AWS Partner Network (APN) Blog
Integrating SaaS Data Platforms from ISV Partners with AWS Services
By Mehmet Bakkaloglu, Sr. Solutions Architect, AWS
A software-as-a-service (SaaS) data platform typically provides one or more capabilities such as data integration, data cleansing, data transformation, data storage, model integration, analytics, dashboarding, visualization, or machine learning.
A SaaS data platform may run in the account of an independent software vendor (ISV) or a dedicated account provided by the customer. In both of these cases, it’s essential for the SaaS platform to integrate with AWS services running in the customer’s Amazon Web Services (AWS) account.
There are a number of benefits to this, such as:
- Provides customers with a seamless analytics experience.
- Enables customers to use services they are familiar with.
- Gives customers choice of tools to use.
- Allows SaaS vendors to focus on what matters and rapidly take advantage of trusted AI/ML services.
- Prevents data from being locked in the SaaS data platform.
- Depending on service, avoids data duplication by enabling in-place querying.
- Helps build joint solutions and GTM strategies with AWS.
Integration Architecture
AWS has more than 200 services, and when it comes to SaaS data platforms from ISV partners there is a category of services where we see the most adoption in terms of integration. The diagram below shows these services grouped according to their functionality, along with the core components a SaaS data platform may have.
Such a platform may provide a subset or all of these functionalities, and may ingest data from both on-premises and cloud source systems. The focus of this post is on services that complement the functionality of the data platform, rather than on connectors to source systems.
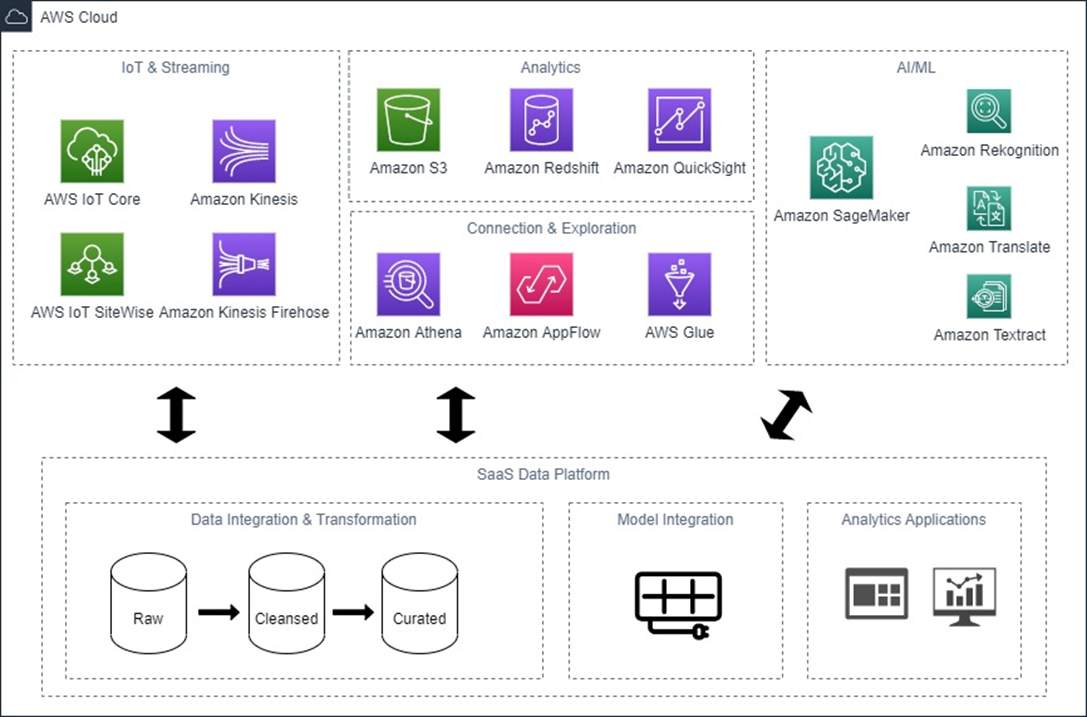
Figure 1 – Integration architecture.
