Category: Amazon Simple Queue Service (SQS)
Roundup of AWS HIPAA Eligible Service Announcements
At AWS we have had a number of HIPAA eligible service announcements. Patrick Combes, the Healthcare and Life Sciences Global Technical Leader at AWS, and Aaron Friedman, a Healthcare and Life Sciences Partner Solutions Architect at AWS, have written this post to tell you all about it.
-Ana
We are pleased to announce that the following AWS services have been added to the BAA in recent weeks: Amazon API Gateway, AWS Direct Connect, AWS Database Migration Service, and Amazon SQS. All four of these services facilitate moving data into and through AWS, and we are excited to see how customers will be using these services to advance their solutions in healthcare. While we know the use cases for each of these services are vast, we wanted to highlight some ways that customers might use these services with Protected Health Information (PHI).
![]() As with all HIPAA-eligible services covered under the AWS Business Associate Addendum (BAA), PHI must be encrypted while at-rest or in-transit. We encourage you to reference our HIPAA whitepaper, which details how you might configure each of AWS’ HIPAA-eligible services to store, process, and transmit PHI. And of course, for any portion of your application that does not touch PHI, you can use any of our 90+ services to deliver the best possible experience to your users. You can find some ideas on architecting for HIPAA on our website.
As with all HIPAA-eligible services covered under the AWS Business Associate Addendum (BAA), PHI must be encrypted while at-rest or in-transit. We encourage you to reference our HIPAA whitepaper, which details how you might configure each of AWS’ HIPAA-eligible services to store, process, and transmit PHI. And of course, for any portion of your application that does not touch PHI, you can use any of our 90+ services to deliver the best possible experience to your users. You can find some ideas on architecting for HIPAA on our website.
Amazon API Gateway
Amazon API Gateway is a web service that makes it easy for developers to create, publish, monitor, and secure APIs at any scale. With PHI now able to securely transit API Gateway, applications such as patient/provider directories, patient dashboards, medical device reports/telemetry, HL7 message processing and more can securely accept and deliver information to any number and type of applications running within AWS or client presentation layers.
One particular area we are excited to see how our customers leverage Amazon API Gateway is with the exchange of healthcare information. The Fast Healthcare Interoperability Resources (FHIR) specification will likely become the next-generation standard for how health information is shared between entities. With strong support for RESTful architectures, FHIR can be easily codified within an API on Amazon API Gateway. For more information on FHIR, our AWS Healthcare Competency partner, Datica, has an excellent primer.
AWS Direct Connect
Some of our healthcare and life sciences customers, such as Johnson & Johnson, leverage hybrid architectures and need to connect their on-premises infrastructure to the AWS Cloud. Using AWS Direct Connect, you can establish private connectivity between AWS and your datacenter, office, or colocation environment, which in many cases can reduce your network costs, increase bandwidth throughput, and provide a more consistent network experience than Internet-based connections.
In addition to a hybrid-architecture strategy, AWS Direct Connect can assist with the secure migration of data to AWS, which is the first step to using the wide array of our HIPAA-eligible services to store and process PHI, such as Amazon S3 and Amazon EMR. Additionally, you can connect to third-party/externally-hosted applications or partner-provided solutions as well as securely and reliably connect end users to those same healthcare applications, such as a cloud-based Electronic Medical Record system.
AWS Database Migration Service (DMS)
To date, customers have migrated over 20,000 databases to AWS through the AWS Database Migration Service. Customers often use DMS as part of their cloud migration strategy, and now it can be used to securely and easily migrate your core databases containing PHI to the AWS Cloud. As your source database remains fully operational during the migration with DMS, you minimize downtime for these business-critical applications as you migrate your databases to AWS. This service can now be utilized to securely transfer such items as patient directories, payment/transaction record databases, revenue management databases and more into AWS.
Amazon Simple Queue Service (SQS)
Amazon Simple Queue Service (SQS) is a message queueing service for reliably communicating among distributed software components and microservices at any scale. One way that we envision customers using SQS with PHI is to buffer requests between application components that pass HL7 or FHIR messages to other parts of their application. You can leverage features like SQS FIFO to ensure your messages containing PHI are passed in the order they are received and delivered in the order they are received, and available until a consumer processes and deletes it. This is important for applications with patient record updates or processing payment information in a hospital.
Let’s get building!
We are beyond excited to see how our customers will use our newly HIPAA-eligible services as part of their healthcare applications. What are you most excited for? Leave a comment below.
