AWS Big Data Blog
Category: AWS Glue

Migrate your existing SQL-based ETL workload to an AWS serverless ETL infrastructure using AWS Glue
Data has become an integral part of most companies, and the complexity of data processing is increasing rapidly with the exponential growth in the amount and variety of data. Data engineering teams are faced with the following challenges: Manipulating data to make it consumable by business users Building and improving extract, transform, and load (ETL) […]

Simplify external object access in Amazon Redshift using automatic mounting of the AWS Glue Data Catalog
November 2024: This post was reviewed and updated for accuracy. Amazon Redshift is a petabyte-scale, enterprise-grade cloud data warehouse service delivering the best price-performance. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift to cost-effectively and quickly analyze their data using standard SQL and existing business intelligence (BI) tools. Amazon Redshift now […]

Use AWS Glue DataBrew recipes in your AWS Glue Studio visual ETL jobs
AWS Glue Studio is now integrated with AWS Glue DataBrew. AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. DataBrew is a visual data preparation tool that enables you to clean and normalize data without writing any code. The […]

End-to-end development lifecycle for data engineers to build a data integration pipeline using AWS Glue
Data is a key enabler for your business. Many AWS customers have integrated their data across multiple data sources using AWS Glue, a serverless data integration service, in order to make data-driven business decisions. To grow the power of data at scale for the long term, it’s highly recommended to design an end-to-end development lifecycle […]

Build data integration jobs with AI companion on AWS Glue Studio notebook powered by Amazon CodeWhisperer
Data is essential for businesses to make informed decisions, improve operations, and innovate. Integrating data from different sources can be a complex and time-consuming process. AWS offers AWS Glue to help you integrate your data from multiple sources on serverless infrastructure for analysis, machine learning (ML), and application development. AWS Glue provides different authoring experiences […]

Migrate data from Google Cloud Storage to Amazon S3 using AWS Glue
Today, we are pleased to announce a new AWS Glue connector for Google Cloud Storage that allows you to move data bi-directionally between Google Cloud Storage and Amazon Simple Storage Service (Amazon S3). In this post, we go over how the new connector works, introduce the connector’s functions, and provide you with key steps to set it up. We provide you with prerequisites, share how to subscribe to this connector in AWS Marketplace, and describe how to create and run AWS Glue for Apache Spark jobs with it.

How AWS helped Altron Group accelerate their vision for optimized customer engagement
This is a guest post co-authored by Jacques Steyn, Senior Manager Professional Services at Altron Group. Altron is a pioneer of providing data-driven solutions for their customers by combining technical expertise with in-depth customer understanding to provide highly differentiated technology solutions. Alongside their partner AWS, they participated in AWS Data-Driven Everything (D2E) workshops and a […]

Extract time series from satellite weather data with AWS Lambda
Extracting time series on given geographical coordinates from satellite or Numerical Weather Prediction data can be challenging because of the volume of data and of its multidimensional nature (time, latitude, longitude, height, multiple parameters). This type of processing can be found in weather and climate research, but also in applications like photovoltaic and wind power. […]

Harmonize data using AWS Glue and AWS Lake Formation FindMatches ML to build a customer 360 view
In today’s digital world, data is generated by a large number of disparate sources and growing at an exponential rate. Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their data lake to derive […]
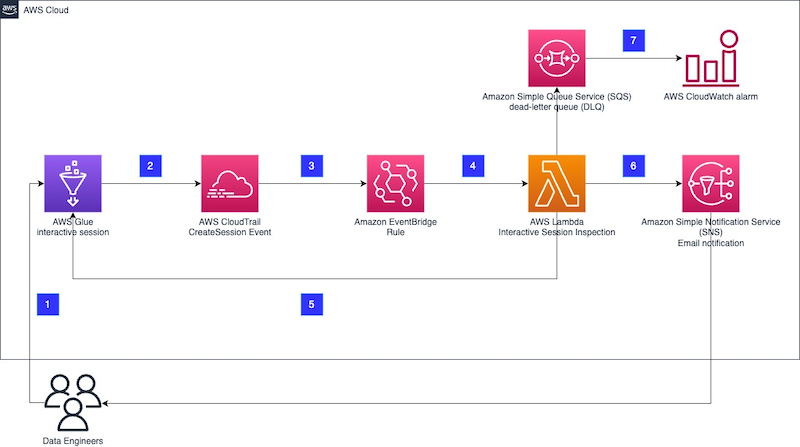
Enforce boundaries on AWS Glue interactive sessions
AWS Glue interactive sessions allow engineers to build, test, and run data preparation and analytics workloads in an interactive notebook. Interactive sessions provide isolated development environments, take care of the underlying compute cluster, and allow for configuration to stop idling resources. Glue interactive sessions provides default recommended configurations, and also allows users to customize the […]