Starting from the AI/ML services, Amazon SageMaker is a powerful platform for end-to-end machine learning (ML) lifecycle, providing a fully managed infrastructure. Meanwhile, AWS AI services are pre-trained models for common use cases based on the same deep learning technology that powers Amazon.com. Integration with these services adds ML functionality to a SaaS platform with little effort, and gives data scientists a unified experience regardless of whether the data is in the SaaS platform or in another system.
Amazon Athena, Amazon AppFlow, and AWS Glue integration enable data that’s in the SaaS platform to be explored, catalogued, and exported for further analytics with AWS services such as Amazon Redshift for data warehousing and Amazon QuickSight for dashboarding and visualization.
Integration with AWS Internet of Things (IoT) services allow building joint solutions between AWS and the ISV that join IoT data with enterprise resource planning (ERP), customer relationship management (CRM), and other data to tackle pressing business problems, as described in this AWS blog post. This can range from predictive maintenance and reducing carbon footprint to improving supply chain resiliency.
Services and Integration Method
In this section, I’ll provide an overview of how the integration with these services can be built with links to successful integration stories from AWS ISV Partners.
Amazon SageMaker
Amazon SageMaker is a broad platform where there can be multiple points of integration.
The first stage in ML model development is data preparation. Amazon SageMaker Data Wrangler simplifies this process by providing data scientists with a visual interface to select, clean, and explore their datasets. The integration from data flow directly to the SaaS platform allows data to be imported for further processing, as shown in the image below. There are a few ways in which this integration can work, including via a JDBC connection.
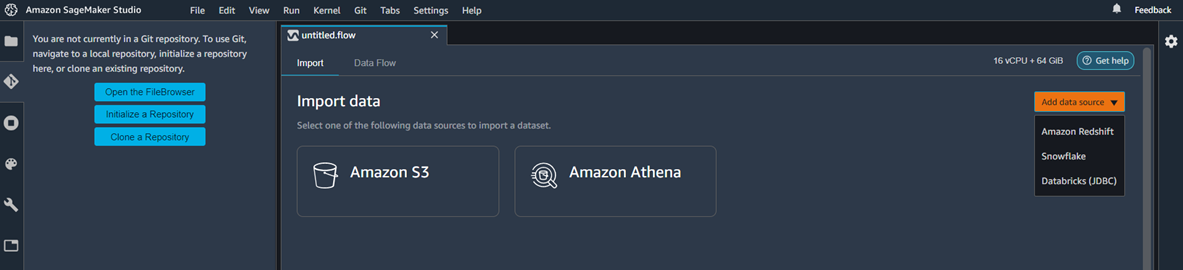
Figure 2 – Amazon SageMaker Data Wrangler Integration.
When it comes to inference, there are multiple options. The inference can be real-time, serverless, asynchronous, or batch transform. When invoking a model deployed to an endpoint, best practice is to seal the backend with an Amazon API Gateway that calls the endpoint via an AWS Lambda function that runs in a protected private network.
Amazon SageMaker Autopilot helps automatically build, train, and tune the best ML model. This is especially powerful to integrate into platforms where building models may be an auxiliary functionality, such as in the case of Snowflake integration where models can be trained and invoked using simple SQL functions. In the case of Domo, the integration is via the console user interface (UI). In cases where, due to governance constraints, SageMaker Autopilot needs to run in a different AWS account, then cross-account access needs to be set up.
Other possible integration points are Amazon SageMaker Feature Store, to create a single source of features that can be used by multiple teams; Amazon SageMaker Model Registry, to create a single source of models and manage versioning; and Amazon Ground Truth, which is a data labelling service.
AWS AI Services
AWS pre-trained AI services are particularly useful to integrate where standard functionality such as language translation, image recognition, or sentiment analysis is required. In such cases, rather than building custom ML models, services such as Amazon Translate, Amazon Rekognition, and Amazon Comprehend can be invoked by simple API calls.
