AWS Partner Network (APN) Blog
How Slalom and WordStream Used MLOps to Unify Machine Learning and DevOps on AWS
By Dylan Tong, Machine Learning Partner Solutions Architect at AWS
By Courtney McKay, Solution Architect at Slalom
By Krishnama Raju, Director Engineering at WordStream
 |
A recent Gartner survey revealed that 14 percent of global CIOs have already deployed artificial intelligence (AI), and 48 percent would deploy it in 2019 or by 2020.
The upward trend in production deployments is a sign that more businesses are achieving value from AI and driving a fundamental shift in data science from experimentation to production delivery.
Deploying AI solutions with machine learning (ML) models into production introduces new challenges. Data scientists are typically involved in developing ML models, but they’re not responsible for production processes and systems.
Productionizing models requires bringing together data science, data engineering, and DevOps expertise, processes, and technologies.
Machine Learning Operations (MLOps) has been evolving rapidly as the industry learns to marry new ML technologies and practices with incumbent software delivery systems and processes.
WordStream is a software-as-a-service (SaaS) company using ML capabilities to help small and mid-sized businesses get the most out of their online advertising. Their product development team partnered with Slalom to augment their data science expertise and accelerate project delivery.
Slalom is an AWS Partner Network (APN) Premier Consulting Partner with the AWS Machine Learning Competency.
In this post, we describe the machine learning architecture developed at WordStream to productionize their ML efforts. We’ll also provide additional insights and alternative approaches to what was built at WordStream to help you establish best practices in your own data science projects.
The Project
The machine learning project Slalom undertook with WordStream aimed to leverage performance data across networks and channels to build a cross-platform recommendation engine. Its initial goal was to identify similar advertising profiles based only on keyword and search terms.
The data scientists at Slalom’s Boston Data & Analytics practice created a text processing pipeline and topic models on Amazon SageMaker, using spaCy and Gensim, which are open source libraries designed for natural language processing (NLP). Amazon SageMaker enables ML practitioners to build, train, and deploy ML models at any scale. It supports a wide range of ML libraries and frameworks in addition to spaCy and Gensim.
Slalom designed topic models that identify patterns of co-occurring terms in WordStream’s ad campaigns, which can represent topics or meaning within the text corpus. They created the topic models by training on a large text corpus—the keywords and search terms—that represented thousands of anonymized ad campaigns.
They used the topic models to score each campaign on the likelihood of aligning with each of the topics in the corpus, creating a digital fingerprint that represents the underlying subject matter of each campaign.
Lastly, Slalom clustered the campaigns on their digital fingerprints using the nearest-neighbors algorithm. This enables users to identify similar ad campaigns, and forms the basis of recommended actions that help WordStream’s customers optimize their campaign strategies.

Figure 1 – Example of WordStream recommended actions.
The Challenges
Challenges surfaced as the project transitioned to production.
WordStream set a high bar for operability for any new ML capabilities they offered to customers. Among other things, data pipelines had to be scaled and automated, and data science processes had to be unified with product delivery processes. This included operability with the existing continuous integration/continuous development CI/CD pipeline, which provides a low-risk path to production.
Finally, collaboration across DevOps, data science, and data engineering disciplines was necessary.
The following figure depicts the top level of a continuous ML delivery lifecycle. WordStream and Slalom developed a similar process to support their ML project.
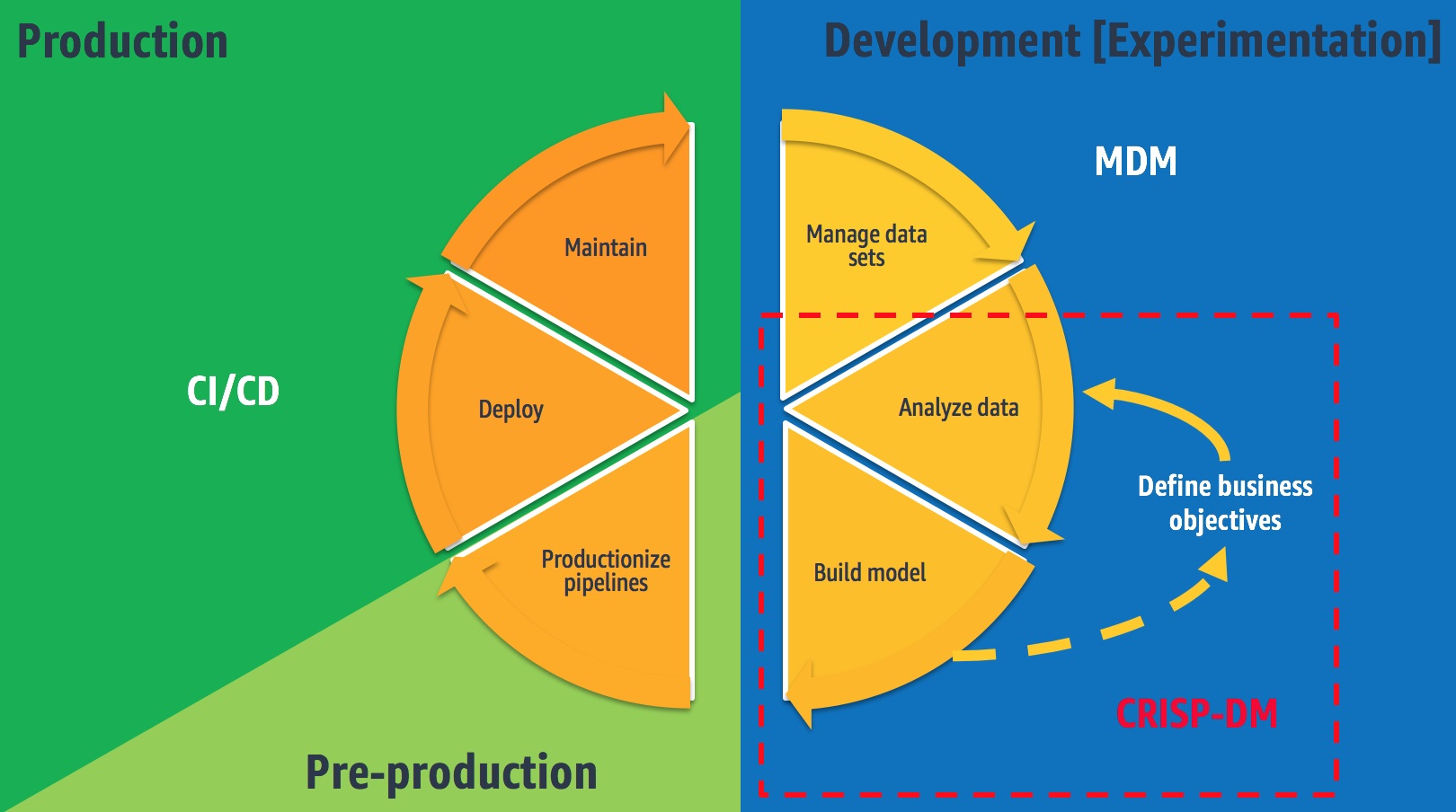
Figure 2 – Continuous machine learning delivery lifecycle.
