Category: Amazon Redshift
AWS CloudFormation Adds Support for Redshift and More
My colleague Chetan Dandekar has a lot of good news for AWS CloudFormation users!
— Jeff;
AWS CloudFormation now supports Amazon Redshift. We have recently enhanced our support for other AWS resources as well.
What is CloudFormation?
AWS CloudFormation simplifies provisioning and management of a wide range of AWS resources, from EC2 and VPC to DynamoDB. CloudFormation enables users to model and version control the architecture they want in the CloudFormation template files. An architecture could be as simple as a single EC2 instance or as complex as a distributed database or the entire VPC configuration of an enterprise. (See CloudFormation sample templates). The CloudFormation service can automatically create the desired architecture (CloudFormation stacks) from the template files, without burdening the users with writing complex provisioning code.
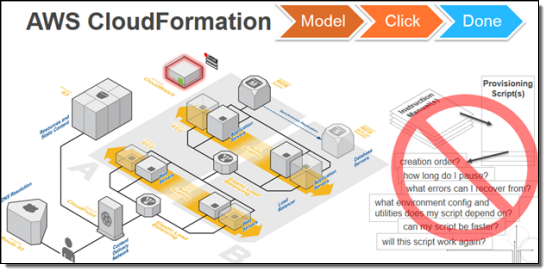
CloudFormation speeds up provisioning by parallelizing creation and updating of stacks. The CloudFormation API lets you automate AWS provisioning and also gives you the ability to integrate it with the development and system management tools that you already use.
The CloudFormation templates can also be used to standardize and package products for broader users to use. (For example, an administrator can create a standard VPC configuration template for an entire developer team to use, and an ISV can package a distributed database configuration for its client to provision on AWS).
Amazon Redshift Support
![]() Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse service. You can now launch and manage Redshift clusters using CloudFormation. You can also document, version control, and share your Redshift configuration using CloudFormation templates. Here is a sample CloudFormation template provisioning a Redshift cluster.
Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse service. You can now launch and manage Redshift clusters using CloudFormation. You can also document, version control, and share your Redshift configuration using CloudFormation templates. Here is a sample CloudFormation template provisioning a Redshift cluster.
CloudFormation also supports the other AWS database services: Amazon RDS, Amazon DynamoDB, Amazon SimpleDB and Amazon ElastiCache.
Other Additions
Support for the following AWS features was added in early 2014:
- Auto Scaling scheduled actions and block device properties
- DynamoDB local and global secondary indexes
- SQS dead letter queue (DLQ)
- Updating Elastic Beanstalk applications
- Updating SQS queues and queue policy
- Updating S3 buckets and bucket policies
- Up to 60 parameters and 60 outputs in a CloudFormation template
Read the CloudFormation release notes for additional information on these changes.
To learn more about CloudFormation, please visit the CloudFormation detail page, documentation or watch this introductory video. We have a large collection of sample templates that makes it easy to get started with CloudFormation within minutes.
Faster & More Cost-Effective SSD-Based Nodes for Amazon Redshift
Amazon Redshift provides customers with fast, fully managed, SQL-based data warehousing in the AWS Cloud at a tenth the price of traditional solutions. In previous blog posts, weve talked about Redshifts launch, global expansion, and new features.
Today we are making Redshift faster and more cost-effective by adding Dense Compute Nodes. This new SSD-based storage option is available in two sizes:
- Large – 160 GB of SSD storage, 2 Intel Xeon E5-2670v2 virtual cores, and 15 GiB of RAM.
- Eight Extra Large – 2.56 TB of SSD storage, 32 Intel Xeon E5-2670v2 virtual cores, and 244 GiB of RAM.
The Dense Compute nodes feature a high ratio of CPU power, RAM, and I/O performance to storage, making them ideal hosts for data warehouses where high performance is essential. You can start small, with a single Large node for $0.25/hour, and scale all the way up to a cluster with thousands of cores, terabytes of RAM, and hundreds of terabytes of SSD storage.
If you have less than 500 GB of compressed data, your lowest cost and highest performance option is Dense Compute. Above that, if you care primarily about performance, you can stay with Dense Compute and scale all the way up to clusters with thousands of cores, terabytes of RAM and hundreds of terabytes of SSD storage. Or, at any point, you can use switch over to our existing Dense Storage nodes that scale from terabytes to petabytes for little as $1,000 / TB / Year. Amazon Redshifts resize feature lets you easily change node types or cluster sizes with a few clicks in the Console:

All of the features that have made Redshift such a big hit are available on the Dense Compute nodes including fast provisioning, automatic patching, continuous backups to Amazon S3, fast restores, failure handling, cross-region disaster recovery, and encryption of data at rest and in transit.