For instance, to extract health data from unstructured medical text developers can call Amazon Comprehend Medical from a Snowflake stored procedure via a Lambda function and get the results back in JSON.
These services also allow new products to be built, as in the case of Anaplan integrating with Amazon Forecast. In addition, these services can be combined to address a specific use case, such as the example where Amazon Textract and Amazon Comprehend are used to provide Intelligent Document Processing (IDP).
Amazon Athena
Amazon Athena is an interactive query service based on Presto. The Athena Federated Query feature allows data in on-premises and cloud source systems to be queried via a simple SQL statement on Athena’s serverless architecture. This is very powerful in that the query can be executed from the AWS Management Console, an Amazon SageMaker Notebook, or via Amazon QuickSight. It can also be used to extract data into a customer’s Amazon Simple Storage Service (Amazon S3) bucket so the data can be used with a wide range of other AWS services.
SaaS vendors can build their own connectors using the Athena Query Federation SDK. This takes the form of two Lambda functions that act as a connector between the Athena engine and SaaS data platform and allow users to access data that is in the SaaS platform as described in this example.
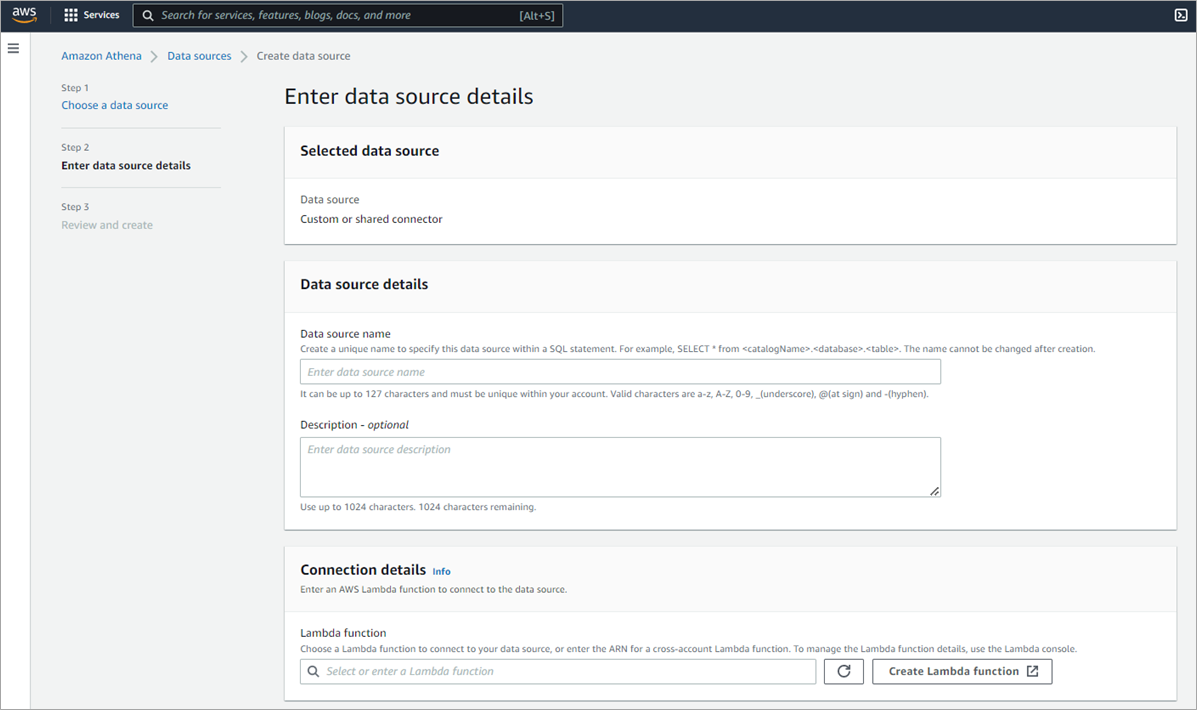
Figure 3 – Amazon Athena Custom Connector data source via Lambda function.
