AWS Partner Network (APN) Blog
How AWS Machine Learning Services Increase Medical Coding Accuracy and Efficiency
By Pavel Vasilyev, Director of Solutions Architecture at ClearScale
By Vyacheslav Gorlov, Sr. Solutions Architect at ClearScale
 |
| ClearScale |
 |
Medical coding helps providers maintain patient records and obtain reimbursement for services. Unfortunately, the process is complicated, time-consuming, and prone to error.
Among the most significant challenges is accurately deciphering the correct codes from notes dictated by medical professionals after patient visits. It requires listening to recordings and identifying the diagnoses and procedures performed.
That information must then be matched to billing codes drawn from different code systems, and have medical billing rules applied to it.
Numerous software programs have been developed to simplify these processes using macros, automation, and speech recognition.
Unfortunately, these programs often generate inaccurate transcriptions:
- Voice-to-text translation accuracy can be hampered by an inability to discern the context in which many words are used, as well as the ambiguity and imprecise characteristics of natural language processing (NLP). This includes pronunciation and spelling variances.
. - Rules-based approaches tend to be too general and cannot take into account language variants. Most of the software programs lack the ability to fully understand medical terminology, much less the terminology differences when more than one language is involved. There can also be issues with voice activity detection.
. - Regulatory compliance presents yet another challenge. Any organization that works with protected health information (PHI) is subject to stringent HIPAA rules for security and privacy in the United States, and similar regulations abroad. Failure to comply with these mandates can lead to costly fines and penalties.
Companies that deal with medical coding often struggle to incorporate the necessary technical security and privacy to meet these requirements.
Creative Practice Solutions, a medical consulting firm, recently collaborated with Amazon Web Services (AWS) and ClearScale to develop an application that increases the efficiency and accuracy of the coding process. Powered by machine learning (ML), the application translates recorded medical appointment notes, and uses the information to generate more accurate medical codes.
ClearScale is an AWS Premier Consulting Partner with 10 AWS Competencies, including one in Healthcare. In this post, we will describe the solution we developed, including its architecture, workflow, our approach to natural language processing, a little about deployment and the user experience, and finally our results and plans for the future.
Solution Overview
The solution that ClearScale designed, detailed in the following architecture diagram, uses a variety of AWS services.

Figure 1 – ClearScale’s solution overview.
The key capabilities of ClearScale’s solution are:
- Easy to manage elastic compute − The compute layer is almost entirely serverless, including services like AWS Lambda and AWS Fargate. This provides virtually infinite scalability, without adding any systems administration burden. To provide automatic health checks, provisioning, and decommissioning, we used both Network and Application Elastic Load Balancers.
. - Performant and scalable storage − The storage layer includes a secure and reliable data lake designed for the long-term storage of entities of various sizes. Mostly, it consists of multiple Amazon Simple Storage Service (Amazon S3) buckets for different purposes, such as raw recordings, processed transcripts, and intermediate artifacts storage.
. - Operations and governance − We used Amazon CloudWatch, Amazon Simple Notification Service (SNS), AWS CloudTrail, and AWS Config for management and governance. These services provided excellent visibility and traceability for application internals.
.
To distribute application updates quickly and risk-free, we stuck with AWS Developer Tools and adopted the principles of continuous delivery. We designed the entire infrastructure to be reproducible in case of disaster by using infrastructure as code (IaC) via AWS CloudFormation.
.
In the future, we will migrate to AWS Cloud Development Kit (AWS CDK), which provides object-oriented and protocol-oriented methods to reduce boilerplate code. It also allows us to find bugs and edge cases during development, rather than after it has been deployed into production.
. - Ability to interrogate the data − The ML layer consists of AWS machine learning services and allows it to glean comprehensive results from the data, without suffering from the zero-size historical dataset.
Workflows
AWS Step Functions state machines orchestrate the AWS services in the solution into serverless workflows. The process starts with a healthcare provider recording a medical appointment conversation, typically on a mobile device. The recording can be paused and continued in the future, if, for example, a doctor has to work with another patient.