On-Demand prices for a single Large Dense Compute node start at just $0.25 per hour in the US East (Northern Virginia) Region; this drops down to an effective price of $0.10 (ten cents!) per hour with a Three Year Reserved Instance. Like the Dense Storage nodes, the new Dense Compute nodes are available in the following AWS Regions:
- US East (Northern Virginia)
- US West (Oregon)
- EU (Ireland)
- Asia Pacific (Singapore)
- Asia Pacific (Tokyo)
- Asia Pacific (Sydney)
The new nodes are available today and you can use them to create your data warehouse now!
— Jeff;
Cross-Region Read Replicas for Amazon RDS for MySQL
You can now create cross-region read replicas for Amazon RDS database instances!
This feature builds upon our existing support for read replicas that reside within the same region as the source database instance. You can now create up to five in-region and cross-region replicas per source with a single API call or a couple of clicks in the AWS Management Console. We are launching with support for version 5.6 of MySQL.
Use Cases
You can use this feature to implement a cross-region disaster recovery model, scale out globally, or migrate an existing database to a new region:
Improve Disaster Recovery – You can operate a read replica in a region different from your master database region. In case of a regional disruption, you can promote the replica to be the new master and keep your business in operation.
Scale Out Globally – If your application has a user base that is spread out all over the planet, you can use Cross Region Read Replicas to serve read queries from an AWS region that is close to the user.
Migration Between Regions – Cross Region Read Replicas make it easy for you to migrate your application from one AWS region to another. Simply create the replica, ensure that it is current, promote it to be a master database instance, and point your application at it.
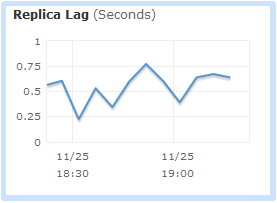
You will want to pay attention to replication lag when you implement any of these use cases. You can use Amazon CloudWatch to monitor this important metric, and to raise an alert if it reaches a level that is unacceptably high for your application:
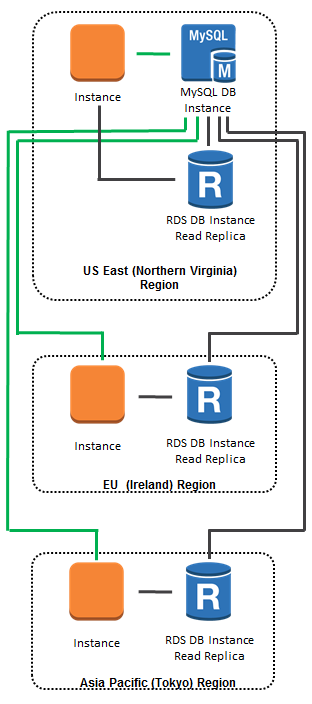
As an example of what you can do with Cross Region Replicas, here’s a global scale-out model. All database updates (green lines) are directed to the database instance in the US East (Northern Virginia) region. All database queries (black lines) are directed to in-region or cross-region read replicas, as appropriate:
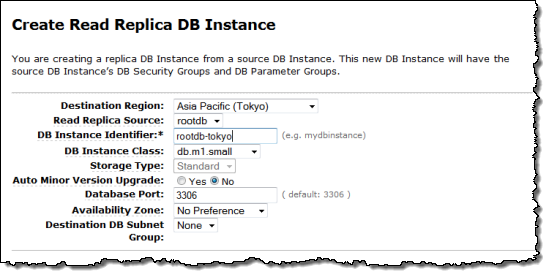
Creating Cross-Region Read Replicas
The cross-region replicas are very easy to create. You simply select the desired region (and optional availability zone) in the AWS Management Console:
You can also track the status of each of your read replicas using RDS Database Events.
All data transfers between regions are encrypted using public key encryption. You pay the usual AWS charges for the database instance, the associated storage, and the data transfer between the regions.