Amazon AppFlow
Athena Federated Query works best for interactive querying and transferring small amounts of data. On the other hand, Amazon AppFlow is a fully managed service for enterprise-scale secure data transfer with no code required. It enables bidirectional integration between SaaS platforms and AWS services such as Amazon S3 and Amazon Redshift.
Salesforce, SAP OData, and Infor Nexus are some of the sources supported. There is also support for Salesforce Private Connect which leverages AWS PrivateLink to transfer data securely between AWS and Salesforce over the AWS private network. Snowflake and Upsolver are examples of SaaS data platforms supported.
The connector for a SaaS platform may be developed by AWS or by the ISV partner. The open-source Custom Connector SDK enables the development of a private, shared, or public connector using Python or Java by ISV Partners. The connector is a Lambda function that acts an intermediary between Amazon AppFlow and the SaaS platform.
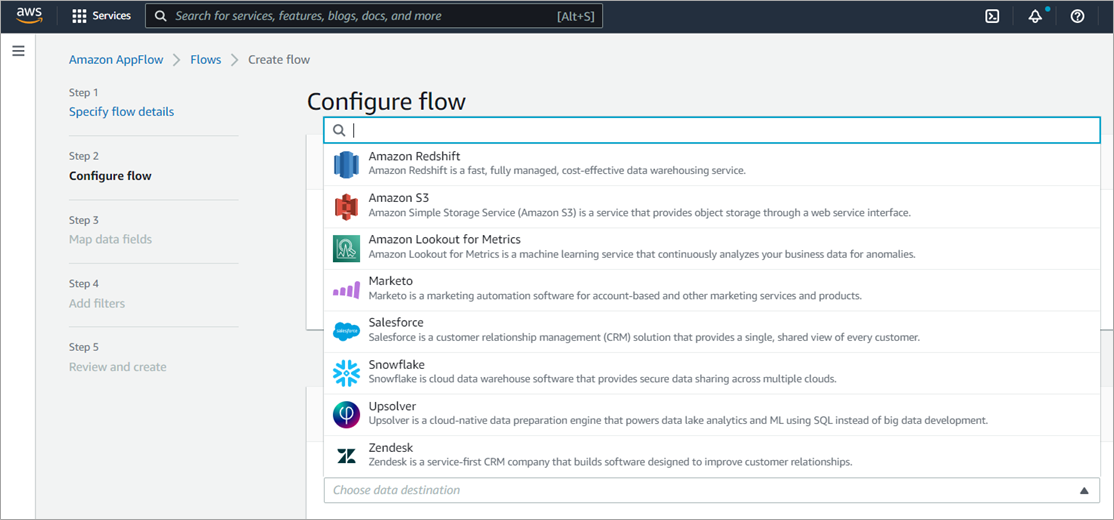
Figure 4 – Amazon AppFlow integration.
AWS Glue
AWS Glue is a serverless data integration service for preparing data for analytics and machine learning. SaaS vendors can build a custom connector based on Athena Federated Query, JDBC, or Apache Spark DataSource. These connectors can also be listed on AWS Marketplace. Snowflake, Splunk, and Cassandra are some of the platforms for which a connector can be purchased. An alternative method for Snowflake is to use a custom connector based on JDBC. For MongoDB Atlas, there’s native support in AWS Glue.
Another point of integration is with AWS Glue Data Catalog. You can use AWS Glue Data Catalog as the central data catalog for the organization, where tables (which are metadata definitions that represent the data) from all data stores are listed. In addition, ISVs can configure AWS Glue Data Catalog to be used as a metastore in place of their Hive metastore as in the case of Starburst.
It’s also possible to extract information from AWS Glue Data Catalog to store in an external catalog such as Collibra, where a JDBC driver which leverages the Amazon Athena JDBC driver under the hoods is utilized.
Figure 5 – AWS Glue Custom Connector.
