Category: AWS Data Pipeline
AWS Data Pipeline Update – Parameterized Templates
AWS Data Pipeline helps you to reliably process and move data between compute and storage services running either on AWS on on-premises. The pipelines that you create with Data Pipeline’s graphical editor are scalable and fault tolerant, and can be scheduled to run at specific intervals. To learn more, read my launch post, The New AWS Data Pipeline.
New Parameterized Templates
Today we are making Data Pipeline easier to use by introducing support for parameterized templates, along with a library of templates for common use cases. You can now select a template from a drop-down menu, provide values for the specially marked parameters within the template, and launch the customized pipeline, all with a couple of clicks.
Let’s start with a quick tour and then dig in to details. The Create Pipeline page of the AWS Management Console contains a new menu:
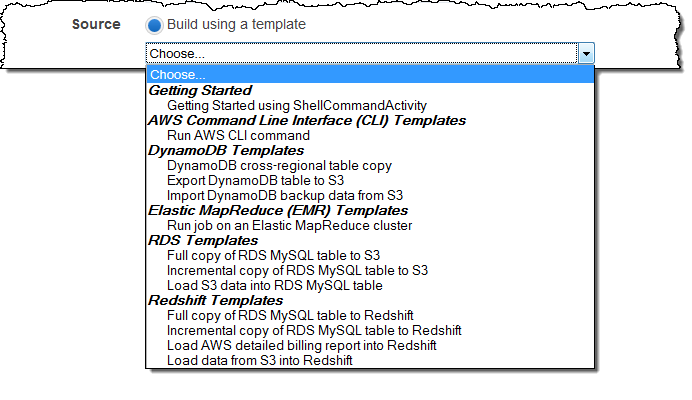
As you can see from the menu, you can access templates for jobs that use the AWS Command Line Interface (CLI), Amazon DynamoDB, Amazon EMR, Amazon Relational Database Service (RDS), and Amazon Redshift. We plan to add more templates later and are open to your suggestions!
I chose Run an Elastic MapReduce job flow. Now all I need to do is to fill in the parameters for the job flow:
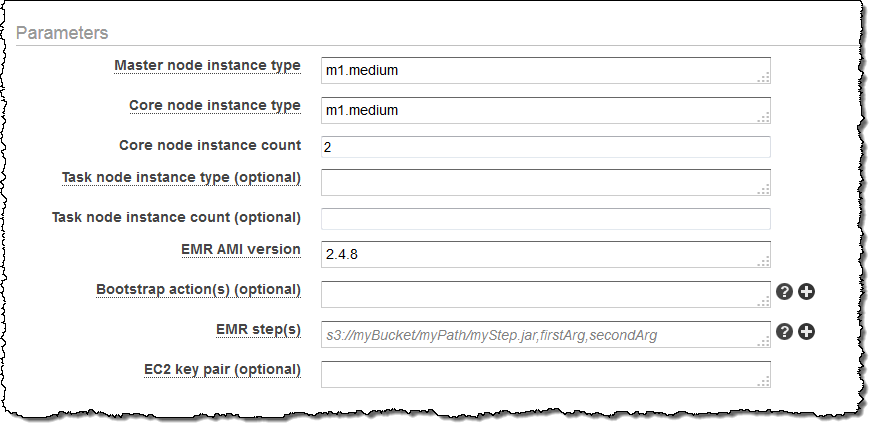
The “+” next to some of the parameters indicates that the template makes provision for an array of values for the parameter. Clicking on it will add an additional data entry field:

You can use these templates as a starting point by editing the pipeline before you activate it (You can download them from s3://datapipeline-us-east-1/templates/).
How it Works
Each template is a JSON file. Parameters are specified like this (this is similar to the syntax used by AWS CloudFormation):
{
"parameters":[
{
"id": "mys3OutputBucket",
"type":"AWS::S3::ObjectKey",
"description":"S3 output bucket",
"default ":"s3://abc"
},
{
"id" : "myobjectname"
"type" : "String",
"description" : "Object name"
}
]
}
Parameters can be of type String, Integer, or Double and can also be flagged as isArray to indicate that multiple values can be entered. Parameters can be marked as optional; the template can supply a default value and a list of acceptable values if desired.