Reports from the Field
I know that our users have been looking forward to this feature. Here’s some of the feedback that they have already sent our way:
Isaac Wong is VP of Platform Architecture at Medidata. He told us:
 Medidata provides a cloud platform for life science companies to design and run clinical trials faster, cheaper, safer, and smarter. We use Amazon RDS to store mission critical clinical development data and tested many data migration scenarios between Asia and USA with the cross region snapshot feature and found it very simple and cost effective to use and an important step in our business continuity efforts. Our clinical platform is global in scope. The ability provided by the new Cross Region Read Replica feature to move data closer to the doctors and nurses participating in a trial anywhere in the world to shorten read latencies is awesome. It allows health professionals to focus on patients and not technology. Most importantly, using these cross region replication features, for life critical services in our platform we can insure that we are not affected by regional failure. Using AWS’s simple API’s we can very easily bake configuration and management into our deployment and monitoring systems at Medidata.
Medidata provides a cloud platform for life science companies to design and run clinical trials faster, cheaper, safer, and smarter. We use Amazon RDS to store mission critical clinical development data and tested many data migration scenarios between Asia and USA with the cross region snapshot feature and found it very simple and cost effective to use and an important step in our business continuity efforts. Our clinical platform is global in scope. The ability provided by the new Cross Region Read Replica feature to move data closer to the doctors and nurses participating in a trial anywhere in the world to shorten read latencies is awesome. It allows health professionals to focus on patients and not technology. Most importantly, using these cross region replication features, for life critical services in our platform we can insure that we are not affected by regional failure. Using AWS’s simple API’s we can very easily bake configuration and management into our deployment and monitoring systems at Medidata.
Joel Callaway is IT Operations Manager at Zoopla Property Group Ltd. This is what he had to say:
 Amazon RDS cross region functionality gives us the ability to copy our data between regions and keep it up to date for disaster recovery purposes with a few automated steps on the AWS Management Console. Our property and housing prices website attracts over 20 million visitors per month and we use Amazon RDS to store business critical data of these visitors. Using the cross region snapshot feature, we already transfer hundreds of GB of data from our primary US-East region to the EU-West every week. Before this feature, it used to take us several days and manual steps to do this on our own. We now look forward to the Cross Region Read Replica feature, which would make it even easier to replicate our data along with our application stack across multiple regions in AWS.
Amazon RDS cross region functionality gives us the ability to copy our data between regions and keep it up to date for disaster recovery purposes with a few automated steps on the AWS Management Console. Our property and housing prices website attracts over 20 million visitors per month and we use Amazon RDS to store business critical data of these visitors. Using the cross region snapshot feature, we already transfer hundreds of GB of data from our primary US-East region to the EU-West every week. Before this feature, it used to take us several days and manual steps to do this on our own. We now look forward to the Cross Region Read Replica feature, which would make it even easier to replicate our data along with our application stack across multiple regions in AWS.
Time to Replicate
This feature is available now and you can start using it today!
You may also want to investigate some of our other cross-region features including EC2 AMI Copy, RDS Snapshot Copy, DynamoDB Data Copy, and Redshift Snapshot Copy.
— Jeff;
Automated Cross-Region Snapshot Copy for Amazon Redshift
As part of our plan to make it even easier for you to build and run AWS applications that have a global footprint, I am happy to announce that Amazon Redshift now has the ability to automatically back up your cluster to a second AWS region!
You simply select the second region and the desired retention period; Redshift will take care of the rest:
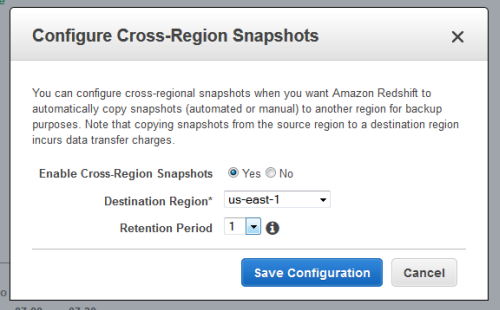
Once you enable this feature, Redshift will make subsequent snapshots available in the second region.
— Jeff;
Amazon Redshift – New Features Galore
We have added a very large collection of new features to Amazon Redshift. You now have more options and more ways to organize and query your petabyte-scale data warehouse.
Here’s a summary:
- Distributed Tables – You now have more control over the distribution of a table’s rows across compute nodes.
- Remote Loading – You can now load data into Redshift from remote hosts across an SSH connection.
- Approximate Count Distinct – You can now use a variant of the COUNT function to approximate the number of matching rows.
- Workload Queue Memory Management – You can now apportion available memory across work queues.
- Key Rotation – You can now direct Redshift to rotate keys for an encrypted cluster.
