AWS for M&E Blog
Video summarization with AWS artificial intelligence (AI) and machine learning (ML) services
Publishers and broadcasters recognize that short video clips are effective in gaining attention from younger viewers, many of whom are enthusiasts of short form content on platforms like TikTok. If companies in traditional M&E industries can efficiently generate short video clips from original content and distribute them across various social media platforms such as Facebook, Instagram, Snap, and TikTok, they have the potential to attract broader audiences to their services.
Generating video summaries is a manual and time-consuming process due to challenges like understanding complex content, maintaining coherence, diverse video types, and lack of scalability when dealing with a large volume of videos. Introducing automation through the use of artificial intelligence (AI) and machine learning (ML) can make this process more viable and scalable with automatic content analysis, real-time processing, contextual adaptation, customization, and continuous AI/ML system improvement. The resulting business impact might involve enhanced efficiencies in the content production supply chain, in addition to the ability to engage larger audiences, ultimately leading to increased revenues.
In this blog post, we demonstrate how to build an end-to-end workload to solve this business problem, allowing users to upload, process, and summarize videos into short form with voice narration by leveraging AWS AI/ML services Amazon Transcribe, Amazon SageMaker Jumpstart, and Amazon Polly.
Amazon Transcribe is a fully managed ML service that automatically converts speech from video into text and subtitles. Amazon Transcribe also supports custom models that understand your domain-specific vocabulary.
Amazon SageMaker JumpStart is a one-click ML hub providing foundation models, built-in algorithms, and prebuilt ML solutions from publicly available sources like Hugging Face, AI21, and Stability AI, for a wide range of problem types such as text summarization. These models have been packaged to be securely and easily deployable via SageMaker APIs.
Amazon Polly is a service that uses deep learning technologies to convert text into lifelike speech, which we will use to create narration audio for summarized videos in our solution.
Solution overview
The end-to-end solution for video summarization workload consists of five main components: 1) user experience, 2) request management, 3) AWS Step Functions workflow orchestration with AWS AI/ML services, 4) media and metadata storage, 5) event-driven services and monitoring.
The following diagram illustrates the pipeline of the video summarization workload.
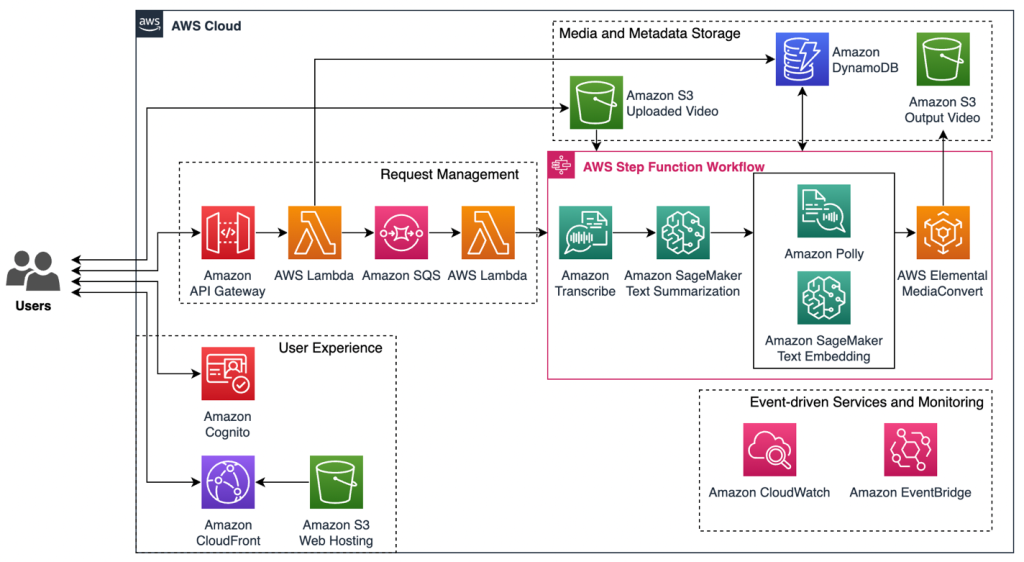
User experience: The architecture contains a simple static web application hosted in Amazon Simple Storage Service (Amazon S3). To serve the static website hosted on Amazon S3, we deploy an Amazon CloudFront distribution and use origin access control (OAC) to restrict access to the S3 origin. With Amazon Cognito, we are able to protect the web application from unauthenticated users.
Request management: We use Amazon API Gateway as the entry point for all real-time communication between the front-end and the back-end of the video summarization workload where requests to create, read, update, delete (CRUD), or run workflows begin. The API requests invoke AWS Lambda function that puts video summarization tasks into Amazon Simple Queue Service (Amazon SQS) queue to support workload reliability and scale before sending the pre-processed requests to AWS Step Functions.
AWS Step Functions workflow orchestration with AWS AI/ML services: The process to achieve a summarized video starts with using Amazon Transcribe for automatic speech recognition and converting the speech of the video into text with associated metadata information such as timestamps in the output subtitle file. We then leverage an Amazon SageMaker JumpStart pre-trained foundation model to summarize the text that retains the story (plot) of original video but in shorter form. Subsequently, we use a text embedding model deployed in SageMaker JumpStart to automatically pair each sentence in the summarized content with its corresponding sentences in the original subtitle file. This process enables us to precisely select the most relevant video segments and determine their timestamps. We use Amazon Polly to create voice narration and AWS Elemental MediaConvert for final video output.