The parameters are very useful for late binding of actual values. Organizations can identify best practices and encapsulate them in Data Pipeline templates for widespread use within and across teams and departments.
You can also use templates and parameters from the command line and the Data Pipeline API.
Available Now
This feature is available now and you can start using it today.
— Jeff;
New Scheduling Options for AWS Data Pipeline
The AWS Data Pipeline lets you automate the movement and processing of any amount of data using data-driven workflows and built-in dependency checking.
Today we are making the Data Pipeline more flexible and more useful with the addition of a new scheduling model that works at the level of an entire pipeline. This builds upon the existing model, which allows you to schedule the individual activities within a pipeline.
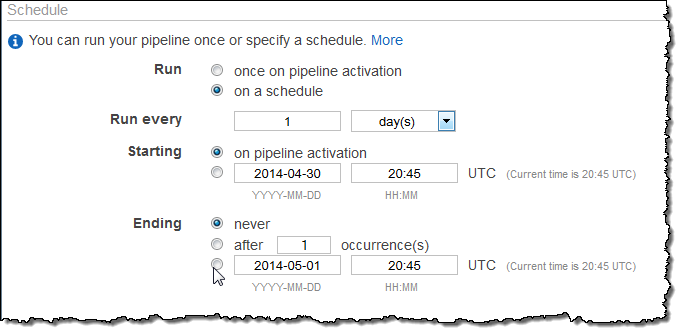
You can now choose between the following options for each pipeline that you build:
- Run once
- Run a defined number of times
- Run on activation
- Run indefinitely
- Run repeatedly within a date range
The schedule that you set for each pipeline will be inherited by every object in the pipeline. If you need to create multiple schedules for complex pipelines you can still set schedules for individual objects.
You can set the schedule from the AWS Management Console and from the Data Pipeline APIs. The console allows you to set the schedule when you create a new pipeline:
This new feature is available now and you can start using it today. You can read all about Data Pipeline Schedules to learn more.
— Jeff;
Cross-Region Export and Import of DynamoDB Tables
Two of the most frequent feature requests for Amazon DynamoDB involve backup/restore and cross-Region data transfer.
 Today we are addressing both of these requests with the introduction of a pair of scalable tools (export and import) that you can use to move data between a DynamoDB table and an Amazon S3 bucket. The export and import tools use the AWS Data Pipeline to schedule and supervise the data transfer process. The actual data transfer is run on an Elastic MapReduce cluster that is launched, supervised, and terminated as part of the import or export operation.
Today we are addressing both of these requests with the introduction of a pair of scalable tools (export and import) that you can use to move data between a DynamoDB table and an Amazon S3 bucket. The export and import tools use the AWS Data Pipeline to schedule and supervise the data transfer process. The actual data transfer is run on an Elastic MapReduce cluster that is launched, supervised, and terminated as part of the import or export operation.
In other words, you simply set up the export (either one-shot or every day, at a time that you choose) or import (one-shot) operation, and the combination of AWS Data Pipeline and Elastic MapReduce will take care of the rest. You can even supply an email address that will be used to notify you of the status of each operation.
Because the source bucket (for imports) and the destination bucket (for exports) can be in any AWS Region, you can use this feature for data migration and for disaster recovery.
Export and Import Tour
Let’s take a quick tour of the export and import features, both of which can be accessed from the DynamoDB tab of the AWS Management Console. Start by clicking on the Export/Import button:
At this point you have two options: You can select multiple tables and click Export from DynamoDB, or you can select one table and click Import into DynamoDB.
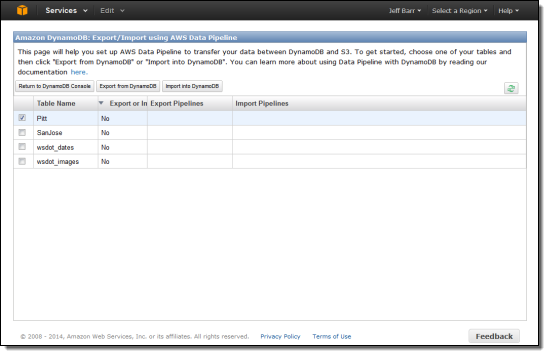
If you click Export from DynamoDB, you can specify the desired S3 buckets for the data and for the log files.
