AWS Partner Network (APN) Blog
Gathering Market Intelligence from the Web Using Cloud-Based AI and ML Techniques
By Dhairya (DJ) Kalyani, Chandramouli Muthu, and Shivamurthy H G, Sr. Architects at Accenture
By Gopal Wunnava, Principal Architect at AWS
 |
Many organizations face the challenge of gathering market intelligence on new product and platform announcements made by their partners and competitors—and doing so in a timely fashion.
Harnessing these insights quickly can help businesses react to specific industry trends and fuel innovative products and offerings inside their own company.
This can be challenging, however, given the need to tap into a diverse pool of online data sources, along with the skills and resources required to consume, store, and analyze this information using artificial intelligence (AI) and machine learning (ML) techniques.
At any given point, businesses may have a host of online data sources to tap into for the purpose of gleaning insights. Typically, organizations need to source data from various channels like the web and social media, for example. Manually sourcing data from these channels can be extremely difficult and, in most cases, the information captured can be lost or remain uncaptured.
Addressing the underlying complexity involved in the extraction of information from specific websites is one of the key issues surrounding web crawling today. To find a solution to this problem, organizations can make use of AI and ML techniques to enable new insights or perspectives in an automated and timely manner.
In this post, we will discuss how Accenture, an AWS Partner Network (APN) Premier Consulting Partner and Managed Service Provider (MSP), helped a customer use Amazon Web Services (AWS) to gather critical insights along with key signals and trends from the web using AI-ML techniques.
The focus here is on the rapid gathering of intelligence by taking advantage of proven and highly scalable AI-ML technology from AWS that requires no machine learning expertise to use.
Data Sources, Scope, and Challenges
The data sources typically used by customers to gather insights can range from websites catering to industry-specific content, online news channels, social media, and online data providers specific to the customer’s industry.
Given the volume and variety of data involved, data sourcing and processing can be far more complex than typical business intelligence (BI) solutions allow. In many BI solutions, data is structured and made available in a data warehouse or data lake environment in query-optimal formats such as parquet.
Often, getting the data to the point where it can be labelled as useful can be challenging. Due to time and scope considerations, data sources can be narrowed.
In this case, Accenture worked with the customer to narrow down the data sources to a handful of websites and online news. Even after narrowing down the data sources, however, we found these selected websites had at least a few thousand web pages each that needed to be scanned in order to uncover meaningful and useful insights.
Given the nature of the problem and various types of data sources involved, the technical challenges faced by the customer can be summarized as follows:
- Raw and unstructured nature of the data.
- Disparate data sources in multiple formats.
- Huge volumes of data (e.g. web pages).
Results comprise a large number of false negatives and/or duplicates that may not add value to the actual results being sought by organizations.
Conceptual View of Solution
To address the problem holistically, Accenture broke the point of view into the following parts:
- Content extraction: This formed the basis for extracting content from websites of interest, and involved identifying URLs of relevant pages, parsing and extracting content, along with the use of regular expressions for finding matches based on specific patterns.
- Keyword search: Accenture worked with the customer on obtaining sample search results they’d like to see as a starting point for newly-generated insights. This resulted in a list of keywords and phrases that can be associated with terms of interest, such as innovation, new technology, and product offerings.
- Matching word extraction: We built a search crawler that took the keyword list outlined in the previous step as input, parsed through several hundred HTML web pages from each of the underlying websites, captured entire paragraphs resulting from the search results.
- Data packaging and consolidation: Results from individual CSV files would be filtered, transformed, and consolidated using Python scripts and packages, which perform basic ETL tasks such as filtering and removing of special characters. The consolidated dataset is stored in a data lake environment.
- Analysis and visualization: The consolidated dataset would be queried and analyzed using Natural Language Processing (NLP) techniques in order to obtain more meaningful insights. Eventually, the dataset would be consumed into a dashboard environment, providing additional insights using visualization and ML techniques.
