AWS Partner Network (APN) Blog
Implementing Data Mesh Using LTI’s Canvas Scarlet Framework on AWS
By Rajan Seshadri, LTI AWS Architect – LTI COE (DATA)
By Shivaji Murkute, LTI AWS Architect – LTI COE (DATA)
By Francois van Rensburg, Sr. Partner Management Solutions Architect – AWS
 |
| LTI |
 |
As data grows at an exponential rate both in volume and velocity, it becomes important for organizations to carve out a strategy to store data in appropriate locations with the correct safeguards to address data access and privacy concerns.
The successful use of data to derive business insights is also key, as more organizations are becoming data driven for their corporate-level decision making. Organizations do acknowledge this and are using data where possible, but it’s becoming difficult to cope with the volume of data growth thanks to the magnitude of data sources, including sensor data and modern applications, to name a few.
A paradigm shift in the way organizations leverage their IT sources is necessary. An agile way to be adaptable to market needs and create new services with a startup mindset is to build data as a product using a bill of materials. This can be assembled from many individual data components, sourced both locally and externally, and converted to a value-added finished product.
In this post, we cover how organizations can transform their data landscape into a more controlled, flexible, and secure landscape using LTI’s Canvas Scarlet Data Mesh framework built on Amazon Web Services (AWS) to meet the data challenges an organization faces today.
Larsen and Toubro Infotech (LTI) is an AWS Premier Tier Services Partner and global technology consulting and digital solutions company, helping customers accelerate their digital transformation journeys. LTI’s unique heritage gives it real-world expertise to solve the most complex challenges of enterprises across all industries.
What is a Data Mesh?
A data mesh follows a distributed architecture. It’s a universal, domain-agnostic, and automated approach to data standardization, with independent lifecycle, built and deployed by independent teams.

Figure 1 – Principles of Data Mesh.
Data mesh is composed of three separate components: data sources, data infrastructure, and domain-oriented data pipelines managed by functional owners. Underlying the data mesh architecture is a layer of universal interoperability, reflecting domain-agnostic standards, as well as observability and governance.

Figure 2 – Components of Data Mesh.
Outcomes of Data Mesh
The answer to many issues and roadblocks in the traditional organizational setup and the monolithic architectures is addressed by a data mesh that focuses on building modern distributed architecture at scale.
The ability to decentralize data storage using logical borders based on the business domains has unlocked the potential to add more variety and operate at scale.
With the data team and operations team working on their areas of development, the collaboration of the data and business operations happening at the data storage level, combined with the application of the reusable design at the storage level, enables the power of data to be unlocked for a variety of domains.
When the data scope and purpose are well defined, catalogued for discovery, orchestrated through web services/APIs, access-controlled using identity management systems, and user access logged, it paves the way for modern architecture designed for scalability, flexibility, and organizational governance.
Important Considerations in Data Mesh Design
- Organization is divided into many lines of business (LOBs) and sub-LOBs. Data is scattered in many silos. Visibility is needed at an enterprise level on the various data stores.
- Data should be democratized within the organization.
- Decentralized model for domain ownership and responsibility for making changes to the domain based on business needs.
- Physical infrastructure and data domains are separated. Value additions to the data are defined by each domain owner.
- Centralized data governance in place for deciding who can access what data.
- Data privacy concerns to be addressed so only consented data and desensitized data is made available for public viewing.
LTI’s Canvas Scarlet for Data Mesh
Implementing a data mesh is a big step forward and requires a thorough analysis of the organizations’ current landscape of technology, ownership of the various applications, as well as the business functions the various sections of the IT services and organization’s vision to adopt a data-driven approach to its long term and short-term decisions.
LTI’s Canvas Scarlet Data Mesh is a framework that follows a structured way to assess the current state of the enterprise IT, garner the vision of the organization, identify gaps, and lay out a blueprint for a data domain-oriented decentralized organization consisting of many data domains with each assigned ownership.