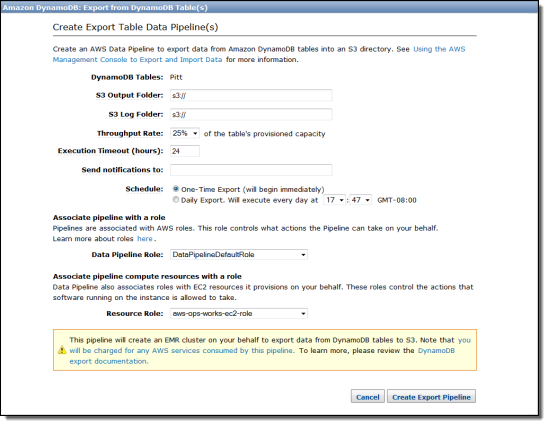
As you can see, you can decide how much of the table’s provisioned throughput to allocate to the export process (10% to 100% in 5% increments). You can run an immediate, one-time export or you can choose to start it every day at the time of your choice. You can also choose the IAM role to be used for the pipeline and for the compute resources that it provisions on your behalf.
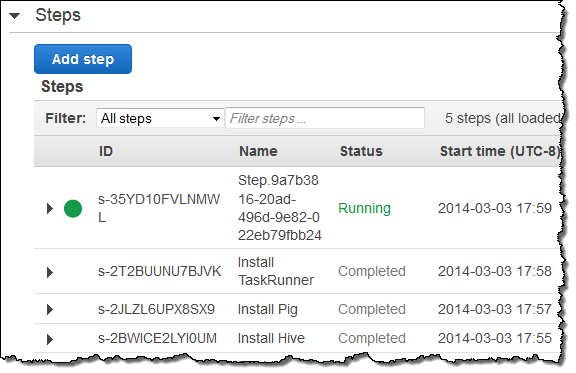
I selected one of my tables for immediate export, and watched as the MapReduce job was started up:
The export operation was finished within a few minutes and my data was in S3:
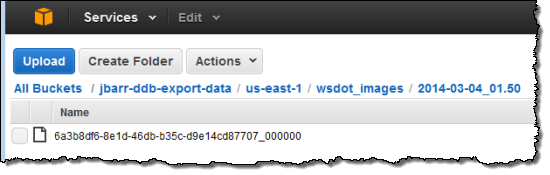
Because the file’s key includes the date and the time as well as a unique identifier, exports that are run on a daily basis will accumulate in S3. You can use S3’s lifecycle management features to control what happens after that.
I downloaded the file and verified that my DynamoDB records were inside:
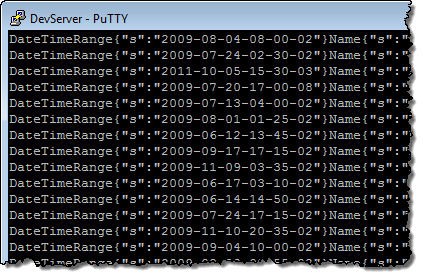
Although you can’t see them in this screen shot, the attribute names are surrounded by the STX and ETX ASCII characters. Refer to the documentation section titled Verify Data File Export for more information on the file format.
The import process is just as simple. You can create as many one-shot import jobs as you need, one table at a time:
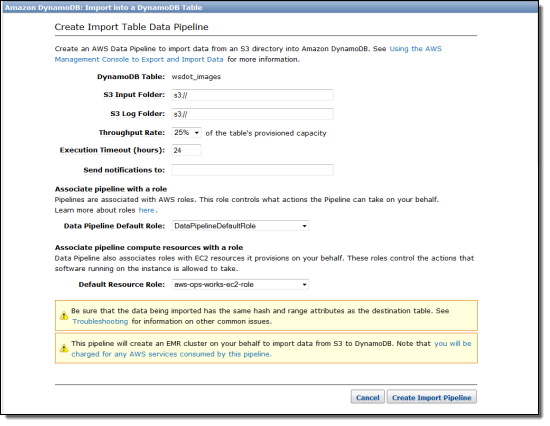
Again, S3 plays an important role here, and you can control how much throughput you’d like to devote to the import process. You will need to point to a specific “folder” for the input data when you set up the import. Although the most common use case for this feature is to import data that was previously exported, you can also export data from an existing relational or NoSQL database, transform it into the structure described here, and import the resulting file into DynamoDB.
