Amazon Web Services ブログ
Category: Database

AWS Weekly Roundup: Amazon DocumentDB、AWS Lambda、Amazon EC2 など (2025 年 8 月 4 日)
8 月 4 日週は、生成 AI 機能から基盤サービスの強化まで、さまざまなイノベーションをご紹介します。これら […]

Amazon DocumentDB サーバーレスが利用可能になりました
7 月 31 日、Amazon DocumentDB サーバーレスの一般提供についてお知らせします。これは A […]
AWS サーバレスサービスで実現するラーメン山岡家のキッチンオペレーション効率化
本ブログ記事は、株式会社丸千代山岡家様と AWS Japan が共同執筆したブログです。AWS Summit Japan 2025 での展示内容をもとに、従来の厨房タイマー装置が抱えていた視認性の問題や熟練職人への依存といった課題を、AWS Fargate や Amazon ElastiCache Serverless 、Amazon Bedrock などのサーバレスサービスを活用してどのように解決したかを詳しく解説しています。記事では、導入によりスタッフのスキル習得期間が 500 日から 350 日に短縮され、提供時間も平均 30 秒削減されるなど、具体的な成果を示しながら、外食産業におけるデジタルトランスフォーメーションの実践例として紹介しました。
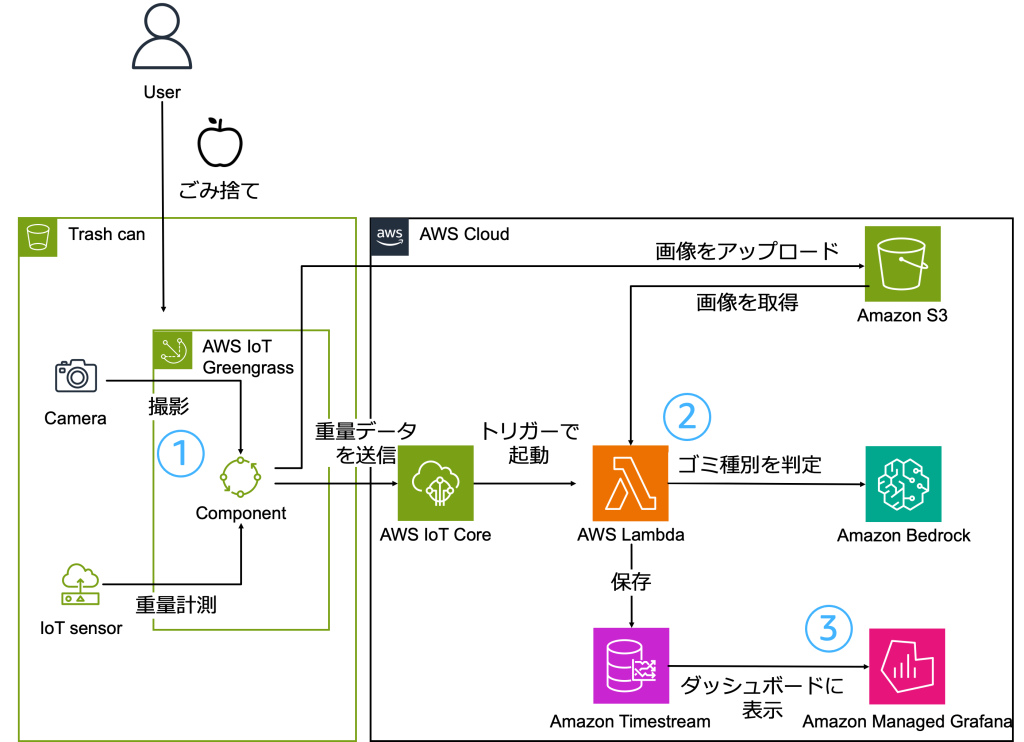
AWS Summit Japan 2025 で次世代のフードマネジメントに挑戦! AI と IoT で実現する スマート廃棄物管理
2025 年 6 月 26 日に AWS Summit Japan 2025 の AWS Builders’ Fair にて、カメラと重量センサーを活用した新しいスマート廃棄物管理ソリューションを展示しました。これは、過去に AWS Blog で紹介されたソリューションを基に、日本の食品を取り扱う企業が直面する課題に合わせて改良を加えたものです。