This lifecycle extends data science processes like CRISP-DM and unifies them with data management and DevOps practices like master data management (MDM) and CI/CD.
However, Figure 2 doesn’t tell the whole story around application delivery. Figure 3 enumerates the many tasks associated with each stage of the lifecycle.
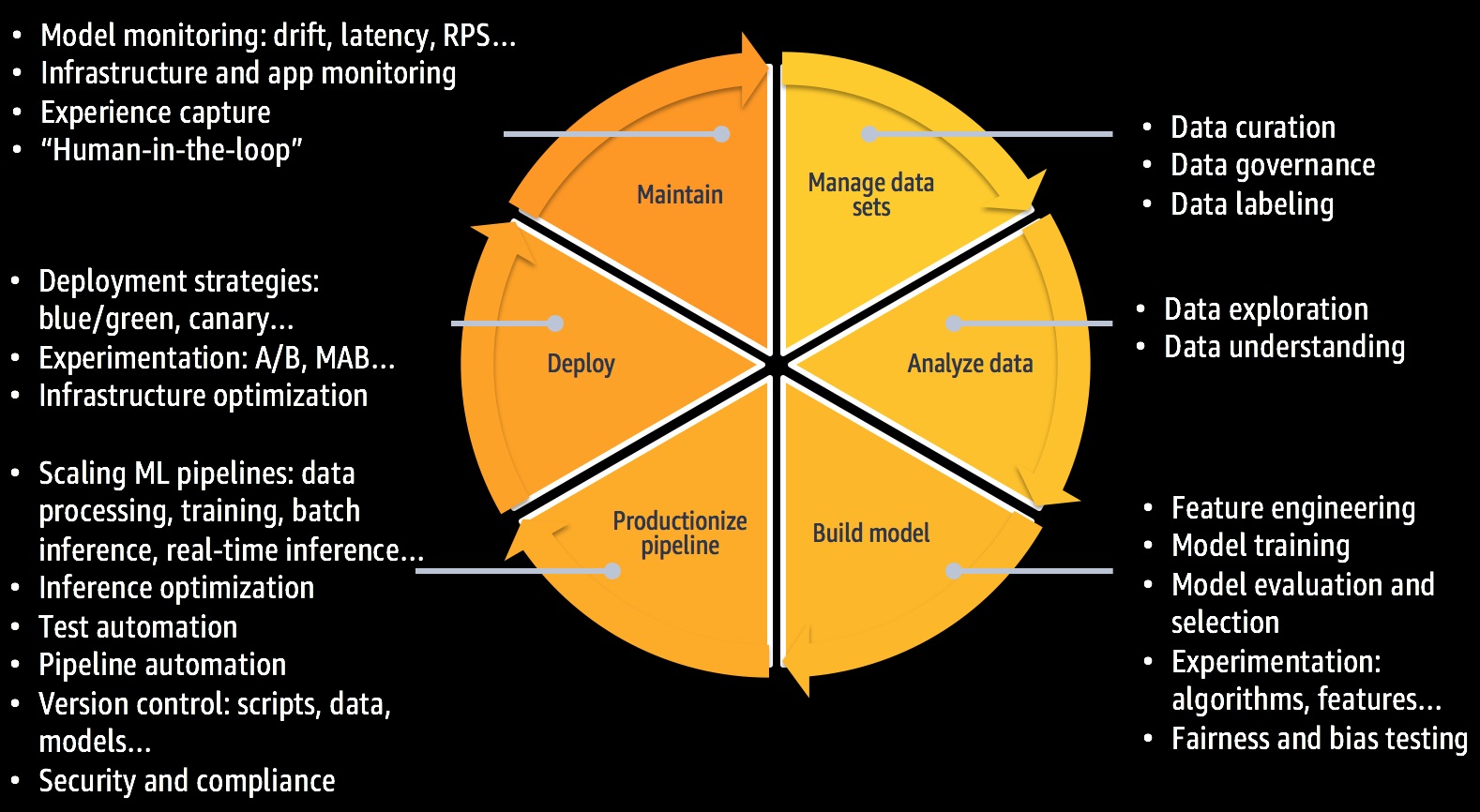
Figure 3 – Tasks needed to unify data management and DevOps.