New – Server-Side Encryption for Amazon Simple Queue Service (SQS)
As one of the most venerable members of the AWS family of services, Amazon Simple Queue Service (SQS) is an essential part of many applications. Presentations such as Amazon SQS for Better Architecture and Massive Message Processing with Amazon SQS and Amazon DynamoDB explain how SQS can be used to build applications that are resilient and highly scalable.
Today we are making SQS even more useful by adding support for server-side encryption. You can now choose to have SQS encrypt messages stored in both Standard and FIFO queues using an encryption key provided by AWS Key Management Service (KMS). You can choose this option when you create your queue and you can also set it for an existing queue.
SSE encrypts the body of the message, but does not touch the queue metadata, the message metadata, or the per-queue metrics. Adding encryption to an existing queue does not encrypt any backlogged messages. Similarly, removing encryption leaves backlogged messages encrypted.
Creating an Encrypted Queue
The newest version of the AWS Management Console allows you to choose between Standard and FIFO queues using a handy graphic:
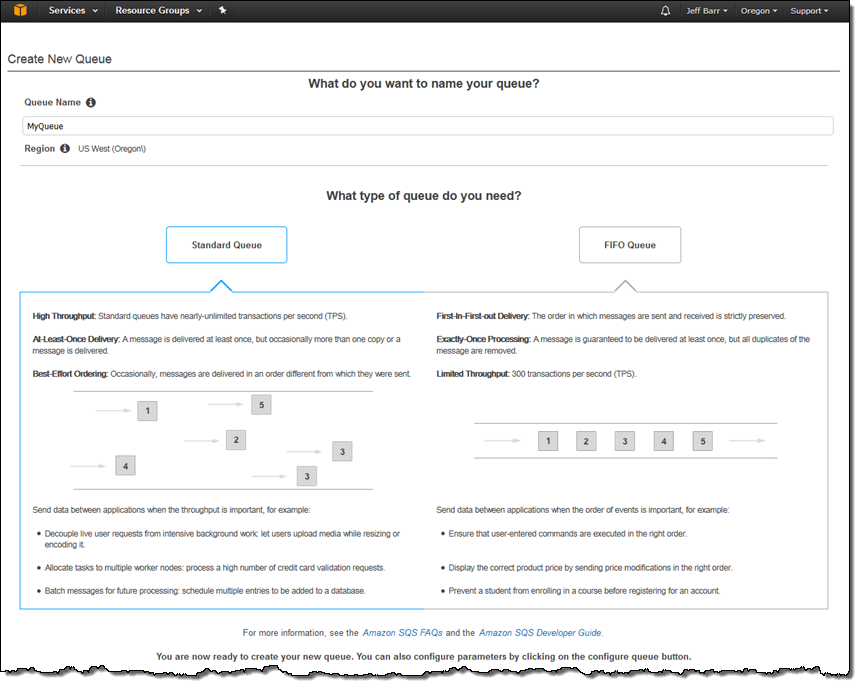
You can set the attributes for the queue and the optional Dead Letter Queue:
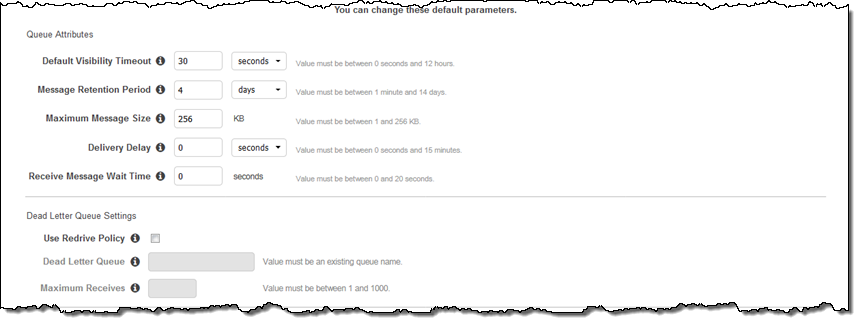
And you can now check Use SSE and select the desired key:
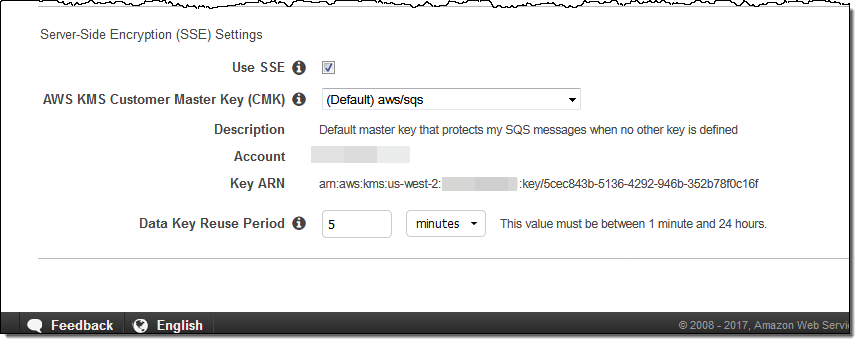
You can use the AWS-managed Customer Master Key (CMK) which is unique for each customer and region, or you can create and manage your own keys. If you choose to use your own keys, don’t forget to update your KMS key policies so that they allow for encryption and decryption of messages.