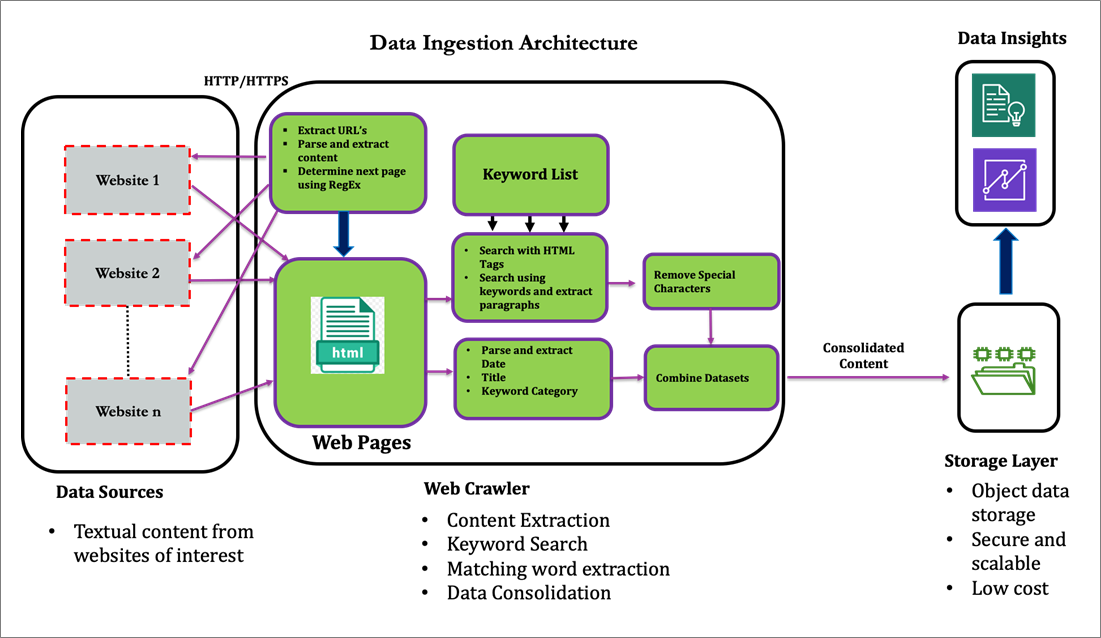
Figure 1 – Conceptual view of web-based market intelligence solution.
Technical Solution Architecture
In order to address the conceptual solution outlined in the previous section, we designed a process to automatically crawl, search, and extract relevant datasets from websites of interest, package and consolidate the datasets, and store the datasets in the customer’s data lake environment.
The data lake serves as the basis to analyze and visualize the datasets to help gather the intelligence we seek. The high-level architecture of the solution on AWS is represented in Figure 2.
Amazon Simple Storage Service (Amazon S3) serves as the object storage layer in the data lake for collecting, storing, and retrieving data at scale. In our example, the S3-as-a-data lake environment is used to store consolidated results from the web crawling process.
Amazon QuickSight serves as the BI layer that makes it easy to deliver insights using visualization and ML techniques. Insights are driven by QuickSight dashboards that can be accessed from any device, and embedded into applications, portals, and websites.
For this use case, the team at Accenture made use of the Machine Learning Insights feature in QuickSight to discover deeper insights and trends in the data. No AI-ML knowledge is required to apply this feature.
Amazon Comprehend provides NLP functionality and uses ML to find various insights and relationships in text. It can be used to determine sentiment, key phrases, and topics of interest contained in the crawled data sets. Results can be visualized using QuickSight and, again, no AI-ML knowledge is required.
AWS Lambda serves as the serverless compute layer and performs functions such as content extraction, search and pattern matching, data packaging, and consolidation. Amazon API Gateway can be used as the “front door” to handle tasks such as concurrency, traffic management, security, and throttling.
For handling periods of high web traffic, consider building an asynchronous serverless architecture that will handle spikes in traffic using services like Amazon API Gateway, Amazon Kinesis, or Amazon Simple Queue Service (Amazon SQS).
Amazon Athena serves as the interactive query service to analyze data on Amazon S3 using standard SQL. Since Athena scales automatically, it can be used in this architecture to handle large datasets for batch processing.
Another feature of Athena is that it can integrate easily with Amazon QuickSight without the need to manage servers, allowing us to create dashboards for business analytics with scale and flexibility. AWS Glue crawlers can be used to automatically infer the schema from your dataset and store the associated metadata in the AWS Glue Data Catalog.
