Artificial Intelligence
How Cepsa used Amazon SageMaker and AWS Step Functions to industrialize their ML projects and operate their models at scale
This blog post is co-authored by Guillermo Ribeiro, Sr. Data Scientist at Cepsa.
Machine learning (ML) has rapidly evolved from being a fashionable trend emerging from academic environments and innovation departments to becoming a key means to deliver value across businesses in every industry. This transition from experiments in laboratories to solving real-world problems in production environments goes hand in hand with MLOps, or the adaptation of DevOps to the ML world.
MLOps helps streamline and automate the full lifecycle of an ML model, putting its focus on the source datasets, experiment reproducibility, ML algorithm code, and model quality.
At Cepsa, a global energy company, we use ML to tackle complex problems across our lines of businesses, from doing predictive maintenance for industrial equipment to monitoring and improving petrochemical processes at our refineries.
In this post, we discuss how we built our reference architecture for MLOps using the following key AWS services:
- Amazon SageMaker, a service to build, train, and deploy ML models
- AWS Step Functions, a serverless low-code visual workflow service used to orchestrate and automate processes
- Amazon EventBridge, a serverless event bus
- AWS Lambda, a serverless compute service that allows you to run code without provisioning or managing servers
We also explain how we applied this reference architecture to bootstrap new ML projects in our company.
The challenge
During the last 4 years, multiple lines of business across Cepsa kicked off ML projects, but soon certain issues and limitations started to arise.
We didn’t have a reference architecture for ML, so each project followed a different implementation path, performing ad hoc model training and deployment. Without a common method to handle project code and parameters and without an ML model registry or versioning system, we lost the traceability amongst datasets, code, and models.
We also detected room for improvement in the way we operated models in production, because we didn’t monitor deployed models and therefore didn’t have the means to track model performance. As a consequence, we usually retrained models based on time schedules, because we lacked the right metrics to make informed retraining decisions.
The solution
Starting from the challenges we had to overcome, we designed a general solution that aimed to decouple data preparation, model training, inference, and model monitoring, and featured a centralized model registry. This way, we simplified managing environments across multiple AWS accounts, while introducing centralized model traceability.
Our data scientists and developers use AWS Cloud9 (a cloud IDE for writing, running, and debugging code) for data wrangling and ML experimentation and GitHub as the Git code repository.
An automatic training workflow uses the code built by the data science team to train models on SageMaker and to register output models in the model registry.
A different workflow manages model deployment: it obtains the reference from the model registry and creates an inference endpoint using SageMaker model hosting features.
We implemented both model training and deployment workflows using Step Functions, because it provided a flexible framework that enables the creation of specific workflows for each project and orchestrates different AWS services and components in a straightforward way.
Data consumption model
In Cepsa, we use a series of data lakes to cover diverse business needs, and all these data lakes share a common data consumption model that makes it easier for data engineers and data scientists to find and consume the data they need.
To easily handle costs and responsibilities, data lake environments are completely separated from data producer and consumer applications, and deployed in different AWS accounts belonging to a common AWS Organization.
The data used to train ML models and the data used as an inference input for trained models is made available from the different data lakes through a set of well-defined APIs using Amazon API Gateway, a service to create, publish, maintain, monitor, and secure APIs at scale. The API backend uses Amazon Athena (an interactive query service to analyze data using standard SQL) to access data that is already stored in Amazon Simple Storage Service (Amazon S3) and cataloged in the AWS Glue Data Catalog.
The following diagram provides a general overview of Cepsa’s MLOps architecture.

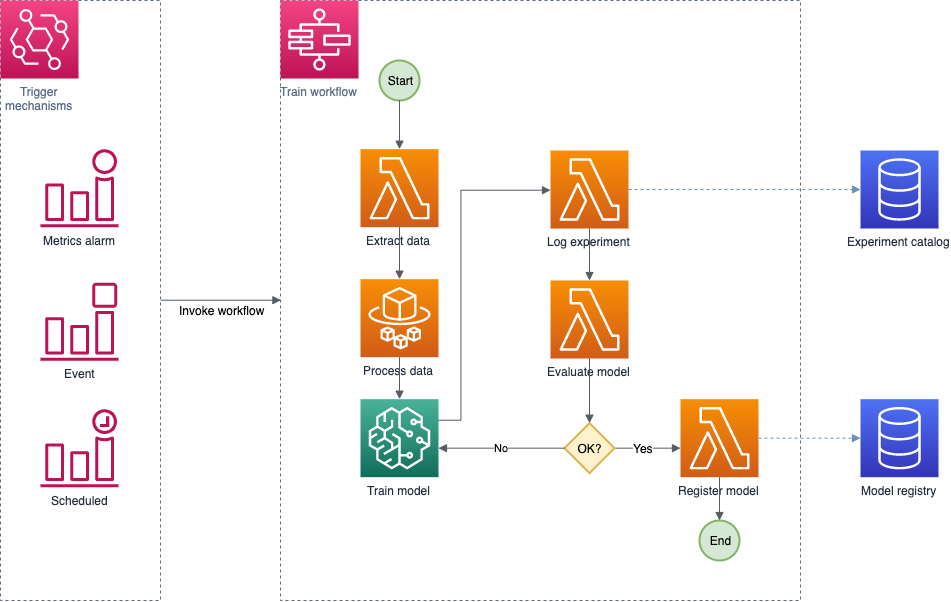
Model training
The training process is independent for each model and handled by a Step Functions standard workflow, which gives us flexibility to model processes based on different project requirements. We have a defined a base template that we reuse on most projects, performing minor adjustments when required. For example, some project owners have decided to add manual gates to approve deployments of new production models, while other project owners have implemented their own error detection and retry mechanisms.