You can also configure the data reuse period. This interval controls how often SQS refreshes cryptographic information from KMS, and can range from 1 minute up to 24 hours. Using a shorter interval can improve your security profile, but increase your KMS costs.
To learn more, read the SQS SSE FAQ and the documentation for Server-Side Encryption.
Available Now
Server-side encryption is available today in the US West (Oregon) and US East (Ohio) Regions, with support for others in the works.
There is no charge for the use of encryption, but you will be charged for the calls that SQS makes to KMS. To learn more about this, read How do I Estimate My Customer Master Key (CMK) Usage Costs.
— Jeff;
New for Amazon Simple Queue Service – FIFO Queues with Exactly-Once Processing & Deduplication
As the very first member of the AWS family of services, Amazon Simple Queue Service (SQS) has certainly withstood the test of time! Back in 2004, we described it as a “reliable, highly scalable hosted queue for buffering messages between distributed application components.” Over the years, we have added many features including a dead letter queue, 256 KB payloads, SNS integration, long polling, batch operations, a delay queue, timers, CloudWatch metrics, and message attributes.
New FIFO Queues
Today we are making SQS even more powerful and flexible with support for FIFO (first-in, first-out) queues. We are rolling out this new type of queue in two regions now, and plan to make it available in many others in early 2017.
These queues are designed to guarantee that messages are processed exactly once, in the order that they are sent, and without duplicates. We expect that FIFO queues will be of particular value to our financial services and e-commerce customers, and to those who use messages to update database tables. Many of these customers have systems that depend on receiving messages in the order that they were sent.
FIFO ordering means that, if you send message A, wait for a successful response, and then send message B, message B will be enqueued after message A, and then delivered accordingly. This ordering does not apply if you make multiple SendMessage calls in parallel. It does apply to the individual messages within a call to SendMessageBatch, and across multiple consecutive calls to SendMessageBatch.
Exactly-once processing applies to both single-consumer and multiple-consumer scenarios. If you use FIFO queues in a multiple-consumer environment, you can configure your queue to make messages visible to other consumers only after the current message has been deleted or the visibility timeout expires. In this scenario, at most one consumer will actively process messages; the other consumers will be waiting until the first consumer finishes or fails.
Duplicate messages can sometimes occur when a networking issue outside of SQS prevents the message sender from learning the status of an action and causes the sender to retry the call. FIFO queues use multiple strategies to detect and eliminate duplicate messages. In addition to content-based deduplication, you can include a MessageDeduplicationId when you call SendMessage for a FIFO queue. The ID can be up to 128 characters long, and, if present, takes higher precedence than content-based deduplication.
When you call SendMessage for a FIFO queue, you can now include a MessageGroupId. Messages that belong to the same group (as indicated by the ID) are processed in order, allowing you to create and process multiple, ordered streams within a single queue and to use multiple consumers while keeping data from multiple groups distinct and ordered.
You can create standard queues (the original queue type) or the new FIFO queues using the CreateQueue function, the create-queue command, or the AWS Management Console. The same API functions apply to both types of queues, but you cannot convert one queue type into the other.
Although the same API calls apply to both queue types, the newest AWS SDKs and SQS clients provide some additional functionality. This includes automatic, idempotent retries of failed ReceiveMessage calls.
Individual FIFO queues can handle up to 300 send, receive, or delete requests per second.
Some SQS Resources
Here are some resources to help you to learn more about SQS and the new FIFO queues:
If you’re coming to Las Vegas for AWS re:Invent and would like to hear more about how AWS customer Capital One is making use of SQS and FIFO queues, register and plan to attend ENT-217, Migrating Enterprise Messaging to the Cloud on Wednesday, November 30 at 3:30 PM.