Athena natively supports querying datasets and data sources that are registered with the AWS Glue Data Catalog.
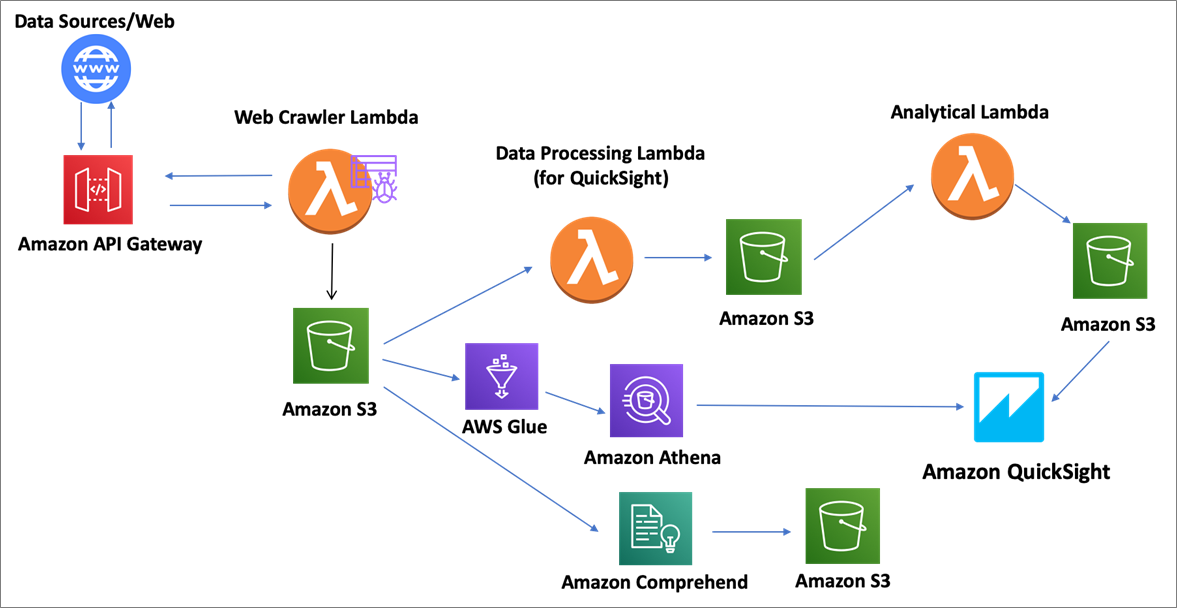
Figure 2 – AWS technical solution architecture.
As depicted in Figure 2, the solution framework has three key Lambda functions. Let’s review these functions at a high level before diving into more details for each function.
- Web crawler Lambda function: We used the Scrapy package in Python to crawl web pages and provide the required response objects. This code is packaged into a Lambda function and contains both the parser function responsible for extracting relevant links and providing response objects, and web links function that’s a data structure consisting of all the links obtained from each page crawled.
- Data processing Lambda functions: These perform the pre-processing of data and any required data preparatory steps for subsequent processing in QuickSight. If you need to crawl a specific website again to extract new updates, the data processing Lambda function provides the first five URLs of websites crawled previously, while the web crawler Lambda function crawls these websites again to extract the requested updates.
- Analytical Lambda function: This is responsible for determining the delta that is used to refresh the QuickSight dashboards using S3 as the data source.
Next, the following sections will dive deeper into the details of each solution component.
Web Crawler Lambda Function
In this framework, we’re crawling the web at two different levels (1 and 2). Level 1 helps us perform horizontal crawling, while level 2 helps with deep crawling.
The steps involved in this framework are as follows:
- The crawler function initially starts crawling the website using a starting URL page.
- The function connects to the website and processes the underlying pages corresponding to the URLs provided. This leads to the generation of the response object for this page.
- The same response object is passed to the parser, which understands the content of the crawled pages and extracts key metadata elements. This can include next page information, textual content, dates, and relevant links or hyperlinks.
- Using the next page information from the metadata context obtained in the earlier step, the parser constructs the subsequent next page URL and passes the combined URL information to the data processing Lambda function for crawling subsequent pages.
