AWS for Industries
Retail demand forecasting using AWS
Retailers use demand forecasting to anticipate customer needs and optimize supply decisions. Like most industries, demand forecasting in retail industry uses large amounts of historical data to predict future consumer demand. These forecasts depend upon analyses of variables that impact demand, such as seasonality, promotions, inventory levels, and market trends. Prediction accuracy is influenced by the model complexity and ability of the model to handle large data volume.
The use of machine learning (ML) has been shown to improve forecasting accuracy because of the large size and variety of retail data that ML can handle, and it also helps address these challenges that are inherent in retail data.
Many retailers are interested in implementing ML-forecasting techniques to improve demand forecasting accuracy. Using an iterative process of ML for demand forecasting can help customers reduce inventory cost and increase revenue. ML reduces an item’s price by optimizing inventory and supply chain operations.
However, there are challenges with adopting ML-based demand forecasting for retailers. These include poor data source and quality, extensive time and resources needed for model tuning, lack of data science expertise, and other organizational and technical challenges.
Amazon Web Services (AWS) offers one of the most comprehensive suite of services that can handle the full lifecycle of an ML project, from data ingestion to complex modeling to deployment and inference at scale. The retail landscape is changing, and with more data points available than ever before, demand forecasting has become the de facto standard. This blog will talk about how retailers can perform demand forecasting with AWS services.
Reference architecture
Demand forecasting is a multistage process, with each step having unique objectives. The diagram below breaks down the lifecycle into eight distinctive phases, covering everything from data ingestion to model deployment.
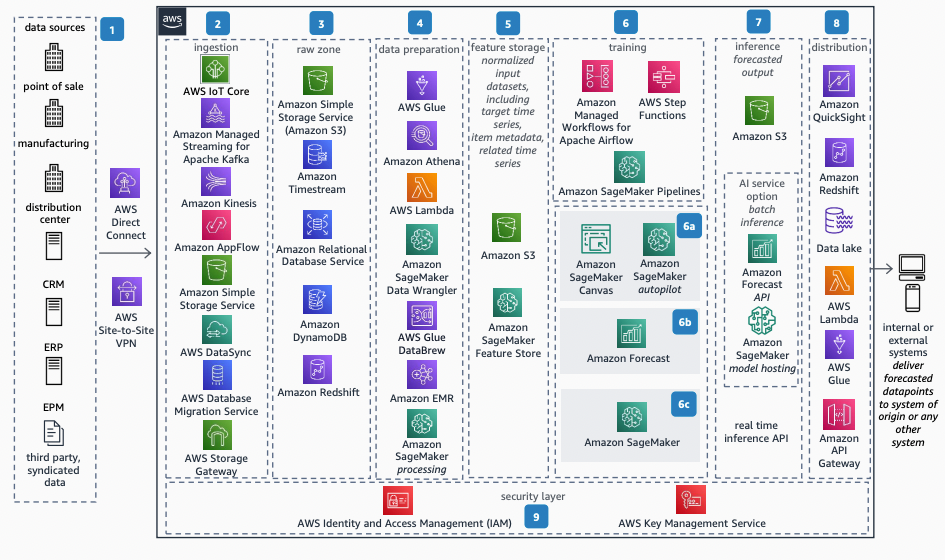
Each phase has a distinctive part in the entire process. Let’s have a closer look at them.
Description of architecture
1. Data source
Forecasting depends heavily on reliable sources of both historical and current data. These sources can come in various formats (json, XML, structured logs, and others) and from a variety of sources, including retail stores, manufacturing and distribution centers, customer relationship management (CRM), enterprise resource planning (ERP), enterprise performance management (EPM), and third-party systems such as product vendors and logistic partners. When data is generated by events in the cloud, various connectivity options between end points exist. In hybrid environments, there are options to connect on-premises infrastructure with the cloud using AWS Direct Connect, which customers can use to create a dedicated network connection to AWS; AWS Site-to-Site VPN, a fully managed service that creates a secure connection between your data center or branch office and your AWS resources; or direct, secure transfer through the internet.
Input data consists of
- time-series data—historical time-series data for the retail demand-forecasting use case could include item_id, timestamp, and the target field demand (sales history).
- related time-series dataset—a related time-series dataset includes time-series data that isn’t included in a target time-series dataset and might improve the accuracy of a user’s predictor (for example, promotions, working days, hours, items’ availability, and more).
- item metadata—this includes categorical data that provides valuable context for the items in a target time-series dataset (for example, color, category, and more).
- miscellaneous data—this includes other data, like geolocation, time zone, or others; third-party information, like market analysis trends, can also be included.