The healthcare provider can also review and edit the notes if needed. In addition, the notes can be signed to protect them from accidental or malicious editing.
The solution uploads the recordings to an Amazon S3 object storage bucket. This event triggers a Lambda function to start the processing cycle. AWS Step Functions trigger all the Lambda functions in the application tier.
Following, we walk through each the transcription and information extraction processes.
Transcription Process
The process for medical transcription is shown in Figure 2, while Figure 3 shows which AWS components are involved.
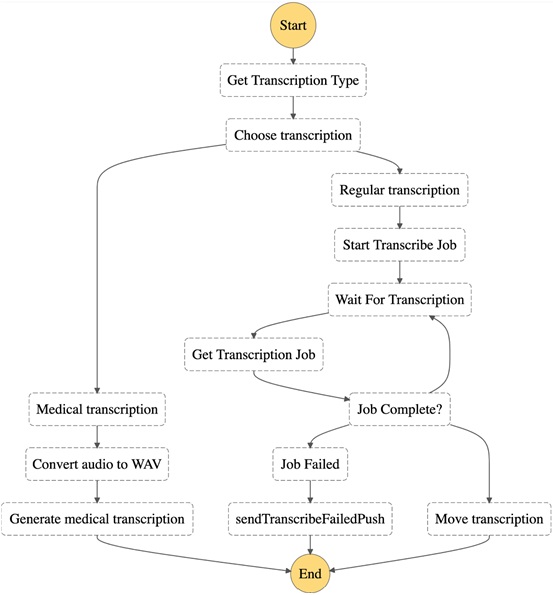
Figure 2 – Stateflow diagram for medical transcription.
We first extract S3 meta tags from the recording, which we use for stateflow augmentation; for example, transcription type and applied medical specialties.
Based on one of these tags, we decide whether to use the standard Amazon Transcribe service or the more specialized Amazon Transcribe Medical. The medical version provides better accuracy for medical terms without custom vocabulary preparation, but is limited to US English. Since we may want transcriptions of medical terms in languages other than US English, we maintain two state machine branches.
We implemented the branch for Amazon Transcribe Medical as AWS re:invent 2019 occurred, so it still relies on low-level WebSocket APIs. To overcome this limitations and inconvenience, we introduced a custom microservice. It converts input audio into raw format, and sends it in chunks into Amazon Transcribe Medical. This combines the outputs, and moves the result into the main flow.
We use the Amazon Transcribe branch mainly for non-English speakers and situations when processing duration is more important than accuracy. To improve the transcription quality and align it with what Amazon Transcribe Medical branch produces, ClearScale carefully composed a custom vocabulary of medical terms.
If the resulting transcript is not in English, Amazon Translate converts it into English to be further processed by Amazon Comprehend Medical.
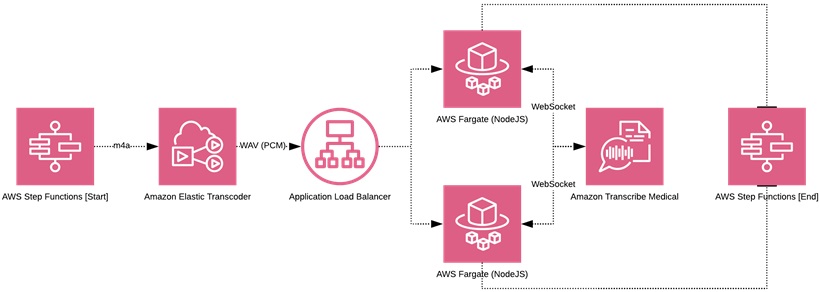
Figure 3 – AWS services involved in the transcription process.
Information Extraction Process
The process for information extraction is shown in Figure 4, while Figure 5 shows which AWS components are involved.
