Amazon Web Services ブログ
Category: Compute

AWS Weekly Roundup: Amazon EC2 M8azn インスタンス、Amazon Bedrock の新しいオープンウェイトモデルなど (2026 年 2 月 16 日)
2021 年に AWS に入社して以来、私は Amazon Elastic Compute Cloud (Am […]

AWS で NVIDIA Cosmos world foundation models を実行
本記事は 2025/11/24 に公開された “Running NVIDIA Cosmos wor […]

BMW Group が AWS 上のエージェンティック検索でペタバイト規模のデータからインサイトを引き出す
BMW Group が AWS 上でエージェント検索ソリューションを構築し、ペタバイト規模のデータからインサイトを引き出す取り組みを紹介します。同社の Cloud Data Hub は 20 PB のデータを保存し、1 日平均 110 TB を取り込んでいますが、従来は専門知識がないユーザーにとってデータ分析が困難でした。AWS Professional Services と協力し、Amazon S3 Vectors、Amazon Bedrock、Strands Agents を組み合わせたソリューションを開発。ハイブリッド検索、網羅的検索、SQL クエリの 3 つのアプローチにより、技術スキルに関係なく自然言語でデータにアクセス可能になりました。サーバーレスアーキテクチャによりコスト効率も実現しています 。

AWS Weekly Roundup: Amazon Bedrock の Claude Opus 4.6、AWS ビルダー ID による Apple でのサインインなど (2026 年 2 月 9 日)
2026 年 2 月 2 日週に行われた注目のリリースとアップデートをご紹介します。これらはすべて、AWS で […]

【寄稿】CO2 排出量可視・削減サービス「e-dash」を支えるサーバーレスアーキテクチャと IaC 戦略
こんにちは、AWS ソリューションアーキテクトの松本 敢大です。 本日は、三井物産発の環境系スタートアップである e-dash 株式会社様が提供する CO2 排出量可視化・削減サービスプラットフォーム「e-dash」のシステム構築事例をご紹介します。e-dash 株式会社 プロダクト開発部部長の佐藤様、プロダクト開発部の伊藤様、竹内様に、AWS を活用したモダンなアプリケーション開発の取り組みについてお話を伺いました。

AI を活用したゲーム制作: 静的なコンセプトからインタラクティブなプロトタイプへ
AI を活用することで、ゲーム開発の初期段階でコンセプトをインタラクティブにし、数分でプレイ可能なプロトタイプを作成できます。AWS re:Invent 2025 で紹介する Agentic Arcade は、マルチエージェントオーケストレーション、プログラマティックアセット生成、セマンティック検索を組み合わせ、開発サイクルの早い段階で創造的な方向性を探索し検証する方法を示します。

VAMS における NVIDIA Isaac Lab を使用した GPU アクセラレーション型ロボットシミュレーショントレーニング
オープンソースの Visual Asset Management System (VAMS) が NVIDIA Isaac Lab との統合により、ロボットアセット向けの GPU アクセラレーション強化学習に対応しました。このパイプラインでアセット管理ワークフローから直接 RL ポリシーのトレーニングと評価ができ、AWS Batch でスケーラブルな GPU コンピューティングを活用できます。
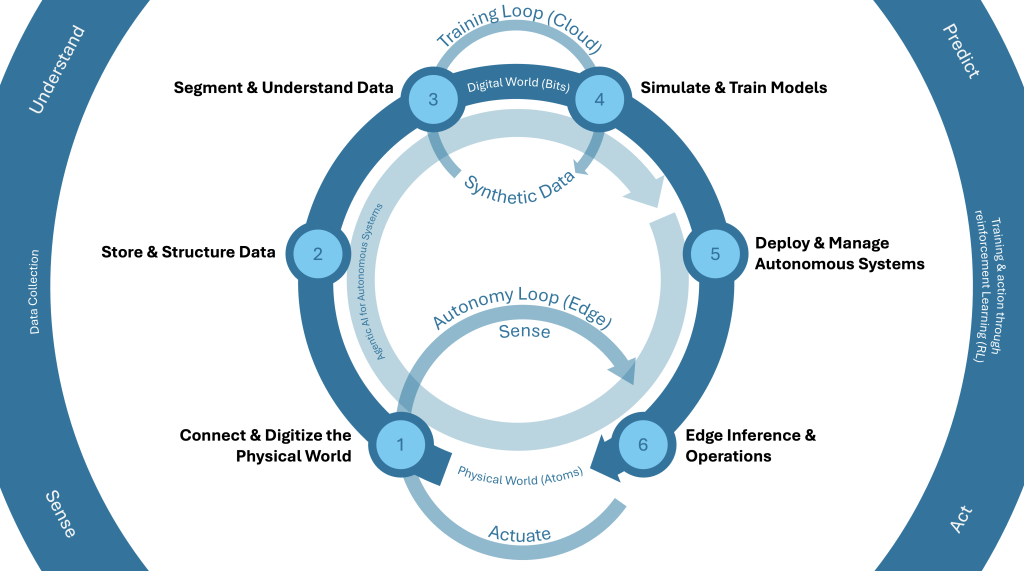
フィジカル AI: 自律型インテリジェンスに向けた次なる基盤を築く
AWS の Physical AI フレームワークは、デジタル世界と物理世界を橋渡しする自律システムを構築するための包括的なアプローチです。物理世界の接続とデジタル化、データの保存と構造化、データのセグメント化と理解、シミュレーションとトレーニング、デプロイと管理、エッジ推論と運用の 6 つの相互接続された機能を通じて、継続的な学習サイクルを作り出し、自律型経済への移行を支援します。

最大 22.8 TB のローカル NVMe ストレージを備えた Amazon EC2 C8id、M8id、および R8id インスタンスの一般提供が開始されました
2025 年、AWS は Amazon Elastic Compute Cloud (Amazon EC2) […]

AWS Weekly Roundup: Amazon Bedrock エージェントワークフロー、Amazon SageMaker プライベート接続など (2026 年 2 月 2 日)
2026 年 1 月 26 日週、私たちはラバ祭りを祝いました。これは、旧正月まで残りわずかであることを告げる […]