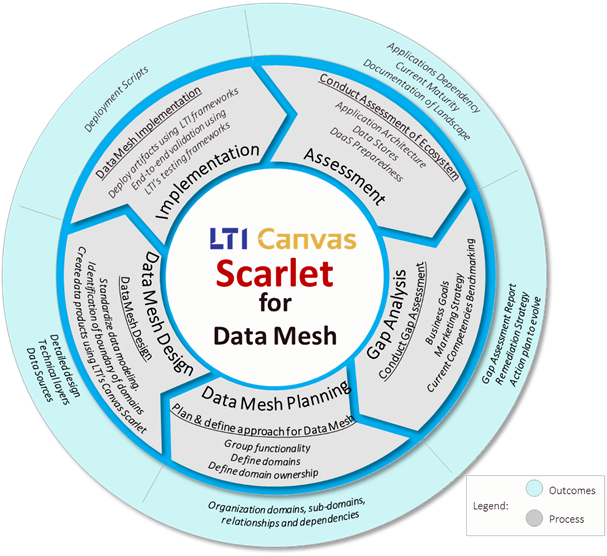
Figure 3 – LTI Canvas Scarlet Framework.
Outcomes of the Data Mesh Architectural Pattern
A successful data mesh architecture can be defined by four key components:
- Data domain: Enables users to create many data domains with ownerships to domain owners who decide the extract, transform, loads (ETLs) and data products from the foundational data.
- Central data catalog: A central repository of data products which potential customers can search, discover, view sample data, and subscribe.
- Data as a product: Orchestrate the value added data products through the central data catalog.
- Data governance: A maker-checker process to govern who can access what data products. Following are the important roles and their corresponding responsibilities:
- Domain administrator: Overall owner of the entire solution; grants access to users and defines their role within data mesh.
- Domain owner: Defines the source data from many data repositories; creates ETLs, and their refresh frequency, and the data products.
- Data governance team: Configurable set of users assigned this “data governance” role will be notified to approve or reject the subscription requests by consumers to data products. Approved requests and user ID will be stored in a data table that will be looked up during API request processing.
- Data user: Corporate user with a role of “data user” is authorized to view the central data catalog.
Process Flow
As a prerequisite, all organization data is made available using physical data store. LTI’s Canvas Scarlet Data Mesh solution is deployed as a Docker-based web application.
- Domain administrator creates data-domains and assigns the responsibility of maintenance to a domain owner.
- Domain owner identifies data tables from various data stores both in AWS and on premises based on the relevance to their domain. Selected tables’ metadata is stored in AWS Glue Data Catalog. This process defines logical mapping between data stores and their corresponding data domains. No physical data movement takes place.
- Domain owner defines materialized views and tables along with refresh rates. The outputs are stored in Amazon Simple Storage Service (Amazon S3) or Amazon Redshift. In addition, the domain owner defines ETLs using a graphical user interface (UI) featuring a toolset with drag-and-drop for various individual processes such as data pull from data stores, cleansing, transformation, and processing before storing the resultant set into S3 or Redshift. The output created is also cataloged and made available to the respective domain owners.
- The data elements in the catalog will be categorized into basic foundational elements, value-added elements, and ETL-created aggregated data elements.
- Data owners can choose from a combination of the above data elements to define data products by assembling them into various forms as value-added data products. Post-definition, data products will be made available in a global data catalog that can be searched by authorized corporate users.
- The output of the search will contain metadata and a sample of the data product.
- Users interested in the data products raise a request for accessing them with one request per product. This request will go through a data governance process. Post-approval, API access will be permitted, and an email notification will be sent to the user who raised the request.