2. Data ingestion
Depending on the retailer’s needs, the AWS Cloud offers multiple services that help ingest data in batch or near real time. Amazon Kinesis, which makes it easy to collect, process, and analyze near-real-time, streaming data, is an example of a service that’s suitable for streaming data, and AWS IoT Core, which lets users connect billions of Internet of Things (IoT) devices and route trillions of messages to AWS services, is better suited for IoT devices. Customers can use AWS Database Migration Service (AWS DMS), a managed migration and replication service, to fetch data from existing databases. Customers can also use AWS DataSync, which simplifies and accelerates secure data migrations, and AWS Storage Gateway, a set of hybrid cloud-storage services, for transfers from on-premises environments. Optionally, customers can upload data into Amazon Simple Storage Service (Amazon S3), an object storage service, using the Amazon S3 command line interface (CLI) commands, API, or console. Customers can also use Amazon AppFlow, a fully managed integration service, for SAP and Salesforce.
3. Raw zone
Data that is ingested can be stored in an intermediate staging-and-landing area or raw zone. Data stores like
- Amazon S3;
- Amazon Timestream, a fast, scalable, and serverless time-series database service;
- Amazon Relational Database Service (Amazon RDS), a collection of managed services;
- Amazon DynamoDB, a fully managed, serverless, key-value NoSQL database; and
- Amazon Redshift, which uses SQL to analyze structured and semistructured data
provide a raw zone for historical and near-real-time time-series data, item metadata, and related time-series data. Customers can use their data lake as a raw zone.
4. Data preparation
Data preparation, or data preprocessing, is the process of transforming raw data so that data scientists and analysts can run it through ML algorithms to uncover insights or make predictions. During this stage, scientists and analysts can select and query data from various sources, cleanse and explore it, check it for outliers and statistical bias, visualize it, analyze the data to identify feature importance, perform feature engineering, and finally export the data in a form that can be used for ML models. In this tier, Amazon SageMaker Data Wrangler, a fast and easy way to prepare data for ML, is a low-code/no-code option. With the Amazon SageMaker Data Wrangler data selection service, users can quickly select data from multiple data sources, such as Amazon S3; Amazon Athena, which analyzes petabyte-scale data; Amazon Redshift; AWS Lake Formation, which lets users easily create secure data lakes; or solutions from AWS Partners Snowflake and Databricks.
Then, users can transform the data by using over 300 preconfigured data transformations and explore and visualize the data. Another low-code option is AWS Glue DataBrew, which provides a visual data preparation tool that can help clean and normalize data to prepare for ML. Advanced customers can use Amazon EMR, a cloud big data solution for petabyte-scale data processing, and Amazon SageMaker—to build, train, and deploy ML models—for processing jobs, which are advanced options for data transformation and feature engineering. AWS Glue, a serverless data integration service, can also be used to filter, aggregate, and reshape data. If data resides in multiple relational and nonrelational data sources, then Amazon Athena can be used to perform federated queries on multiple relational, nonrelational, object, and custom data sources. AWS Lambda, a serverless, event-driven compute service, can be used for data transformation.
5. Feature storage
The data in its final form is now ready to be consumed by ML models. It is placed into a special dataset on Amazon S3 or Amazon SageMaker Feature Store, a fully managed, purpose-built repository to store, share, and manage features for ML models. Features are inputs to ML models used during training and inference. Features are used repeatedly by multiple teams, and feature quality is critical for a highly accurate model. Also, when features used to train models offline in batch are made available for near-real-time inference, it’s hard to keep the two feature stores synchronized. Amazon SageMaker Feature Store provides a secure and unified store for feature use across the ML lifecycle.
6. Training and hyperparameter tuning
Depending on the customer’s use case, task force, skill set, and time and accuracy requirements, customers can pick various options from AWS. There are three major approaches that customers could take to the model training process. These will be discussed in detail in the “Approach” section, followed by practical examples.
MLOps and orchestration are key parts of any ML process. Customers can use
- AWS Step Functions, a visual workflow service that helps developers use AWS services;
- Amazon Managed Workflows for Apache Airflow (Amazon MWAA), which orchestrates workflows using Directed Acyclic Graphs (DAGs); or
- Amazon SageMaker Pipeline, a purpose-built continuous integration continuous delivery service for ML
to help orchestrate the complete ML process.
7. Inference
You have a model that can now be deployed for an ML inference to predict the forecast. You could now select batch inference for asynchronous forecasting or a near-real-time option that uses an API. Batch inference places the forecast results in Amazon S3 as a comma separated values (CSV) file. This CSV file can be exported and consumed by internal and external systems. Batch inference is a cost-effective inference mechanism where latency can be tolerated. Amazon SageMaker offers batch transform. Additionally, in Amazon Forecast, a time-series forecasting service, you can create a forecast with the Amazon Forecast Console, AWS CLI, or AWS SDKs and export it to an Amazon S3 bucket.