— Jeff;
AWS Data Pipeline Now Available in Four More Regions
As we often do, we launched AWS Data Pipeline in a single AWS Region (US East (Northern Virginia) to be precise). It is now available in the following Regions as well:
- US West (Oregon)
- EU (Ireland)
- Asia Pacific (Sydney)
- Asia Pacific (Tokyo)
AWS Data Pipeline has always supported data flows between Regions. With today’s release, you can now choose to locate your pipelines closer to the services and the data that they manage. You also have the option to build additional redundancy in to your systems.
To learn more or to get started, visit the AWS Data Pipeline page.
— Jeff;
AWS Data Pipeline Now Supports Amazon Redshift
AWS Data Pipeline (see my introductory blog post for more information) is a web service that helps you to integrate and process data across compute and storage services at specified intervals. You can transform and process data that is stored in the cloud or on-premises in a highly scalable fashion without having to worry about resource availability, inter-task dependencies, transient failures, or timeouts.
Amazon Redshift (there’s a blog post for that one too) is a fast, fully managed, petabyte-scale data warehouse optimized for datasets that range from a few hundred gigabytes to a petabyte or more, and costs less than $1,000 per terabyte per year (about a tenth the cost of most traditional data warehousing solutions). As you can see from this post, we recently expanded the footprint and feature set of Redshift.
Pipeline, Say Hello to Redshift
Today we are connecting this pair of powerful AWS services; Amazon Redshift is now natively supported within the AWS Data Pipeline. This support is implemented using two new activities:
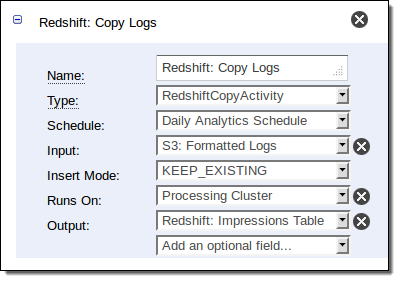
The RedshiftCopyActivity is used to bulk copy data from Amazon DynamoDB or Amazon S3 to a new or existing Redshift table. You can use this new power in a variety of different ways. If you are using Amazon RDS to store relational data or Amazon Elastic MapReduce to do Hadoop-style parallel processing, you can stage data in S3 before loading it into Redshift.
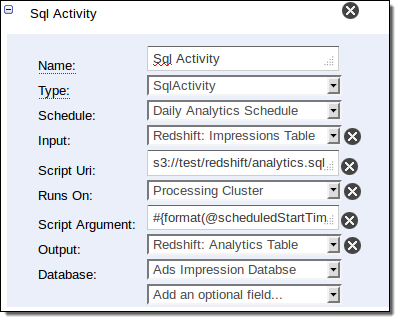
The SqlActivity is used to run SQL queries on data stored in Redshift. You specify the input and output tables, along with the query to be run. You can create a new table for the output, or you can merge the results of the query into an existing table.
You can access these new activities using the graphical pipeline editor in the AWS Management Console, a new [Redshift Copy template], the AWS CLI, and the AWS Data Pipeline APIs.
Putting it Together
Let’s take a look at a representative use case. Suppose you run an ecommerce website and you push your clickstream logs into Amazon S3 every 15 minutes. Every hour you use Hive to clean the logs and combine them with customer data residing in a SQL database, load the data into Redshift, and perform SQL queries to compute statistics such as sales by region and customer segment on a daily basis. Finally, you store the daily results in Redshift for long-term analysis.