- The same process continues until the last page of the starting URL has been crawled. We’ll refer to this crawling process as level 1 or horizontal crawling.
- Relevant links or hyperlinks for each page can be accumulated as a stack of hyperlinks to be used for level 2 crawling. Note that 1) for most web pages, the relevant content is typically distributed along multiple pages, and 2) use of level 2 crawling helps extract this distributed content based on the stack of accumulated hyperlinks.
- Once the level 1 crawling has been completed, the parser processes the set of stacked hyperlinks accumulated previously and provides all the links to the data processing Lambda function for the purposes of crawling further (level 2 crawling).
- The resulting response objects are stored in Amazon S3 in CSV format.
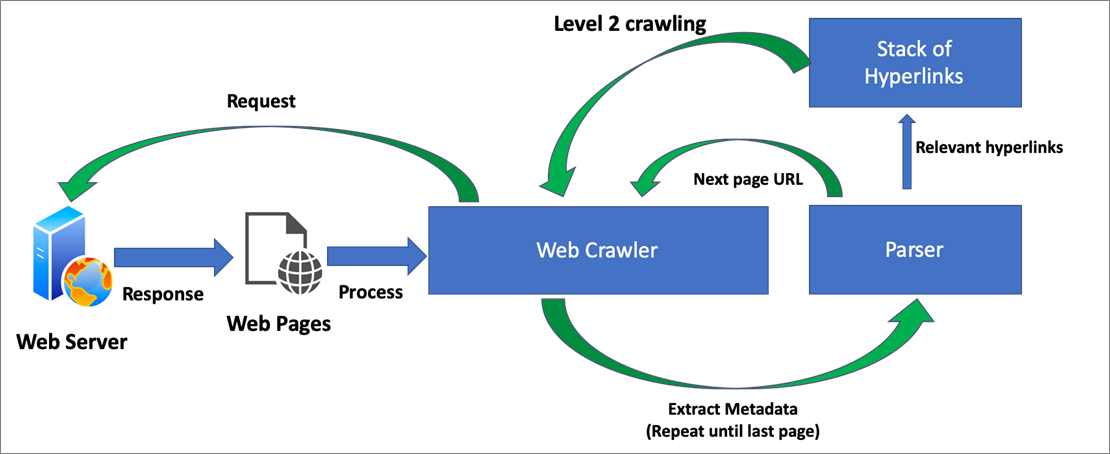
Figure 3 – Pictorial view of the web crawler framework.
Data Processing Lambda Function (for QuickSight)
The primary objective of the data processing Lambda function (for QuickSight) is the extraction of required data elements (website, url webpage_title, keyword_category, text and publication_date), along with any associated data using the information obtained from the response object of the web server.
This function enables you to locate each and every element of the object using regular expressions (Regex) for identifying the underlying elements based on a pattern match.
Textual content and metadata elements, such as the date element, can be created and processed using the knowledge gathered previously from the response object. All relevant entities are pulled out from the response object using the XML path language (Xpath).
The combination of Xpath and Regex usage helps preserve associations within the data elements. One of the key attributes obtained from this process is the underlying textual content, which forms the basis for further analysis.
Additional keywords from our predefined list are applied to this textual content to get the most relevant data points. This enables you to construct the metadata elements (main URL, first five and last five URLs, number of records).
Lastly, we will keep appending the data into a single data frame, which is stored as a CSV file in Amazon S3.
 Figure 4 – Delta processing and refresh logic.
Figure 4 – Delta processing and refresh logic.
Analytical Lambda Function
The analytical Lambda is created for processing the delta operations, with the delta being defined as new content or updated information from our web sites of interest. Subsequently, this delta information is used to refresh the QuickSight dashboards based on a schedule using an Amazon S3 manifest file.
For processing the delta, we compare the date attributes captured previously from web pages. If this function finds any applicable delta, we proceed to refresh the QuickSight dashboard and update the metadata accordingly in S3.
In some cases, the date attributes may not be available from the web pages. In such situations, the Lambda function processes each and every page of textual content from the new dataset.