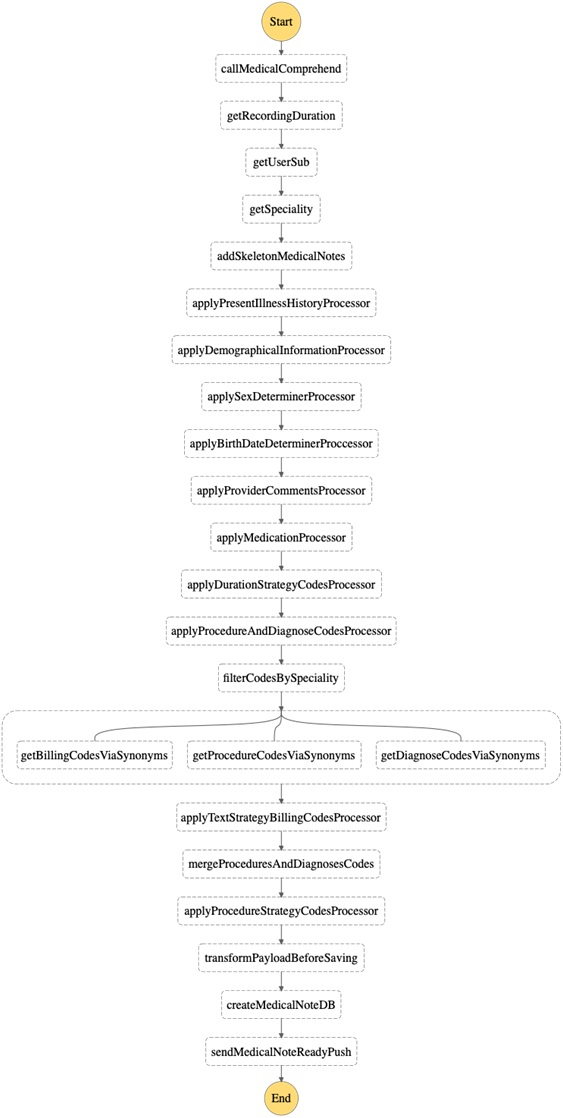
Figure 4 – Stateflow diagram for information extraction.
Now that the recording has gone through multiple optimizations, is accurately transformed from audio to text, and is aligned with US English, it’s time to mine the named entities directly involved in medical billing coding.
It’s also an iterative, multi-step process because of various types of codes (ICD10 for diagnoses and RxNorm for medications, for example) to be extracted and billing rules (based on duration and key phrases presented) to be applied.
- Amazon Comprehend Medical − The “hearth” of the pipeline is Amazon Comprehend Medical, providing PHI, diagnosis, procedures, and medications from the text.
. - Recording metadata extraction − Each recording object in Amazon S3 carries various metadata that participated in medical coding operations. It extracts duration, medical specialty, and doctors’ Amazon Cognito unique identifier.
. - Skeleton medical note − Appends the base medical note to the carried state to be filled in later.
. - Present illness history − Relies both on Amazon Comprehend Medical’s Detect Entities Version 2 and Infer ICD10 features to extract diagnoses and anatomies.
. - Medical entities recognition − At this step, with the help of Amazon Comprehend Medical and custom ML algorithms, medical entities (like diagnosis, procedures, medications, anatomies, and doctor’s comments) are transformed into their respective codes and added into the note.
.
Simultaneously, the billing coding rules are applied, accounting for the appointment’s length, disease duration, relevant diagnosis, and performed examinations.
. - Fuzzy Matching − This provides the ability to find non-strict versions of words and sentences in text. For example, “nasal” and “nose endoscopy” can be recognized as synonyms with a certain confidence. Fuzzy Matching is used for billing codes, diagnosis, and procedures. Accuracy is improved through synonym dictionaries based on NLP.
. - Database load − The medical note is saved into MongoDB through a database API that is:
- A full CRUD database layer, which is abstracted from the actual database implementation.
- A stateless Amazon Relational Database Service (Amazon RDS) proxy analog, which continuously maintains a pool of warm connections to the Amazon DocumentDB, reducing cold start.
- A robust load balancer and disaster detection and prevention system.
- Figure 5 below shows which AWS components are involved in this mircoservice.
.
