Artificial Intelligence
Automated model refresh with streaming data
In today’s world, being able to quickly bring on-premises machine learning (ML) models to the cloud is an integral part of any cloud migration journey. This post provides a step-by-step guide for launching a solution that facilitates the migration journey for large-scale ML workflows. This solution was developed by the Amazon ML Solutions Lab for customers with streaming data applications (e.g., predictive maintenance, fleet management, autonomous driving). Some of the AWS services used in this solution include Amazon SageMaker, which is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy ML models quickly, and Amazon Kinesis, which helps with real-time data ingestion at scale.
Being able to automatically refresh ML models with new data can be of high value to any business when an ML model drifts. Amazon SageMaker Model Monitor continuously monitors the quality of Amazon SageMaker ML models in production. It enables you to set alerts for when deviations in the model quality occur. The solution presented in this post provides a model refresh architecture that is launched with one-click via an AWS CloudFormation template, and enables capabilities on the fly. You can quickly connect your real-time streaming data via Kinesis, store the data on Amazon Redshift, schedule training and deployment of ML models using Amazon EventBridge, orchestrate jobs with AWS Step Functions, take advantage of AutoML capabilities during model training via AutoGluon, and get real-time inference from your frequently updated models. All this is available in a matter of few minutes. The CloudFormation stack creates, configures, and connects the necessary AWS resources.
The rest of the post is structured as follows:
- Overview of the solution and how the services and architecture are set up
- Details of data ingestion, automated and scheduled model refresh, and real-time model inference modules
- Instructions on how to launch the solution on AWS via a Cloud Formation template
- Cost aspects
- Cleanup instructions
Solution overview
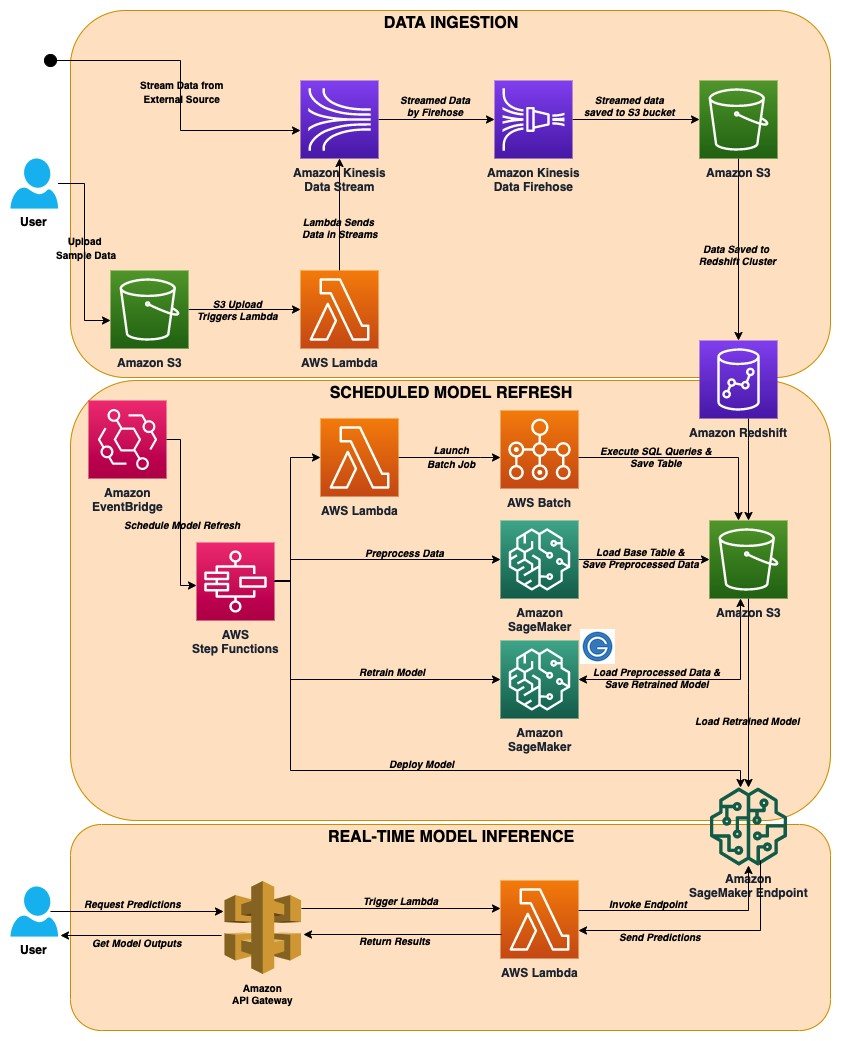
The following diagram depicts the solution architecture, which contains three fully integrated modules:
- Data ingestion – Enables real-time data ingestion from either an IoT device or data uploaded by the user, and real-time data storage on a data lake. This functionality is specifically tailored for situations where there is a need for storing and organizing large amounts of real-time data on a data lake.