The processed text content can be represented in the form of TF-IDF vectors and projected in the form of a feature vector. We then calculate the cosine similarity between the content of the previous page and most recent page using these projected vectors.
Based on the predefined similarity threshold, the analytical Lambda function finds the associated delta and refreshes the QuickSight dashboard accordingly.
Visualization Layer
The BI and visualization layer sources data from the consolidated results stored in Amazon S3 and uses QuickSight to gain insights into the data. For large datasets, data is sourced from Amazon Athena to provide scale and performance. Note that you can use a Glue crawler to keep the AWS Glue Data Catalog and Amazon S3 in sync.
In addition to the visualization capabilities, the solution also takes advantage of the Machine Learning Insights feature in QuickSight to derive insights and trends without the need for any additional programming effort.
There are two distinct patterns involved here. One involves ingesting straight from the web crawling results, which is in the form of a CSV file stored in S3. The other pattern involves creation of an Amazon Athena table on top of the underlying data and sourcing the data from Athena for the visualization effort.
The visualization step applies a filter to the keyword category attribute (e.g. drilling) for displaying relevant results on the dashboard. Multiple visuals are generated based on aggregated datasets, and a detailed breakdown is provided based on keyword category.
Presented in Figure 5 is a dashboard that represents a count of keywords across various categories of interest. For example, it may be useful to know that terms like visualization and virtual reality occur with high frequency in our collection of documents.
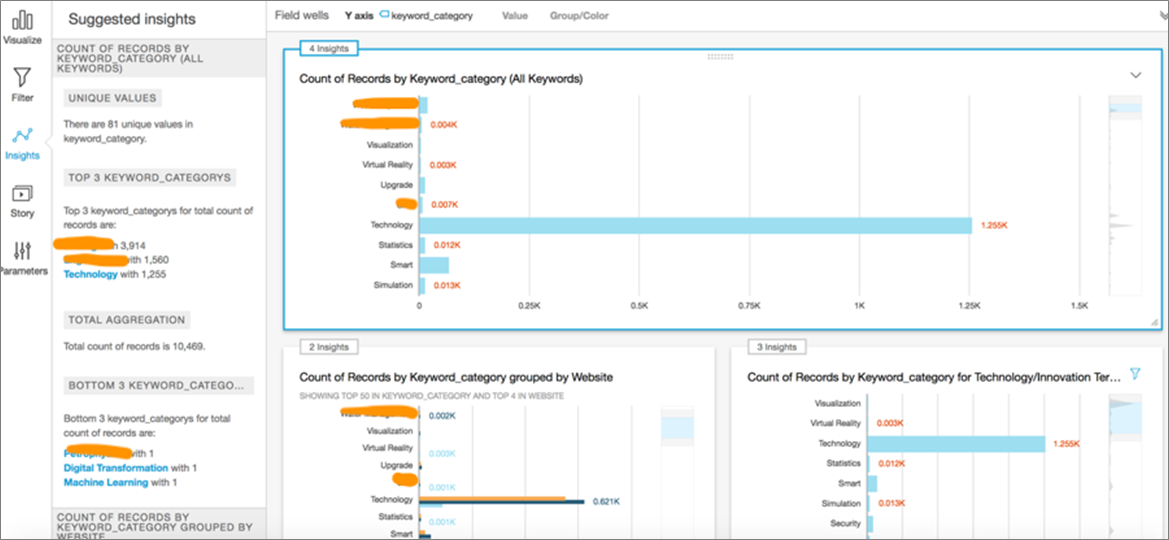
Figure 5 – Summary dashboard visual based on counts of key trends observed.
The next dashboard in Figure 6 represents a count by publication date and keyword category. A dashboard of this nature may be useful to pick up certain trends, such as a spike in the occurrence of terms like analytics, automation, and AI on specific dates. You’ll then observe the suggested insights obtained from the ML Insights feature on the far left of this figure.
We can use the intelligence obtained here to explore our datasets further and determine the likely cause for these spikes.