It’s clear these tasks extend beyond the scope of a single role, team, and the data science domain. A complete process has to draw from data engineering practices to fully address data pipelining, curation, governance requirements, and DevOps to account for a number of operational tasks.
The Solution
WordStream and Slalom reached a juncture in their project as the focus began to shift from prototyping to production delivery. There was a need to formalize new processes and systems. Together, WordStream, Slalom, and Amazon Web Services (AWS) collaborated to define a reference architecture for continuous ML delivery on AWS.
The architecture presented in this post is similar to WordStream’s implementation, largely built on AWS services. Nonetheless, there’s a wide selection of partner solutions that are viable alternatives to the presented building blocks.
Since this solution spans many domains, we’ll present the architecture as an evolutionary process through the six stages of the ML delivery lifecycle shown in Figure 3:
- Establish a data architecture
- Facilitate data analysis
- Enable rapid prototyping
- Productionize pipelines
- Deploy ML models
- Continuous improvement
1. Establish a Data Architecture
The following figure illustrates the data management system—the AWS data lake. Its purpose is to facilitate data curation and governance.
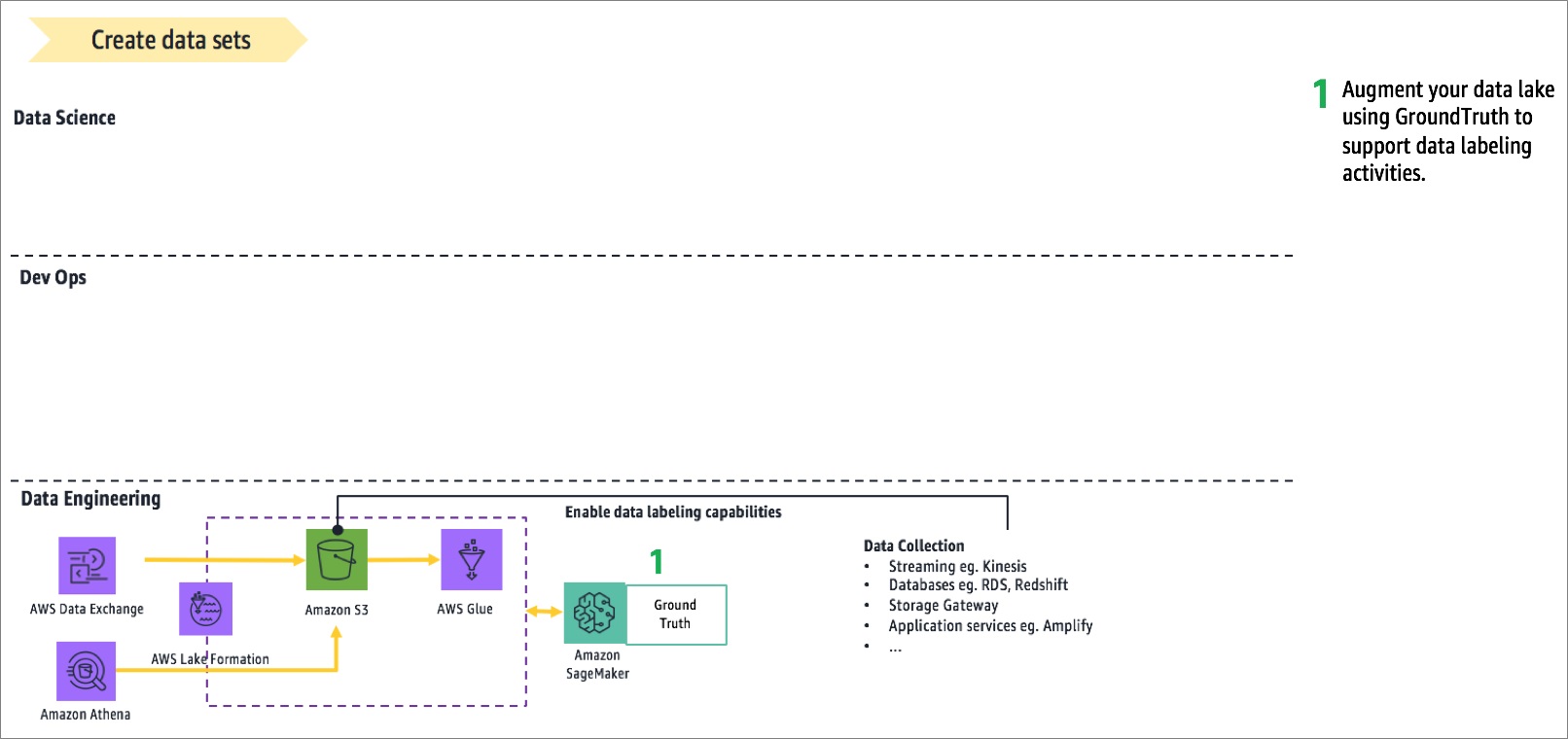
Figure 4 – How to establish a data architecture for data science.
A basic data architecture should be established before scaling data science activities. There should be a system to track and curate features used for model training, the versioning on data sets, and a way to enforce granular security controls. These capabilities are important to ensuring ML processes are auditable.
The data architecture can be augmented over time with capabilities like data labeling to support supervised learning.