- Scheduled model refresh – Provides scheduling and orchestrating ML workflows with data that is stored on a data lake, as well as training and deployment using AutoML capabilities.
- Real-time model inference – Enables getting real-time predictions from the model that is trained and deployed in the previous step.
In the following sections, we provide details of the workflow and services used in each module.
Data ingestion
In this module, data is ingested from either an IoT device or sample data uploaded into an S3 bucket. The workflow is as follows:
- The streaming option via data upload is mainly used to test the streaming capability of the architecture. In this case, a user uploads a sample CSV data into an Amazon Simple Storage Service (Amazon S3) bucket. Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance.
- Uploading the data triggers an AWS Lambda function. Lambda lets you run code without provisioning or managing servers. You pay only for the compute time you consume.
- When the Lambda function is triggered, it reads the data and sends it in streams to Amazon Kinesis Data Streams. Kinesis Data Streams is a massively scalable and durable real-time data streaming service. Alternatively, an external IoT device can also be connected directly to Kinesis Data Streams. The data can then be streamed via Kinesis Data Streams.
- The Kinesis streaming data is then automatically consumed by Amazon Kinesis Data Firehose. Kinesis Data Firehose loads streaming data into data lakes, data stores, and analytics services. It’s a fully managed service that automatically scales to match the throughput of your data and requires no ongoing administration. Data captured by this service can optionally be transformed and stored into an S3 bucket as an intermediate process.
- The stream of data in the S3 bucket is loaded into an Amazon Redshift cluster and stored in a database. Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. The data warehouse is a collection of computing resources called nodes, which are organized into a group called a cluster. Each cluster runs an Amazon Redshift engine and contains one or more databases.
Scheduled model refresh
In this module, you can schedule events using EventBridge, which is a serverless event bus that makes it easy to build event-driven applications. In this solution, we use EventBridge as a scheduler to regularly run the ML pipeline to refresh the model. This keeps the ML model up to date.
The architecture presented in this post uses Step Functions and Lambda functions to orchestrate the ML workflows from data querying to model training. Step Functions is a serverless function orchestration service that makes it easy to sequence Lambda functions and multiple AWS services into business-critical applications. It reduces the amount of code you have to write by providing visual workflows to enable fast translation of business requirements into technical requirements. Additionally, it manages the logic of your application by managing state, checkpoints, and restarts, as well as error handing capabilities such as try and catch, retry, and rollback. Basic primitives such as branching, parallel execution, and timeouts are also implemented to reduce repeated code.
In this architecture, the following subsequent steps are triggered within each state machine:
- AWS Batch to run queries to Amazon Redshift to ETL data – This architecture triggers and controls an AWS Batch job to run SQL queries on the data lake using Amazon Redshift. The results of the queries are stored on the specified S3 bucket. Amazon Redshift is Amazon’s data warehousing solution. With Amazon Redshift, you can query petabytes of structured and semi-structured data across your data warehouse, operational database, and your data lake using standard SQL.
