Amazon Web Services ブログ
Category: Compute

AWS Weekly Roundup : Anthropic と Meta のパートナーシップ、AWS Lambda S3 ファイル、Amazon Bedrock AgentCore CLI など (2026 年 4 月 27 日)
3 月下旬、世界中の AWS スペシャリストが集まる最も活気あふれるイベントの 1 つである Speciali […]

AUMOVIO が Amazon Bedrock 搭載のエージェント型コーディングアシスタントでソフトウェア開発を強化
本ブログ記事では、AUMOVIO が Amazon Web Services (AWS) のサービスと知見を活用して、Software-Defined Vehicle (SDV) 領域における革新的な自動車向けコーディングアシスタントを開発した事例をご紹介します。AUMOVIO のソリューションは、複数の AI モデルを活用して開発ライフサイクルの各工程を加速させながら、自動車業界の標準と AUMOVIO 独自のコーディングベストプラクティスに準拠しています。可能な限りコードを再利用し、変更を最小限に抑えることで、このアシスタントは V 字モデルの他の工程に必要な作業を大幅に削減します。
リアルタイム分析ダッシュボードを備えた Innovation sandbox on AWS
本記事は、2026 年 1 月 28 日に公開された “Innovation sandbox on […]

Amazon EVS で Windows Server ライセンスが利用可能に: ステップバイステップガイド
Amazon EVS で Microsoft Windows Server ライセンスが利用可能になりました。BYOL または vCPU 時間単位の AWS 提供ライセンスの 2 つのオプションから選択でき、EVS 環境内で Windows Server VM を柔軟に運用できます。本記事では、vCenter コネクタの作成からライセンスエンタイトルメントの設定、KMS サーバーによるアクティベーションまでの手順を説明します。

[資料公開 & 開催報告] 初学者向けセミナー「これから始める AWS のコンテナサービス活用」を開催しました
2025年4月14日(火)にコンテナサービスの基礎的な内容を扱うウェビナー「これから始める AWS のコンテナサービス活用」を開催しました。本セミナーでは、なぜコンテナが必要なのか、AWS コンテナサービスのラインナップや使い分けといった基礎的な内容から、生成 AI を活用したコンテナ環境の構築・運用や ECS/EKS の新機能のご紹介まで幅広くお届けし、170名の方々にご登録いただき、131名の方々に当日ご参加いただきました。
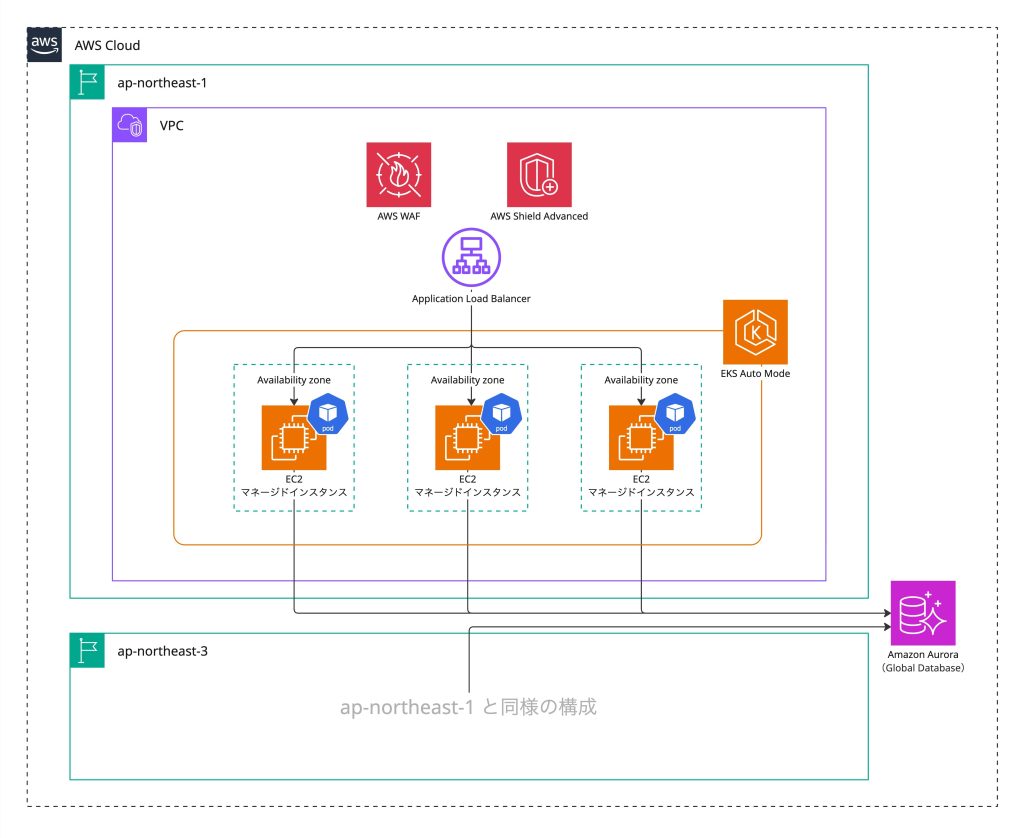
寄稿:SBI ネオバンキングシステムにおける Amazon EKS Auto Mode の導入事例 ― 移行で実現した運用負荷の軽減
本稿は、SBI ネオバンキングシステム株式会社による AWS EKS Auto Modeの活用について、主導さ […]
丸紅グループが描く生成AI活用の全貌 〜内製開発・AIエージェント活用で変わる総合商社の姿〜
本ブログは 【寄稿】AI民主化に向けた丸紅の取組(丸紅株式会社)の続編です。 みなさん、こんにちは。総合商社を […]

AWS Weekly Roundup: AWS DevOps エージェントとセキュリティエージェント GA、製品ライフサイクルの更新など (2026 年 4 月 6 日)
2026 年 3 月 30 日週、私はチームと一緒に AWS 香港ユーザーグループを訪問しました。香港には小さ […]
Amazon ECS マネージドインスタンスのマネージドデーモンサポートの発表
2026 年 4 月 1 日、Amazon Elastic Container Service (Amazon […]

2026 年 3 月の AWS Black Belt オンラインセミナー資料及び動画公開のご案内
2026 年 03 月に公開された AWS Black Belt オンラインセミナーの資料及び動画についてご案内させて頂きます。
動画はオンデマンドでご視聴いただけます。