AWS Partner Network (APN) Blog
Taming Machine Learning on AWS with MLOps: A Reference Architecture
By Kwabena Mensa-Bonsu, Sr. Consultant – Data Reply
By Luca Piccolo, Manager – Data Reply
 |
Despite the investments and commitment from leadership, many organizations are yet to realize the full potential of artificial intelligence (AI) and machine learning (ML).
Data science and analytics teams are often squeezed between increasing business expectations and sandbox environments evolving into complex solutions. This makes it challenging to transform data into solid answers for stakeholders consistently.
How can teams tame complexity and live up to the expectations placed on them? MLOps provides some answers.
There is no one size fits all when it comes to implementing an MLOps solution on Amazon Web Services (AWS). Like any other technical solution, MLOps should be implemented to meet the project requirements.
The first part of this post will discuss the key components of an MLOps solution architecture, regardless of the project requirements or business goals. The second part will explore a conceptual example of an MLOps architecture to demonstrate how these key components can be glued together to implement an MLOps solution.
For an introduction to MLOps, refer to Reply’s whitepaper: How MLOps helps operationalize machine learning models.
Data Reply is a Reply Group company, an AWS Premier Consulting Partner and Managed Service Provider (MSP) that offers a broad range of advanced analytics, AI/ML, and data processing services. Reply holds 10 AWS Competencies, including Machine Learning, and was an AWS launch partner in the latest ML Competency category: MLOps.
Reply operates across different industries and business functions, enabling customers to achieve meaningful business outcomes through effective use of data, which accelerates innovation and time to value. Reply is also a member of the AWS Well-Architected Partner Program.
Key Components of an MLOps Solution
This section briefly discusses the key components for implementing an MLOps solution:
- A version control system to store, track, and version changes to your ML code.
. - A version control system to track and version changes to your training datasets.
. - A network layer that implements the necessary network resources to ensure the MLOps solution is secured.
. - An ML-based workload to execute machine learning tasks. AWS offers a three-layered ML stack to choose from based on your organization’s skill level.
.
We describe the three layers briefly here, and will refer to them in later sections:- AI services: They are a fully managed set of services that enable you to quickly add ML capabilities to your workloads using API calls. Examples of these AWS services are Amazon Rekognition and Amazon Comprehend.
- ML services: AWS provides managed services and resources (Amazon SageMaker suite, for example) to enable you to label your data and build, train, deploy, and operate your ML models.
- ML frameworks and infrastructure: This is a level intended for expert ML practitioners using open-source frameworks like TensorFlow, PyTorch, and Apache MXNet; Deep Learning AMI for Amazon EC2 P3 and P3dn instances; and Deep Learning Containers to implement your own tools and workflows to build, train, and deploy the ML models.
It’s important to note the ML-based workloads can also be implemented by combining services and infrastructure from the different levels of the AWS ML stack.
- Use infrastructure as code (IaC) to automate the provisioning and configuration of your cloud-based ML workloads and other IT infrastructure resources.
. - An ML (training/retraining) pipeline to automate the steps required to train/retrain and deploy your ML models.
. - An orchestration tool to orchestrate and execute your automated ML workflow steps.
. - A model monitoring solution to monitor production models’ performance to protect against both model and data drift. You can also use the performance metrics as feedback to help improve the models’ future development and training.
. - A model governance framework to make it easier to track, compare, and reproduce your ML experiments and secure your ML models.
. - A data platform like Amazon Simple Storage Service (Amazon S3) to store your datasets.
Implementing an MLOps Solution
The ML-based workload (as described in the previous section) underpins the reproducible machine learning pipeline, which, as mentioned in Reply’s whitepaper, is central to any MLOps solution.
The ML-based workload implementation choice can directly impact the design and implementation of your MLOps solution. Since this post aims to showcase a reference architecture of an MLOps solution that can be easily adapted for different use cases, we chose an ML-based workload implementation that would meet this requirement.
To better understand the architectural considerations of the reference architecture, we will further explore AWS options for building ML-based workloads.