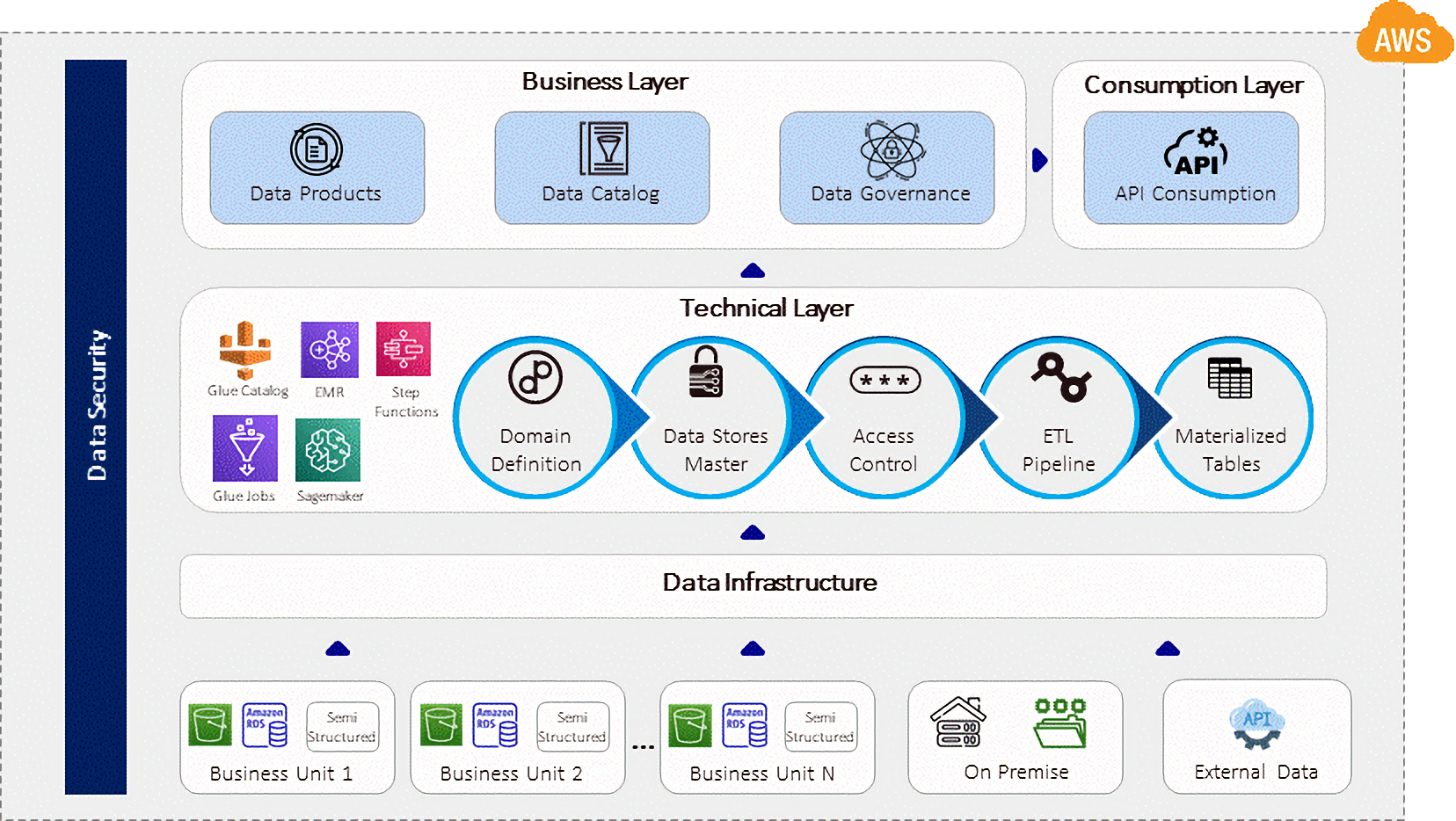
Figure 4 – Logical diagram of data mesh implementation.
Solution Artifacts
The foundational building block of a data mesh is a domain which creates value-added products and is a producer. A domain can depend not only on the foundational data stores of applications for creating ETLs and data products, but also on other domains sourced both internally within the organization and externally for data products that can be used for building better value-added data products.
A centralized data catalog can provide authorized users with the ability to search data products using keywords and request for subscription. A data governance team can validate the request and grant access permissions. The usage in terms of number of hits by API aggregated at the data domain level can be reported for statistical reasons.