Here is how you would define this processing pipeline using the AWS Management Console:
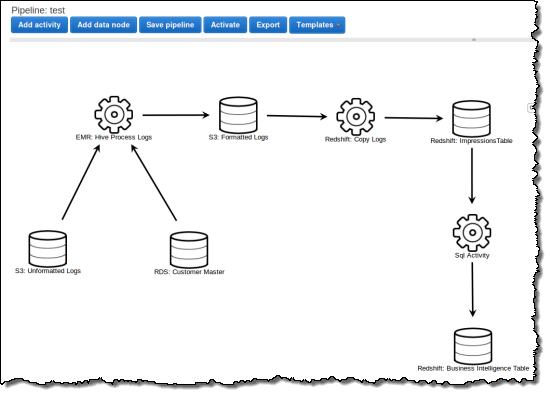
Here is how you define the activity that copies data from S3 to Redshift in the pipeline shown above:
And here is how you compute the statistics:
Start Now
The AWS Data Pipeline runs in the US East (Northern Virginia) Region. It supports access to Redshift in that region, along with cross-region workflows for Elastic MapReduce and DynamoDB. We plan to add cross-region access to Redshift in the future.
Begin by reading the Copy to Redshift documentation!
— Jeff;
Copy DynamoDB Data Between Regions Using the AWS Data Pipeline
If you use Amazon DynamoDB, you may already be using AWS Data Pipeline to make regular backups to Amazon S3, or to load backup data from S3 to DynamoDB.
Today we are releasing a new feature that enables periodic copying of the data in a DynamoDB table to another table in the region of your choice. You can use the copy for disaster recovery (DR) in the event that an error in your code damages the original table, or to federate DynamoDB data across regions to support a multi-region application.
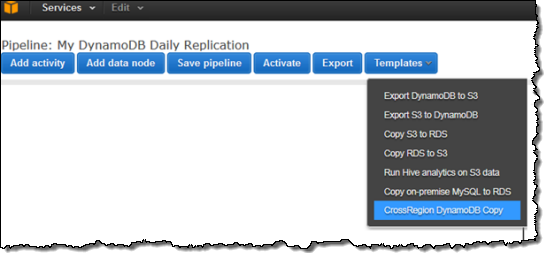
You can access this feature by using a new template that you can access through the AWS Data Pipeline:
Select the template and then set up the parameters for the copy:
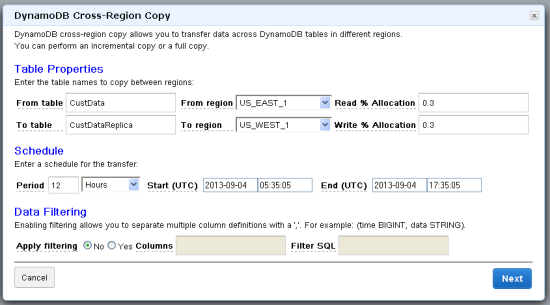
Enter the table names for the source and destination, along with their respective regions. The Read and Write Percentage Allocation is the percentage of the table’s total capacity units allocated to this copy. Then, set up the frequency of this copy, the start time for the first copy, and optionally the end time.
You can use the Data Filtering option to choose between four different copy operations:
Full Table Copy – If you do not set any of the Data Filtering parameters, the entire table — all items and all of their attributes — will be copied on every execution of the pipeline.
Incremental Copy – If each of the items in the table has a timestamp attribute, you can specify it in the Filter SQL field along with the timestamp value to select against. Note that this will not delete any items in the destination table. If you need this functionality, you can implement a logical delete (usig an attribute to indicate that an item has been deleted) instead of a physical deletion.
Selected Attribute Copy – If you would like to copy only a subset of the attributes of each item, specify the desired attributes in the Columns field.
Incremental Selected Attribute Copy – You can combine Incremental and Selected Attribute Copy operations and incrementally copy a subset of the attributes of each item.
Once you have filled out the form, you will see a confirmation window that summarizes how the copy is going to be accomplished. Data Pipeline uses Amazon Elastic Map Reduce (EMR) to perform a parallel copy of data directly from one DynamoDB table to the other, with no intermediate staging involved:
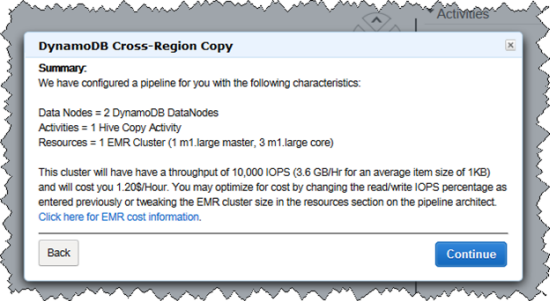
The usual AWS data transfer charges apply when you use this facility to copy data between DynamoDB tables.