WordStream’s topic models are an example of unsupervised learning, which doesn’t require data labels. In many cases, ML algorithms are based on supervised learning, which require labeled data to serve as training examples.
For instance, an ML model could be trained to detect the presence of branding in rich media across social networks. A supervised algorithm would require examples of images with branding and corresponding labels to identify the branding in each image.
You can use Amazon SageMaker Ground Truth to manage data labeling at scale. It provides capabilities like integrated workflows with labeling services like Amazon Mechanical Turk to scale workforces, automatic labeling using active learning to reduce cost, and annotation consolidation to maintain label quality.
2. Facilitate Data Analysis
Once the datasets were available, Slalom’s data scientists were able to develop on Amazon SageMaker as shown in Figure 5. They deployed Amazon SageMaker notebooks, which provided them with managed Jupyter environments.
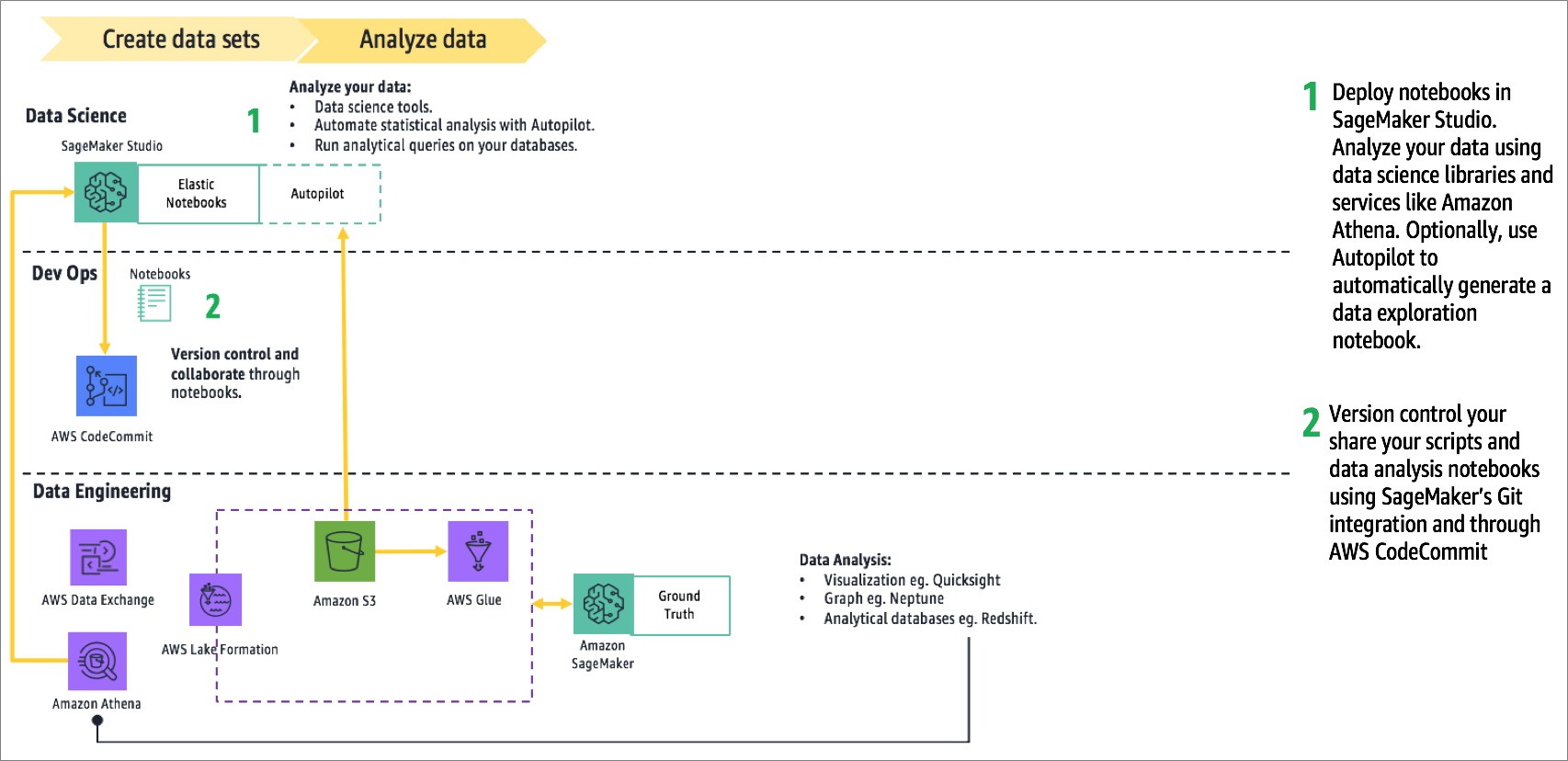
Figure 5 – How Slalom facilitated rapid prototyping.
Slalom used Python data science libraries within the notebooks to facilitate data exploration. They could have also accessed analytical systems like data warehouses within these notebooks.
With the recent release of Amazon SageMaker Autopilot, there’s now also the option to automate data profiling by generating data exploration notebooks that provide insights into data distribution, missing values, and other quality issues. These insights guide data prep requirements such as imputation and data cleansing.
Slalom versioned and shared their notebooks through Amazon SageMaker’s Git integration. WordStream uses AWS CodeCommit, which gives them a private, fully-managed Git repository.
3. Enabling Rapid Prototyping
The following figure depicts the system Slalom used during model development.