Near-real-time inference is ideal for inference workloads where users have near-real-time, interactive, low-latency requirements. You can deploy a model to Amazon SageMaker hosting options and get an end point that can be used for inference. These end points are fully managed and support autoscaling (see Automatically Scale Amazon SageMaker Models). Another option is Amazon SageMaker Serverless Inference, which is a purpose-built inference option that makes it easy for users to deploy and scale ML models. Serverless Inference is ideal for workloads that have idle periods between traffic spurts and can tolerate cold starts. Serverless end points automatically launch compute resources and scale them in and out depending on traffic, eliminating the need to choose instance types or manage scaling policies. This diminishes the undifferentiated heavy lifting of selecting and managing servers. Serverless Inference integrates with AWS Lambda to offer high availability, built-in fault tolerance, and automatic scaling. For asynchronous inference, where large payload size and long processing times are involved, customers can use asynchronous inference. Amazon SageMaker Asynchronous Inference is a new capability in Amazon SageMaker that queues incoming requests and processes them asynchronously.
8. Distribution
The output of the inference can be used by an organization for business intelligence, inventory planning, logistics planning, and replenishment. The forecast output can be consumed by internal applications within the organization—for example, CRM/ERP/EPM; through an API using Amazon API Gateway, a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at virtually any scale; or exported as a CSV file. Business analysts and stakeholders can view the forecast to perform business intelligence and visualization in services like Amazon QuickSight, which powers data-driven organizations with unified business intelligence (BI) at hyperscale. The forecast data can be exported and embedded into a data lake or data warehouse and can act as key data for business processes.
9. Security
Security is job zero, and users will want to facilitate security throughout the entire process. AWS recommends encryption as an additional access control to complement the identity, resource, and network-oriented access controls. AWS provides a number of features so that customers can encrypt data and manage the keys. All AWS services offer the ability to encrypt data at rest and in transit. AWS Key Management Service (AWS KMS), which lets users create, manage, and control cryptographic keys, integrates with the majority of AWS services to let customers control the lifecycle of and permissions on the keys that are used to encrypt data on the customer’s behalf. Customers can enforce and manage encryption across services integrated with AWS KMS using policy and configuration tools. AWS environments can be connected to a customer’s existing infrastructure through various means, including a virtual private network (VPN) connection over the internet, or through AWS Direct Connect. We recommend using AWS Identity and Access Management (AWS IAM) for access control. With AWS IAM, users can specify who or what can access services and resources in AWS, centrally manage fine-grained permissions, and analyze access to refine permissions across AWS. This will facilitate least privilege access.
Model training approaches
A. Low-code/no-code
With the low-code/no-code option, users can simply use Amazon SageMaker Canvas, which expands access to ML by providing business analysts with a visual point-and-click interface, or Amazon SageMaker Autopilot, which eliminates the heavy lifting of building ML models. This is the least-effort method in which very little or no knowledge of ML or development is required. Business or data analysts can use it without the need to dive into algorithm selection, evaluation, or other complexities. They can simply browse the data, select the target, and let Amazon SageMaker generate a model for them. Amazon SageMaker can also perform hyperparameter tuning based on predefined metrics. Low-code and no-code ML services address the resource constraints of demand forecasting. Customers can prepare the features to train their models in a matter of days instead of weeks.
Amazon SageMaker Autopilot automatically prepares the data, as well as builds, trains, and tunes the best ML models for the tabular datasets. It runs several algorithms on the data and tunes their hyperparameters on a fully managed compute infrastructure. Amazon SageMaker Canvas allows business analysts to generate accurate ML predictions on their own—without requiring any ML experience or writing a single line of code. A solution to use Amazon SageMaker Canvas to generate sales forecasts can be found here.
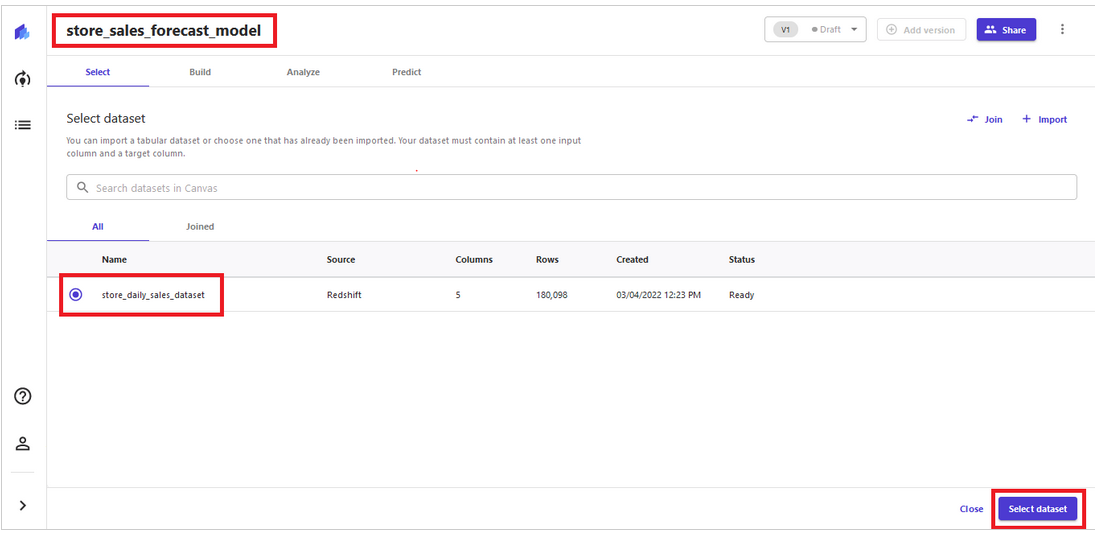
This solution uses Amazon Redshift cluster-based data with Amazon SageMaker Canvas to build ML models. Customers can also choose to directly upload local .csv files of sample datasets. The solution follows four steps (select data → build model→ analyze results → generate prediction) to build a retail forecast model (see visualization below). Sales managers and operations planners without expertise in data science and programming can use this approach to expedite decision-making, enhance productivity, and help build operational plans.