- Data preprocessing using Amazon SageMaker – Amazon SageMaker Processing is a managed data preprocessing solution within Amazon SageMaker. It processes the raw extract, transform, and load (ETL) data and makes it ingestible by ML algorithms. It launches a processing container, pulls the query results from the S3 bucket, and runs a custom preprocessing script to perform data processing tasks such as feature engineering, data validation, train/test split, and more. The output is then stored on the specified S3 bucket.
- Training and deploying ML models using Amazon SageMaker – This step in the architecture launches an ML training job using the AutoGluon Tabular implementation available through AWS Marketplace to train on the processed and transformed data, and then store the model artifacts on Amazon S3. It then deploys the best model trained via an automatic ML approach on an Amazon SageMaker endpoint.
Amazon SageMaker lets you build, train, and deploy ML models quickly by removing the heavy lifting from each step of the process.
AutoGluon is an automatic ML toolkit that enables you to use automatic hyperparameter tuning, model selection, and data processing. AutoGluon Tabular is an extension to AutoGluon that allows for automatic ML capabilities on tabular data. It’s suitable for regression and classification tasks with tabular data containing text, categorical, and numeric features. Accuracy is automatically boosted via multi-layer stack ensembling, deep learning, and data-splitting (bagging) to curb over-fitting.
AWS Marketplace is a digital catalog with software listings from independent software vendors that make it easy to find, test, buy, and deploy software that runs on AWS. The AWS Marketplace implementation of AutoGluon Tabular allows us to treat the algorithm as an Amazon SageMaker built-in algorithm, which speeds up development time.
Real-time model inference
The inference module of this architecture launches a REST API using Amazon API Gateway with Lambda integration, allowing you to immediately get real-time inference on the deployed AutoGluon model. The Lambda function accepts user input via the REST API and API Gateway, converts the input, and communicates with the Amazon SageMaker endpoint to obtain predictions from the trained model.
API Gateway is a fully managed service that makes it easy to create, publish, maintain, monitor, and secure APIs at any scale. It also provides tools for creating and documenting web APIs that route HTTP requests to Lambda functions.
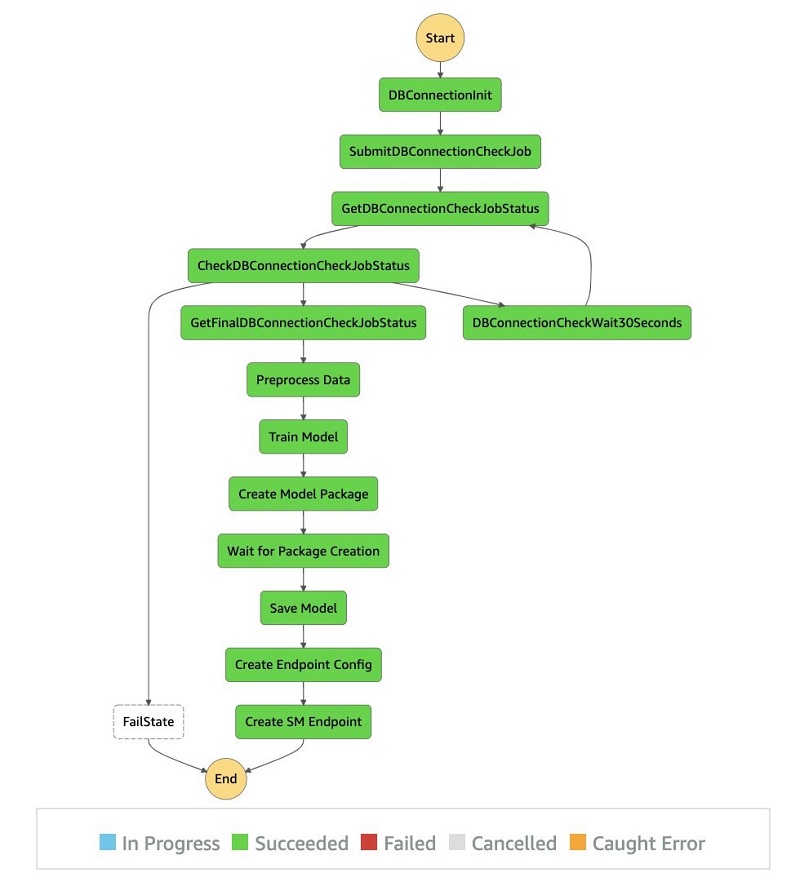
The following diagram depicts the steps that are taken for an end-to-end run of the solution, from a task orchestration point of view. The graph indicator is available on the Step Functions console.