- HSM Support – You can now direct Redshift to use an on-premises Hardware Security Module (HSM) or AWS CloudHSM to manage the encryption master and cluster encryption keys.
- Database Auditing and Logging – You can log connections and user activity to Amazon S3.
- SNS Notification – Redshift can now issue notifications to an Amazon SNS topic when certain events occur.
Let’s take a deeper look at each of these new features.
Distributed Tables
As part of the query planning process, the Redshift optimizer determines where the data blocks need to be located in order to best execute the query. The data is then physically moved, or redistributed, during execution. This process can account for a substantial part of the cost of a query plan.
The storage for each compute node is divided into slices. Each XL compute node has two slices and each 8XL compute node has 16.
You can now choose to exercise additional control over the way that Redshift distributes table rows to compute nodes by choosing one of the following distribution styles when you create the table:
- Even – Rows are distributed across slices in round-robin fashion.
- Key – Rows with the same keys will tend to be stored on the same slice.
- All – Rows are distributed to all nodes.
Read more about choosing a distribution style.
Remote Loading
The Redshift COPY command can now reach out to remote locations (Elastic MapReduce clusters, Amazon EC2 instances, and on-premises hosts) to load data from external sources.
In order to do this you must add the cluster’s public key to the remote host’s authorized keys file (or equivalent). You must also configure the remote host to accept incoming connections from all of the IP addresses in the cluster.
Next, you create a simple manifest file in JSON format and upload it to an Amazon S3 bucket. The manifest provides Redshift with the information that it needs to have in order for it to connect to the remote host and to retrieve the data.
Finally, you issue a COPY command, including a reference to the manifest file.
Read more copying from remote hosts.
Approximate Count Distinct
You can now specify the APPROXIMATE option when you use Redshift’s COUNT DISTINCT function. Queries specified in this way use a HyperLogLog algorithm to approximate the number of distinct non-NULL values in a column or expression. This is much faster for large tables, and has a relative error of about 2%.
Read more about the COUNT function.
Workload Memory Management
A newly created Redshift cluster is configured with a single queue, capable of running five queries concurrently. You can add up to seven additional queues, each with a configurable level of concurrency, a user list, and a timeout. You can also create query groups. These are simply labels that you can also assign to queries in order to direct them to a particular queue.
In order to provide you with additional control over the WLM (Workload Management) features of Redshift, you can now control how much of the available memory is used to process the queries in each queue. You can specify the desired values in the WLM section of the parameter group associated with the cluster:
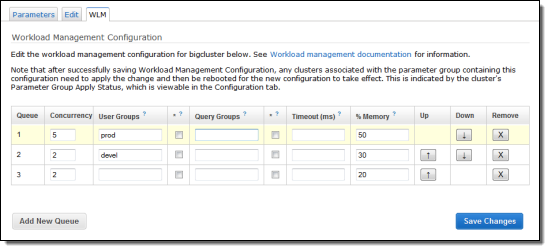
Read more about defining query queues.
Key Rotation
As you may know, Redshift uses three tiers of encryption keys to help protect data at rest. The randomly generated AES-256 block encryption keys encrypt data blocks in a cluster. The database key encrypts the block encryption keys and is in turn encrypted using a master key encryption key.
You can now direct Redshift to rotate the encryption keys for encrypted clusters. As part of the rotation process, keys are also updated for all of the cluster’s automatic and manual snapshots. You cannot rotate keys for snapshots that do not have a source cluster.
The cluster state transitions to ROTATING_KEYS for the duration of the rotation process, and returns to AVAILABLE when it completes.
Read more about database encryption and rotating encryption keys.
HSM Support
You can now opt to store your master and database encryption keys in an HSM (Hardware Security Module). Devices of this type provide direct control of key generation and management, and make key management separate and distinct from the application and the database.
You can use an on-premises HSM or AWS CloudHSM. Either way, you will need to configure a trusted network link between the Amazon Redshift and the HSM using client and server certificates.
Read more about hardware security modules.
Database Auditing and Logging
Amazon Redshift logs information about connections and user activity related to your database, allowing you to monitor your cluster for security and troubleshooting processes. Customers can now choose to have these logs downloaded to Amazon S3 for secure and convenient access. Read the Database Auditing and Logging documentation to learn more.