Step 1 – select data
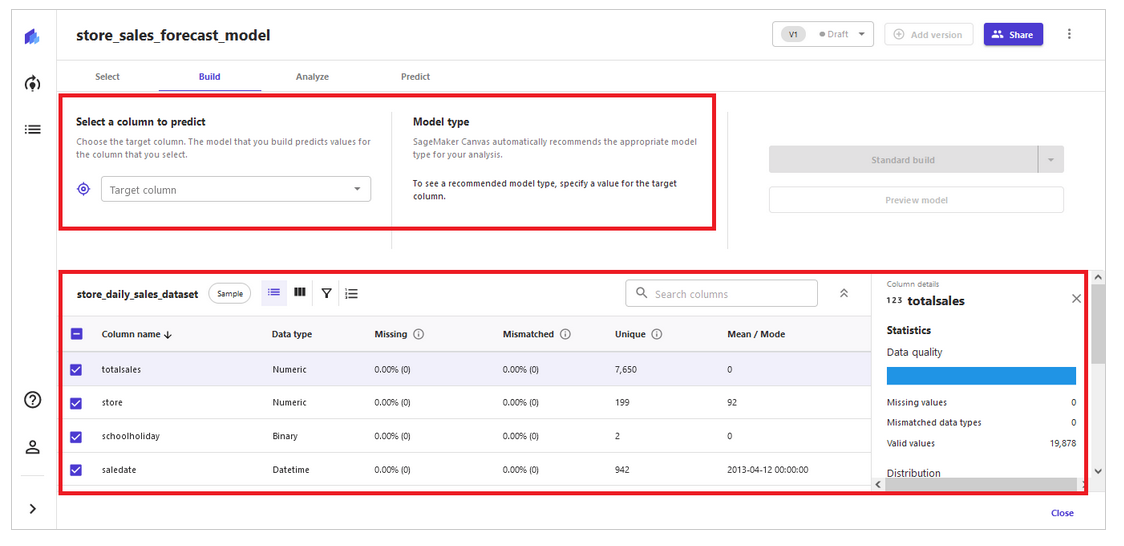
Step 2 – build model
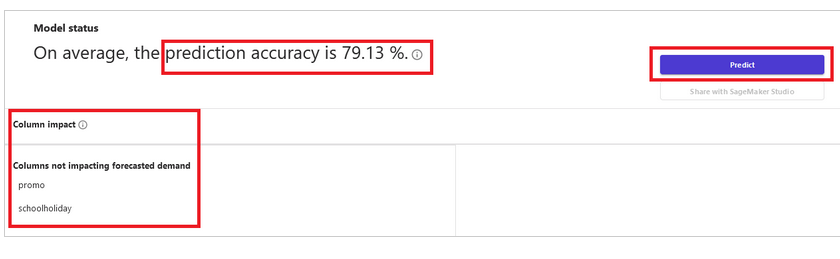
Step 3 – analyze the results
Step 4 – generate prediction
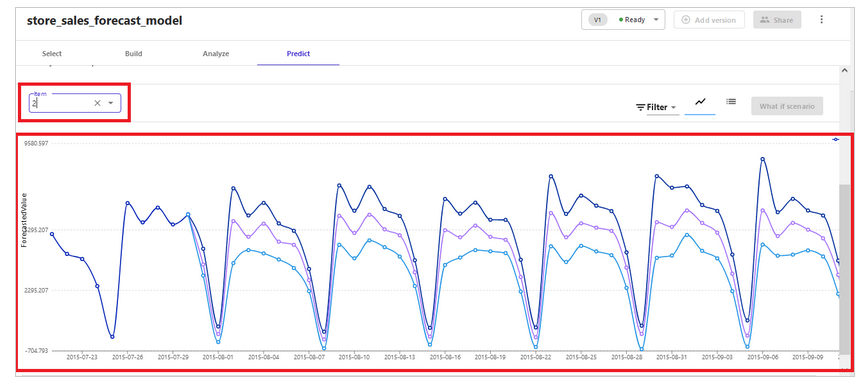
B. Amazon Forecast
Data engineers and developers can take advantage of Amazon Forecast. In this case, you supply historical time-series data (and optional datasets, like related time-series data and item metadata, if available) and ask for predictions of future metrics. Amazon Forecast creates an autopredictor that applies the optimal combination of algorithms to each time series in your datasets. You can also visualize the effect of your work as you’re weighing different options. Built from over 20 years of experience at Amazon.com, Amazon Forecast requires no knowledge of ML to use the service.
