Category: Amazon Polly
Amazon Polly – スピーチマークとウィスパーを発表
私のように、あなたは好きな本を読んでもらうために図書館か書店に行くのが好きかもしれません。幼い頃、声の抑揚を変えて話に命を吹き込むことができる上手な物語作家が物語る本の話を聞くのが好きでした。物語作家がよく使うスライド付きの本のナレーションは、新しい本を読んだり、見つけたりする私の趣味を駆り立てました。
実際、私の読書に関する趣味が古典小説にいたるように、両親はテープレコーダー付きの小さなプロジェクターを姉妹と私に買ってくれました。このプロジェクターは話を物語り、次のスクリーンに進むべきタイミングをチャイム音で知らせ、本と映像の投影を同期しました。不運にも、私はその話に夢中になってしまったけれど、私たちが TTS のようなスピーチ技術を実現するのにどれくらいの位置にいるのかについて振り返り、考えることが私にとって重要でした。あらゆるスピーチ技術の進歩をもってしても、TTS を利用して、ゲームやビデオ、デジタル書籍の中でキャラクターのアニメーションやグラフィックスに同期した会話/音声を追加することはデベロッパーにとって今だチャレンジングなものでした。加えて、リアルな音声のピッチやテンポ、音圧の強さを模倣するために TTS を利用したソリューションの成功事例は非常に稀でした。
