Amazon Web Services ブログ

Amazon ElastiCache 向け Valkey 9.0 のお知らせ
本ブログでは、Amazon ElastiCache で利用可能になった Valkey 9.0 の新機能についてご紹介します。フルテキスト検索やベクトル検索、ハイブリッドクエリを組み合わせた高度な検索機能、パイプライン処理で最大40%のスループット向上、ハッシュフィールド単位の TTL 設定、クラスターモードでのマルチデータベース対応など、リアルタイム分析や生成 AI ワークロードを支える多彩な機能強化を学べます。Amazon Bedrock や Amazon SageMaker AI と連携した RAG アーキテクチャの構築にも役立つ内容となっています。

Build with Kiro: コミュニティハブと Kiro Labs のご紹介
Kiro コミュニティは、日々新たなものを生み出し続けています。境界を押し広げるハッカソンプロジェクトから、カスタムフック、創造的なエージェントワークフロー、そして SNS や Discord で共有される MCP インテグレーションまで、皆さんは私たちの想像を超える場所へ Kiro を連れて行ってくれました。Amazon 社内でも同じ現象が起きています。多様なバックグラウンドを持つビルダーたちが、私たちの予想を超える形で Kiro を最大限に活用するワークフロー、インターフェイス、ツールをカスタマイズしています。そして今、私たちはこれらすべてにふさわしい拠点を用意しました。

週刊AWS – 2026/4/27週
Amazon EC2 M8in/M8ibインスタンスの一般提供開始、Amazon QuickSightがチャット内ドキュメント・ビジュアル作成に対応、Amazon QuickSightで自然言語によるカスタムアプリ構築機能プレビュー開始、Amazon BedrockでOpenAIモデル・Codex・Managed AgentsをLimited Preview提供開始、Amazon Bedrock AgentCore RuntimeがNode.jsに対応、Amazon CloudFrontがキャッシュタグによる無効化をサポート、AWS LambdaがRuby 4.0をサポート開始等
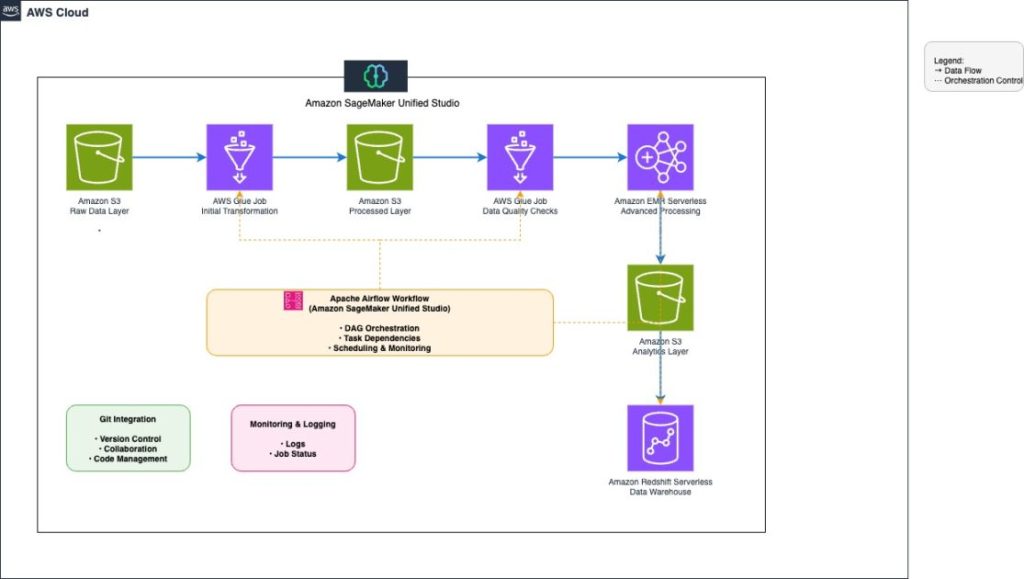
Amazon SageMaker ワークフローによるスケーラブルなエンドツーエンド ETL パイプラインのオーケストレーション
本記事では、Amazon SageMaker Unified Studio ワークフローでコードベースのエンドツーエンド ETL パイプラインを構築・管理する方法を紹介します。AWS Glue、Amazon EMR Serverless、Amazon Redshift Serverless、Amazon MWAA を組み合わせ、EC の顧客行動分析を例に、データ取り込みから変換、品質チェック、データウェアハウスへのロード、日次スケジュール実行まで、単一の統合 UI で構築する手順を解説します。