An example of a ready-to-deploy solution that adds further automation and analytical capabilities around Amazon Forecast can be found here, and an architecture diagram of the solution is shown below.
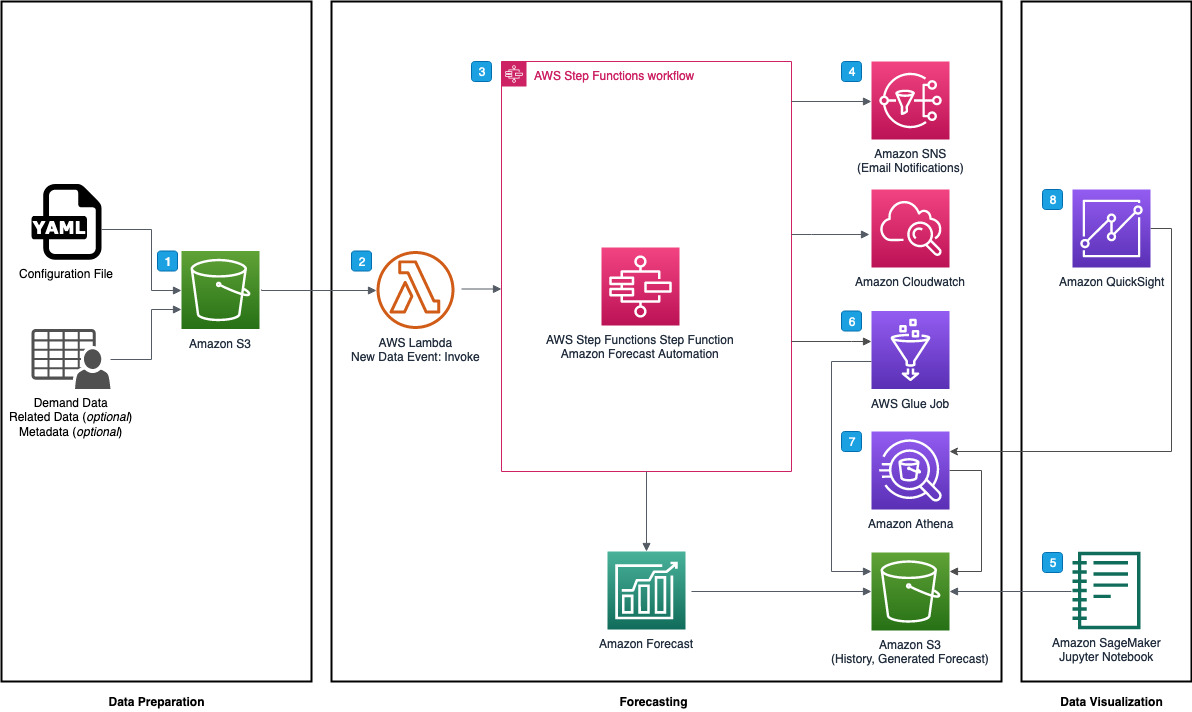
This solution supports multiple forecasts and per-forecast parameter configurations to reduce the repetitive task of generating multiple forecasts. The use of AWS Step Functions eliminates the undifferentiated heavy lifting of creating Amazon Forecast datasets, dataset groups, predictors, and forecasts, allowing developers and data scientists to focus on the accuracy of their forecasts. Amazon Forecast predictors and forecasts can be updated as item-demand data, related time-series data, and item metadata are refreshed, which allows for A/B testing against different sets of related time-series data and item metadata.
The results of your forecast can be explored directly in the AWS Console, through Amazon Athena queries, or through Amazon QuickSight dashboards included in the solution.