Note that the AWS Data Pipeline is currently available in the US East (Northern Virginia) Region and you’ll have to launch it from there. It can, however, copy data between tables located in any of the public AWS Regions.
This feature is available now and you can start using it today!
— Jeff;
AWS Data Pipeline – Now Ready for Use!
The AWS Data Pipeline is now ready for use and you can sign up here.
As I described in my initial blog post, the AWS Data Pipeline gives you the power to automate the movement and processing of any amount of data using data-driven workflows and built-in dependency checking. You can access it from the command line, the APIs, or the AWS Management Console.
Today l’d like to show you how to use the AWS Management Console to create your own pipeline definition. Start by opening up the console and chosing Data Pipeline from the Services menu:

You’ll see the main page of the Data Pipeline console:
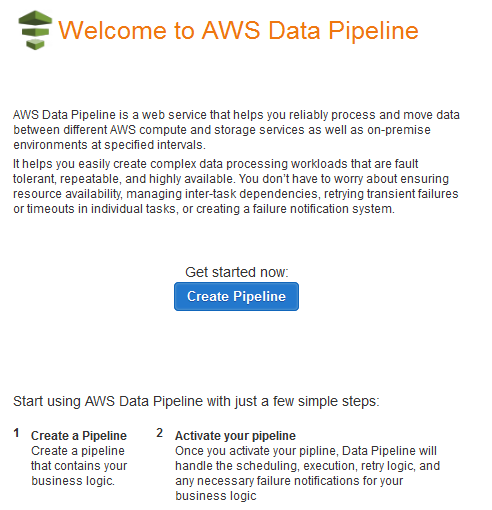
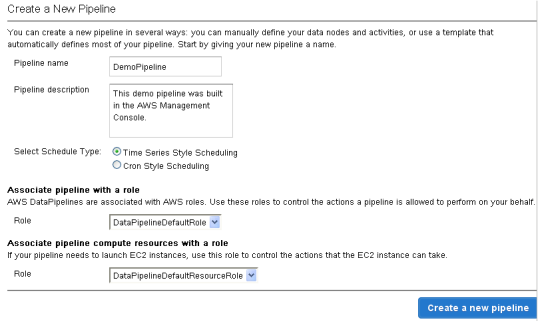
Click on Create Pipeline to get started, then fill in the form:
With that out of the way, you now have access to the actual Pipeline Editor:
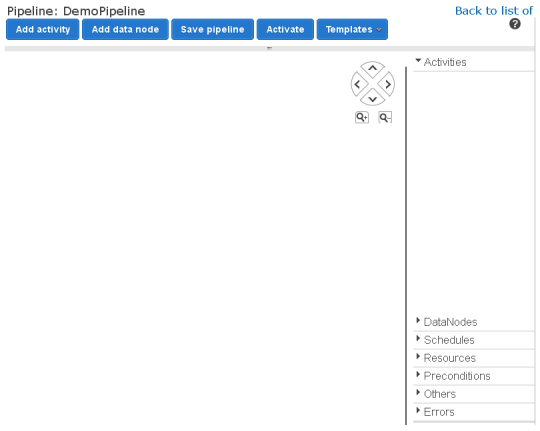
At this point you have two options. You can build the entire pipeline scratch or you can use one of the pre-defined templates as a starting point:
I’m going to use the first template, Export DynamoDB to S3. The pipeline is shown on the left side of the screen:
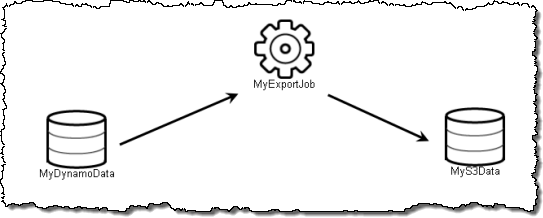
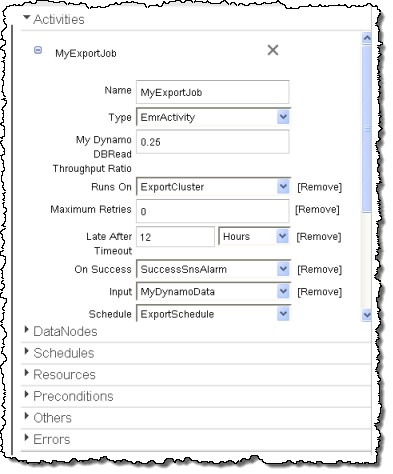
Clicking on an item to select it will show its attributes on the right side:
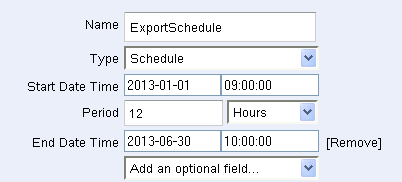