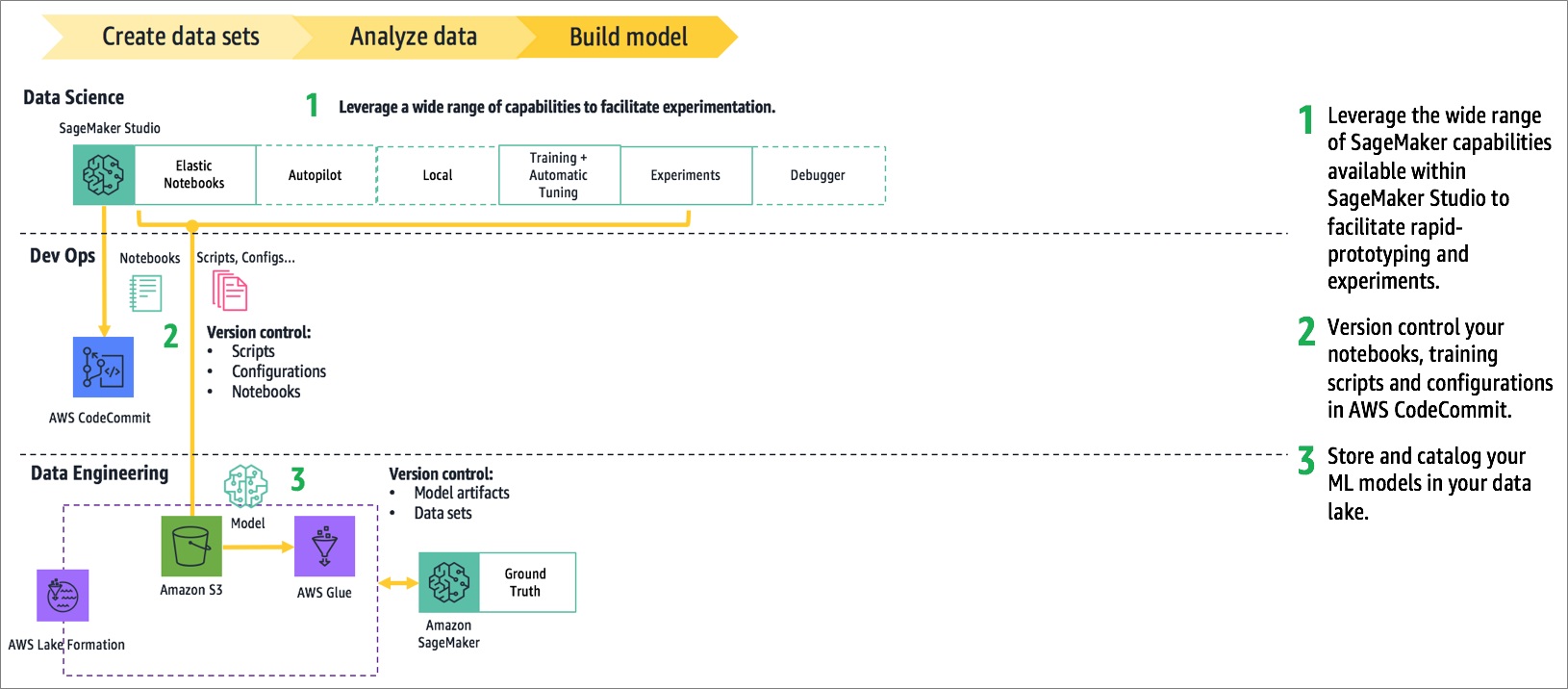
Figure 6 – Active system Slalom used for rapid prototyping.
At this stage, one might consider adjusting the notebook resources for GPU acceleration and other resources to facilitate prototyping. Using Amazon SageMaker, Slalom had the flexibility to use the Latent Dirichlet Allocation (LDA) algorithm, spaCy, Gensim, scikit-learn, and other tools within the notebook to rapidly prototype their topic and clustering models.
As the project transitioned from experimentation to production, Slalom had to refactor local training scripts for Amazon SageMaker remote training. This provides large-scale training with zero setup and serverless infrastructure economics. Thus, it’s suited for production scale and automation requirements.
Slalom used Amazon SageMaker Local to facilitate this transition. This feature allows developers to simulate the remote training environment by running a container on the notebook instance. Using it, you can validate training scripts without having to launch remote training jobs that incur a lot of overhead during iterative development.
Depending on the situation, there’s a range of Amazon SageMaker components that could be utilized at this stage. Automatic Model Tuning can save time and cost by automating hyperparameter optimization. The Debugger can analyze and catch errors during remote training. Experiments facilitates experiment tracking, and Autopilot delivers solutions for supervised learning problems using AutoML.
4. Productionize Pipelines
The next figure illustrates how the system expanded into the DevOps domain as the project transitioned towards production. Before WordStream introduced ML into their application delivery process, a CI/CD pipeline built on AWS DevOps services existed (the blue icons).