- Push notification on stateflow completion − Sent via Amazon Pinpoint, it signals the data can be fetched via Amazon API Gateway, revised by the doctor, and exported to other medical systems when needed.
.
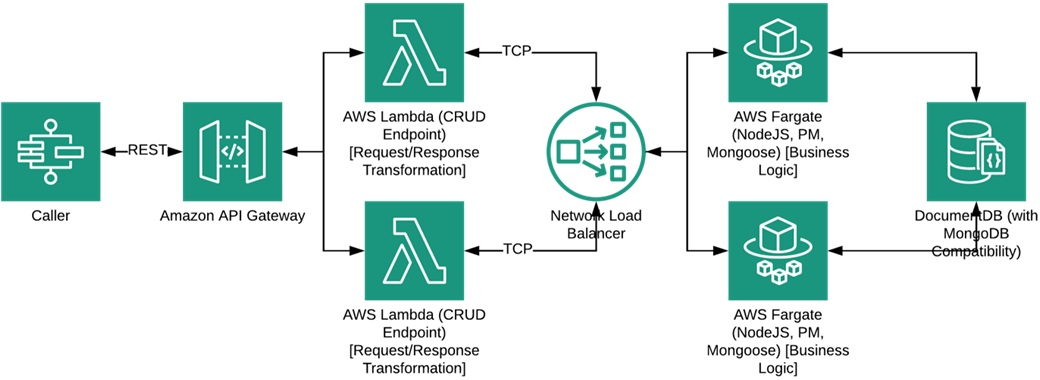
Figure 5 – AWS services involved in information extraction.
Our Approach to Natural Language Processing
Though integral to the solution, NLP presented challenges due to the ambiguity of human language. For example, the same word can have multiple meanings. Different words can mean the same thing. Grammar rules, the context in which words are used, industry jargon, slang, and other factors, further complicate processing.
Amazon Comprehend Medical (including ICD10 and RxNorms ontologies) allows us to extract meaningful medical entities from free-form texts. Its underlying algorithms produce high-accuracy results with exact entities position in the text. However, medical billing coding is more sensitive to missing entities than to redundant ones.
For example, if a diagnosis has been implicitly stated, it will normally go into the billing rules. If it does not, the overall insurance claim can be rejected.
To overcome this obstacle, we augmented Comprehend’s outcomes with Fuzzy Matching. This approach allows us to find “similar” words, statements, or even sentences by accounting for factors such as their parts (root, suffix, prefix), absolute position in the text, and position relative to other word types (for example, the adjective is likely to appear near its subject).
ClearScale’s implementation relies on the highly-modified variant of Elasticsearch’s Fuzzy Matching deployed in the Amazon Elastic Container Service (Amazon ECS) cluster. This algorithm is semi-supervised, meaning it can produce results without historical data. However, you can get better outcomes if you supply the specific terms you are looking for and their synonyms.
The solution also generated a list synonyms to further train the ML model. We employed the NLP technique Word2Vec, which creates a words matrix wrapped into n-dimensional space. Likewise for cosine similarity, which measures the text-similarity between two documents.
We also used Doc2Vec to vectorize the entire document, Sent2Vec to vectorize sentences, and FastText to enrich word context through subword information.
We use two different ML models and converted their results into the vectors dictionary NLWordEmbedding through Apple CreateML on macOS. The resulting Word2Vec vectors can be exported in a C text format.
The ML trainer relies on parallelization and can train multiple models. The trained models are embedded in a highly optimized Reducer that produces the synonyms list to be imported into Amazon OpenSearch Service (successor to Amazon Elasticsearch Service).
The solution makes use of parallelization and multi-threading, using Apple Grand Central Dispatch (GCD) DispatchGroup, DispatchSemaphore, aggressive buffers, and aggressive Automatic Reference Counting (ARC). It’s capable of mapping procedures to diagnoses and using various measures of semantic similarity, such as the WuPalmer WordNet similarity and Resnik similarity.
Because there are few available medical text corpora, we implemented web crawling to create a robust dataset. We also employed DiffBot, an artificial intelligence (AI) web data extraction and crawling tool, because of its automation capabilities. We used the Unified Medical Language System (UMLS) as a text corpus source.