Media and metadata storage: The solution stores uploaded videos and output video in Amazon S3, which offers durable, highly available and scalable data storage at low cost. All the media, profiling and task metadata are stored in Amazon DynamoDB NoSQL database service that, for example, allows users to keep track of the tasks’ status and other relevant information.
Event-driven services and monitoring: We leverage Amazon CloudWatch and Amazon EventBridge to monitor in real-time every component and make responsive actions during the Step Functions workflow.
Walkthrough
In this blog post, we focus on the Step Functions workflow using AWS AI/ML services in order to generate the summarized content and select the most relevant video frame sequence.
Starting with Amazon Transcribe StartTranscriptionJob API, we simply transcribes the original video stored in Amazon S3 into text. With additional Request Parameters from the API, we are able to get both the full text and other metadata in JSON and SRT (subtitle) file formats.
The following is an example of our workload’s Amazon Transcribe output in JSON format:
The following is another example of Amazon Transcribe output in SRT (subtitle) format:
In the next step of the workflow, we deploy a pre-trained Large Language Model (LLM) in Amazon SageMaker JumpStart. Large language models (LLMs) are neural network-based language models with hundreds of millions to over a trillion parameters. Their generative capabilities make them popular for tasks such as text generation, summarization, translation, sentiment analysis, conversational chatbot and more. In this workload, we choose the pre-trained and fine-tuned Llama 2 generative model to summarize the original text. You can use other LLMs for text summarization such as Hugging Face DistilBART-CNN-12-6, Hugging Face BART Large CNN, and many more and which can be easily deployed in Amazon SageMaker JumpStart in one click.
As shown in the following Python code, after deploying Llama 2 in Amazon SageMaker, we can easily call InvokeEndpoint API to get inferences from the Llama 2 model hosted at the SageMaker endpoint.
You can invoke the endpoint with different parameters defined in the payload to impact the text summarization. Two important parameters are top_p and temperature. While top_p is used to control the range of tokens considered by the model based on their cumulative probability, temperature controls the level of randomness in the output. Although there isn’t a one-size-fits-all combination of top_p and temperature for all use cases, in the previous example, we demonstrate sample values with high top_p and low temperature that leads to summaries focused on key information and avoid deviating from the original text but still introduce some creative variations to keep the output interesting.
The next step starts with Amazon Polly to generate speech from summarized text. The output of the Polly task is both MP3 files and documents marked up with Speech Synthesis Markup Language (SSML). Within this SSML file, essential metadata is encapsulated, describing the duration of individual sentences vocalized by a specific Polly voice. With this audio duration information, we will be able to define the length of the video segments; in this case, a direct 1:1 correspondence is employed.
In the final step of the Step Functions workflow, we need to select the most relevant video frame sequence to match with every sentence in the summarized content. Thus, we use text embedding to perform the sentence similarity task, which determines how similar two texts are. Sentence similarity models transform input texts into vectors (embeddings) that capture semantic information and calculate the proximity or similarity between them.
With Amazon SageMaker, you are able to use either built-in text embedding algorithms such as BlazingText or use transformer-based model from open sources such as Hugging Face all-MiniLM-L6-v2, which takes a text string as input and produces an embedding vector with 384 dimensions. In this workload, we deploy a pretrained all-MiniLM-L6-v2 model in Amazon SageMaker.
The following code gives an example of how text embedding using Amazon SageMaker endpoint works:
will return the similarity_matrix matrix as follow:
We use Cosine similarity to measure similarities between two vectors. For example, you can interpret the prior result as: the first row of the matrix corresponds to the first sentence in the summarized content and all the columns show its similarity scores to the sentences in the original text. Similarity values typically range between -1 and 1, where 1 indicates that the vectors are identical or very similar; 0 indicates that the vectors are orthogonal (not correlated) and have no similarity; -1 indicates that the vectors are diametrically opposed or very dissimilar.
From the similarity matrix, we identify the top-k highest similarity scores for each sentence in the summarized content, thereby aligning them with the most similar sentences in the original text. Each sentence in the original text also has its corresponding timestamp (i.e. startTime, endTime) stored in the original SRT subtitle file. In the next step, we use the timestamps to guide the process of segmenting the original video into clips. By incorporating both the duration of Polly audio for each summarized sentence and the timestamps from the original subtitle file, we can then select the timestamp sequence for the most relevant frames corresponding to each summarized sentence. The length of each selected video segment for a summarized sentence will be aligned with the length of its narration audio. An example of the timestamp output is:
We then use the sequence of the timestamps as parameters to create AWS Elemental MediaConvert assembly workflows to performs basic input clipping. By combining it with the MP3 audio from Amazon Polly and along with the possibility of incorporating background music of your preference, you can ultimately achieve the final video summarization output.
The following image illustrates the user interface of the video summarization web application which is simple and easy to use. The front-end is built on Cloudscape, an open source design system for the cloud.

Conclusion
In this blog post, we demonstrated an AI-generated video summarization workload for media supply chain that allows users to ingest, process, and summarize videos into shorter clips with voice narration. The blog describes how to build an end-to-end solution, from the front-end where users need to login with Amazon Cognito user pools, to the AWS Step Functions logic in the backend using different AWS AI/ML services and finally uses AWS Elemental MediaConvert to produce summarized video output. The video summarization workload addresses scenarios involving videos with audio speech. It’s important to note that the scope of this blog post does not extend to situations where videos lack audio speech or dialogue content.
The solution uses Amazon S3, Amazon CloudFront, Amazon API Gateway, AWS Lambda, Amazon Cognito, AWS Step Functions and AWS AI/ML services such as Amazon Transcribe, Amazon SageMaker, Amazon Polly, etc.
For more information about any AWS services, please refer to this link to learn more.