AWS Big Data Blog
Category: AWS Step Functions

Simplify your ETL and ML pipelines using the Amazon Athena UNLOAD feature
Many organizations prefer SQL for data preparation because they already have developers for extract, transform, and load (ETL) jobs and analysts preparing data for machine learning (ML) who understand and write SQL queries. Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using […]

How the Georgia Data Analytics Center built a cloud analytics solution from scratch with the AWS Data Lab
This is a guest post by Kanti Chalasani, Division Director at Georgia Data Analytics Center (GDAC). GDAC is housed within the Georgia Office of Planning and Budget to facilitate governed data sharing between various state agencies and departments. The Office of Planning and Budget (OPB) established the Georgia Data Analytics Center (GDAC) with the intent […]

ETL orchestration using the Amazon Redshift Data API and AWS Step Functions with AWS SDK integration
Extract, transform, and load (ETL) serverless orchestration architecture applications are becoming popular with many customers. These applications offers greater extensibility and simplicity, making it easier to maintain and simplify ETL pipelines. A primary benefit of this architecture is that we simplify an existing ETL pipeline with AWS Step Functions and directly call the Amazon Redshift […]

Doing more with less: Moving from transactional to stateful batch processing
Amazon processes hundreds of millions of financial transactions each day, including accounts receivable, accounts payable, royalties, amortizations, and remittances, from over a hundred different business entities. All of this data is sent to the eCommerce Financial Integration (eCFI) systems, where they are recorded in the subledger. Ensuring complete financial reconciliation at this scale is critical […]
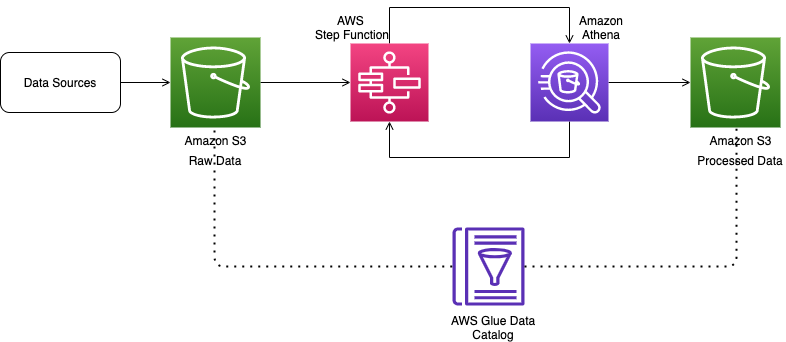
Build and orchestrate ETL pipelines using Amazon Athena and AWS Step Functions
Extract, transform, and load (ETL) is the process of reading source data, applying transformation rules to this data, and loading it into the target structures. ETL is performed for various reasons. Sometimes ETL helps align source data to target data structures, whereas other times ETL is done to derive business value by cleansing, standardizing, combining, […]

Prepare, transform, and orchestrate your data using AWS Glue DataBrew, AWS Glue ETL, and AWS Step Functions
Data volumes in organizations are increasing at an unprecedented rate, exploding from terabytes to petabytes and in some cases exabytes. As data volume increases, it attracts more and more users and applications to use the data in many different ways—sometime referred to as data gravity. As data gravity increases, we need to find tools and […]

Centralize feature engineering with AWS Step Functions and AWS Glue DataBrew
One of the key phases of a machine learning (ML) workflow is data preprocessing, which involves cleaning, exploring, and transforming the data. AWS Glue DataBrew, announced in AWS re:Invent 2020, is a visual data preparation tool that enables you to develop common data preparation steps without having to write any code or installation. In this […]

Orchestrate an Amazon EMR on Amazon EKS Spark job with AWS Step Functions
At re:Invent 2020, we announced the general availability of Amazon EMR on Amazon EKS, a new deployment option for Amazon EMR that allows you to automate the provisioning and management of open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). With Amazon EMR on EKS, you can now run Spark applications alongside other […]

Building complex workflows with Amazon MWAA, AWS Step Functions, AWS Glue, and Amazon EMR
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a fully managed service that makes it easy to run open-source versions of Apache Airflow on AWS and build workflows to run your extract, transform, and load (ETL) jobs and data pipelines. You can use AWS Step Functions as a serverless function orchestrator to build scalable […]
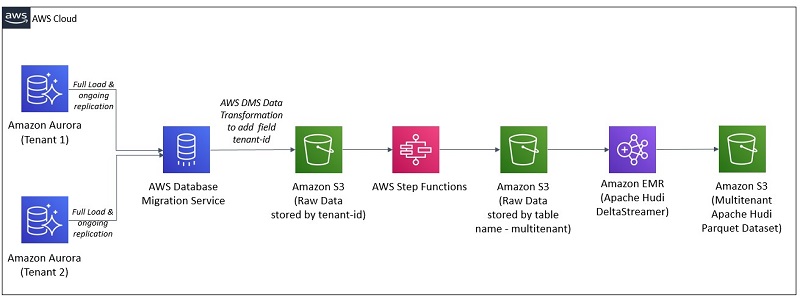
Multi-tenant processing pipelines with AWS DMS, AWS Step Functions, and Apache Hudi on Amazon EMR
Large enterprises often provide software offerings to multiple customers by providing each customer a dedicated and isolated environment (a software offering composed of multiple single-tenant environments). Because the data is in various independent systems, large enterprises are looking for ways to simplify data processing pipelines. To address this, you can create data lakes to bring […]