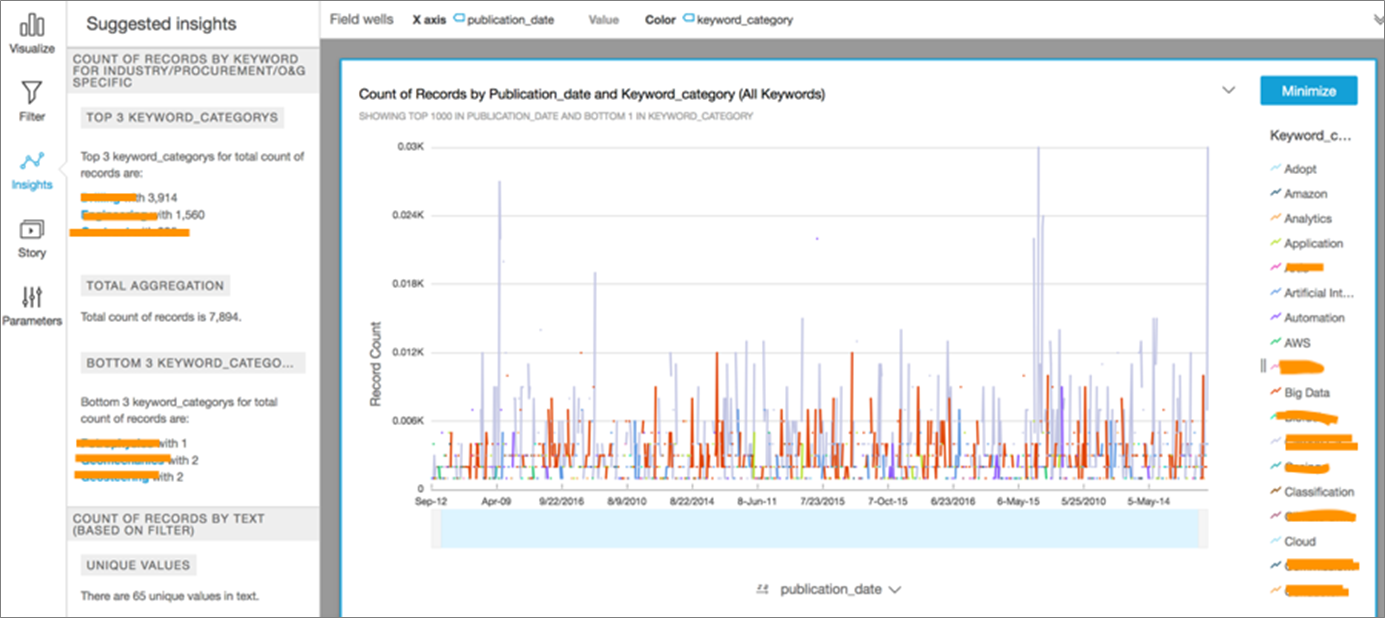
Figure 6 – Keyword category visual based on trends over time by publication date.
Amazon Comprehend
Amazon Comprehend can be used to carry out NLP tasks such as sentiment analysis, topic modeling, and key phrase extraction with no prior knowledge of NLP or machine learning.
In order to gain insights using NLP techniques, the team at Accenture executed analysis jobs in Amazon Comprehend to analyze the content of documents contained in the consolidated dataset stored in S3. The results provide insights on entities, phrases, primary language, or sentiment found in these documents.
Due to the volume of data contained in the consolidated data set, we used the Asynchronous Batch Processing feature in Amazon Comprehend to carry out these tasks.
The sample results below capture the sentiment class for each line in the document based on the class with the highest confidence score, along with the associated confidence scores for each sentiment class.

The next results represent a sample set of key phrases in our documents obtained using Amazon Comprehend’s key phrase detection feature.

