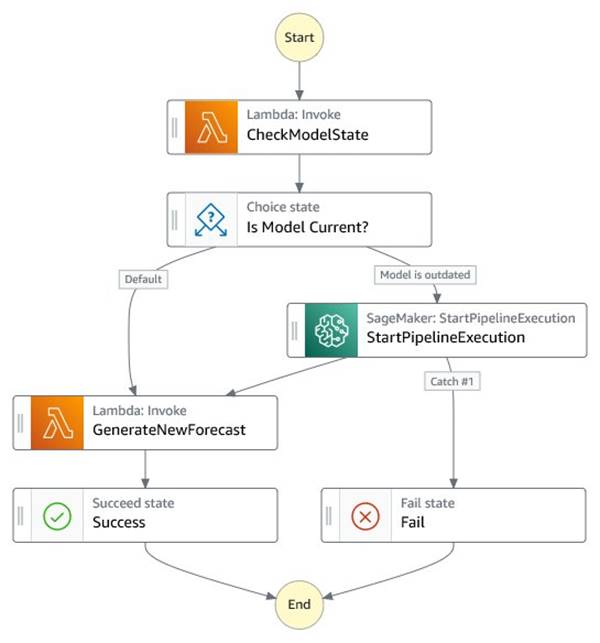

To reduce cost and time to market in building a pilot solution, Marubeni used Amazon SageMaker Serverless Inference. This ensures that the underlying infrastructure used for training and deployment incurs charges only when needed. This also makes the process of building the pipeline easier because developers no longer need to manage the infrastructure. This is a great option for workloads that have idle periods between traffic spurts. As the solution matures and transitions into production, Marubeni will review their design and adopt a configuration more suited for predictable and steady usage.
Bids generation and data querying
The bids generation Lambda function periodically invokes the inference endpoint to generate hourly predictions and stores the output into Amazon S3.
Developers and business analysts can then explore the data using Athena and Microsoft Power BI for visualization. The data can also be made available via API to downstream business applications. In the pilot phase, operators visually consult the bid curve to support their power transaction activities on markets. However, Marubeni is considering automating this process in the future, and this solution provides the necessary foundations to do so.
Conclusion
This solution enabled Marubeni to fully automate their data processing and ingestion pipelines as well as reduce their predictive and optimization models’ deployment time from hours to minutes. Bid curves are now automatically generated and kept up to date as market conditions change. They also realized an 80% cost reduction when switching from a provisioned inference endpoint to a serverless endpoint.
MPII’s forecasting solution is one of the recent digital transformation initiatives Marubeni Corporation is launching in the power sector. MPII plans to build additional digital solutions to support new power business platforms. MPII can rely on AWS services to support their digital transformation strategy across many use cases.
“We can focus on managing the value chain for new business platforms, knowing that AWS is managing the underlying digital infrastructure of our solutions.”
– Hernan Figueroa, Sr. Manager Data Science at Marubeni Power International.
For more information on how AWS is helping energy organizations in their digital transformation and sustainability initiatives, refer to AWS Energy.
![]() Marubeni Power International is a subsidiary of Marubeni Corporation. Marubeni Corporation is a major Japanese trading and investment business conglomerate. Marubeni Power International mission is to develop new business platforms, assess new energy trends and technologies and manage Marubeni’s power portfolio in the Americas. If you would like to know more about Marubeni Power, check out https://www.marubeni-power.com/.
Marubeni Power International is a subsidiary of Marubeni Corporation. Marubeni Corporation is a major Japanese trading and investment business conglomerate. Marubeni Power International mission is to develop new business platforms, assess new energy trends and technologies and manage Marubeni’s power portfolio in the Americas. If you would like to know more about Marubeni Power, check out https://www.marubeni-power.com/.
About the Authors
 Hernan Figueroa leads the digital transformation initiatives at Marubeni Power International. His team applies data science and digital technologies to support Marubeni Power growth strategies. Before joining Marubeni, Hernan was a Data Scientist at Columbia University. He holds a Ph.D. in Electrical Engineering and a B.S. in Computer Engineering.
Hernan Figueroa leads the digital transformation initiatives at Marubeni Power International. His team applies data science and digital technologies to support Marubeni Power growth strategies. Before joining Marubeni, Hernan was a Data Scientist at Columbia University. He holds a Ph.D. in Electrical Engineering and a B.S. in Computer Engineering.
 Lino Brescia is a Principal Account Executive based in NYC. He has over 25 years of technology experience and has joined AWS in 2018. He manages global enterprise customers as they transform their business with AWS cloud services and perform large-scale migrations.
Lino Brescia is a Principal Account Executive based in NYC. He has over 25 years of technology experience and has joined AWS in 2018. He manages global enterprise customers as they transform their business with AWS cloud services and perform large-scale migrations.
 Narcisse Zekpa is a Sr. Solutions Architect based in Boston. He helps customers in the Northeast U.S. accelerate their business transformation through innovative, and scalable solutions, on the AWS Cloud. When Narcisse is not building, he enjoys spending time with his family, traveling, cooking, playing basketball, and running.
Narcisse Zekpa is a Sr. Solutions Architect based in Boston. He helps customers in the Northeast U.S. accelerate their business transformation through innovative, and scalable solutions, on the AWS Cloud. When Narcisse is not building, he enjoys spending time with his family, traveling, cooking, playing basketball, and running.
 Pedram Jahangiri is an Enterprise Solution Architect with AWS, with a PhD in Electrical Engineering. He has 10+ years experience in the energy and IT industry. Pedram has many years of hands-on experience in all aspects of Advanced Analytics for building quantitative and large-scale solutions for enterprises by leveraging cloud technologies.
Pedram Jahangiri is an Enterprise Solution Architect with AWS, with a PhD in Electrical Engineering. He has 10+ years experience in the energy and IT industry. Pedram has many years of hands-on experience in all aspects of Advanced Analytics for building quantitative and large-scale solutions for enterprises by leveraging cloud technologies.
 Sarah Childers is an Account Manager based in Washington DC. She is a former science educator turned cloud enthusiast focused on supporting customers through their cloud journey. Sarah enjoys working alongside a motivated team that encourages diversified ideas to best equip customers with the most innovative and comprehensive solutions.
Sarah Childers is an Account Manager based in Washington DC. She is a former science educator turned cloud enthusiast focused on supporting customers through their cloud journey. Sarah enjoys working alongside a motivated team that encourages diversified ideas to best equip customers with the most innovative and comprehensive solutions.