Launching the CloudFormation template
The following section explains the steps for launching this solution.
Before you get started, make sure you have the following:
- Access to an AWS account
- Permissions to create a CloudFormation stack
- Permissions to create an AWS Identity and Access Management (IAM) role and other AWS resources
Choose Launch Stack and follow the steps to create all the AWS resources to deploy the solution. This solution is deployed in the us-east-1 Region.
![]()
After a successful deployment, you can test the solution using sample data.
Testing the Solution
To demonstrate the capabilities of the solution, we have provided an example implementation using stocks data. The dataset consists of around 150,000 observations from the most popular stocks being bought and sold, with columns (ticker_symbol, sector, change, and price). The ML task is regression, and the target column price is a continuous variable. The following example shows how to start streaming such data using the data ingestion module; how to schedule an automated ML training and deployment with the scheduled model refresh module; and how to predict a stock price by providing its ticker symbol, sector, and change information using the inference module.
Note: This post is for demonstration purposes only. It does not attempt to build a viable stock prediction model for real world use. Nothing in this post should be construed as investment advice.
Before starting the testing process, you need to subscribe to AutoGluon on AWS Marketplace.
- Choose Continue to Subscribe.
- Choose Accept Offer.
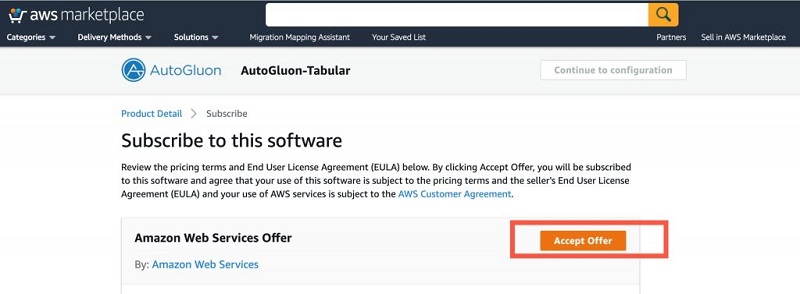
- Choose Continue to configuration.
- For Software version, choose your software version.
- For Region, choose your Region.
- Choose View in Amazon SageMaker.
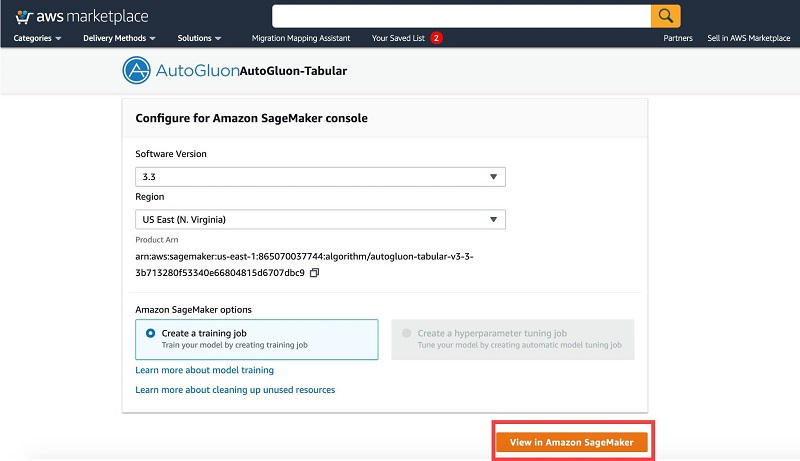
You’re redirected to the Amazon SageMaker console.
Data ingestion from streaming data
You can use an Amazon SageMaker notebook instance or an Amazon Elastic Compute Cloud (Amazon EC2) instance to run the following commands. For instructions in Amazon SageMaker, see Create a Notebook Instance. In the following code, replace <account-id> with your AWS account and <region> with your current Region, which for this post is us-east-1.