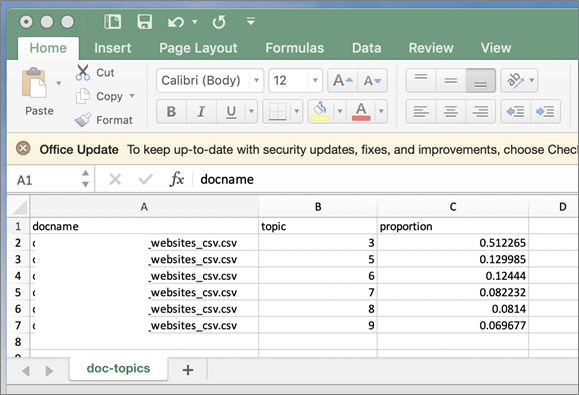
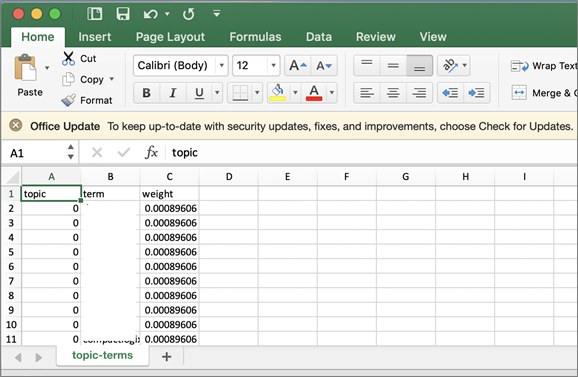
The next two screenshots represent a sample set of topics and terms in our collection obtained using Amazon Comprehend’s topic modeling feature.
The output below is a sample list of documents associated with a topic along with the proportion of the document that is concerned with the topic.
The output below is a sample list of topics in the collection. For each topic, the list includes the top terms associated with that topic along with the associated weight.
Lessons Learned
While there are many benefits to building a solution like this for your organization, it would be worth pointing out some challenges and underlying complexities involved.
- Structure, format, and arrangement of relevant information is unique to each website. This creates a challenge in terms of consistently applying a crawling framework across multiple websites.
- Performance challenges created by large volumes of web pages that need to be scanned and retrieved (crawl performance and latency varies by website).
- Not every website is crawler-friendly, and upfront analyses needs to be performed to determine the crawler worthiness of these websites. Note that some websites may ban crawling altogether or reject automated crawlers.
- Lack of standard web crawling tools and APIs that work consistently across all websites.
- Availability of skilled resources: building a solution like this requires a combination of skills across programming, web crawling, search technologies, big data, and AI-ML, among others.
Extending the Solution
The solution approach identified in this post could be modified in several different ways to suit your needs, including:
- Use of a different, and perhaps more efficient, toolkit for crawling. This could be supported not just in Python but in other languages like R, or even an open source tool.
- Use of Amazon SageMaker for AI and ML-driven insights involving more sophisticated use of NLP techniques, which requires knowledge of programming and machine learning techniques. Here are some additional pointers in this regard:
- Enhanced text classification and word vectors using the Amazon SageMaker BlazingText algorithm.
- Creation of low dimensional embeddings from high dimensional objects, using Amazon SageMaker’s Object2vec algorithm.
- Use of AWS Lake Formation to build, manage, and secure the data lake end-to-end. For this specific use case, two features come to mind:
- The data catalog feature can be used to build the catalog that will describe the crawling dataset results.
- The ML transform feature can be used to resolve duplicate web pages (an alternative approach to using TF-IDF).
- Adding audio, video, and image processing capabilities to the solution using native AI-ML services. This includes harnessing content from non-English websites using Amazon Translate and Amazon Transcribe.
Summary
In this post, we discussed how Accenture helped a customer derive intelligence from the web on industry trends, competitive offerings, and consumer sentiments.
The intelligence obtained from a solution like this can be used by any organization to carve out a strategy to create new offerings, or improve upon existing ones. The key is to obtain these insights in a timely fashion with minimal effort, using technology that has built-in capabilities.
For our solution, the fact that AI-ML services from AWS come with pre-trained deep learning technology and require no machine learning experience was a significant benefit to our customer, who had limited knowledge and resource availability in this space.
We hope the ideas and approach laid out here can serve as a launching pad for your teams to build AI-ML solutions on AWS, enabling you to gain new insights and trends for your organization through artificial intelligence and machine learning techniques.
.

.
Accenture – APN Partner Spotlight
Accenture is an APN Premier Consulting Partner and Managed Service Provider. A global professional services company that provides an end-to-end solution to migrate to and manage operations on AWS, Accenture’s staff of 440,000+ includes more than 4,000 trained and 2,000 AWS Certified professionals.
Contact Accenture | Practice Overview
*Already worked with Accenture? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.