これを踏まえて、Amazon Polly がスピーチマークとウィスパーをサポート開始することを私は喜んで発表します。

Amazon Polly はテキストをリアルな音声に変換することを可能にする深層学習を利用したサービスです。サービスが提供する24の言語と47のリアルな音声から好きな音声を選択することが可能です。Polly を使って、音声に変換したいテキストを Polly の API に送信することができます。そして、API は再生、もしくは、MP3 のような共通オーディオファイルフォーマットに保存可能なオーディオストリームを返却します。
スピーチマークはデベロッパーが映像体験と会話の同期を可能とするメタデータです。この機能は、会話を顔のアニメーションと同期することや、カラオケスタイルの単語の強調表示を利用することで、リップシンクのようなシナリオを可能とします。スピーチマークメタデータは合成された音声を記述します。そして、スピーチマークメタデータを会話と一緒に使うことにより、音声ストリームが音、語句、文、そして SSML タグの始まりと終わりを決定することができます。新しいスピーチマークを利用することで、デベロッパーは今、リップシンクするアバターや視覚的に強調表示された読み下し体験を生み出すことができ、そして、キャラクターに声を与えるために Amazon Lumberyard のようなゲーミングエンジンに会話能力を統合することができます。
スピーチマークには4つの種類があります:
- 文: 入力テキストの1文要素を明示する
- 語句: 入力テキストの1単語要素を表す
- ビゼーム(Viseme): 話された音に対応する顔と口の位置を説明する
- Speech Synthesis Markup Language(SSML): SSML で表現された入力テキストから <mark> タグを記述する
ウィスパーはピッチやテンポ、音圧と似たスピーチエフェクトの1つで、デベロッパーに TTS 出力を装飾可能とするもう一つの音声表現機能を提供します。ウィスパー機能はデベロッパーが <amazon:effect name=”whispered”> SSML タグを使って、ささやき声で話される言葉を持つのを可能とします。
これら2つの新しい機能について、見てみることにしましょう。
スピーチマークの利用
AWS 管理コンソールで Amazon Polly を使ってスピーチマークを利用する例にさっそく入ります。まず最初に Amazon Polly のコンソールに移動し、Get Startedボタンを押下します。
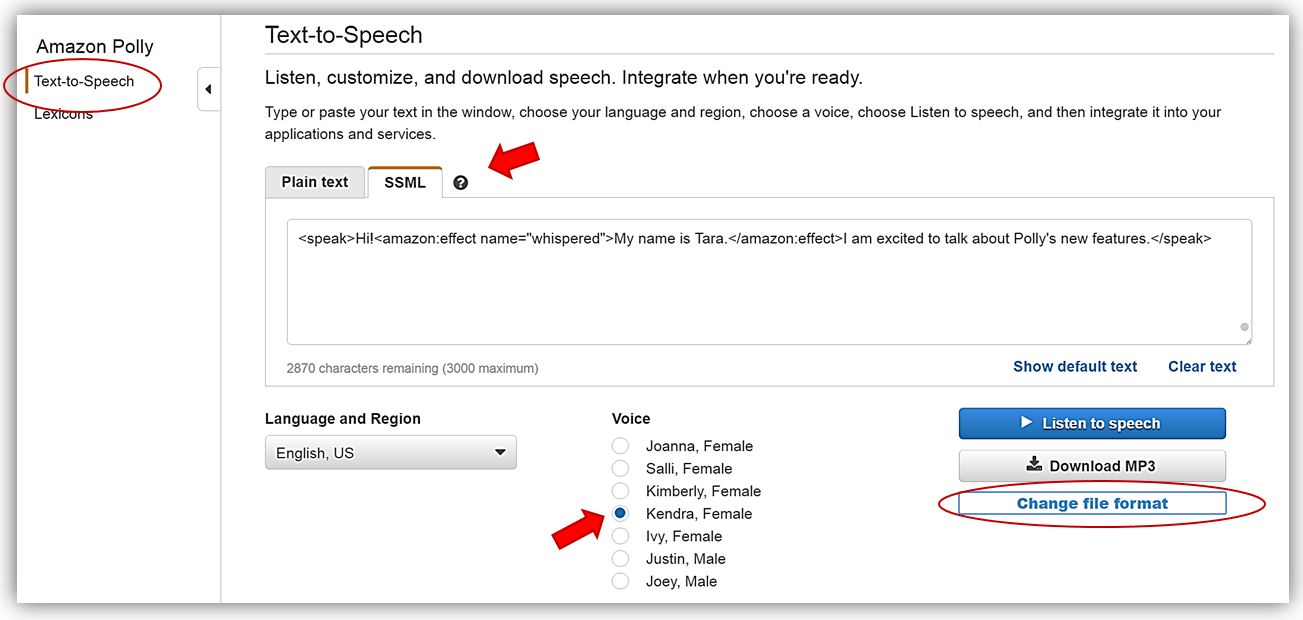