SNS Notification
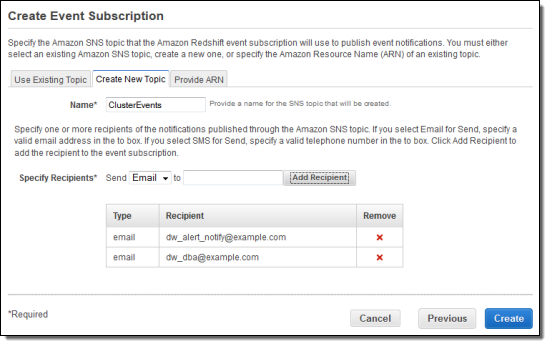
Redshift publishes notifications to Amazon Simple Notification Service (SNS) topics when events occur on Redshift clusters, snapshots, security groups, and parameter groups. There are four categories of notifications (Management, Monitoring, Security, and Configuration), two severity levels (Error and Info), and forty distinct types of events.
You enable these notifications by creating a subscription — a set of filters and an SNS topic in the AWS Management Console:
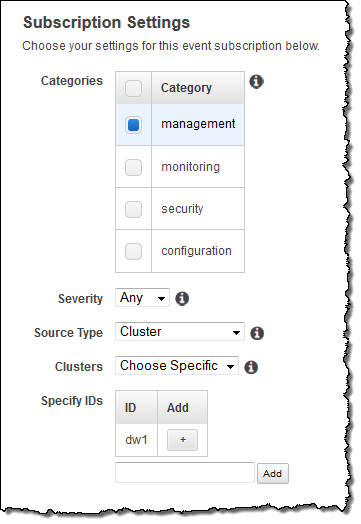
After you select a category, severity, and source type, the console displays the events that you will receive:
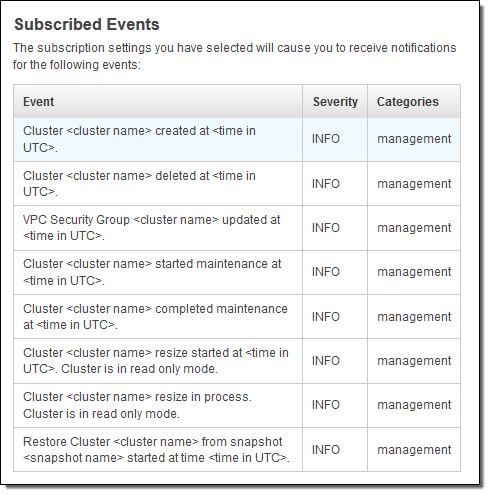
You can route the notifications to current or newly created SNS topics. You can also create email subscriptions to the topic at the same time:
Read more about event notifications.
Time to Shift
These features will be rolling out to all clusters and regions over course of the next two weeks!
— Jeff;
AWS Data Pipeline Now Supports Amazon Redshift
AWS Data Pipeline (see my introductory blog post for more information) is a web service that helps you to integrate and process data across compute and storage services at specified intervals. You can transform and process data that is stored in the cloud or on-premises in a highly scalable fashion without having to worry about resource availability, inter-task dependencies, transient failures, or timeouts.
Amazon Redshift (there’s a blog post for that one too) is a fast, fully managed, petabyte-scale data warehouse optimized for datasets that range from a few hundred gigabytes to a petabyte or more, and costs less than $1,000 per terabyte per year (about a tenth the cost of most traditional data warehousing solutions). As you can see from this post, we recently expanded the footprint and feature set of Redshift.
Pipeline, Say Hello to Redshift
Today we are connecting this pair of powerful AWS services; Amazon Redshift is now natively supported within the AWS Data Pipeline. This support is implemented using two new activities:
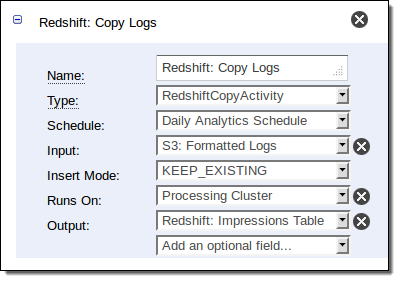
The RedshiftCopyActivity is used to bulk copy data from Amazon DynamoDB or Amazon S3 to a new or existing Redshift table. You can use this new power in a variety of different ways. If you are using Amazon RDS to store relational data or Amazon Elastic MapReduce to do Hadoop-style parallel processing, you can stage data in S3 before loading it into Redshift.