The ExportSchedule (an item of type Schedule) specifies how often the pipeline should be run, and over what time interval. Here I’ve specified that it should run every 12 hours for the first 6 months of 2013:
The ExportCluster (a Resource) specifies that an Elastic MapReduce cluster will be used to move the data:
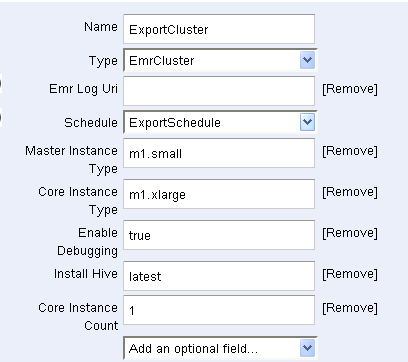
MyDynamoData and MyS3Data specify the data source (a DynamoDB table) and the destination (an S3 bucket):
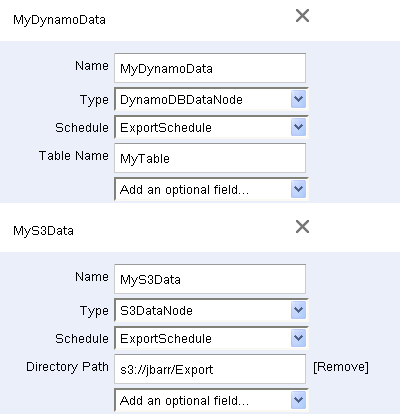
An Amazon SNS topic is used to provide notification of successes and failures (not shown):

Finally, MyExportJob (an Activity) pulls it all together:
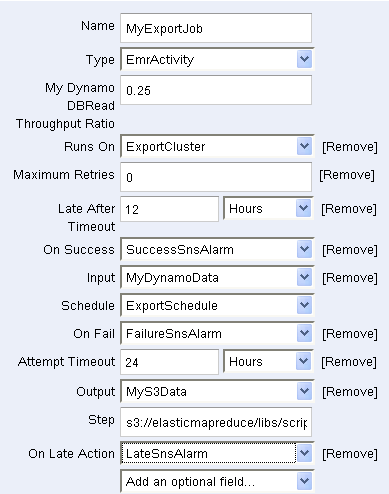
Once the pipeline is ready, it can be saved and then activated:

Here are some other resources to help you get started with the AWS Data Pipeline:
- AWS Data Pipeline Home Page
- AWS Data Pipeline Developer Guide
- AWS Data Pipeline API Reference
- AWS Data Pipeline FAQ
And there you have it! Give it a try and let me know what you think.
— Jeff;
The New AWS Data Pipeline
Data. Information. Big Data. Business Intelligence. It’s all the rage these days. Companies of all sizes are realizing that managing data is a lot more complicated and time consuming than in the past, despite the fact that the cost of the underlying storage continues to decline.
Buried deep within this mountain of data is the “captive intelligence” that you could be using to expand and improve your business. Your need to move, sort, filter, reformat, analyze, and report on this data in order to make use of it. To make matters more challenging, you need to do this quickly (so that you can respond in real time) and you need to do it repetitively (you might need fresh reports every hour, day, or week).