Available Now
FIFO queues are available now in the US East (Ohio) and US West (Oregon) regions and you can start using them today. If you are running in US East (Northern Virginia) and want to give them a try, you can create them in US East (Ohio) and take advantage of the low-cost, low-latency connectivity between the regions.
As part of today’s launch, we are also reducing the price for standard queues by 20%. For the updated pricing, take a look at the SQS Pricing page.
— Jeff;
New SQS Client Library for Java Messaging Service (JMS)
The Java Message Service (JMS) allows a pair of cooperating Java applications to create, send, receive, and read messages. The loosely coupled nature of JMS allows one part of the application to operate asynchronously with respect to the other.
Until now, you needed to stand up, maintain, and scale a multi-instance (for high availability) JMS server cluster if you wanted to make use of it within an application. Today we are launching a client library that implements the JMS 1.1 specification and uses Amazon Simple Queue Service (SQS) as the JMS provider. You can now count on the scale, low cost, and high availability of SQS and forget about running your own JMS cluster!
Getting Started
If you have an existing application that makes use of the JMS API, you can move it to SQS quickly and easily. Start by opening up the AWS Management Console and creating a queue:
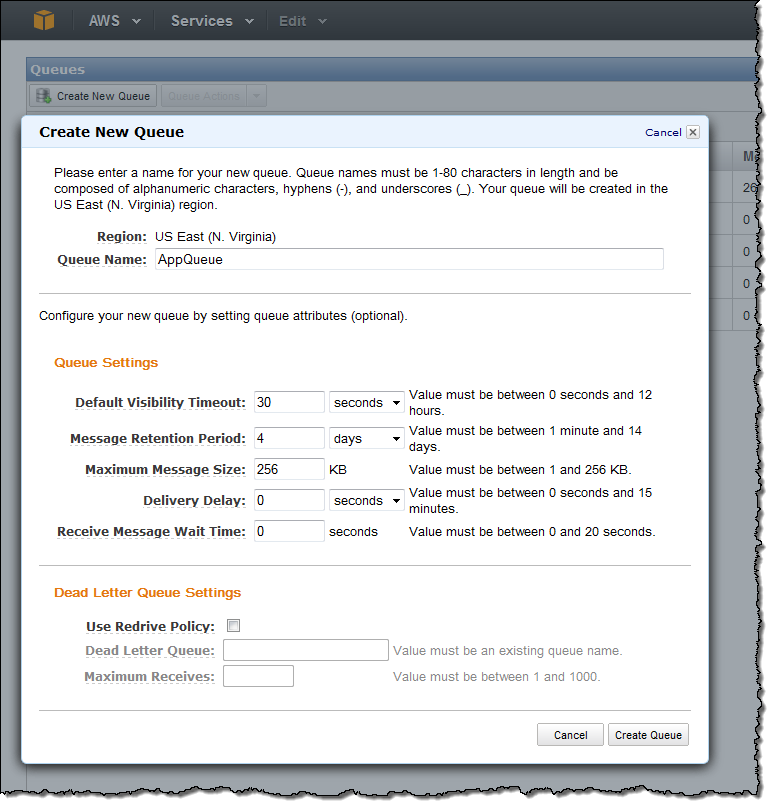
You can also create a queue using the AWS Command Line Interface (CLI), the AWS Tools for Windows PowerShell, or the
CreateQueue function.
Download the Amazon SQS Java Messaging Library JAR File and update your application’s CLASSPATH as appropriate. Then, configure your application’s connection factory to target the queue that you created.
Interesting Use Cases
Here are some of the ways that you can put this new library to use:
 Remove JMS Provider Cluster – You no longer need to run a JMS cluster. In addition to the reduction in hardware overhead (less servers to buy and maintain), you may no longer need to pay licensing and support fees for commercial software. Further, because SQS scales as needed, you don’t need to add hardware when the message rate or message size increases.