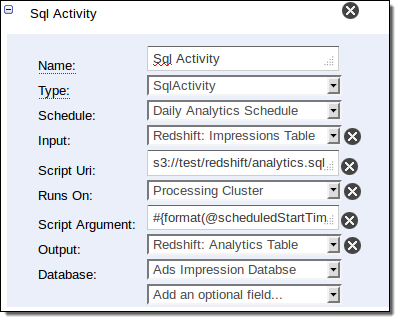
The SqlActivity is used to run SQL queries on data stored in Redshift. You specify the input and output tables, along with the query to be run. You can create a new table for the output, or you can merge the results of the query into an existing table.
You can access these new activities using the graphical pipeline editor in the AWS Management Console, a new [Redshift Copy template], the AWS CLI, and the AWS Data Pipeline APIs.
Putting it Together
Let’s take a look at a representative use case. Suppose you run an ecommerce website and you push your clickstream logs into Amazon S3 every 15 minutes. Every hour you use Hive to clean the logs and combine them with customer data residing in a SQL database, load the data into Redshift, and perform SQL queries to compute statistics such as sales by region and customer segment on a daily basis. Finally, you store the daily results in Redshift for long-term analysis.
Here is how you would define this processing pipeline using the AWS Management Console:
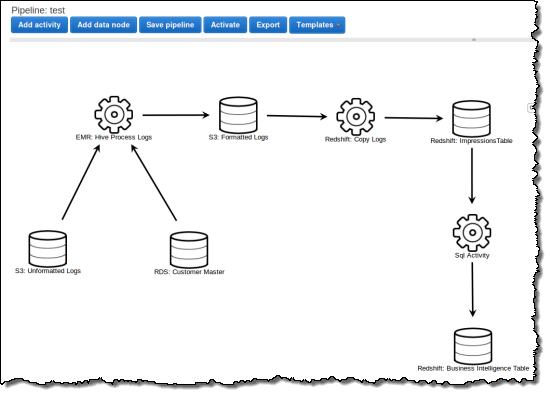
Here is how you define the activity that copies data from S3 to Redshift in the pipeline shown above:
And here is how you compute the statistics:
Start Now
The AWS Data Pipeline runs in the US East (Northern Virginia) Region. It supports access to Redshift in that region, along with cross-region workflows for Elastic MapReduce and DynamoDB. We plan to add cross-region access to Redshift in the future.
Begin by reading the Copy to Redshift documentation!
— Jeff;
Amazon Redshift Expands into Asia Pacific, Adds Features
Amazon Redshift lets you deploy a fast, fully managed, petabyte-scale data warehouse with just a couple of clicks. Once you create your cluster, you can use it to analyze your data using your existing business intelligence tools. Custom applications that use JDBC or ODBC connections will also work, as will those which use standard PostgreSQL drivers. Net-net, the analytical tools that you use today should work with Amazon Redshift.
Today we are making Amazon Redshift available in two more AWS Regions, and we are formally announcing a big pile of features that we have quietly added over the past few months. I’ll also toss in an interview with Redshift Product Manager Rahul Pathak.
Redshift in Asia
You can now launch Amazon Redshift clusters in the Asia Pacific (Singapore) and Asia Pacific (Sydney) Regions.

Amazon Redshift is also available in the US East (Northern Virginia), US West (Oregon), EU (Ireland), and Asia Pacific (Tokyo) Regions.
The XL Node (2 TB of compressed customer storage, 15 GiB of RAM) and 8XL Node (16 TB of compressed customer storage, 120 GiB of RAM) are available in all of the regions listed above, with both On-Demand and Reserved Instance pricing (see the Redshift Pricing page to learn more).
New Features
The Redshift team has been adding features at a rapid pace, many of them in response to your feedback on the Redshift forum. You can use this forum to provide us with input, ask questions, and keep track of newly released features.
Here’s what we are adding in this week’s release:
- The CONVERT_TIMEZONE SQL function converts a timestamp from one time zone to another, and can now automatically adjust for Daylight Savings Time.
- The new SPLIT_PART SQL function splits a string using a specified delimiter and returns the part at a specified position.
- The new STL_USERLOG table records the changes that occur when a database user is added, changed, or deleted.
And here’s what we added before that (see the documentation history for more information):
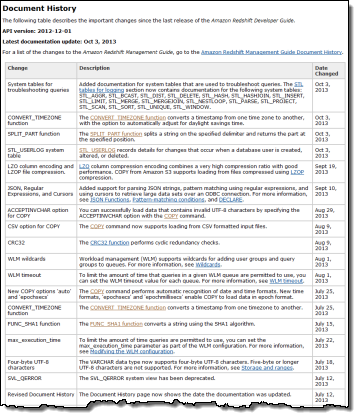 LZO column encoding.