If the ML capabilities required by your use cases can be implemented using the AI services mentioned above, then you likely don’t need an MLOps solution. On the other hand, if you use either the ML services or ML frameworks and infrastructure, we recommend you implement an MLOps solution that’s conceptually similar to our reference architecture regardless of the use case.
The ML services stack’s ease of use and support for various use cases made it a good candidate for the ML-based workload implementation for our reference architecture.
Also, keep in mind your implementation of model training and serving algorithms can alter your MLOps solution. Let’s look at the three main options Amazon SageMaker provides when it comes to choosing your training algorithm:
- Use a built-in Amazon SageMaker algorithm or framework. With this option, a training dataset is the only input developers and data scientists have to provide when training their models. On the other hand, the trained model artefacts are the only input they need to deploy the models. This is the least flexible of the options available and a good fit for scenarios where off-the-shelf solutions meet your need.
. - Use pre-built Amazon SageMaker container images. For this option, you need to provide two inputs to train your models, and they are your training scripts and datasets. Likewise, the inputs for deploying the trained models are your serving scripts and the trained model artefacts.
. - Extend a pre-built Amazon SageMaker container image, or adapt an existing container image. This is for more advanced use cases. You are responsible for developing and maintaining those container images. Therefore, you may want to consider implementing a CI/CD pipeline to automate the building, testing, and publishing of the customized Amazon SageMaker container images and then integrate the pipeline with your MLOps solution.
.
This can introduce some complexity to the MLOps solution, but it provides the flexibility to use custom and other third-party libraries to build and train your models. This option’s training inputs are your training scripts, datasets your customized Docker image for Amazon SageMaker.
.
Lastly, the inputs for model deployment are the trained model artefacts, serving scripts and your customized Docker image for Amazon SageMaker.
As previously mentioned, if your use case requires a customized Amazon SageMaker container image, then we recommend implementing a CI/CD pipeline that automates the build, test, and publishing of those container images as part of your MLOps solution.
MLOps Reference Architecture
Our reference architecture demonstrates how you can integrate the Amazon SageMaker container image CI/CD pipeline with your ML (training) pipeline.
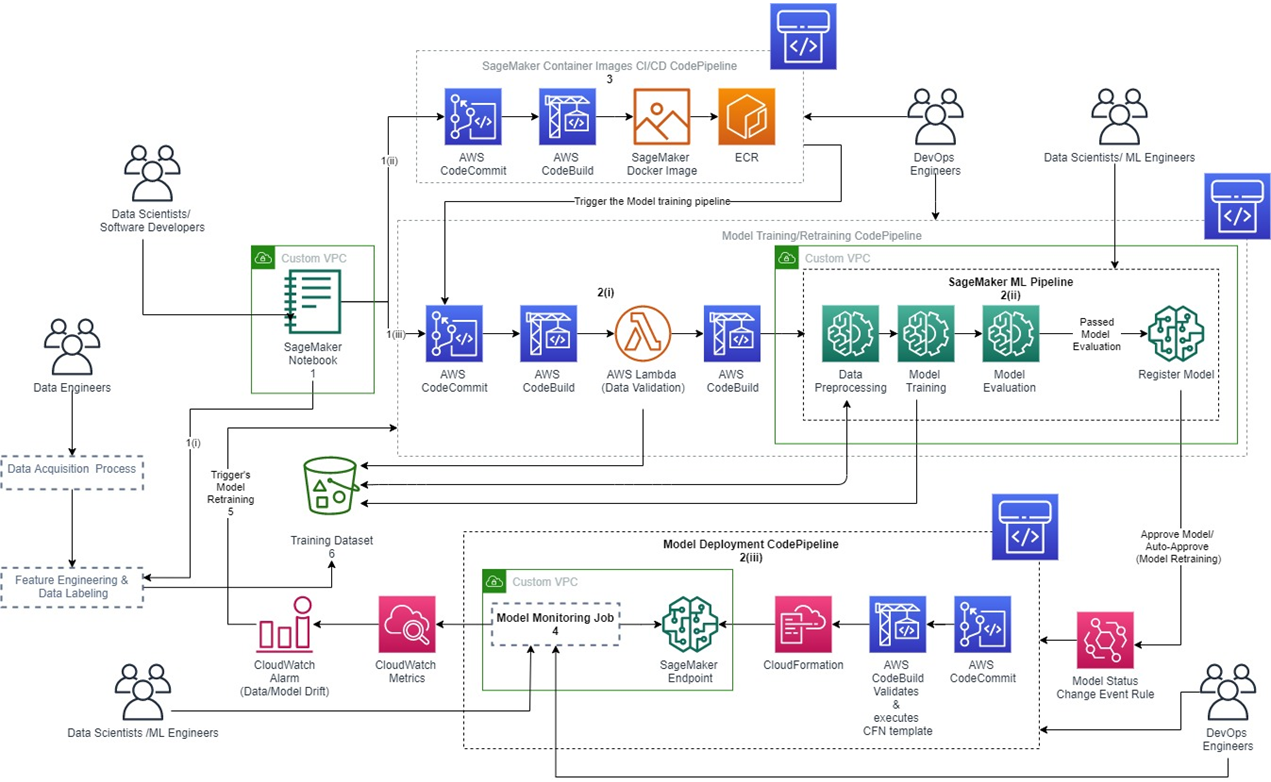
Figure 1 – MLOps reference architecture.