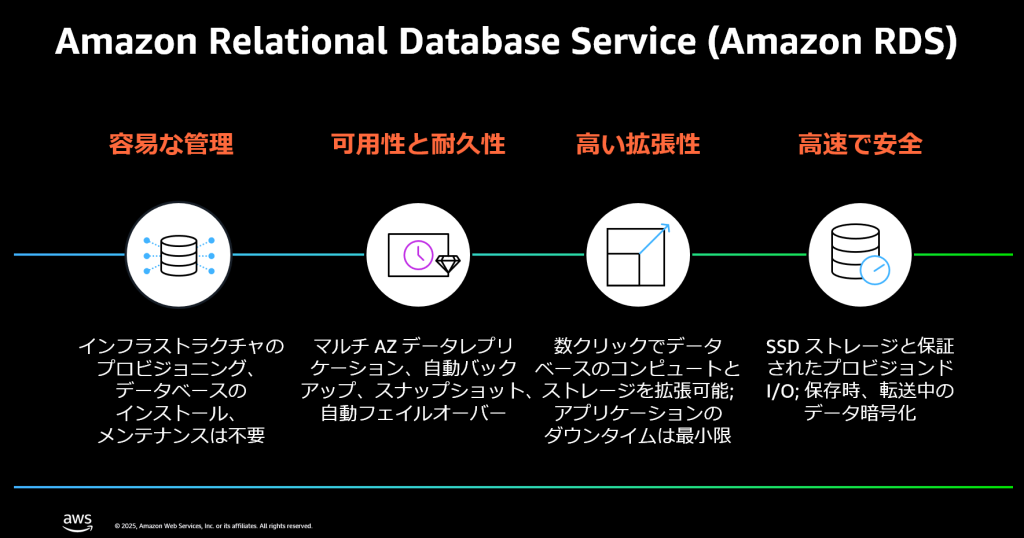
【配信開始】商用データベース(Oracle, SQL Server, Db2)を AWS 上で活用するための Web セミナー
2025 年 7 月 17 日に「商用データベースを AWS で活用する」と題したイベントを開催し、オンプレミス等の環境に商用データベース ( Oracle, SQL Server, IBM Db2 )をご利用の方向けに、最初に AWS を利用するメリットとや各商用データベースを AWS 上で稼働させる際のサービス選択のポイントや注意点について説明しました。現在、オンデマンドで視聴が可能です。
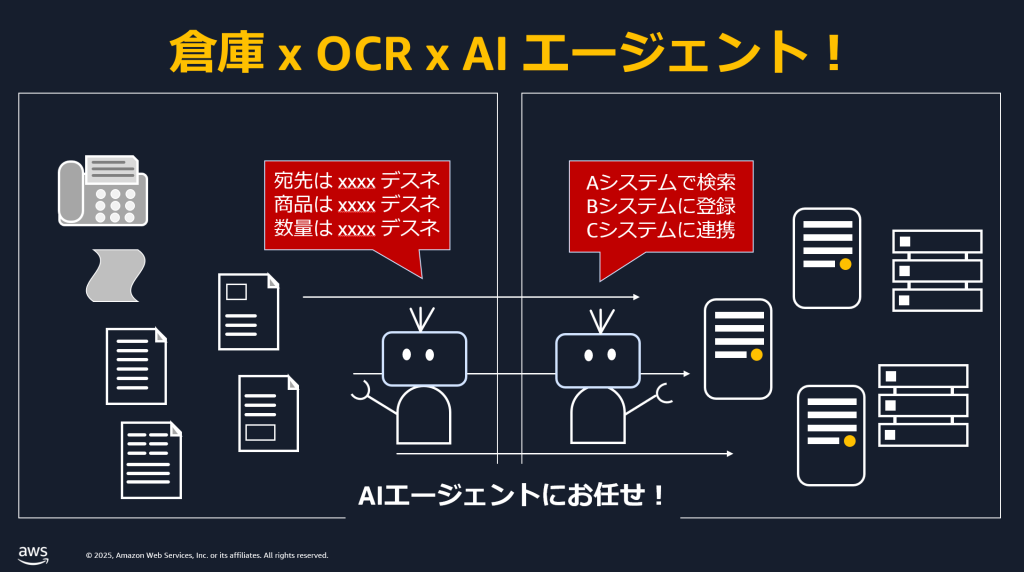
【開催報告】AWS Summit Japan 2025 物流業界向けブース展示 「倉庫 x OCR x 生成 AI エージェント」
6月 24 日と 25 日の 2 日間にわたり、幕張メッセにおいて 14 回目となる AWS Summit J […]

AWS Weekly Roundup: AWS Builder Center、Amazon Q、Oracle Database@AWS など (2025 年 7 月 14 日)
ここ、英国にも夏がやってきました! でも私は夏がちょっと苦手です。多くの人とは違い、外出時に「輝かしい太陽」を […]

Oracle Exadata から AWS クラウドへの移行を簡素化する Oracle Database@AWS のご紹介
7 月 8 日、AWS 内で Oracle Real Application Clusters (RAC) を […]

SQL から NoSQL へ : Amazon DynamoDB でのデータモデリング
本記事は 2025/07/03に投稿された SQL to NoSQL: Modeling data in Am […]
SQL から NoSQL へ : Amazon DynamoDB へのアプリケーション移行の計画
本記事は 2025/07/03に投稿された SQL to NoSQL: Planning your appli […]