Remove JMS Provider Cluster – You no longer need to run a JMS cluster. In addition to the reduction in hardware overhead (less servers to buy and maintain), you may no longer need to pay licensing and support fees for commercial software. Further, because SQS scales as needed, you don’t need to add hardware when the message rate or message size increases.- Modularize Monolithic Java Apps – You can modularize and modernize monolithic Java apps without having to stand up a
JMS cluster. You can move to an architecture that is modern and
scalable while taking advantage of time-tested Java APIs. - Load Test Producers and Consumers – You can load test your custom producer and consumer clients at production scale without having to create a correspondingly large (yet temporary) JMS cluster. This will also allow you to gain experience with SQS and allow you to observe its scale and performance in comparison to your existing vendor-provided middleware.
- Overflow Handling -With some extra logic on the producer and the consumer, you can use your existing
JMS cluster for steady-state processing, backed by a new, SQS queue to handle the extra load at peak times.
Learn More
To learn more, take a look at Using JMS with Amazon SQS in the SQS Documentation. The documentation includes sample code and
full configuration information.
— Jeff;
Message Attributes for the Amazon Simple Queue Service
Way back in November of 2004 I wrote that “The Simple Queue Service offers a reliable, highly scalable hosted queue for buffering messages between distributed application components.” In the intervening years, we have enhanced SQS with additional features, while keeping in mind that “Simple” is part of the product’s name and appeal. Some of the most important additions include support for a dead letter queue, support for 256 KB payloads, Simple Notification Service integration, long polling, batch operations, a delay queue, and timers, and CloudWatch metrics.
Today we are enhancing SQS once again, with support for message attributes. You can use these attributes to pass name/value pairs to your application in addition to the unstructured, uninterpreted content in the message body.
All About Attributes
Each message attribute is a typed, name/value pair. Names can be up to 256 characters long, are case-sensitive, and must be unique within the message. The predefined type names are string, number, and binary. You can also augment the type with custom information by using a name of the form number.float or binary.png. SQS does not process or interpret the custom information.
Numbers can be positive or negative, integers or floating point, with up to 38 decimal digits of precision and a range from 10-128 to 10126. Strings are Unicode with UTF-8 encoding. Binary values can store any binary data including images.
You can attach up to ten attributes to each of your messages. The entire message, including the body plus all names, types, and values, can be as large as 256 KB (262,144 bytes).
Using Attributes
You can attach attributes to your messages using the AWS SDKs (Python support will be ready by the middle of the week; the other SDKs will be ready this evening). Here’s how you would attach a string attribute using the AWS SDK for Java:
Map messageAttributes = new HashMap();
messageAttributes.put("Owner",
new MessageAttributeValue()
.withDataType("String")
.withStringValue("Jeff Barr"));
And here is how you would attach a custom numeric value:
Map messageAttributes = new HashMap();
messageAttributes.put("SalesPrice",
new MessageAttributeValue()
.withDataType("Number.Dollars")
.withStringValue("655.35"));
You can also send an attributed message using the AWS Management Console:
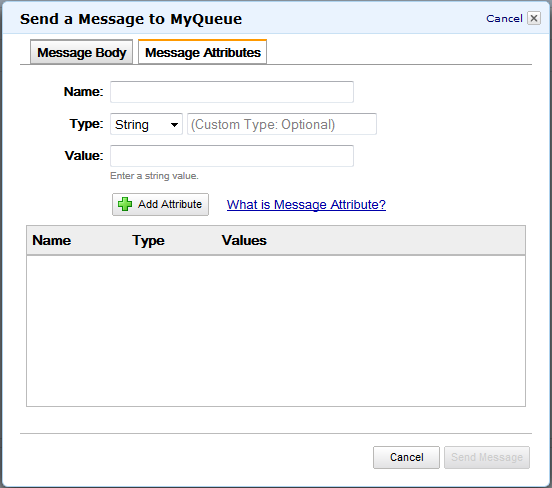
(the AWS GovCloud (US) Console will be updated later this week)
Some Use Cases
You could build a mobile application and allow your users to “check-in” and share gas prices as part of their fill-up, so that other users can find the closest gas station with the best price. The application would obtain the device location (latitude and longitude) from the operating system and attach it to an SQS message as a pair of float values and then send the message. On the backend, the message consumer process would receive the message, store the update in a database that supports geospatial queries (DynamoDB + the DynamoDB GeoSpatial Library and PostgreSQL are two good options), and send notifications to other users to update them on conditions in their area.
You could use the geospatial query support recently released for Amazon CloudSearch to implement targeting for local advertisements, find points of interest for an “around the town” application, and more.
Available Now
This new feature is available now and you can start using it today. You may want to start by reading the new documentation on Using Amazon SQS Message Attributes.