- Copy the data and other artifacts of the solution in the newly created input S3 bucket by running the following command:
On the Amazon S3 console, or using the AWS Command Line Interface (AWS CLI), modify the contents of the unload SQL script by replacing the <region> and <account-id> entries, and re-upload it to Amazon S3. The file is located at s3://model-refresh-input-bucket-<region>-<account-id>/model-refresh/sql/script_unload.sql. It stores a script that is used to copy the contents of the stock_table from the Amazon Redshift database into the newly created S3 bucket. This is used to train and evaluate a model. See the following code:
- On the Amazon Redshift console, create a new table within the newly created Amazon Redshift cluster named model-refresh-cluster.
- Connect to the database dev within the cluster with the following credentials (you can change the password later because this is automatically created from the CloudFormation template):
Database: dev
Username: awsuser
Password: Password#123 - Create a table named stock_table within the database. You can also change the table name and schema later. You can run the following command in the query editor after connecting to the Amazon Redshift cluster:
- Copy the data from the input bucket to the newly created Amazon Redshift table. The IAM role is the role associated with the cluster that has at least Amazon S3 read access. The following command is a query and is run via the Amazon Redshift query editor:
- Check if the data is copied to the database. When you run the following SQL, you should get 153580 rows:
The next step is to test if the data streaming pipeline is working as expected.
- Copy a sample CSV data using the CLI from the input bucket into the newly created output S3 bucket named model-refresh-output-bucket-<region>-<account-id>. This sample CSV file only contains 10 observations for test purposes.
After it’s copied to the S3 bucket, the streaming functionality is triggered.
After 3–5 minutes, check if the streamed data is loaded into the Amazon Redshift table.
- On the Amazon Redshift console, run the following SQL statement to see the number of rows added to the table. 10 rows should be added from the previous one.
Scheduling automated ML training and deployment
In this section, you schedule the automated model training and deployment.
- On the EventBridge console, choose Create Rule.
- Enter a name for the role.
- For Define a pattern, choose Schedule.
- Define any frequency (such as 1 per day).
- Leave the event bus as its default.
- For the target, select Step Functions step machine.
- Choose model-refresh-state-machine.
This points the scheduler to the state machine that trains and deploys the model.
To configure the input, you need to pass the required parameters for the state machine.
- Enter the value of
ExecutionInputfrom the CloudFormation stack outputs. The JSON looks like the following code:
You can track the progress of the model refresh by navigating to the Step Functions console and choosing the corresponding state machine. A sample of the visual workflow is shown in the Real-time model inference section of this post.
Inference from the deployed model
Let’s test the deployed model using Postman, which is an HTTP client for testing web services. Download the latest version.
During the previous step, an endpoint is created and is available for getting inference. You need to update the Lambda function for inference with this new endpoint.
- On the Amazon SageMaker console, choose Endpoints.
- Copy the name of the endpoint you created.
- On the Lambda console, choose InferenceLambdaFunction.
- Under Environment variables, update the
ENDPOINT_NAMEvariable to the new endpoint name.
When you deployed your API Gateway, it provided the invoke URL that looks like the following:
It follows the format:
You can locate this link on the API Gateway console under Stages.
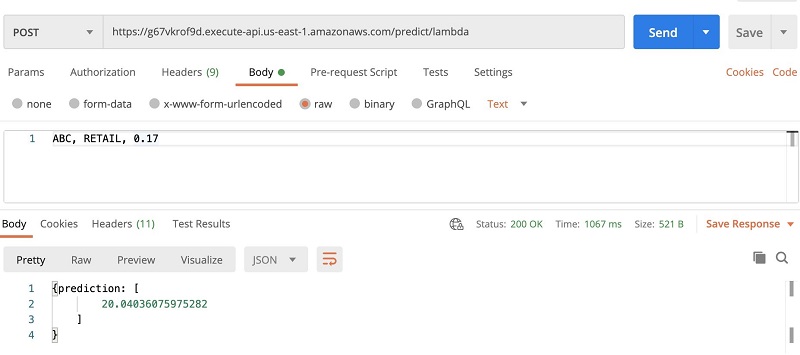
- Enter the invoke URL into Postman.