Amazon SageMaker Catalog でのビジネス用語集分類ルールの必須化
Amazon SageMaker Catalog で、資産レベルでの用語集タームの分類 (タグ付け) に対するメタデータ適用ルールがサポートされました。本記事では、金融サービスのユースケースを例に、プロジェクトから公開するすべての資産に特定のビジネス用語タームを必須化するルールの作成手順を紹介します。

Amazon SageMaker のメタデータ必須化ルールによるガバナンスの強化
Amazon SageMaker Catalog が新たにサポートするメタデータ強制ルールを使うと、データ公開やサブスクリプションのワークフローに必要なメタデータ項目を定義・強制できます。本記事では、特定のドメインにメタデータ強制ルールを設定し、カタログでの資産公開時と資産サブスクリプション時に強制適用する 2 つのワークフローを紹介します。

Amazon DataZone によるデータガバナンスのスケール: Covestro の事例
本記事では、Covestro が中央集権型のデータレイクから Amazon DataZone と AWS Serverless Data Lake Framework (SDLF) を使ったデータメッシュアーキテクチャへ移行した事例を紹介します。標準化されたブループリントと自動化されたガバナンスにより、1,000 を超えるデータパイプラインを運用しながら市場投入までの時間を 70% 短縮し、部門横断のデータ共有と品質管理を実現した経緯を解説します。

データサイロの解消: Volkswagen の Amazon DataZone を活用したアプローチ
本記事では、Volkswagen が Amazon DataZone を使ってデータサイロを解消し、データメッシュアーキテクチャを実装した事例を紹介します。AWS CDK を使った自動登録ワークフローにより、Amazon Redshift データウェアハウスのデータ資産を中央のデータメッシュに自動公開する仕組みを構築し、データガバナンスを維持しつつデータ検出とアクセスを効率化する方法を解説します。

Amazon SageMaker のカスタムサブスクリプションワークフローによるデータガバナンスの加速
本記事では、Amazon SageMaker のサブスクリプションリクエスト承認を自動化するカスタムワークフローを紹介します。AWS Lambda、Amazon EventBridge、Amazon SNS を組み合わせたイベント駆動型のサーバーレスアーキテクチャにより、ガバナンスを維持しつつ機微でないデータセットへのアクセスを迅速化できます。
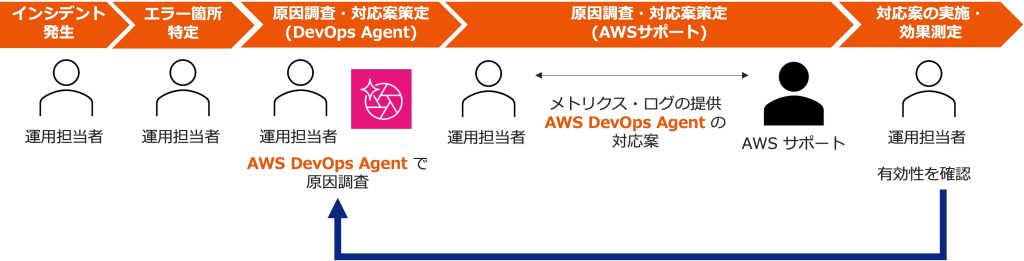
KDDI が実践する AWS DevOps Agent 活用:AWSサポートと連携したインシデント対応の効率化
本ブログは、KDDI 株式会社 パーソナル事業統括本部 システム開発本部 ライフデザインプラットフォーム部 ア […]