— Jeff;
AWS CloudFormation Adds Support for Redshift and More
My colleague Chetan Dandekar has a lot of good news for AWS CloudFormation users!
— Jeff;
AWS CloudFormation now supports Amazon Redshift. We have recently enhanced our support for other AWS resources as well.
What is CloudFormation?
AWS CloudFormation simplifies provisioning and management of a wide range of AWS resources, from EC2 and VPC to DynamoDB. CloudFormation enables users to model and version control the architecture they want in the CloudFormation template files. An architecture could be as simple as a single EC2 instance or as complex as a distributed database or the entire VPC configuration of an enterprise. (See CloudFormation sample templates). The CloudFormation service can automatically create the desired architecture (CloudFormation stacks) from the template files, without burdening the users with writing complex provisioning code.
CloudFormation speeds up provisioning by parallelizing creation and updating of stacks. The CloudFormation API lets you automate AWS provisioning and also gives you the ability to integrate it with the development and system management tools that you already use.
The CloudFormation templates can also be used to standardize and package products for broader users to use. (For example, an administrator can create a standard VPC configuration template for an entire developer team to use, and an ISV can package a distributed database configuration for its client to provision on AWS).
Amazon Redshift Support
![]() Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse service. You can now launch and manage Redshift clusters using CloudFormation. You can also document, version control, and share your Redshift configuration using CloudFormation templates. Here is a sample CloudFormation template provisioning a Redshift cluster.
Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse service. You can now launch and manage Redshift clusters using CloudFormation. You can also document, version control, and share your Redshift configuration using CloudFormation templates. Here is a sample CloudFormation template provisioning a Redshift cluster.
CloudFormation also supports the other AWS database services: Amazon RDS, Amazon DynamoDB, Amazon SimpleDB and Amazon ElastiCache.
Other Additions
Support for the following AWS features was added in early 2014:
- Auto Scaling scheduled actions and block device properties
- DynamoDB local and global secondary indexes
- SQS dead letter queue (DLQ)
- Updating Elastic Beanstalk applications
- Updating SQS queues and queue policy
- Updating S3 buckets and bucket policies
- Up to 60 parameters and 60 outputs in a CloudFormation template
Read the CloudFormation release notes for additional information on these changes.
To learn more about CloudFormation, please visit the CloudFormation detail page, documentation or watch this introductory video. We have a large collection of sample templates that makes it easy to get started with CloudFormation within minutes.
Background Task Handling for AWS Elastic Beanstalk
My colleague Abhishek Singh sent along a guest post to introduce a really important new feature for AWS Elastic Beanstalk.
— Jeff;
You can now launch Worker Tier environments in Elastic Beanstalk.
These environments are optimized to process application background tasks at any scale. Worker tiers complement the existing web tiers and are ideal for time consuming tasks such as report generation, database cleanup, and email notification.
For example, to send confirmation emails from your application, you can now simply queue a task to later send the email while your application code immediately proceeds to render the rest of your webpage. A worker tier in your environment will later pick up the task and send the email in the background.
A worker is simply another HTTP request handler that Beanstalk invokes with messages buffered using the Amazon Simple Queue Service (SQS). Elastic Beanstalk takes care of creating and managing the queue if one isnt provided. Messages put in the queue are forwarded via HTTP POST to a configurable URL on the local host. You can develop your worker code using any language supported by Elastic Beanstalk in a Linux environment: PHP, Python, Ruby, Java, or Node.js.
You can create a single instance or a load balanced and auto-scaled worker tier that will scale based on the work load. With worker tiers, you can focus on writing the actual code that does the work. You don’t have to learn any new APIs and you don’t have to manage any servers. For more information, read our new documentation on the Environment Tiers.
Use Case – Sending Confirmation Emails
Imagine, youre a startup with a game changing idea or product and youd like to gauge customer interest.
You create a simple web application that will allow potential customers to register their email address to be notified of updates. As with most businesses, you decide that once the customer has provided their email address you will send them a confirmation email informing them that their registration was successful. By using an Elastic Beanstalk worker tier to validate the email address and to generate and send the confirmation email, you can make your front-end application non-blocking and provide customers with a more responsive user experience.
The remainder of the post will walk you through creating a worker tier and deploying a sample Python worker application that can be used to send emails asynchronously. If you do not have a frontend application, you can download a Python based front-end application from the AWS Application Management Blog.
