Amazon Web Services ブログ
Category: Analytics

AWS Weekly Roundup: Amazon Bedrock エージェントワークフロー、Amazon SageMaker プライベート接続など (2026 年 2 月 2 日)
2026 年 1 月 26 日週、私たちはラバ祭りを祝いました。これは、旧正月まで残りわずかであることを告げる […]
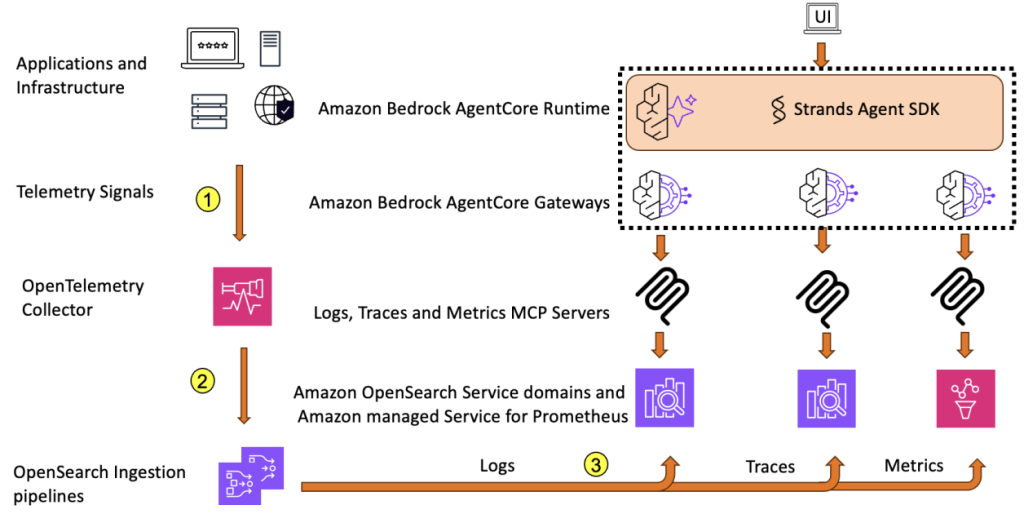
オブザーバビリティエージェントで平均復旧時間を短縮する
Amazon OpenSearch Service と Amazon Bedrock AgentCore を使用したオブザーバビリティエージェントを紹介します。ログ、トレース、メトリクスを自律的にクエリし、相関させることで、インシデント調査を効率化し、平均復旧時間 (MTTR) を短縮できます。

Amazon OpenSearch Ingestion 101: 主要メトリクスに対する CloudWatch アラームの設定
Amazon OpenSearch Ingestion パイプラインの主要メトリクスに対する Amazon CloudWatch アラームの設定方法を解説します。Source、Processor、Sink、Buffer の各コンポーネントのアラームメトリクスと、パイプラインのレイテンシー低減やドキュメントエラー解決のシナリオを紹介します。

Amazon MSK Connect と Iceberg Kafka Connect でリアルタイムデータレイクを構築する
Amazon MSK Connect と Iceberg Kafka Connect を使用して、トランザクションデータベースから Apache Iceberg テーブルへのリアルタイムデータ同期を実現する方法を紹介します。単一テーブルと複数テーブルの同期、スキーマ進化機能についても解説します。

AWS で DER アグリゲーター向けのスケーラブルな DERMS ソリューションを構築する
エネルギー環境が分散型モデルへと進化する中、分散型エネルギーリソース (DER) は、エネルギー市場のさまざまなプレーヤー (電力会社、立法機関、アグリゲーター、消費者、サービスプロバイダー) に課題と機会の両方をもたらしています。
さまざまな関係者が Amazon Web Services (AWS) を活用して DER を最大限に活用する方法について、一連のブログを計画しています。最初のブログでは、アグリゲーターが事業の成長に合わせて拡張できる堅牢な分散型エネルギーリソース管理システム (DERMS) を構築するために、AWS サービスがどのように役立つかを探ります。