The components of the reference architecture diagram are:
- A secured development environment was implemented using an Amazon SageMaker Notebook Instance deployed to a custom virtual private cloud (VPC), and secured by implementing security groups and routing the notebook’s internet traffic via the custom VPC.
.
Also, the development environment has two Git repositories (AWS CodeCommit) attached: one for the Exploratory Data Analysis (EDA) code and the other for developing the custom Amazon SageMaker Docker container images.
. - An ML CI/CD pipeline made up of three sub-components:
- Data validation step implemented using AWS Lambda and triggered using AWS CodeBuild.
- Model training/retraining pipeline implemented using Amazon SageMaker Pipelines (pipeline-as-code) and executed using CodeBuild.
- Model deployment pipeline that natively supports model rollbacks was implemented using AWS CloudFormation.
Finally, AWS CodePipeline is used to orchestrate the pipeline.
- A CI/CD pipeline for developing and deploying the custom Amazon SageMaker Docker container image. This pipeline automatically triggers the ML pipeline when you successfully push a new version of the SageMaker container image, providing the following benefits:
- Developers and data scientists can thoroughly test and get immediate feedback on the ML pipeline’s performance after publishing a new version of the Docker image. This helps ensure ML pipelines are adequately tested before promoting them to production.
- Developers and data scientists don’t have to manually update the ML pipeline to use the latest version of the customized Amazon SageMaker image when working on the develop git branch. They can branch off the develop branch if they want to use an older version or start developing a new version, which they will merge back to develop branch once approved.
.
- A model monitoring solution implemented using Amazon SageMaker Model Monitor to monitor the production models’ quality continuously.
.
This provides monitoring for the following: data drift, model drift, the bias in the models’ predictions, and drifts in feature attributes. You can start with the default model monitor, which requires no coding.
. - A model retraining implementation that is based on the metric-based model retraining strategy. There are three main retaining strategies available for your model retraining implementation:
- Scheduled: This kicks off the model retraining process at a scheduled time and can be implemented using an Amazon EventBridge scheduled event.
- Event-driven: This kicks off the model retraining process when a new model retraining dataset is made available and can be implemented using an EventBridge event.
- Metric-based: This is implemented by creating a Data Drift CloudWatch Alarm (as seen in Figure 1 above) that triggers your model retraining process once it goes off, fully automating your correction action for a model drift.
- A data platform implemented using Amazon S3 buckets with versioning enabled.
. - A model governance framework, which is not obvious from the architectural diagram and is made of the following components:
- A model registry for versioning and tracking the trained model artefacts, implemented using Amazon SageMaker Model Registry.
- Dataset versioning implemented using Amazon S3 bucket versioning.
- ML workflow steps auditability, visibility, and reproducibility implemented using Amazon SageMaker Lineage Tracking.
- Secured trained model artefacts implemented using AWS Identity and Access Management (IAM) roles to ensure only authorized individuals have access.