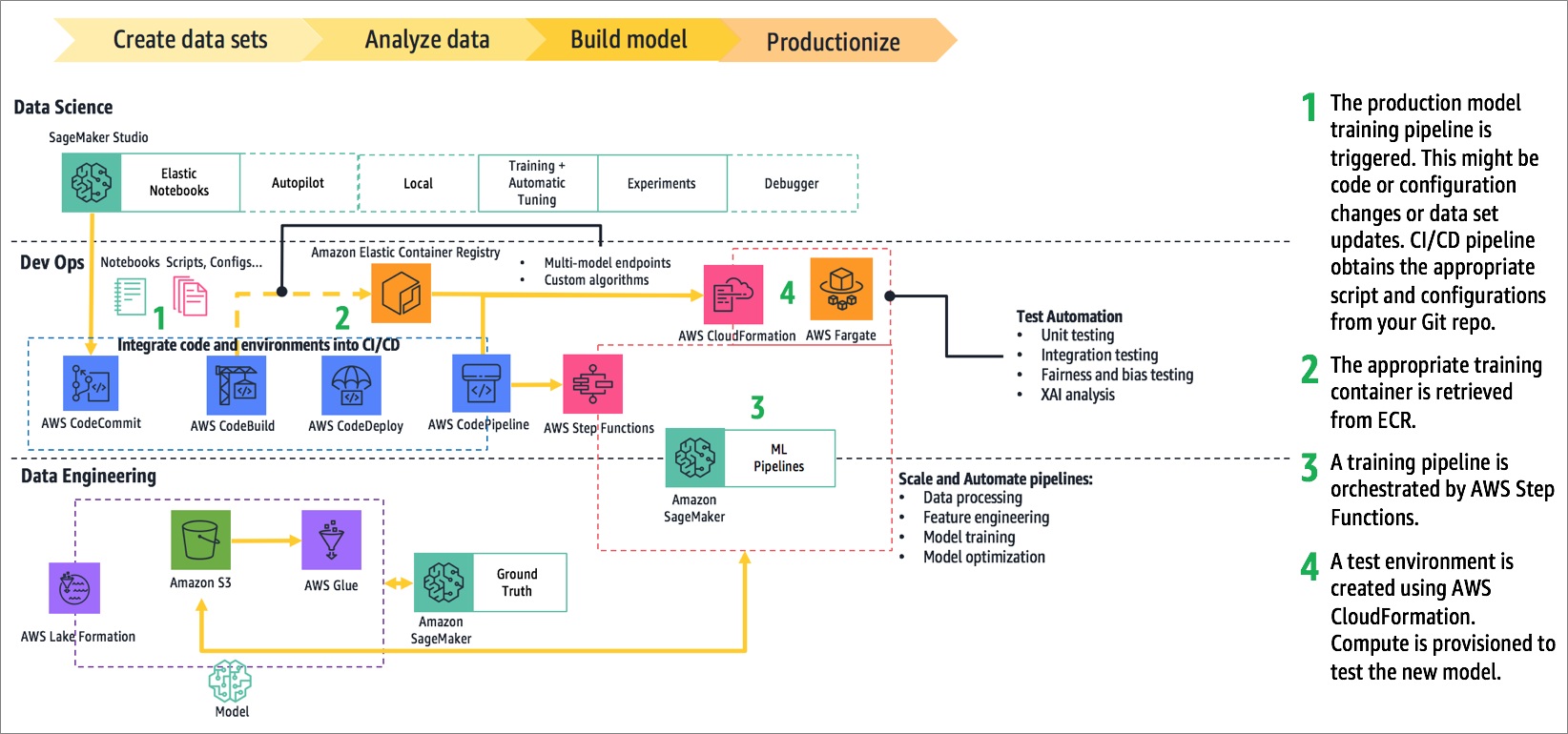
Figure 7 – How the system expanded into DevOps.
WordStream’s DevOps team extended the CI/CD pipeline to manage Gensim containers, orchestrate training pipelines, and automate tests. They built Amazon SageMaker-compatible containers according to the documented process to train and serve Gensim and spaCy models.
Pre-built Amazon SageMaker containers are available to support common scenarios like built-in algorithms, deep learning frameworks, SparkML, and scikit-learn. As a best practice, you should use these containers when possible to avoid having to manage your own containers, or use them as a base image to reduce maintenance work.
WordStream used the Data Science Software Development Kit (SDK) in AWS Step Functions to orchestrate the Amazon SageMaker training pipeline. Its native integration and serverless design enabled WordStream’s DevOps team to stay lean and agile.
WordStream generated test automation environments using AWS CloudFormation, and executed test suites on AWS Lambda, which was selected for its simplicity and low operational overhead.
AWS Fargate provides clusterless container management and is a good option for cases that require longer running tests.
Amazon SageMaker provides various utilities to track model performance. However, you should consider implementing automated tests as part of your pipeline to support granular error analysis. You could use model interpretability and explainability (XAI) tools such as Shap to help you understand what’s influencing the predictions that are generated by your black-box models.
Additionally, if your model has sensitive applications, you should implement regression tests for evaluating model fairness.
Once WordStream built their test automation and container build pipelines, they integrated these systems into their CI/CD pipeline running on AWS CodePipeline.
5. Deploy ML Models
The following figure illustrates how the system progressed into deployment.