LZO column encoding.- LZOP file compression.
- JSON string parsing.
- Regular expressions in conditional expressions.
- Cursors for ODBC connections.
- Replacement of invalid UTF-8 characters.
- Support for 4-byte UTF-8 characters.
- IAM resource-level permissions.
- Restore progress metrics.
- COPY from CSV format.
- Workload Management (WLM) enhancements.
- Automatic date, time, and format recognition for COPY.
- New FUNC_SHA1, MD5, and CRC32 functions.
- Snapshot sharing between AWS accounts.
Here’s Rahul
I interviewed Rahul Pathak, Amazon Redshift Product Manager, last month for the AWS Report:
— Jeff;
PS – If you are new to Amazon Redshift or you are not sure what a data warehouse is and why you need one, take a look at our Introduction to Amazon Redshift video.
Amazon Redshift Now Available in Japan
Amazon Redshift is now available in the Asia Pacific (Tokyo) Region. AWS customers running in this Region can now create a fast, fully managed, petabyte-scale data warehouse today at a price point that is a tenth that of most traditional data warehousing solutions.
Customers Love Amazon Redshift
We launched Redshift in February of 2013. Since that time, we’ve signed up well over 1000 customers, and are currently adding over a 100 or so per week. In aggregate, we’ve enabled these customers to save millions of dollars in capital expenditures (CAPEX).
Timon Karnezos of Aggregate Knowledge did a deep dive on Redshift to learn more about its performance and cost characteristics. His recent blog post, 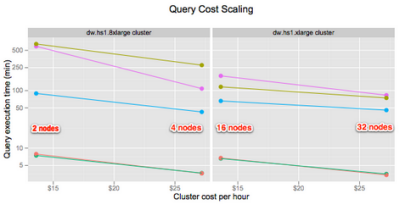 AWS Redshift, How Amazon Changed the Game, tells the story. Timon tested 4 data sets (2 billion to 57 billion rows) on six Redshift cluster configurations (1 to 32 of the dw.hs1.xlarge nodes and either 2 or 4 of the dw.hs1.8xlarge nodes). His data sets were stored in Amazon S3; he found that the overall load time scaled linearly with cost and data size. He also measured a variety of queries that were representative of those he runs to generate reports, and found that performance to be impressive as well, with near-linear scaling even as the data set grew beyond 50 billion rows, with very consistent query times. Timon also tested Redshift’s snapshotting and resizing features, and wrapped up by noting that:
AWS Redshift, How Amazon Changed the Game, tells the story. Timon tested 4 data sets (2 billion to 57 billion rows) on six Redshift cluster configurations (1 to 32 of the dw.hs1.xlarge nodes and either 2 or 4 of the dw.hs1.8xlarge nodes). His data sets were stored in Amazon S3; he found that the overall load time scaled linearly with cost and data size. He also measured a variety of queries that were representative of those he runs to generate reports, and found that performance to be impressive as well, with near-linear scaling even as the data set grew beyond 50 billion rows, with very consistent query times. Timon also tested Redshift’s snapshotting and resizing features, and wrapped up by noting that:
I caused a small riot among the analysts when I mentioned off-hand how quickly I could run these queries on substantial data sets. On a service that I launched and loaded overnight with about three days of prior fiddling/self-training.
Were excited to see how customers are benefiting from Amazon Redshifts price, performance, and ease of use, so please keep the blog posts coming.
Get Started Today
Amazon Redshift is now available in the US East (Northern Virginia), US West (Oregon), EU West (Ireland), and Asia Pacific (Tokyo) Regions, with additional Regions coming soon.
You can get started with Redshift today. Read the Redshift Getting Started Guide, check out the selection of business intelligence and data integration software in the AWS Marketplace, and launch your own cluster.
— Jeff;
PS – We are also launching a number of new EC2 instance types in the Tokyo Region.
AWS Expansion in Oregon – Amazon Redshift and Amazon EC2 High Storage Instances
You can now launch Amazon Redshift clusters and EC2 High Storage instances in the US West (Oregon) Region.
Amazon Redshift
Amazon Redshift is a fully managed data warehouse service that lets you create, run, and manage a petabyte-scale data warehouse with ease. You can easily scale up by adding additional nodes (giving you more storage and more processing power) and you pay a low, hourly fee for each node (Reserved Nodes are also available and bring Amazon Redshift’s price to under $1,000 per terabyte per year, less than 1/10th the cost of most traditional data warehouse systems).