Data Issues and Challenges
Here are some of the issues that we are hearing about from our customers when we ask them about their data processing challenges:
Increasing Size – There’s simply a lot of raw and processed data floating around these days. There are log files, data collected from sensors, transaction histories, public data sets, and lots more.
Variety of Formats – There are so many ways to store data: CSV files, Apache logs, flat files, rows in a relational database, tuples in a NoSQL database, XML, JSON to name a few.
Disparate Storage – There are all sorts of systems out there. You’ve got your own data warehouse (or Amazon Redshift), Amazon S3, Relational Database Service (RDS) database instances running MySQL, Oracle, or Windows Server, DynamoDB, other database servers running on Amazon EC2 instances or on-premises, and so forth.
Distributed, Scalable Processing – There are lots of ways to process the data: On-Demand or Spot EC2 instances, an Elastic MapReduce cluster, or physical hardware. Or some combination of any and all of the above just to make it challenging!
Hello, AWS Data Pipeline
Our new AWS Data Pipeline product will help you to deal with all of these issues in a scalable fashion. You can now automate the movement and processing of any amount of data using data-driven workflows and built-in dependency checking.
Let’s start by taking a look at the basic concepts:
A Pipeline is composed of a set of data sources, preconditions, destinations, processing steps, and an operational schedule, all defined in a Pipeline Definition.
The definition specifies where the data comes from, what to do with it, and where to store it. You can create a Pipeline Definition in the AWS Management Console or externally, in text form.
Once you define and activate a pipeline, it will run according to a regular schedule. You could, for example, arrange to copy log files from a cluster of Amazon EC2 instances to an S3 bucket every day, and then launch a massively parallel data analysis job on an Elastic MapReduce cluster once a week. All internal and external data references (e.g. file names and S3 URLs) in the Pipeline Definition can be computed on the fly so you can use convenient naming conventions like raw_log_YYYY_MM_DD.txt for your input, intermediate, and output files.
Your Pipeline Definition can include a precondition. Think of a precondition as an assertion that must hold in order for processing to begin. For example, you could use a precondition to assert that an input file is present.
AWS Data Pipeline will take care of all of the details for you. It will wait until any preconditions are satisfied and will then schedule and manage the tasks per the Pipeline Definition. For example, you can wait until a particular input file is present.
Processing tasks can run on EC2 instances, Elastic MapReduce clusters, or physical hardware. AWS Data Pipeline can launch and manage EC2 instances and EMR clusters as needed. To take advantage of long-running EC2 instances and physical hardware, we also provide an open source tool called the Task Runner. Each running instance of a Task Runner polls the AWS Data Pipeline in pursuit of jobs of a specific type and executes them as they become available.
When a pipeline completes, a message will be sent to the Amazon SNS topic of your choice. You can also arrange to send messages when a processing step fails to complete after a specified number of retries or if it takes longer than a configurable amount of time to complete.
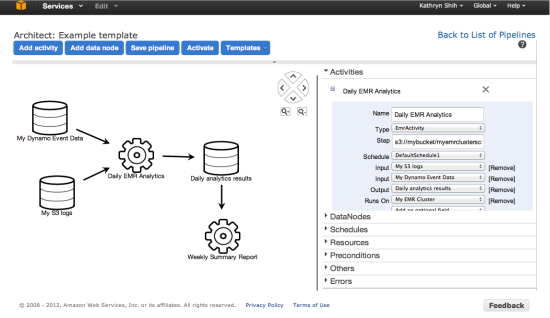
From the Console
You will be able to design, monitor, and manage your pipelines from within the AWS Management Console:
API and Command Line Access
In addition to the AWS Management Console access, you will also be able to access the AWS Data Pipeline through a set of APIs and from the command line.
You can create a Pipeline Definition in a text file in JSON format; here’s a snippet that will copy data from one Amazon S3 location to another:
“name” : “S3ToS3Copy” ,
“type” : “CopyActivity” ,
“schedule” : { “ref” : “CopyPeriod” } ,
“input” : { “ref” : “InputData” } ,
“output” : { “ref” : “OutputData” }
}
Coming Soon
The AWS Data Pipeline is currrently in a limited private beta. If you are interested in participating, please contact AWS sales.
Stay tuned to the blog for more information on the upcoming public beta.
— Jeff;