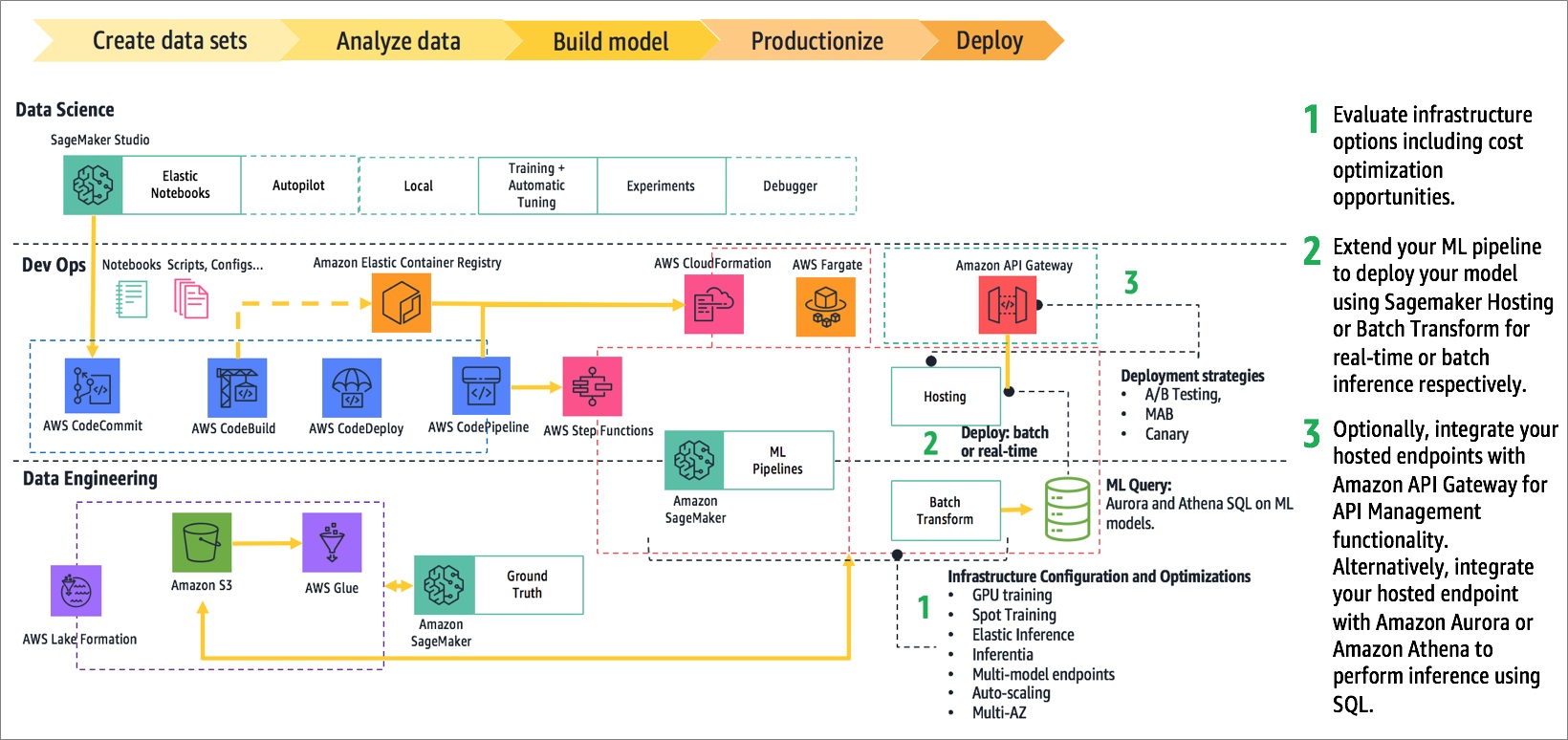
Figure 8 – Progression into deployment.
At this point, WordStream’s data processing, feature engineering, and training pipelines were automated, performant, and scalable.
You could optionally include Amazon SageMaker Neo in some pipelines to optimize your model for multiple target platforms.
Once Slalom’s models met WordStream’s quality standards, WordStream deployed them into production. Amazon SageMaker supports batch and real-time inference on deployed models through two features: Batch Transform and Hosting Services.
WordStream leveraged both of these capabilities as part of their continuous delivery pipeline shown in Figure 8.
After a new model is produced, WordStream performs batched scoring and clustering on historical data. Batching is a resource efficient strategy.
However, ad campaigns generate new data between model re-training, and WordStream’s clients needed the ability to analyze fresh data. Thus, WordStream also deployed hosted endpoints to support real-time inference.
The model versioning and A/B testing functionality on hosted endpoints allows new models to be deployed without disruption, and mitigates the risk of a new model variant that performs poorly in production.
Production systems are often complex and involve communication across many internal and external systems. API management plays an important role in managing this complexity and scale.
WordStream fronted their hosted endpoints with custom APIs managed by Amazon API Gateway. Among the benefits are edge caching for improving inference latency, throttling for managing resource quotas on dependent systems, and canary release for further mitigating the risk of production changes.
You can also consider the option of integrating the hosted endpoints with Amazon Aurora and Amazon Athena for ML query capability. This would enable a data-centric application to blend data and predictions using standard SQL, and reduce data movement and pipelining work.
By the end of the deployment stage, your infrastructure should be optimized. For instance, Amazon SageMaker P and G family instances offer GPU acceleration and are effective for decreasing training time and inference latency on deep learning workloads.
You should also deploy your hosted endpoints on two or more instances to maintain high availability across multiple AWS Availability Zones.
By providing reliability and performance, you’ll ensure a positive customer experience.
Also, keep a checklist of cost optimization opportunities. Evaluate elastic inference to cost-optimize GPU inference workloads, Spot instances for lowering training costs, and multi-model endpoints and automatic scaling for improving resource utilization.
6. Continuous Improvement
The following figure presents the complete solution and the components for maintaining a positive customer experience. This includes production monitoring and human-in-the-loop (HITL) processes that drive continuous improvement.