We also perform transformations on the input datasets used for model training. For this purpose, we use Lambda functions that are integrated in the training workflows. In some scenarios where more complex data transformations are required, we run our code in Amazon Elastic Container Service (Amazon ECS) on AWS Fargate, a serverless compute engine to run containers.
Our data science team uses custom algorithms frequently, so we take advantage of the ability to use custom containers in SageMaker model training, relying on Amazon Elastic Container Registry (Amazon ECR), a fully managed container registry that makes it easy to store, manage, share, and deploy container images.
Most of our ML projects are based on the Scikit-learn library, so we have extended the standard SageMaker Scikit-learn container to include the environment variables required for the project, such as the Git repository information and deployment options.
With this approach, our data scientists just need to focus on developing the training algorithm and to specify the libraries required by the project. When they push code changes to the Git repository, our CI/CD system (Jenkins hosted on AWS) builds the container with the training code and libraries. This container is pushed to Amazon ECR and finally passed as a parameter to the SageMaker training invocation.
When the training process is complete, the resulting model is stored in Amazon S3, a reference is added in the model registry, and all the collected information and metrics are saved in the experiments catalog. This assures full reproducibility because the algorithm code and libraries are linked to the trained model along with the data associated to the experiment.
The following diagram illustrates the model training and retraining process.
Model deployment
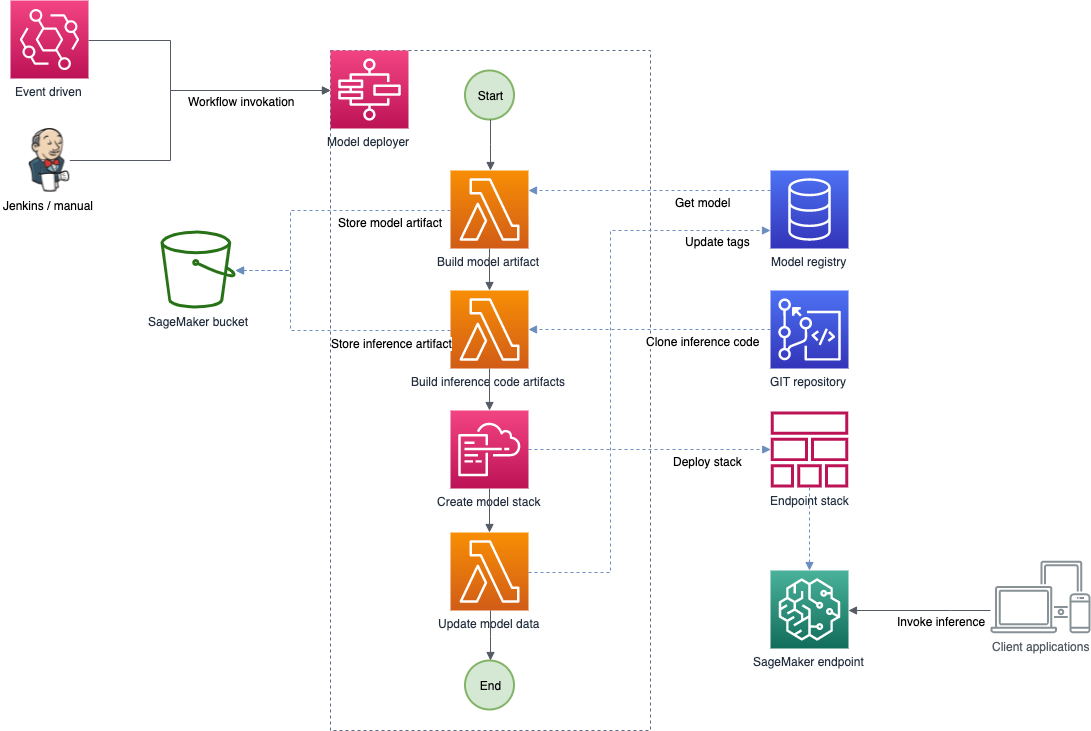
The architecture is flexible and allows both automatic and manual deployments of the trained models. The model deployer workflow is automatically invoked by means of an event that SageMaker training publishes in EventBridge after training has finished, but it can also be manually invoked if needed, passing the right model version from the model registry. For more information about automatic invocation, see Automating Amazon SageMaker with Amazon EventBridge.