To validate, transform, and unload the data, we wrote a bot client using Apple Swift. It uploads predefined sitemaps to be parsed, and fetches URLs from sitemaps, following XML specifications. DiffBot crawls the parsed URLs.
The whole texts array is serialized into the LineSentences format. Once the text corpus is ready, we train the Word2Vec model with text8.
Multiple Platforms, Single Code Base
In creating the solution, we also took advantage of Apple Catalyst, which uses the iOS 13 software development kit (SDK) to take applications developed natively for iOS devices and run them natively on Macs with few changes to the API set.
The Apple UIKit framework provides the infrastructure for iOS or tvOS applications, and unifies the substrate layer between iOS and macOS so that iOS applications can run on macOS.
We delivered our single solution as multiple applications available on different Apple devices. The applications maintained the same design and functionality as on iOS devices and iPads, but their user experience (UX) and user interface (UI) designs are adapted to match macOS design patterns.
UX / UI Designs
ClearScale also set up the UI to automatically adapt to the surrounding environment, working much like Dark Mode in macOS devices. The system adopts a darker color palette for all windows, views, menus, and controls.
Our applications incorporate features to enhance accessibility, such as using Apple’s VoiceOver gesture-based screen reader for vision accessibility. It also includes the ability to change the voice activation detection (VAD) frequency for each user. It can have variable settings for the amount of time no speech is detected so the recording can be stopped.
In addition, we incorporated two kinds of search functions: predicate-based, which requires an exact match of some part of the word, and the heuristic-based fuzzy search. The latter is useful for cases where it is difficult to remember the exact wording when conducting a search, or it’s faster to search for a patient name based on initials.
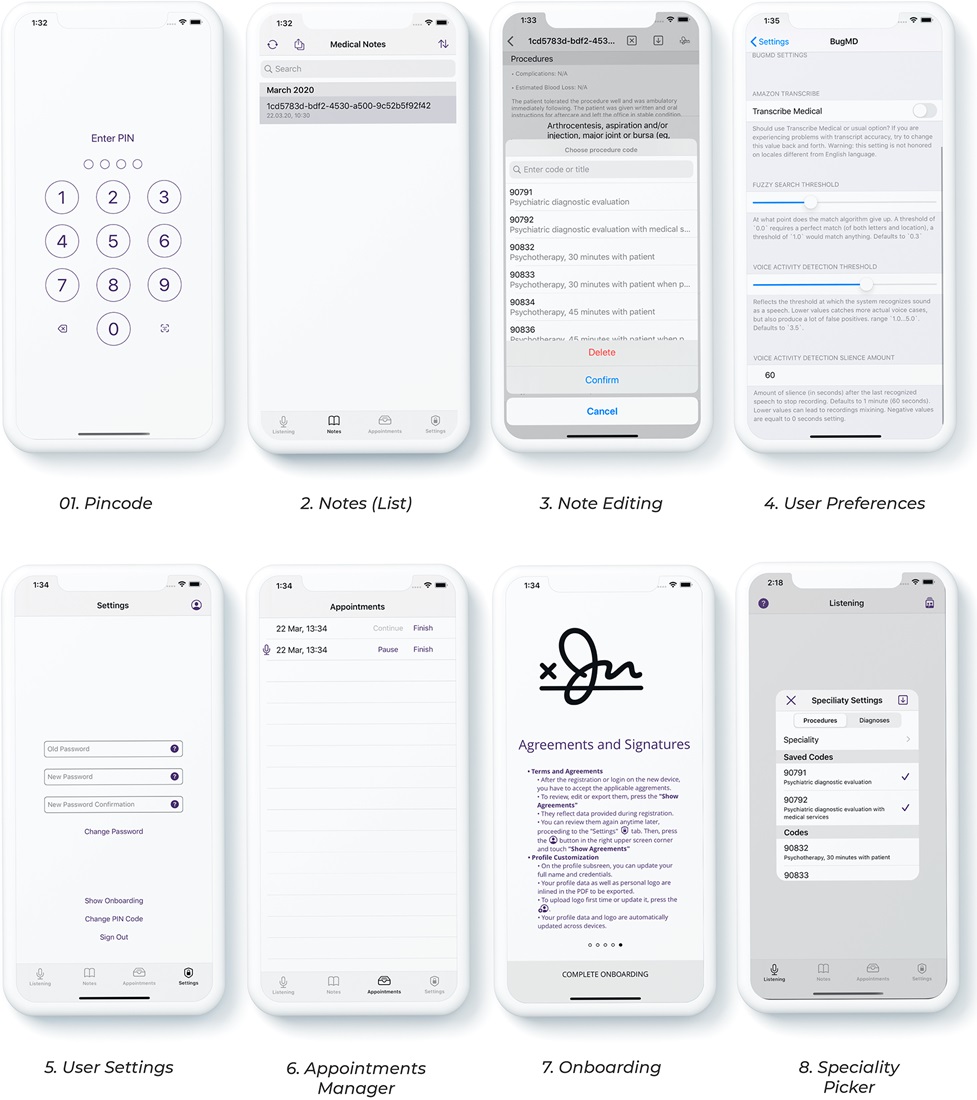
Figure 6 – UX / UI for the application’s version for the iPhone.
Results
While ClearScale’s solution is still evolving, the prototype has already demonstrated numerous benefits to Creative Practice Solutions, our customer:
“Physicians receive little to no training on medical coding, modifiers, or supportive documentation as it relates to actual payment approval,” says Matt Dallmann, President at Creative Practice Solutions.
“This gap has only been made more cumbersome by the digital landscape. Our mission has always been to develop practical solutions for an impractical process. With the help of ClearScale, CPS is on the verge of eliminating much of the technical and administrative burdens of medical coding and administration.”
The benefits of ClearScale’s solution for the customer include:
