Category: Amazon Redshift
Amazon Redshift – Now Broadly Available
We announced Amazon Redshift, our fast and powerful, fully managed, petabyte-scale data warehouse service, late last year (see my earlier blog post for more info). As we often do with complex new services, we started out by making a limited preview version of Redshift available by invitation.
Today I am happy to announce that Amazon Redshift is now available to all customers, and that you can get started with it today by provisioning a cluster from the AWS Management Console. You can start small (which, at data warehouse scale, means a couple of hundred gigabytes), and scale up to a petabyte or more as you discover what Amazon Redshift can do for you.
We’ve designed Amazon Redshift to be cost-effective, easy to use, and flexible.
Cost Effective
We designed Amazon Redshift to deliver 10 times the performance at 1/10th the cost of the on-premises data warehouses that are commonly used today. We used a number of techniques to do this including columnar data storage, advanced compression, and high-performance disk and network I/O.
You can use the High Storage Extra Large (15 GiB of RAM, 4.4 ECU, and 2 TB of local attached compressed user data) for $0.85 per hour or the High Storage Eight Extra Large (120 GiB of RAM, 35 ECU, and 16 TB of local attached user data) for $6.80 per hour. With either instance type, you pay an effective price of $3,723 per terabyte per year for storage and processing. One Year and Three Year Reserved Instances are also available, pushing the annual cost per terabyte down to $2,190 and $999, respectively.
We’re starting out in US East (Northern Virginia), with plans to expand to other AWS Regions in the coming months.
Easy to Use
As I noted earlier, you can manage Redshift from the AWS Management Console. Here are some screen shots of some common operations, starting with provisioning:
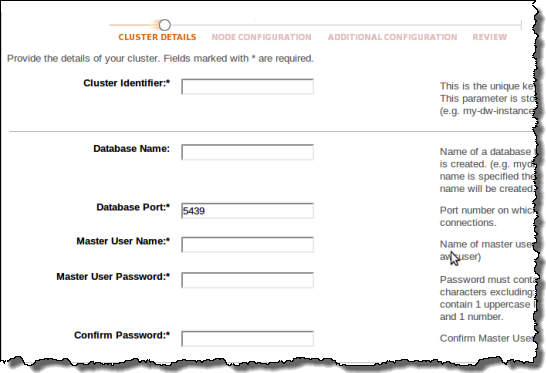
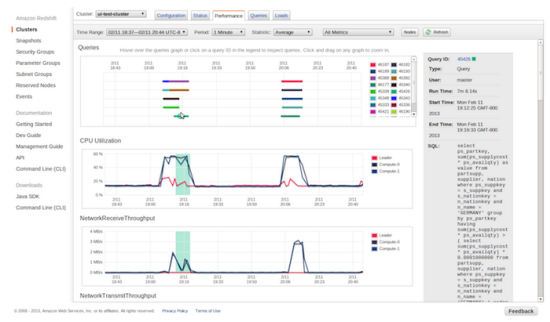
You can use a variety of graphs and visualizations to monitor the status and performance of each of your clusters, as well as the resources consumed by each of your queries:
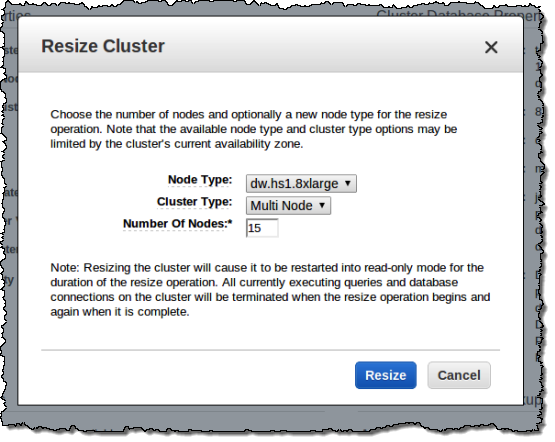
You can easily resize a cluster, adding or removing nodes or changing the instance type, as well (your cluster will be in read-only mode for the duration of the operation):
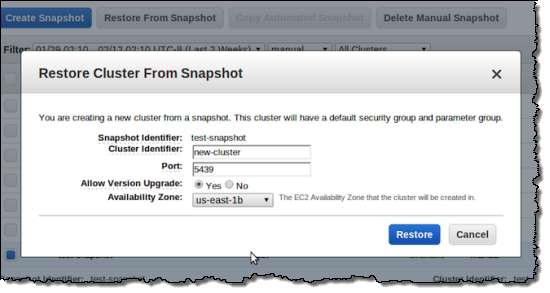
You can create a snapshot, and then restore the snapshot to a new cluster, all with a couple of clicks:
Flexible
Redshift integrates nicely with a number of other AWS services. You can load data into a cluster from Amazon S3 or Amazon DynamoDB. You can also use the AWS Data Pipeline to load data from Amazon RDS, Amazon Elastic MapReduce, and your own Amazon EC2 data sources.
Time to Get Started
As always, we have plenty of information to get you started:
- Redshift Home Page
- Redshift Getting Started Guide
- Redshift Partner Page
- Amazon Redshift Presentation from AWS re:Invent
- Amazon Redshift for Business Intelligence
We’ve put together a new video with more information about Amazon Redshift:
A number of our technology partners have been working hard to test their big data and analytics products with Redshift. Many of these products are now available in the AWS Marketplace:
Some Reviews & Commentary
The first reviews are starting to show up! Here are a few to give you an outside perspective on Amazon Redshift:
- Full360: AWS Redshift First Impressions
- Watch out HP, IBM, Teradata, Oracle: Amazon Redshift is here
— Jeff;