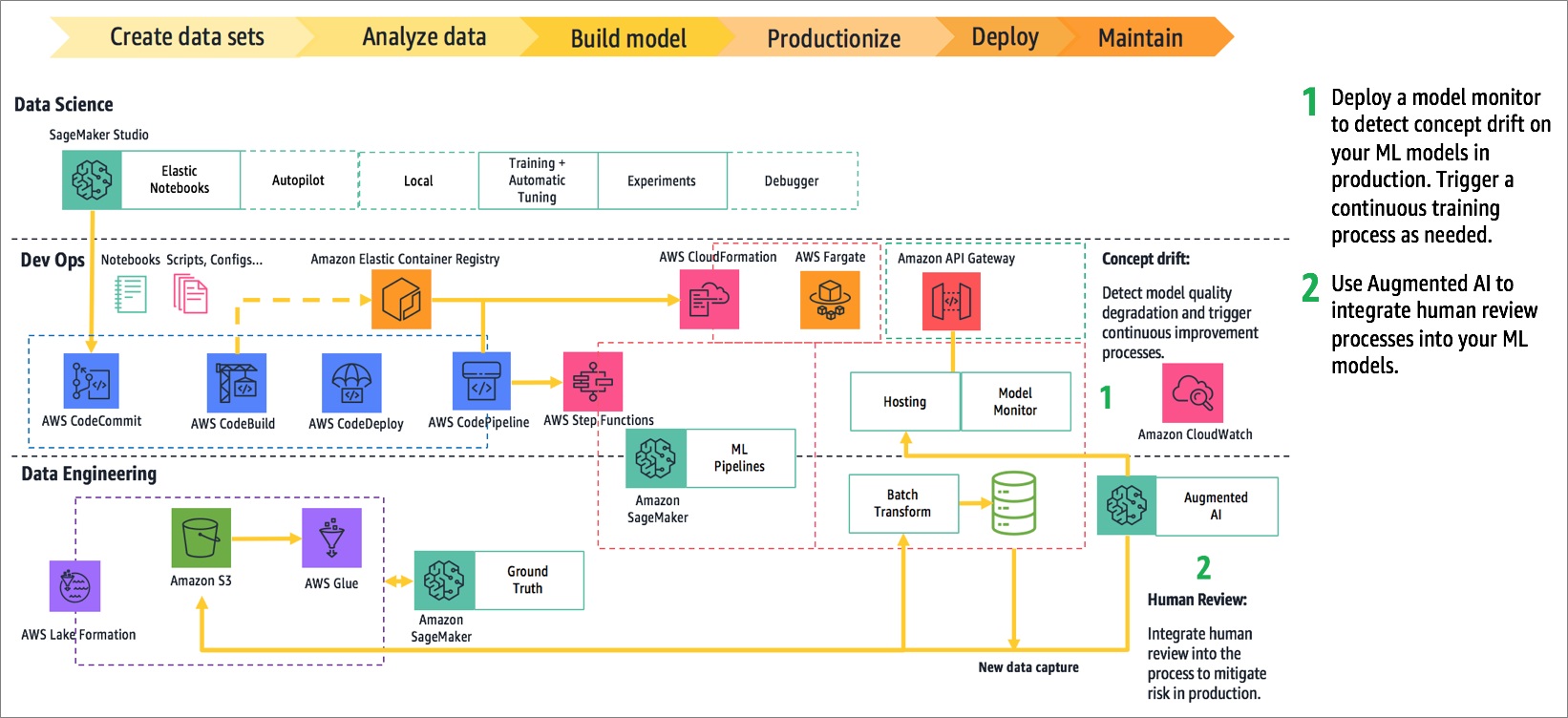
Figure 9 – The complete solution.
Model monitoring in production is important to detect issues like performance degradation. Consider a product recommendation model—as consumer taste changes and seasonality effects shift, model performance can degrade. You should put mechanisms in place to detect this drift and determine whether the model needs to be retrained.
One of those mechanisms is Amazon SageMaker Model Monitor, which automates concept drift detection on an Amazon SageMaker-hosted model. Model Monitor provides a default monitor that can be applied generically for data drift detection.
You can also implement custom monitoring jobs. A custom monitor might leverage newly-acquired Amazon SageMaker Ground Truth data to detect performance decay or leverage XAI tools to give you better insights into any detected changes.
You can also deploy Amazon Augmented AI (AAI) to bring HITL into the process. Human review in machine learning is important for supporting sensitive use cases like loan approval automation. In such use cases, low confidence predictions should be set aside for human review, as poor predictions can have costly legal implications.
Consider an ML use case for marketing involving Natural Language Generation (NLG) to automatically copy-write email and ad campaigns. An effective NLG model can craft messaging that beat humans on user engagement metrics.
However, there are associated risks. A model could inadvertently generate offensive text. You could de-risk this scenario by using a content moderation model to produce a sensitivity score on the generated content. If the score exceeds a certain threshold, AAI could trigger a human review process for copyediting.
Conclusion
Taking your data science organization from the lab to production isn’t an overnight journey. However, organizations like WordStream are poised to offer customers a differentiated experience.
Successful organizations often adopt an evolutionary strategy that generates wins along the way and builds on success. They also value experience and expertise, and like WordStream, collaborate with AWS partners such as Slalom to accelerate that success.
By unifying their data science and DevOps operations, Slalom helped WordStream transition their machine learning efforts directly from experimentation to production.
A well-architected system for productionizing ML enables WordStream to deliver AI-driven insights for online advertising through a process that ensures a consistent standard of quality, reliability, and agility. Learn more about a free trial of WordStream.
.

.
Slalom – APN Partner Spotlight
Slalom is an AWS Premier Consulting Partner. A modern consulting firm focused on strategy, technology, and business transformation, Slalom’s teams are backed by regional innovation hubs, a global culture of collaboration, and partnerships with the world’s top technology providers.
Contact Slalom | Practice Overview
*Already worked with Slalom? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.