MLOps Solution Implementation Strategy
We recommend using Amazon SageMaker Projects to create your end-to-end MLOps solutions. This helps ensure you standardize the ML development processes across the organization, enforce compliance, and simplify and speed up onboarding new ML projects.
Decouple the network layer of your MLOps solution and create a template to provision the rest of the resources you deem as core components for the MLOps solutions in your organization. Then, publish it in AWS Service Catalog as an Amazon SageMaker Project.
Alternately, you can use the Amazon SageMaker-provided templates for your initial MLOps setup and extend them to meet your needs. However, you may run into some limitations when integrating it with your network layer and other existing AWS infrastructure.
If you intend to either use Amazon SageMaker Studio Notebooks or Notebook Instances, ensure they are attached to a custom VPC to help improve your development environment’s security. If you’re using Notebook Instances, consider using AWS Service Catalog to implement your development environments as self-service to help enforce compliance and improve security.
Example Case Studies
Containerized ML, Model Monitoring, and Automation
A car manufacturing company wanted a scalable translation service that could host multiple language models concurrently with model monitoring capabilities. In addition, the Machine Learning Development Cycle (MLDC) processes had to be fully automated.
It was not optimal to deploy the models to Amazon SageMaker endpoints, so the models were packaged as Docker containers and deployed to Amazon Elastic Kubernetes Service (Amazon EKS). The feedback collected from the model monitoring implementation was used in qualitative analysis to help improve future training datasets.
AWS Developer Tools were used to automate the MLDC processes. The scalability capabilities of Kubernetes made it possible to scale the translation service to translate over 4 million characters.
Serverless, Model Monitoring, and Automation
A finance company was looking for a fast and secure way to extract value from its data, previously managed on-premises with a classic data warehouse approach. The solution had to be cloud-based, flexible, and scalable with advanced predictive and prescriptive analytics pipelines.
Reply delivered an automated serverless inference pipeline (ETL + model prediction) implemented using AWS Glue, Lambda functions, and Amazon SageMaker endpoints with a custom model monitoring solution that alerted on model performance or data quality issues.
This flexible platform could scale to support the development and running of an unlimited number of predictive ML models to serve many internal and external users.
Model Governance and Automation
A retail company wanted to improve the working practices of its data science team. Their MLDC processes were manual, causing avoidable human errors and introducing inconsistencies, slowing down the model development lifecycle. In addition, they used Excel spreadsheets to track ML experiments and wanted a more straightforward solution.
Reply implemented a model governance framework using MLflow to track ML experiments and ensured access to trained models was granted using the Principle of Least Privilege (PoLP).
A feature store was also implemented using Amazon Redshift to maximize feature reuse and the MLDC processes were standardized and automated using Amazon SageMaker, IaC, and Jenkins.
Conclusion
In this post, we have demonstrated how you can “glue” the various components of MLOps together to build an MLOps solution using AWS managed services. This can help you with faster ML adoption, productionization, and scaling of ML in your organization to accelerate time to business value from all your ML projects.
The end-to-end automation of the ML lifecycle steps speeds up ML experiments and improves the efficiency of your data science team. Also, it introduces consistency to your ML processes and, coupled with the model governance framework implementation, makes it easy to repeat those processes.
You can use the feedback from the model monitoring solution to continuously improve the quality of the models. Last but not least, it will foster collaboration between the different teams responsible for the various components of the solution.
AWS managed services have scalability built into them. However, to ensure your MLOps solutions are secure, cost-effective, reliable, and perform efficiently, use the AWS Machine Learning Lens, part of the AWS Well-Architected Framework, in your design and implementation.
Finally, please contact Data Reply if you need any help with productionization, or with implementing a secure, scalable, and robust MLOps solution in AWS. Data Reply has developed a MLOps Maturity/Opportunity Framework that can help you develop an MLOps strategy and roadmap for MLOps implementation.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
Reply – AWS Partner Spotlight
Reply is an AWS Premier Consulting Partner that specializes in the design and implementation of solutions based on new communication channels and digital media.
Contact Reply | Partner Overview | AWS Marketplace
*Already worked with Reply? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.