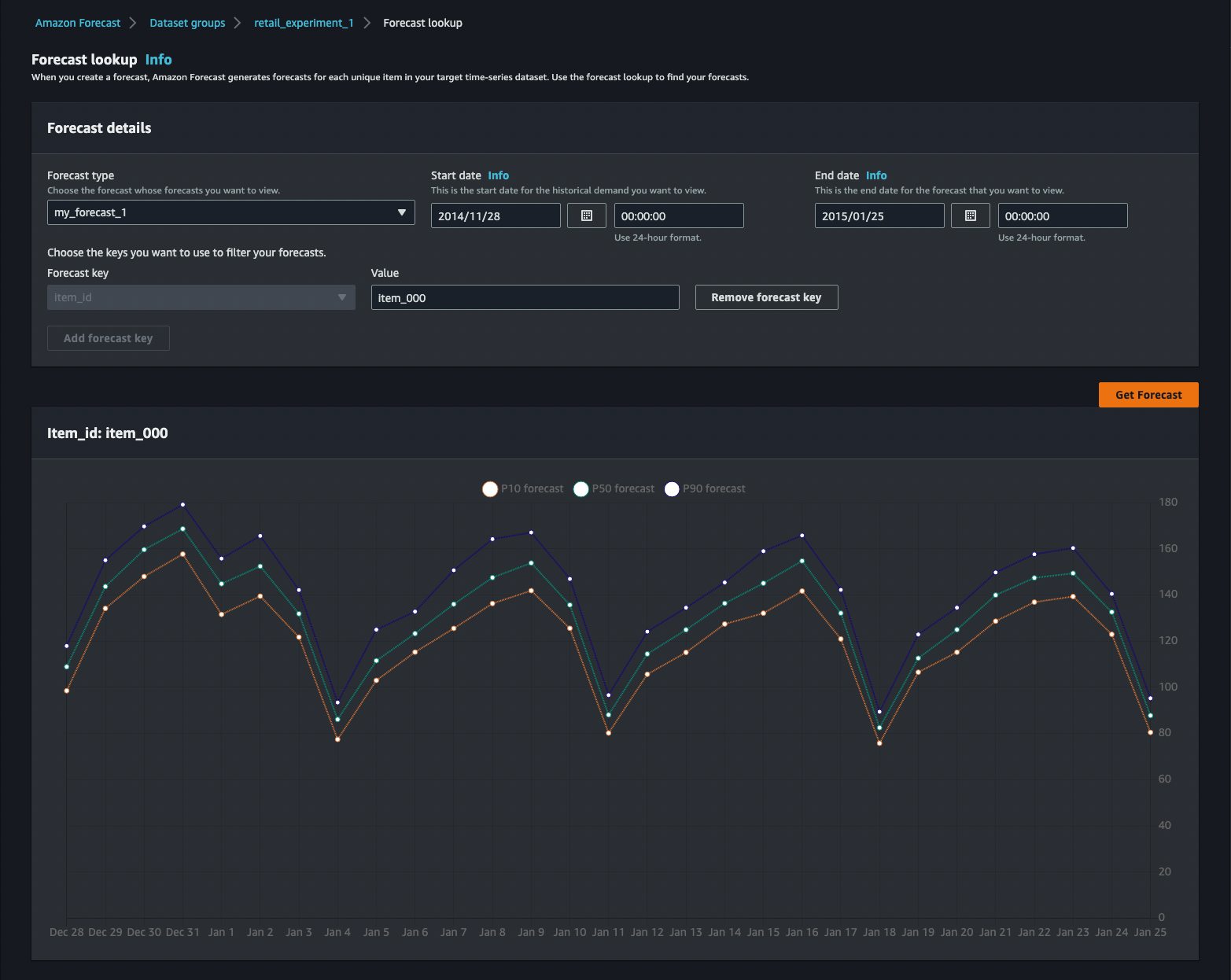
You can also see individual algorithm metrics for your predictor.
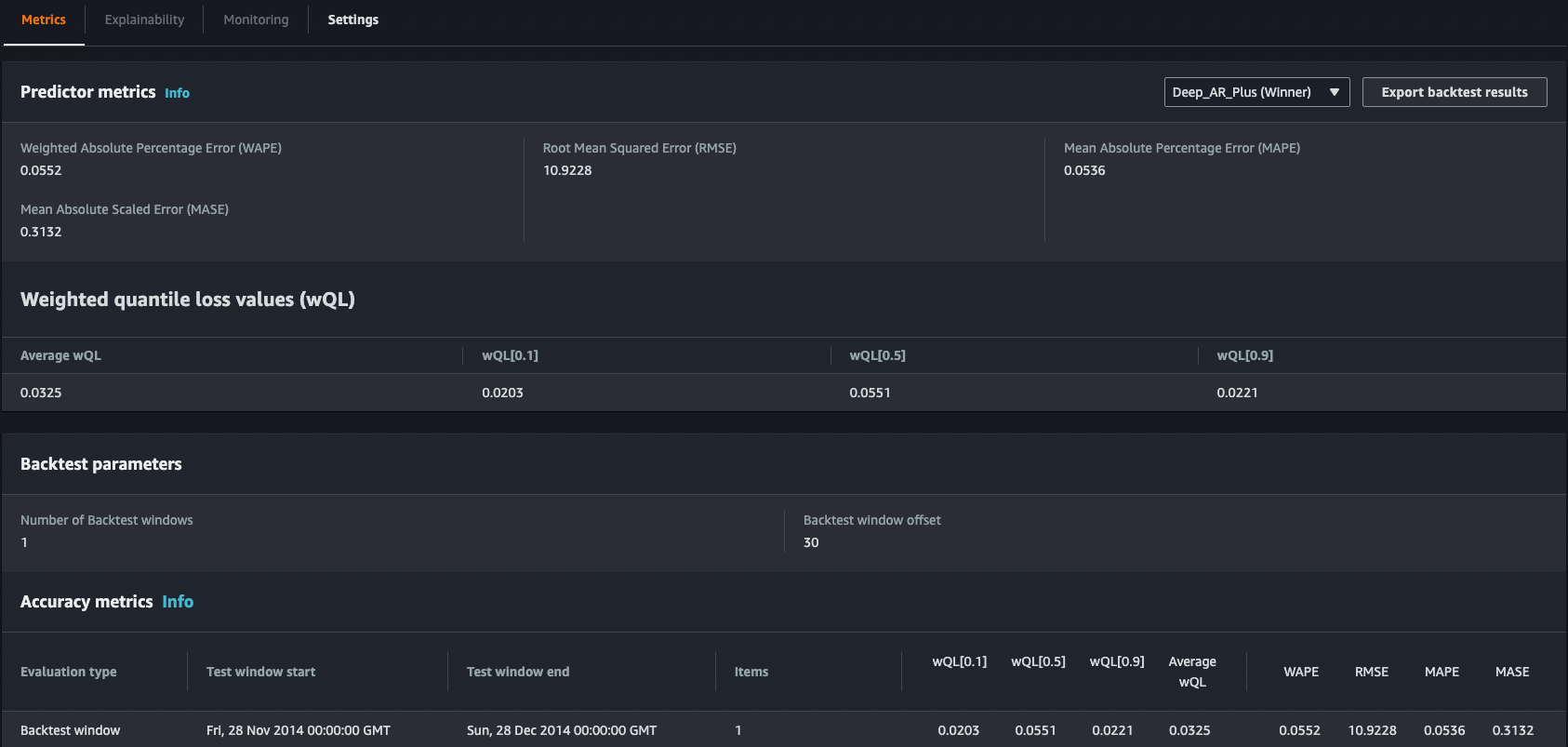
This solution is particularly useful for those retail organizations that recognize the need to implement demand forecasting and have a degree of familiarity with AWS development but where ML expertise is limited. It is a step up from the previous approach and provides a more detailed evaluation of forecast results as well as better control over the training process.
C. Advanced option
Amazon SageMaker is an advanced option for developers and data scientists who can use built-in algorithms like DeepAR or AutoML libraries, such as AutoGluon, or import existing models and perform transfer learning. Customers can use advanced options, like data parallelism and model parallelism, then use built-in features like
- Amazon SageMaker Clarify, which provides ML developers with purpose-built tools to gain greater insights into their ML training data and models, for bias;
- Amazon SageMaker Model Monitor, where users can select the data that they would like to monitor and analyze without the need to write any code, for monitoring; and
- Amazon SageMaker Debugger, which can reduce troubleshooting during training from days to minutes, for debugging.
The most complex projects often have multiple data sources and require advanced data transformation along with a large degree of control over the model training process. For those use cases, Amazon SageMaker is the most suitable choice.
To get a better understanding of this process, users can explore one of the existing solutions available in the AWS samples repository on GitHub.
In this notebook, there is an example of demand forecasting on synthetic retail data that shows users how to train and tune multiple hierarchical time-series models across algorithms and hyperparameter combinations using the scikit-hts tool kit on Amazon SageMaker. Users will learn how to set up scikit-hts on Amazon SageMaker using the Scikit Learn estimator, then train multiple models using Amazon SageMaker Experiments, and finally use Amazon SageMaker Debugger to monitor suboptimal training and improve training efficiencies. Here is a sample dataset:

First, users perform data preprocessing, cleansing, and data visualization. Then, they create an Amazon SageMaker experiment and use Scikit Learn Estimator to call the fit method to jump-start the training. Optionally, customers can use Managed Spot Training in Amazon SageMaker instances for training to be more cost effective and save 90 percent over On-Demand Instances.
![]()
In the console in Amazon SageMaker Studio, a fully integrated development environment (IDE) for ML, users can explore all their experiments and components..