Amazon Redshift Serverless のキューベース QMR できめ細かなリソース制御を実現する
Amazon Redshift Serverless のキューベース Query Monitoring Rules (QMR) を使用して、ワークロードごとに専用キューを作成し、リソース使用量をきめ細かく制御する方法を学びます。クエリの自動中止、ログ記録、制限により、ビジネスクリティカルなクエリを保護し、コストを管理できます。
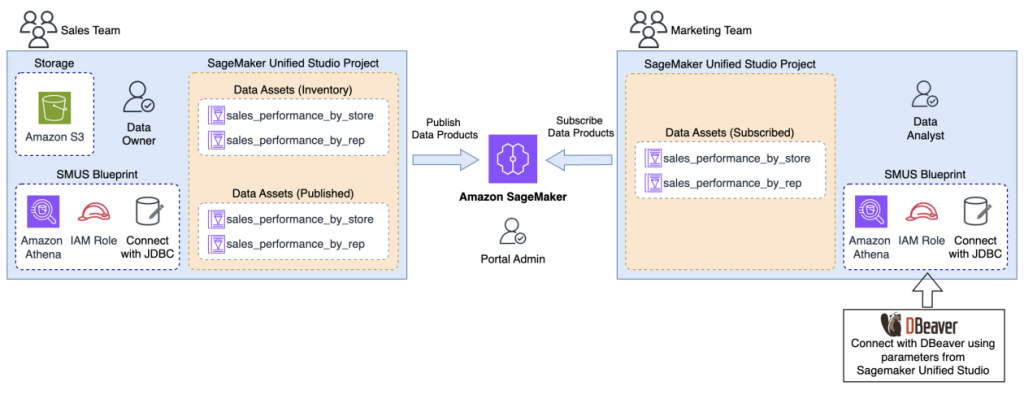
Amazon SageMaker Unified Studio と Tableau、Power BI などの統合で分析を強化
Amazon SageMaker Unified Studio が Athena JDBC ドライバーを通じて Tableau、Power BI、Excel、SQL Workbench、DBeaver などの一般的な BI および分析ツールとの統合をサポート。データユーザーは使い慣れたツールでガバナンスされたデータに安全にアクセスして分析できます。
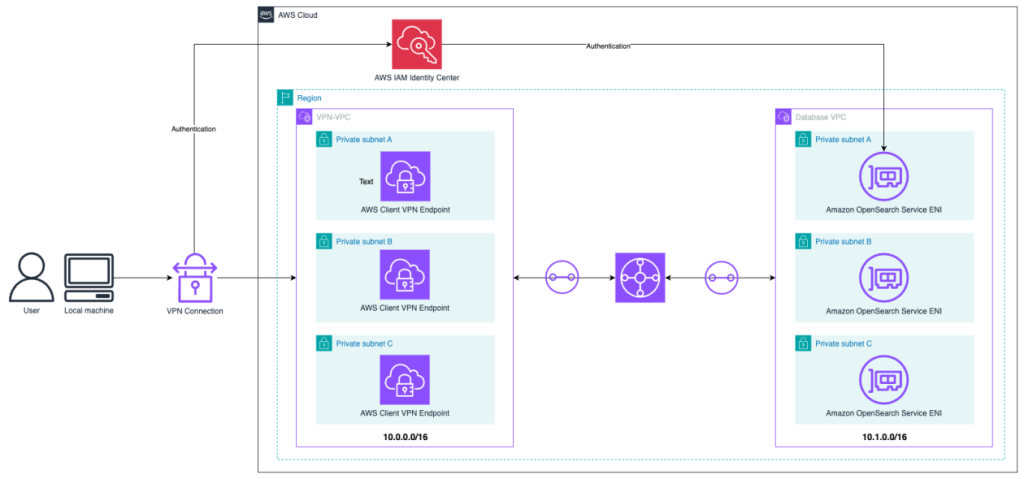
AWS Client VPN を使用して SAML 認証で VPC 内の Amazon OpenSearch Service ドメインにアクセスする
本記事では、AWS Client VPN、AWS Transit Gateway、AWS IAM Identity Center を使用して、VPC 内にデプロイされた Amazon OpenSearch Service ドメインに SAML 認証でアクセスするアーキテクチャの構築方法を紹介します。踏み台サーバーを使用せずに、安全で集中管理されたアクセスを実現できます。

自動車および製造業界むけ AWS re:Invent 2025 のダイジェスト
AWS の年次フラッグシップイベントである AWS re:Invent 2025 は、 2025 年 12 月 […]
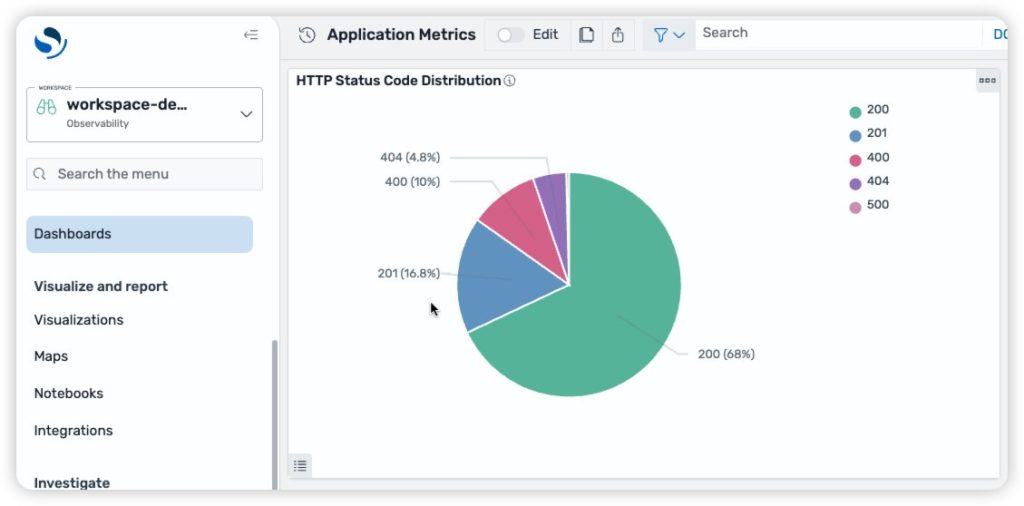
AWS CDK を使用した Amazon OpenSearch UI インフラストラクチャの IaC 管理
この記事では、AWS CDK を使用して Amazon OpenSearch UI アプリケーションをデプロイし、AWS Lambda 関数と統合してワークスペースとダッシュボードを自動的に作成する方法を説明します。Infrastructure as Code (IaC) により、環境は標準化され、バージョン管理され、デプロイ間で一貫性のある分析機能を備えた状態で起動します。