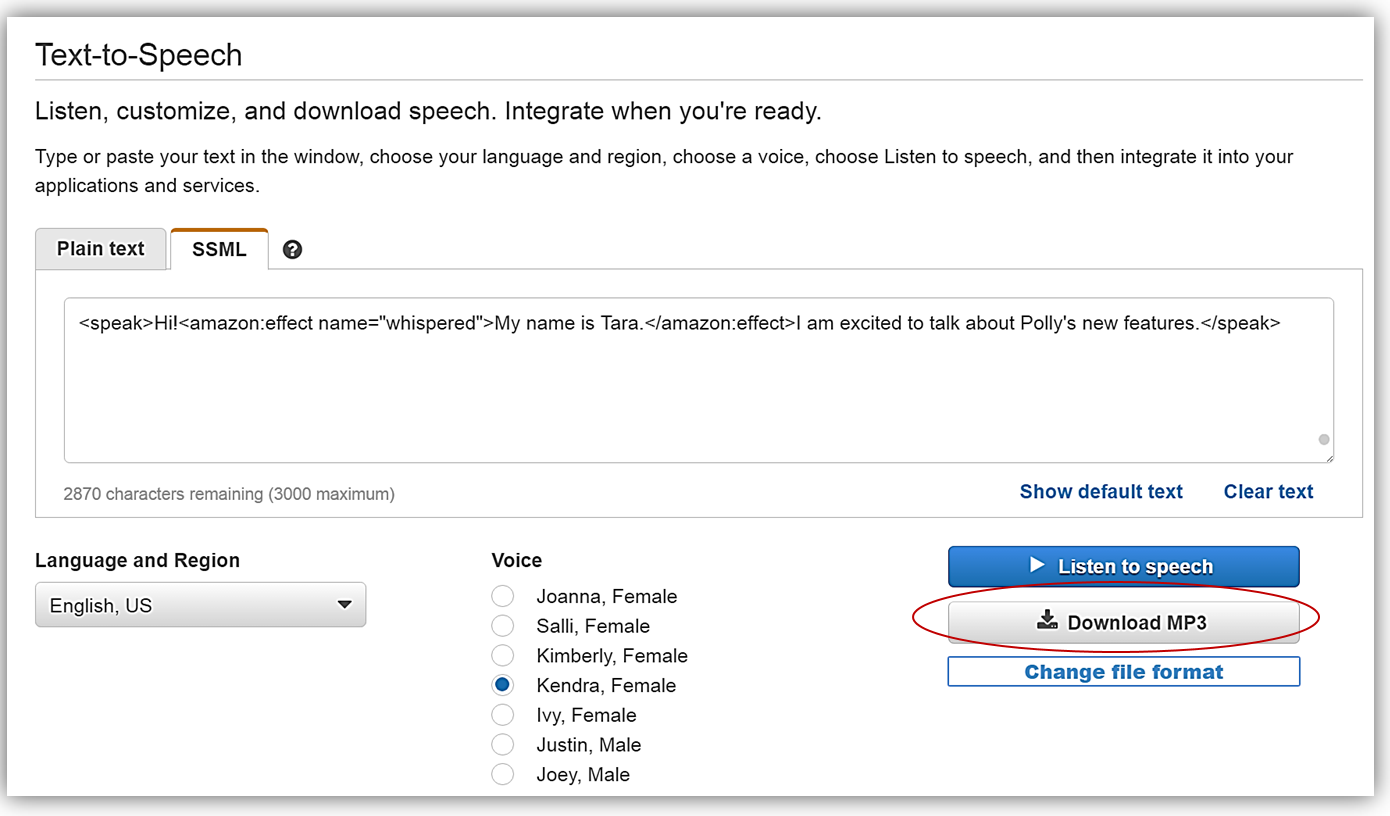
Text-to-Speech (テキスト読み上げ機能) メニューオプションに入り、Text-to-Speech (テキスト読み上げ機能)セクションの下の SSML を選択します。話してほしい2文を提供されたテキストフィールドに単純に追加し、音声を選択します。
Listen to Speech (音声を聴く) ボタンをクリックしてフォームに設定された文章を確かめます。聞いた内容が良かったので、スピーチマークメタデータを追加する手順に進みます。スピーチマークを利用するため、Change file format (ファイル形式を変更) リンクを選択します。
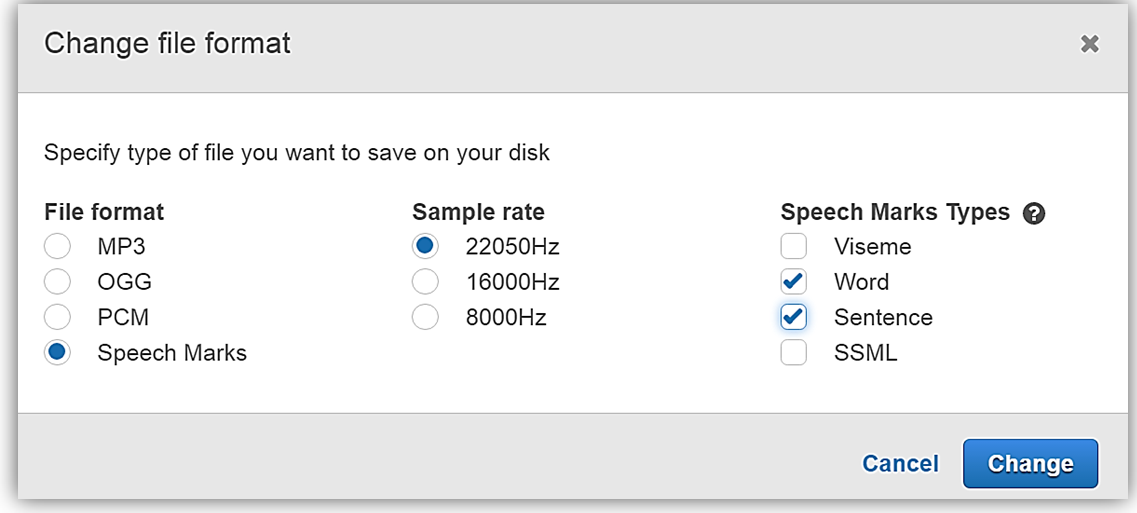
Change file format (ファイル形式を変更) 画面がポップアップするので、File Format (出力形式) からスピーチマークを選択し、スピーチマークのタイプセクションの下のチェックボックスをチェックして、Word(語句) と Sentence(文) を選択します。さあ、Change (変更) ボタンをクリックしましょう。
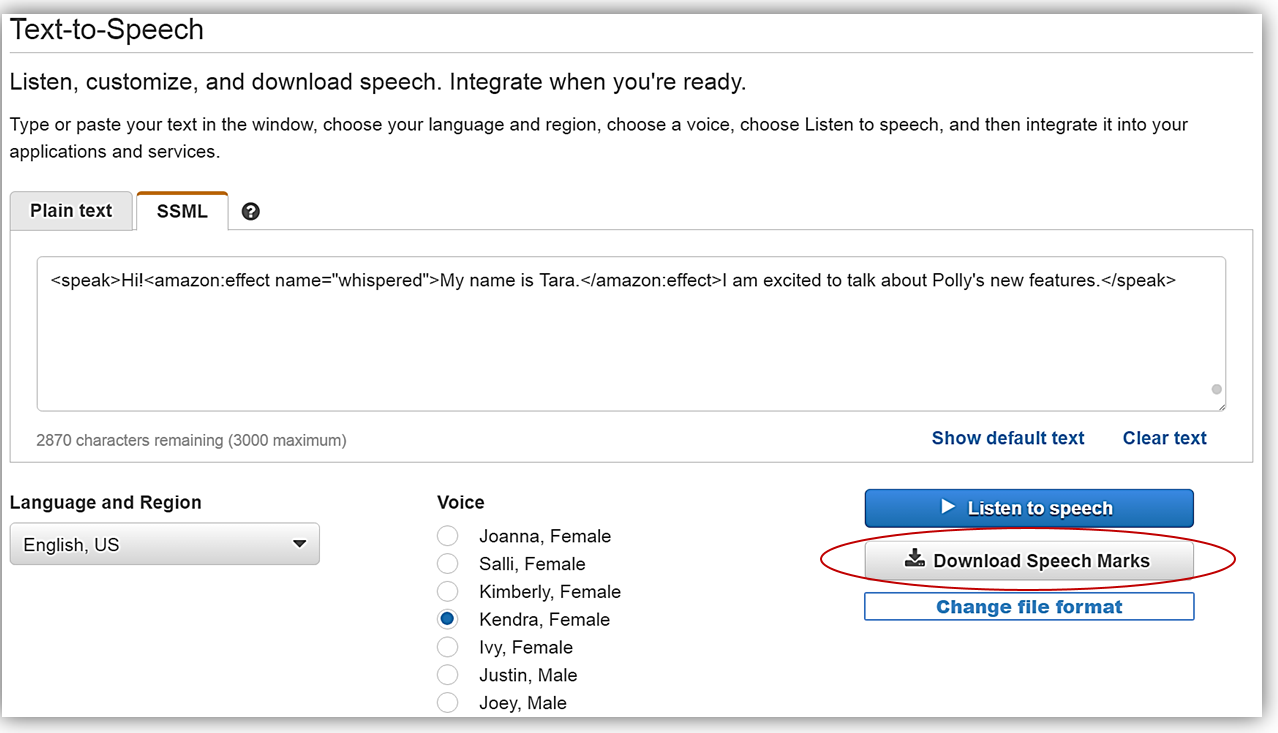