Seattle-based Redfin is ready to use Amazon Redshift in US West (Oregon). Data Scientist Justin Yan told us that:
We took Amazon Redshift for a test run the moment it was released. It’s fast. It’s easy. Did I mention it’s ridiculously fast? We’ve been waiting for a suitable data warehouse at big data scale, and ladies and gentlemen, it’s here. We’ll be using it immediately to provide our analysts an alternative to Hadoop. I doubt any of them will want to go back.
Here’s a video that will introduce you to Redshift:
If you’re interested in helping to build and grow Amazon Redshift, we’re hiring in Seattle and Palo Alto drop us a line! Here are some of our open positions:
High Storage Instances
We are also launching the High Storage Eight Extra Large (hs1.8xlarge) instances in the Region. Each of these instances includes 117 GiB of RAM, 16 virtual cores (providing 35 ECU of compute performance), and 48 TB of instance storage across 24 hard disk drives. You can get up to 2.4 GB per second of I/O performance from these drives, making them ideal for data-intensive applications that require high storage density and high sequential I/O.
Localytics of Boston has moved their primary analytics database to the hs1.8xlarge instance type, replacing an array of a dozen RAID 0 volumes. The large storage capacity coupled with the increased performance (especially for sequential reads and writes) makes this instance type an ideal host for their application. According to Mohit Dilawari of Localytics, “We are extremely happy with these instances. Our site is substantially faster after the recent migration, yet our instance cost has decreased.”
If you are interested in helping to design and deliver instance types similar to the hs1.8xlarge to enable our customers to run high performance applications in the cloud, the EC2 team would like to talk to you about this Senior Product Manager position.
— Jeff;
Amazon RDS – Easier Access to Database Log Files
You can now access the log files generated by your Amazon RDS DB Instances running MySQL, Oracle Database, or SQL Server via the AWS Management Console and the Amazon RDS APIs. You can use these logs to identify, troubleshoot, and repair configuration errors and sub-optimal performance.
You can view the logs as of a certain point in time, watch them for real-time updates, or download them for further processing (downloads are not currently supported by the AWS Management Console and can be initiated via the rds-download-db-logfile command).
You can select a DB Instance in the Console and see the list of log files:
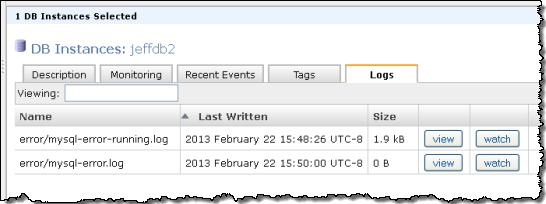
You can then choose to View or Watch any of them:
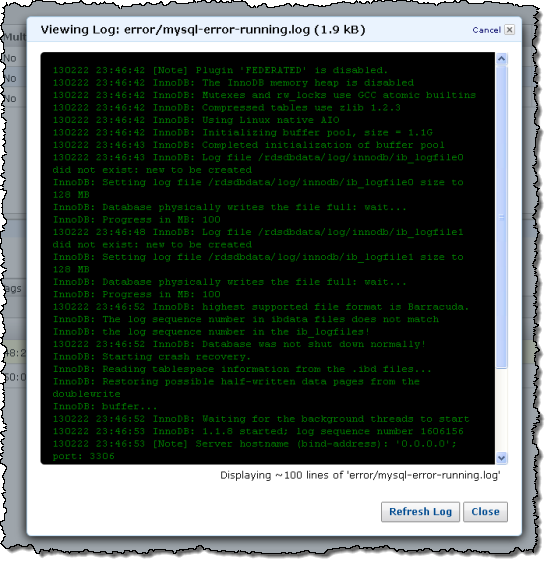
The type of log files available to you will vary based on the database engine:
MySQL – You can monitor the Error Log, Slow Query Log, and General Log files. The Error Log is generated by default; you’ll need to enable the others by using an RDS DB Parameter Group. The logs are rotated hourly and retained for 24 hours.
Oracle Database – You can access the Alert Log and Trace Files. They are retained for seven days by default; you can adjust this as needed.
SQL Server – You can access the Error Log, Agent Log, and Trace Files. They are retained for seven days and you can adjust this as needed.
Refer to the Working with Database Log Files section of the Amazon RDS User Guide to learn more.
— Jeff;