We’ll use the Amazon Simple Email Service (SES). Begin by adding a verified sender email address as follows:
- Log in to the SES Management Console and select Email Addresses from the left navigation bar.
- Click on Verify a New Email Address.
- Type in the email address you want to use to send emails and click Verify This Email Address. You will receive an email at the email address provided with a link to verify the email address. Once you have verified the email address, you can use the email address as the SOURCE_EMAIL_ADDRESS.
Next, download and customize the sample worker tier application:
- Download the worker tier sample application source bundle and extract the files into a folder on your desktop.
- Browse to the folder and edit the line that reads SOURCE_EMAIL_ADDRESS = ‘nobody@amazon.com in the default_config.py file so that it refers to the verified sender email address, then save the file.
- Select all of the files in the folder and add them to a zip archive. For more details on creating a source bundle to upload to Elastic Beanstalk, please read Creating an Application Source Bundle.
Now you need to create an IAM Role for the worker role. Here’s what you need to do:
- Log in to the IAM Management Console and select Roles on the left navigation bar.
- Click the Create New Role button to create a new role.
- Type in WorkerTierRole for the Role Name.
- Select AWS Service Roles and select Amazon EC2.
- Select Custom Policy and click Select.
- Type in WorkerTierRole for the Policy Name, paste the following snippet as the Policy Document, and click Continue:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ses:SendEmail" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "sqs:*" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Action": [ "cloudwatch:PutMetricData" ], "Resource": [ "*" ] } ] } - Click Create Role to create the role.
You are now ready to create the Elastic Beanstalk application which will host the worker tier. Follow these steps:
- Log in to the AWS Elastic Beanstalk Web Console and click on Create New Application
- Enter the application name and description and click Create
- Select Worker for the Environment tier drop down, Python for the Predefined configuration and Single instance for Environment type. Click Continue.
- Select Upload your own and Browse to the source bundle you created previously.
- Enter the environment name and description and click Continue.
- On the Additional Resources page, leave all options unselected and click Continue.
- On the Configuration Details page, select the WorkerTierRole that you created earlier from the Instance profile drop down and click Continue.
- On the Worker Details page, modify the HTTP path to /customer-registered and click Continue.
- Review the configuration and click Create.
Once the environment is created and its health is reported as Green, click on View Queue to bring up the SQS Management Console:
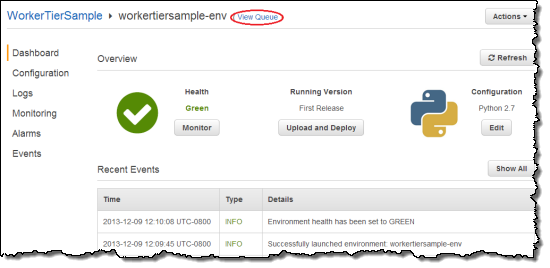
Then Click Queue Actions and select Send a Message.
Type in messages in the following format; click Send Message to send a confirmation email:
{ "name" : "John Smith", "email" : "john@example.com" }
This new feature is available now and you can start using it today.
— Abhishek Singh, Senior Product Manager
Larger Payloads (256 KB) for Amazon SQS and SNS
Today we are raising the maximum payload size for the Amazon Simple Queue Service (SQS) and the Amazon Simple Notification Service (SNS) from 64 KB to 256 KB.
We are also adding a new option to allow you to opt for delivery of SNS messages in raw format, in addition to the existing JSON format. This is useful if you are using SNS in conjunction with SQS transmit identical copies of a message to multiple queues.
Here’s some more information for you:
- 256KB Payloads (SQS and SNS) allows you to send and receive more data with each API call. Previously, payloads were capped at 64KB. Now, large payloads are billed as one request per 64KB ‘chunk’ of payload. For example, a single API call for a 256KB payload will be billed as four requests. Our customers tell us larger payloads will enable new use cases that were previously difficult to accomplish.
- SNS Raw Message Delivery allows you to pack even more information content into your messaging payloads. When delivering notifications to SQS and HTTP endpoints, SNS today adds JSON encoding with metadata about the current message and topic. Now, developers can set the optional RawMessageDelivery property to disable this added JSON encoding. Raw message delivery is off by default, to ensure existing applications continue to behave as expected.
Getting started with Amazon SNS and Amazon SQS is easy with our free tier of service. To learn more, visit the Amazon SNS page and the Amazon SQS page. To learn more about subscribing SQS queues to SNS topics, visit the SQS developer reference guide.
— Jeff;