In this solution architecture of LTI Canvas Scarlet, there is a physical separation of a domain and its associated data products and the underlying data stores from which the low-level data is sourced. Only the metadata and location of its data source are mapped to the domain. The underlying data from various sources is pulled during the ETL processing, and the output is stored in a location accessible to the domain.
A UI part of the solution enables domain owners to define the data stores and its respective coordinates along with the value-added components.
The definitions of the domain and its attributes are stored in Amazon DynamoDB. The data stores and its corresponding metadata are stored in an AWS Glue Data Catalog, and the mappings to the domain are stored in a data model based out of DynamoDB.
The aggregated data, ETL outputs, and data products are stored in data marts which are either hosted on Amazon S3 or Redshift data stores. The ETL features definition of the workflow that involves various operations such as pulling data from raw stores, defining data cleansing, data aggregations, and transformations before writing the output into the target data stores that is ready for consumption or used for further value additions.
The ETL workflow can be created using a GUI tool that is part of the LTI Canvas Scarlet Data Mesh solution. The ETL will be scheduled using Amazon EventBridge and executed using the Glue-based Python Spark program.
The data product defined is stored in a DynamoDB and served using Amazon API Gateway. Access permissions to the data products is stored in DynamoDB and looked up as part of request processing.
Implementation
Installing Canvas Scarlet Data Mesh can be done in two steps:
- Run an AWS CloudFormation template to create the necessary AWS services.
- Docker image that can be deployed and run on Amazon Elastic Container Service (Amazon ECS).
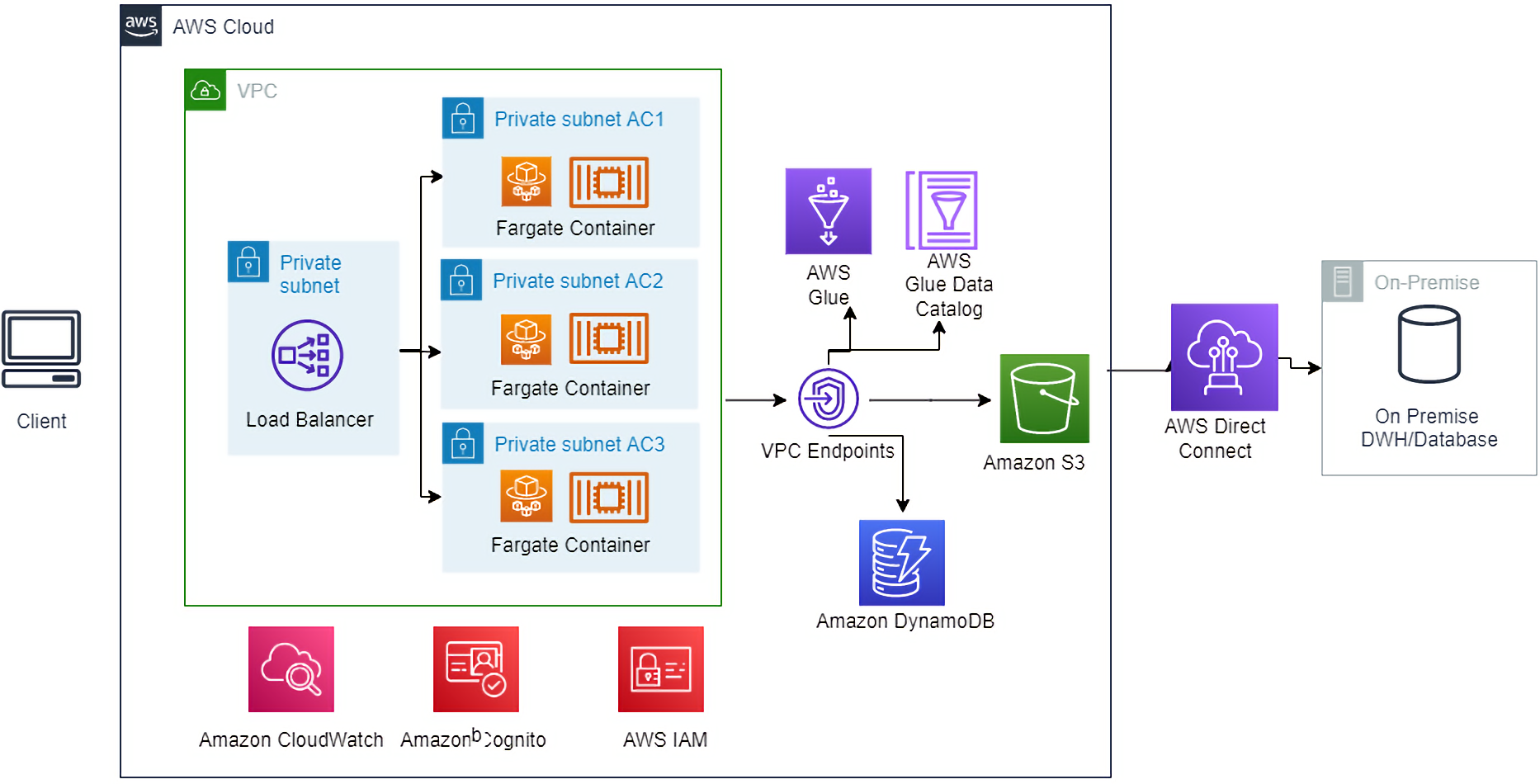
Figure 5 – Physical architecture diagram.
Highlights of the Architecture
The functionalities of LTI’s Canvas Scarlet Data Mesh solution are bundled into a web-based application and Dockerized for deployment.
The physical architecture consists of an AWS Fargate container deployment; deployed across three AWS Availability Zones (AZs) in a private subnet running the container images. A load balancer fronts the Fargate deployment and distributes the incoming HTTPS requests to the web application running in Fargate.