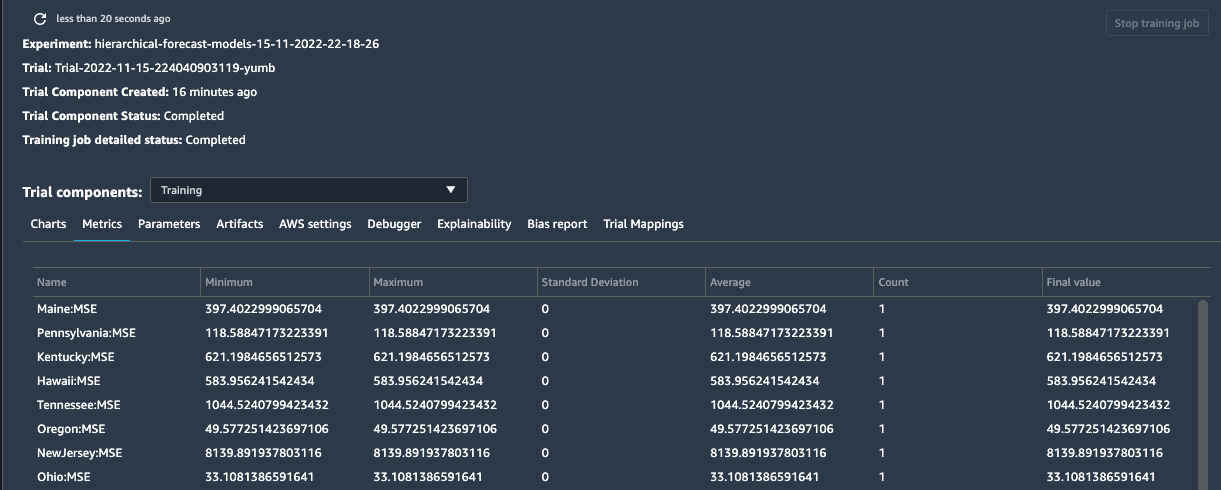
When the training concludes, users can run further analytics of models, pick a winner based on chosen metrics (MSE), and use it to start forecasting.

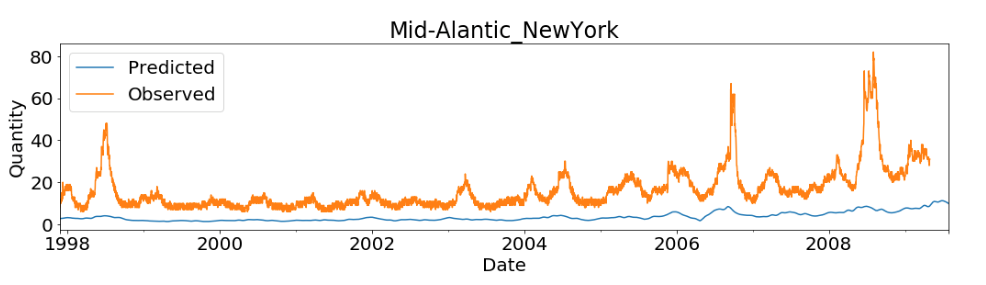
And finally, users can use matplotlib to visualize the first forecast.
Additionally, customers can use multiple other examples in the AWS samples repository on GitHub. Here are two useful examples:
- How to run time-series forecasting at scale with the GluonTS toolkit on Amazon SageMaker: Although this use case is for electricity prediction, it can easily be used to perform demand forecasting using GluonTS toolkit on Amazon SageMaker.
- Build a cold-start forecasting engine using AutoGluon AutoML for time series: This notebook demonstrates how to get forecasting on cold-start items.
Which option to pick
The three model training options described above and summarized below (A, B, and C) require progressively higher levels of ML expertise and model building and tuning experience. Retailers can choose an initial option based on the business goals and the stage of their ML journeys. For example, business users can start with option A if they have tabular data available. Business analysts can share prototype results with their data engineers and ML developers. Option B improves demand forecast accuracy from time-series data, especially when dealing with extensive data with irregular trends. As retailers move to more detailed or complex scenarios, option C offers more flexibility to dive deep into a customized ML forecasting model.
| Options | Applicable users | Access to model training process | Applicable datasets | Services | Control and manual tuning |
| (A)
no-code, low-code |
business analysts, sales managers | no customization to training and hyperparameter tuning | good quality, clean tabular dataset | Amazon SageMaker Canvas,
Amazon SageMaker Autopilot |
low |
| (B)
Amazon AI services |
data engineers, software engineers, ML developers | automated process with some control and customization | predefined retail dataset domains for time-series data, optional item metadata | Amazon Forecast | medium |
| (C) advanced option | data scientists, experienced ML practitioners | customized ML model, fine-grained control over training process | limited historical data, multiple data sources, advanced data transformation required | Amazon SageMaker | high |
Help from AWS Partners
In addition, retailers can connect with AWS Retail Competency Partners, offering retail forecasting solutions on AWS. These AWS Partner offerings have been validated for demonstrated technical proficiency and proven retail customer success in specialized areas, such as advanced retail data science. A selection of these partners is shown below.
Explore AWS Retail Competency Partners with solutions for retail demand forecasting:
Conclusion
Every use case is different, and every project requires a unique approach. The reference architecture presented in this document is an illustration of a systematic approach to a typical ML problem. In some cases, users can skip certain stages or combine them—or perhaps there might be additional steps in the journey. However, it is important to stick with the methodology to fully understand what’s required to solve a real-life problem with ML on the AWS Cloud.