- Accuracy − Our applications deliver a more accurate translation of speech-to-text because background noise is eliminated, and there’s no need to recognize different speakers.
. - English and Spanish − Our applications can recognize US English natively and translate US Spanish to US English.
. - HIPAA compliance − The applications are architected for HIPAA compliance with built-in security controls and HIPAA-eligible services such as Amazon Comprehend Medical. They also incorporate security and data privacy best practices, including encryption at rest and in transit, audit trails, and multi-factor authentication.
. - Reduced management time − The use of AWS managed services reduces administration and management time and costs. With AWS Lambda, for example, you can run code for virtually any type of application or backend service with zero administration.
.
Creative Practice Solutions has approximately 500 doctors who average four to six appointments a day, five days a week. The company reports that post-processing previously took four to five hours. Now, that time has been reduced to one hour.
. - Decreased costs − The use of AWS services also helps reduce costs, as demonstrated by Amazon Comprehend Medical. Creative Practice Solutions is only charged based on the amount of text processed on a monthly basis in particular, and the usage base in general.
More to Come
This is just the beginning. ClearScale will develop additional capabilities and integrate components to meet more regulatory requirements. As historical data is gathered, we will further train ML models while continuing to optimize processes and results.
As AWS releases new services and features, ClearScale and Creative Practice Solutions will implement them to further optimize further and simplify the medical coding and transcription processes.
Conclusion
The process of medical coding is complicated, time-consuming, and prone to error. Companies that deal with medical coding often struggle to incorporate the necessary technical security and privacy to meet these requirements.
The collaboration between Create Practice Solutions, AWS, and ClearScale led to an application that increases the efficiency and accuracy of the coding process.
To learn how ClearScale can help your company leverage AWS machine learning services, or to learn about the benefits of multi-platform, native application development, contact ClearScale at sales@clearscale.net.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
ClearScale – AWS Partner Spotlight
ClearScale is an AWS Premier Consulting Partner and AWS Competency Partner that helps customers design, build, deploy, and manage complex cloud architectures on time and on budget.
Contact ClearScale | Partner Overview
*Already worked with ClearScale? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.