Amazon Web Services ブログ
Category: Compute

AWS Weekly Roundup: AWS AI/ML Scholars プログラム、Agent Plugin for AWS Serverless など (2026 年 3 月 30 日)
2026 年 3 月 23 日週の出来事で私が最も心を躍らせたのは、AWS Agentic AI バイスプレジ […]
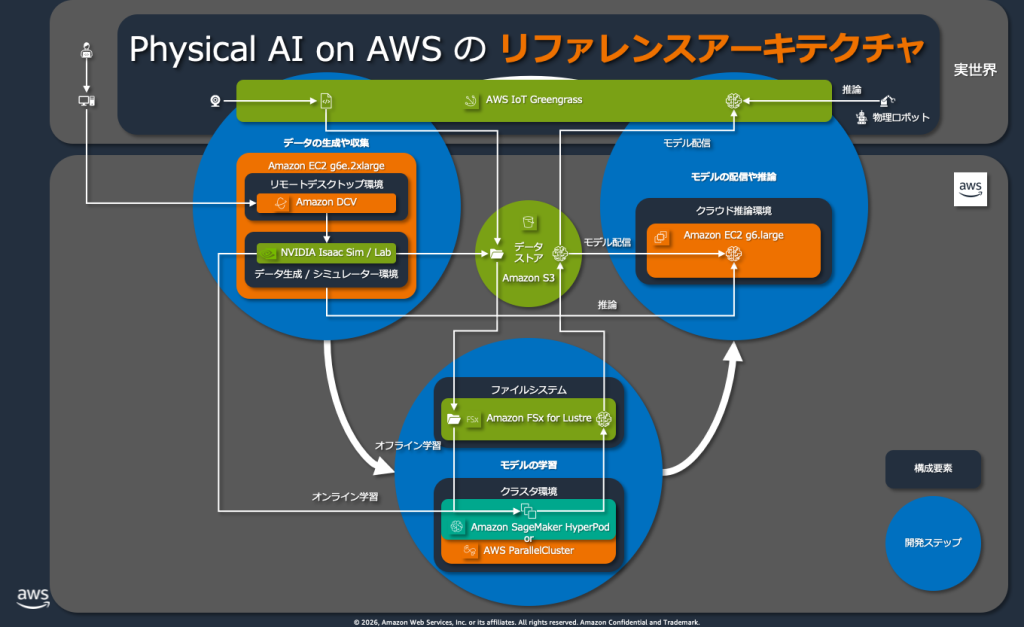
「Physical AI on AWS 勉強会 #1」を開催しました
2026 年 3 月 24 日、アマゾン ウェブ サービス ジャパン合同会社(以下、AWS ジャパン)は、「フ […]

電通総研、大規模 GPU 環境を約 1 ヶ月で構築 〜リアルタイム 3DCG ソリューション「UNVEIL」の戦略的アプローチ 〜
本ブログは株式会社電通総研とAmazon Web Services Japan が共同で執筆いたしました。 電 […]

Amazon Elastic VMware Service における VMwareワークロードのモダンネットワークの構築
組織がクラウド移行を加速させようとする中で、多くのお客様は既存の VMware ワークロードを Amazon Web Services (AWS) にリフトアンドシフトする方法を求めており、アプリケーションのリファクタリングやスタッフの再トレーニングのオーバーヘッドを避けたいと考えています。Amazon Elastic VMware service (Amazon EVS) は、VMware Cloud Foundation (VCF) を Amazon Virtual Private Cloud (VPC) 内で直接実行でき、VMware ワークロードを AWS で移行・運用するための最も迅速な方法を提供します。
VMware ワークロードを AWS に移行する際にお客様が課題として挙げるのが、クラウドでのネットワーク接続とアーキテクチャ設計です。Amazon EVS のネットワークモデルは、一般的なオンプレミスの VMware デプロイメントとはいくつかの違いがあります。本稿では、Amazon EVS のネットワークモデルを解説し、実証済みのアーキテクチャパターンをご紹介し、Amazon EVS の計画と導入を成功させるための重要な考慮事項をご説明します。

AWS Weekly Roundup: Amazon Bedrock での NVIDIA Nemotron 3 Super、Nova Forge SDK、Amazon Corretto 26 など (2026 年 3 月 23 日)
こんにちは! 今回初めて AWS Weekly Roundup を担当する Daniel Abib です。私は […]
Kiro で Amazon Connect AI エージェント開発を加速
本記事では、Kiro を使って 15 のバックエンド API を備えた Amazon Connect AI エージェントをわずか 3 日間で構築した方法を紹介します。仕様駆動設計、高速コード生成、CloudWatch Logs の自動分析による高速イテレーションにより、従来 2〜3 週間かかる開発を大幅に短縮できました。

AWS Load Balancer Controller が Kubernetes Gateway API サポートの一般提供を開始
AWS は最近、Amazon Web Services (AWS) Load Balancer Controller による Kubernetes Gateway API サポートの一般提供を発表しました。これまで、AWS Load Balancer Controller は Kubernetes Ingress と Service リソースの要件を満たすため、それぞれ Application Load Balancer (ALB) と Network Load Balancer (NLB) をプロビジョニングしていました。この新機能により、標準の Kubernetes Gateway API を使用してAWSロードバランシング機能を定義できるようになりました。

AWS 上の Microsoft および VMware ワークロード: AWS re:Invent 2025 完全プレイリスト
AWS re:Invent 2025 の Microsoft および VMware ワークロード移行に関するセッションプレイリストを紹介します。AWS Transform によるエージェンティック AI での自動化、Amazon EVS でのネイティブ VMware 実行、CSL や Thomson Reuters などの顧客成功事例を含みます。

AWS Weekly Roundup: Amazon Connect Health、Bedrock AgentCore ポリシー、GameDay Europe など (2026 年 3 月 9 日)
Fiti (スワヒリ語のスラングで「最高」) AWS Student Community Kenya! 202 […]

寄稿: 三菱電機が挑む製造業の商談変革 – AWS で実現した商談支援サービス「Memory Tech」
本稿は、三菱電機株式会社 名古屋製作所が新たに開発した AI を活用した商談支援サービス「Memory Te […]