Requests are authenticated using an identity provider (IdP) that supports SAML 2.0 or OAUTH2 protocol. Access to the various functions is based on user roles returned by the IdP.
The solution is integrated with AWS services such as AWS Glue Data Catalog, Amazon S3, AWS Glue DataBrew, Amazon EventBridge, and AWS Key Management Service (AWS KMS). Data processing is carried out using AWS Glue DataBrew triggered by EventBridge.
All metadata of tables and its corresponding data stores are stored in Glue Catalog. Data-as-a-product definition is used to refresh the final products stored in S3 data stores, so it’s ready to serve HTTPS requests. In addition, AWS Lake Formation integration is done for the data stores to leverage data security, audit, data sharing, and provide cross account access within the organization.
All data stores are secured using KMS and AWS Identity and Access Management (IAM) policies. Access to the data-as-a-product APIs is governed based on the data governance outcomes that decide who can access what.
Either AWS Site-to-Site VPN or AWS Direct Connect connectivity between the Amazon Virtual Private Cloud (VPC) and the on-premises network housing the databases enables data-domain to access physical data stores on premises and pull data on demand, perform ETLs, and store value added data in a data mart.
Conclusion
In this post, we explained the importance of organizing data sources into many domains, each managed by an owner who is accountable for creating and maintaining value added data products based on market and business needs.
As it’s important to maintain data privacy, we also saw how data security is built into the LTI’s Canvas Scarlet Data Mesh solution using AWS Lake Formation and a data governance process. LTI’s solution is flexible and can accommodate changes to the domain while keeping an audit of changes by domain.
The overall process of data processing uses AWS serverless compute, open-source tools, and flexible storage of Amazon S3 to scale organization needs while optimizing costs.
Data-as-a-service is gaining momentum in the market and organizations that are quick to adopt will be able to monetize their cache of data through secure APIs and create a self-driving IT data business model.
.

.
LTI – AWS Partner Spotlight
LTI is an AWS Premier Tier Services Partner that helps more than 400 clients succeed in a converging world as a global technology consulting and digital solutions company.
Contact LTI | Partner Overview
*Already worked with LTI? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.