The model deployer workflow retrieves the model information from the model registry and uses AWS CloudFormation, a managed infrastructure as code service, to either deploy the model to a real-time inference endpoint or perform batch inference with a stored input dataset, depending on the project requirements.
Whenever a model is successfully deployed in any environment, the model registry is updated with a new tag indicating on which environments the model is currently running. Any time an endpoint is removed, its tag is also deleted from the model registry.
The following diagram shows the workflow for model deployment and inference.
Experiments and model registry
Storing every experiment and model version in a single location and having a centralized code repository enables us to decouple model training and deployment and to use different AWS accounts for every project and environment.
All experiment entries store the commit ID of the training and inference code, so we have complete traceability of the whole experimentation process and are able to easily compare different experiments. This prevents us from performing duplicate work on the scientific exploration phase for algorithms and models, and enables us to deploy our models anywhere, independently from the account and environment where the model was trained. This also holds true for models trained in our AWS Cloud9 experimentation environment.
All in all, we have fully automated model training and deployment pipelines and have the flexibility to perform fast manual model deployments when something isn’t working properly or when a team needs a model deployed to a different environment for experimentation purposes.
A detailed use case: YET Dragon project
The YET Dragon project aims to improve the production performance of Cepsa’s petrochemical plant in Shanghai. To achieve this goal, we studied the production process thoroughly, looking for the less efficient steps. Our target was to increase the yield efficiency of the processes by keeping component concentration exactly below a threshold.
To simulate this process, we built four generalized additive models or GAM, linear models whose response depends on smooth functions of predictor variables, to predict the results of two oxidation processes, one concentration process, and the aforementioned yield. We also built an optimizer to process the results of the four GAM models and find the best optimizations that could be applied in the plant.
Although our models are trained with historical data, the plant can sometimes operate under circumstances that weren’t registered in the training dataset; we expect that our simulation models won’t work well under those scenarios so we also built two anomaly detection models using Isolation Forests algorithms, which determine how far are data points to the rest of the data to detect the anomalies. These models help us detect such situations to disable the automated optimization processes whenever this happens.
Industrial chemical processes are highly variable and the ML models need to be well aligned with the plant operation, so frequent retraining is required as well as traceability of the models deployed in each situation. YET Dragon was our first ML optimization project to feature a model registry, full reproducibility of the experiments, and a fully managed automated training process.
Now, the complete pipeline that brings a model into production (data transformation, model training, experiment tracking, model registry, and model deployment) is independent for each ML model. This enables us to improve models iteratively (for example adding new variables or testing new algorithms) and to connect the training and deployment stages to different triggers.
The results and future improvements
We are currently able to automatically train, deploy, and track the six ML models used in the YET Dragon project, and we have already deployed over 30 versions for each of the production models. This MLOps architecture has been extended to hundreds of ML models in other projects across the company.
We plan to keep launching new YET projects based on this architecture, which has decreased project mean duration by 25%, thanks to the reduction of bootstrapping time and the automation of ML pipelines. We have also estimated savings of around €300,000 per year thanks to the increase in yield and concentration that is a direct result of the YET Dragon project.
The short-term evolution of this MLOps architecture is towards model monitoring and automated testing. We plan to automatically test model efficiency against previously deployed models before a new model is deployed. We’re also working in the implementation of model monitoring and inference data drift monitoring with Amazon SageMaker Model Monitor, in order to automate model retraining.
Conclusion
Companies are facing the challenge of bringing their ML projects to production in an automated and efficient manner. Automating the full ML model lifecycle helps reduce project times and ensures better model quality and faster and more frequent deployments to production.
By developing a standardized MLOps architecture that has been adopted by different business across the company, we at Cepsa were able to speed up ML project bootstrapping and to improve ML model quality, providing a reliable and automated framework upon which our data science teams can innovate faster.
For more information about MLOps on SageMaker, visit Amazon SageMaker for MLOps and check out other customer use cases in the AWS Machine Learning Blog.
About the authors
 Guillermo Ribeiro Jiménez is a Sr Data Scientist at Cepsa with a PhD. in Nuclear Physics. He has 6 years of experience with data science projects, mainly in the telco and energy industry. He is currently leading data scientist teams in Cepsa’s Digital Transformation department, with a focus on the scaling and productization of machine learning projects.
Guillermo Ribeiro Jiménez is a Sr Data Scientist at Cepsa with a PhD. in Nuclear Physics. He has 6 years of experience with data science projects, mainly in the telco and energy industry. He is currently leading data scientist teams in Cepsa’s Digital Transformation department, with a focus on the scaling and productization of machine learning projects.
 Guillermo Menéndez Corral is a Solutions Architect at AWS Energy and Utilities. He has over 15 years of experience designing and building SW applications, and currently provides architectural guidance to AWS customers in the energy industry, with a focus on analytics and machine learning.
Guillermo Menéndez Corral is a Solutions Architect at AWS Energy and Utilities. He has over 15 years of experience designing and building SW applications, and currently provides architectural guidance to AWS customers in the energy industry, with a focus on analytics and machine learning.