AWS Big Data Blog
Tag: Healthcare
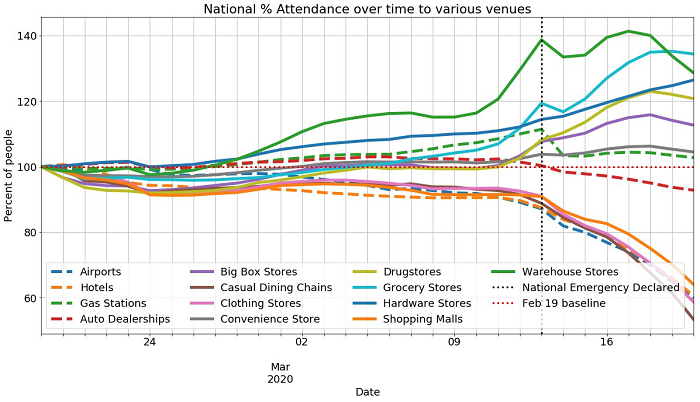
Exploring the public AWS COVID-19 data lake
This post walks you through accessing the AWS COVID-19 data lake through the AWS Glue Data Catalog via Amazon SageMaker or Jupyter and using the open-source AWS Data Wrangler library. AWS Data Wrangler is an open-source Python package that extends the power of Pandas library to AWS and connects DataFrames and AWS data-related services (such as Amazon Redshift, Amazon S3, AWS Glue, Amazon Athena, and Amazon EMR). For more information about what you can build by using this data lake, see the associated public Jupyter notebook on GitHub.

A public data lake for analysis of COVID-19 data
April 2024: This post was reviewed for accuracy. As the COVID-19 pandemic continues to threaten and take lives around the world, we must work together across organizations and scientific disciplines to fight this disease. Innumerable healthcare workers, medical researchers, scientists, and public health officials are already on the front lines caring for patients, searching for […]
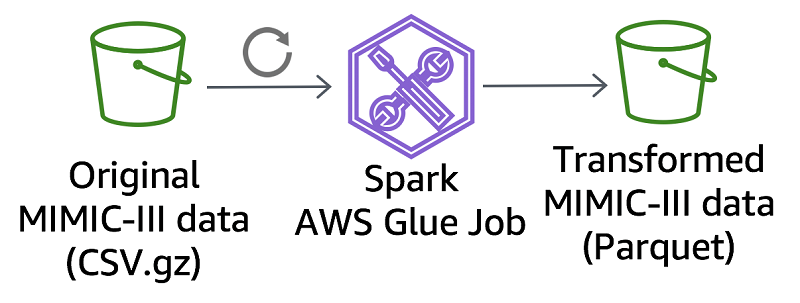
Perform biomedical informatics without a database using MIMIC-III data and Amazon Athena
This post describes how to make the MIMIC-III dataset available in Athena and provide automated access to an analysis environment for MIMIC-III on AWS. We also compare a MIMIC-III reference bioinformatics study using a traditional database to that same study using Athena.

Building a Real World Evidence Platform on AWS
Deriving insights from large datasets is central to nearly every industry, and life sciences is no exception. To combat the rising cost of bringing drugs to market, pharmaceutical companies are looking for ways to optimize their drug development processes. They are turning to big data analytics to better quantify the effect that their drug compounds […]
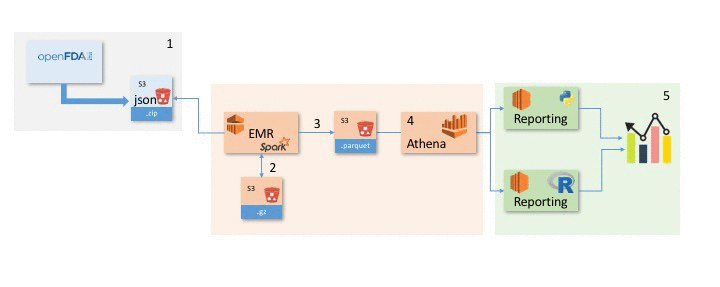
Analyze OpenFDA Data in R with Amazon S3 and Amazon Athena
One of the great benefits of Amazon S3 is the ability to host, share, or consume public data sets. This provides transparency into data to which an external data scientist or developer might not normally have access. By exposing the data to the public, you can glean many insights that would have been difficult with […]
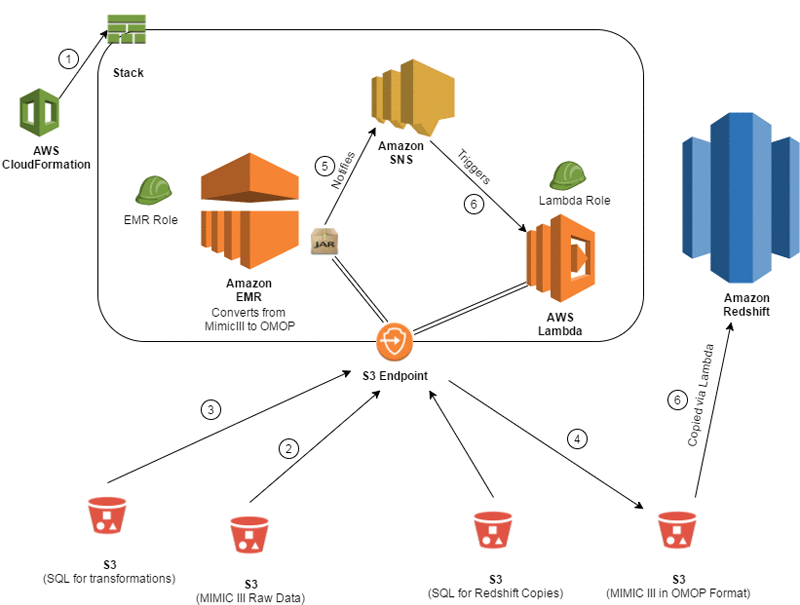
Build a Healthcare Data Warehouse Using Amazon EMR, Amazon Redshift, AWS Lambda, and OMOP
In the healthcare field, data comes in all shapes and sizes. Despite efforts to standardize terminology, some concepts (e.g., blood glucose) are still often depicted in different ways. This post demonstrates how to convert an openly available dataset called MIMIC-III, which consists of de-identified medical data for about 40,000 patients, into an open source data […]

Create a Healthcare Data Hub with AWS and Mirth Connect
As anyone visiting their doctor may have noticed, gone are the days of physicians recording their notes on paper. Physicians are more likely to enter the exam room with a laptop than with paper and pen. This change is the byproduct of efforts to improve patient outcomes, increase efficiency, and drive population health. Pushing for […]

Interactive Analysis of Genomic Datasets Using Amazon Athena
Aaron Friedman is a Healthcare and Life Sciences Solutions Architect with Amazon Web Services The genomics industry is in the midst of a data explosion. Due to the rapid drop in the cost to sequence genomes, genomics is now central to many medical advances. When your genome is sequenced and analyzed, raw sequencing files are […]

Optimize Amazon S3 for High Concurrency in Distributed Workloads
In today’s blog post, I will discuss how to optimize Amazon S3 for an architecture commonly used to enable genomic data analyses. This optimization is important to my work in genomics because, as genome sequencing continues to drop in price, the rate at which data becomes available is accelerating.

How Eliza Corporation Moved Healthcare Data to the Cloud
In this post, I discuss some of the practical challenges faced during the implementation of the data lake for Eliza and the corresponding details of the ways we solved these issues with AWS. The challenges we faced involved the variety of data and a need for a common view of the data.