Amazon QuickSight
Amazon QuickSight can connect to SaaS data sources such as Salesforce, Snowflake, Teradata, and Adobe Analytics out of the box. For other SaaS data platforms, the easiest method currently is via an Athena Federated Query.
The second level of integration is embedding QuickSight dashboards, which is possible with the QuickSight Enterprise edition. The integration can be via an embed code that can be pasted into the application, or via the QuickSight API where authentication is done through an IAM role. Salesforce utilizes the latter method.
One advantage of this approach is that data from both Salesforce and the customer’s AWS account can be displayed in a single dashboard without the need to replicate data, taking advantage of QuickSight’s serverless architecture.
Amazon Redshift
Amazon Redshift can be both a source and destination depending on the SaaS data platform. In the case of Databricks, data can be loaded into Apache Spark SQL DataFrames from Amazon S3 and then gold tables can be queried in place or loaded into Redshift using the Redshift Spectrum to Delta Lake integration. Domo’s Redshift connector retrieves data based on a SQL query.
A number of other partners such as Upsolver, Matillion, and Informatica integrate directly via the Amazon Redshift console. Upsolver low-code data pipelines can be used to stream event data into Redshift via Amazon Kinesis Data Streams, and can also be used to write the stream to a data lake to be queried with Amazon Redshift Serverless. Matillion can be used to rapidly build data pipelines to ingest data into Amazon Redshift.
Figure 6 – Amazon Redshift partner integration.
AWS IoT Services
For a data platform, AWS IoT services are typically a source where having a native connector would accelerate the data ingestion process.
There are multiple ways in which this can be accomplished. Streaming data in real time via Amazon Kinesis Data Firehose is the fastest method. This is a managed service so there’s no need to write an application or manage resources—the data is delivered directly to the destination.
The data can also be batched, compressed, transformed, and encrypted before being loaded into destination system. Integration with a number of SaaS providers has already been built, such as MongoDB Atlas, Splunk, and Datadog. In the case of MongoDB Atlas, it leverages an incoming webhook.
Figure 7 – Amazon Kinesis Data Firehose integration.
A second option is to build a connector to stream data directly from Kinesis Data Streams. Databricks and MuleSoft are two SaaS platforms that have out-of-the-box connectors to Kinesis.
A third option is to get IoT data via AWS IoT Core. Data from AWS IoT Core can be sent to various destinations such as AWS Lambda, Amazon Kinesis Data Stream, Amazon Simple Queue Service (Amazon SQS), or HTTPS endpoint. In the case of Salesforce, a custom connector allows messages from devices to be routed directly to Salesforce IoT Cloud via an AWS IoT Rule with a Salesforce action type. An added benefit of integration with IoT Core is that the communication with devices can be bi-directional.
The fourth method is via AWS IoT SiteWise, which is an asset modelling and time series database. The asset model can be extracted using the API and the asset data can be published to the AWS IoT Core MQTT message broker.
Data can also be streamed through Amazon Managed Streaming for Apache Kafka (Amazon MSK) and ISVs can create a custom plugin which is a set of JAR files containing the connector logic.
Other Services
The services covered in this post are the main AWS services which can be integrated with SaaS data platforms, but it’s not an exhaustive list. There are many other AWS services that can add value to SaaS data platforms.
For instance, Domo’s integration with AWS Data Exchange provides a solution to discover, subscribe to, and access third-party data in the cloud without leaving the platform. With AWS IoT Greengrass, AWS ISV Partners can build and deploy a version of their product to devices to process data or run machine learning models for predictions.
Conclusion
In this post, I covered the main AWS services SaaS data platforms can integrate with to provide customers with a seamless experience and take advantage of AWS services in order to accelerate their drive to meeting their business goals.
I also gave an overview of how those integrations can be built and examples of AWS ISV Partners who have successfully developed these. If you are interested in building such integrations, require further information, or would like help to construct a roadmap for these integrations, please get in touch with your AWS account team.