- Choose Post as method.
- On the Body tab, enter the test data.
- Choose Send to see the returned result.
Customizing the solution
In this post, we use Amazon Redshift, which achieves efficient storage and optimum query performance through a combination of massively parallel processing, columnar data storage, and targeted data compression encoding schemes. Another option for the ETL process is AWS Glue, which is a fully managed ETL service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores. You can easily use AWS Glue instead of Amazon Redshift by replacing a state on the state machine with one for AWS Glue. For more information, see Manage AWS Glue Jobs with Step Functions.
Similarly, you can add several components (such as an A/B testing module) to the state machine by editing the JSON text. You can also bring your own ML algorithm and use it for training instead of the AutoGluon automatic ML.
Service costs
Amazon S3, Lambda, Amazon SageMaker, Amazon API Gateway and Step Functions are included in the AWS Free Tier, with charges for additional use. For more information, see the following pricing pages:
EventBridge is free for AWS service events, with charges for custom, third-party, and cross-account events. For more information, see Amazon EventBridge pricing.
Kinesis Data Firehose charges vary based on amount of data ingested, format conversion, and VPC delivery. Kinesis Data Streams charges vary based on throughput and number of payload units. For more information, see Amazon Kinesis Data Firehose pricing and Amazon Kinesis Data Streams pricing.
Amazon Redshift charges vary by the AWS Region and compute instance used. For more information, see Amazon Redshift pricing.
There is no additional charge for AWS Batch. You only pay for the AWS resources you create to store and run your batch jobs.
Cleaning up
To avoid recurring charges, delete the input and output S3 buckets (model-refresh-input-bucket-<region>-<account-id> and model-refresh-output-bucket-<region>-<account-id>).
After the buckets are successfully removed, delete the created CloudFormation stack. Deleting a CloudFormation stack deletes all the created resources.
Conclusion
This post demonstrated a solution that facilitates cloud adoption and migration of existing on-premises ML workflows for large-scale data. The solution was launched via a CloudFormation template, and provided efficient ETL processes to capture high-velocity streaming data, easy and automated ways to build and orchestrate ML algorithms, and built endpoints for real-time inference from the deployed model.
If you’d like help accelerating your use of ML in your products and processes, please contact the Amazon ML Solutions Lab.
About the Authors

Mehdi Noori is a Data Scientist at the Amazon ML Solutions Lab, where he works with customers across various verticals, and helps them to accelerate their cloud migration journey, and to solve their ML problems using state-of-the-art solutions and technologies.
 Yohei Nakayama is a Deep Learning Architect at the Amazon Machine Learning Solutions Lab, where he works with customers across different verticals accelerate their use of artificial intelligence and AWS cloud services to solve their business challenges. He is interested in applying ML/AI technologies to space industry.
Yohei Nakayama is a Deep Learning Architect at the Amazon Machine Learning Solutions Lab, where he works with customers across different verticals accelerate their use of artificial intelligence and AWS cloud services to solve their business challenges. He is interested in applying ML/AI technologies to space industry.
 Tesfagabir Meharizghi is a Data Scientist at the Amazon ML Solutions Lab where he helps customers across different industries accelerate their use of machine learning and AWS cloud services to solve their business challenges.
Tesfagabir Meharizghi is a Data Scientist at the Amazon ML Solutions Lab where he helps customers across different industries accelerate their use of machine learning and AWS cloud services to solve their business challenges.
 Ninad Kulkarni is a data scientist in the Amazon Machine Learning Solutions Lab. He helps customers adopt ML and AI by building solutions to address their business problems. Most recently, he has built predictive models for sports and automotive customers.
Ninad Kulkarni is a data scientist in the Amazon Machine Learning Solutions Lab. He helps customers adopt ML and AI by building solutions to address their business problems. Most recently, he has built predictive models for sports and automotive customers.