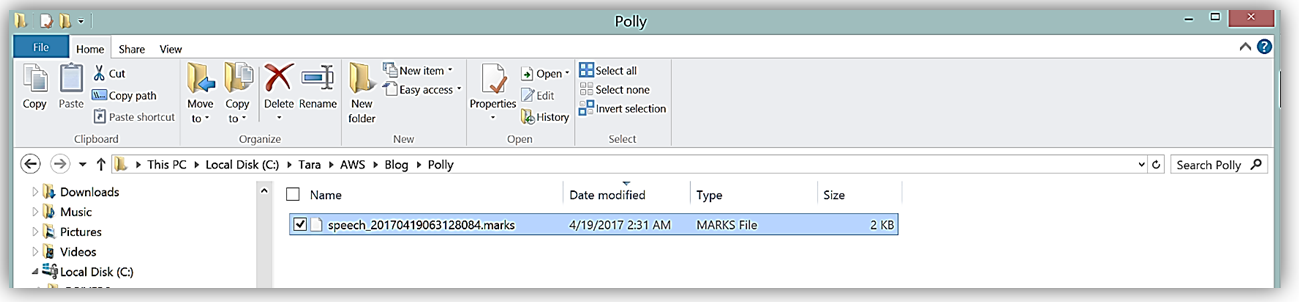
クリックすると、コンソールの Text-to-Speech (テキスト読み上げ機能) セクションに戻るので、生成されたスピーチマークを確かめるため、Download Speech Marks (Speech Marks のダウンロード) ボタンをクリックします。
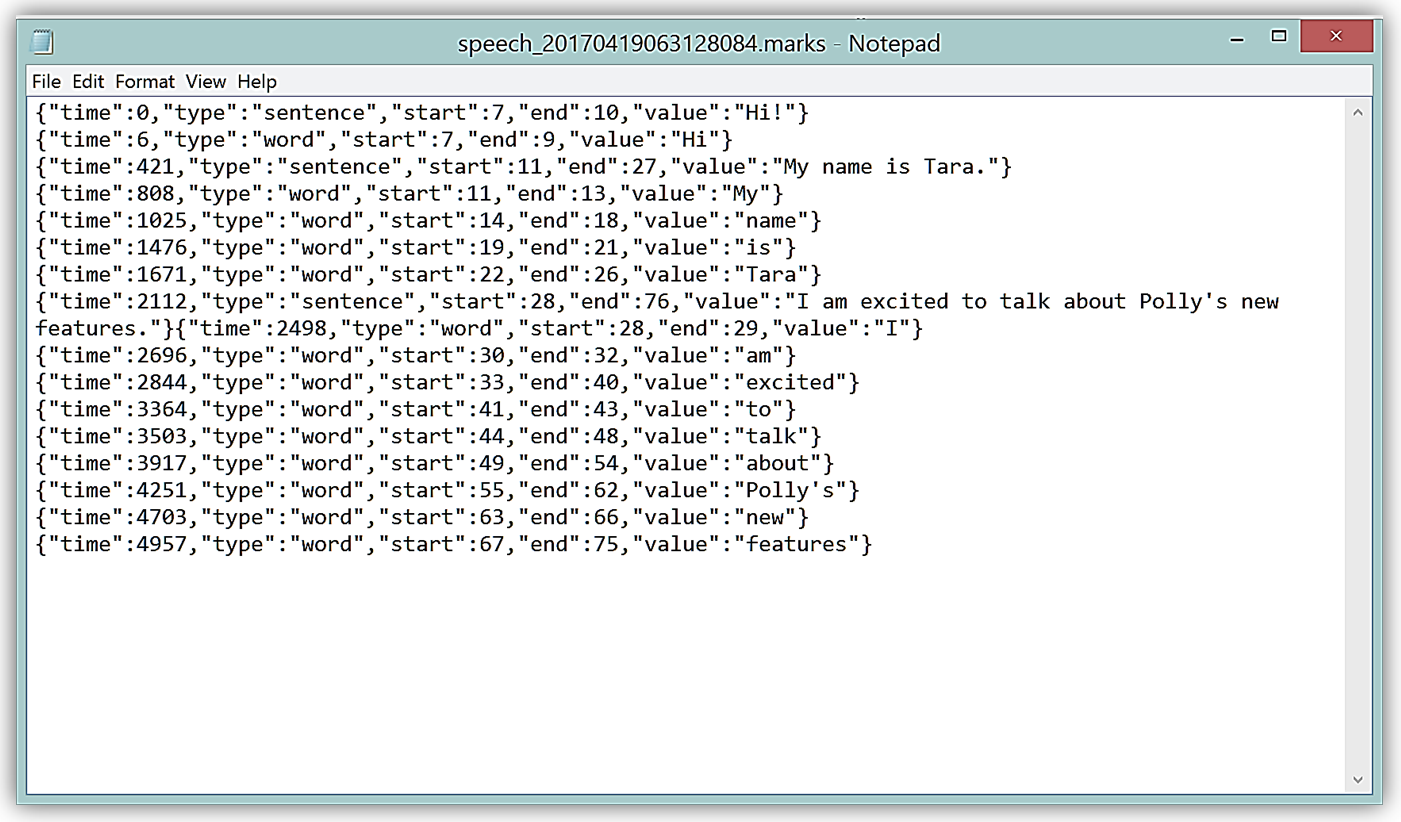
ダウンロードファイルは .marks 拡張子のファイルで、JSON 形式になっており、設定した文と語句それぞれについて最初と最後に関する情報が含まれています。JSON の変数は下記の通りです。
- Time: オーディオストリーム開始からのミリ秒単位経過時間
- Type: スピーチマークの種別(viseme, sentence, word, SSML)
- Start: 入力テキストにおける特定要素に関する先頭からのバイトオフセット(viseme は含まない)
- End: 入力テキストにおける特定要素の最後のバイトオフセット(viseme は含まない)
- Value: スピーチマーク種別に基づき様々な形式となるデータ(例: 文スピーチマークはテキスト中の文全体を含んでいる)
ウィスパーの利用
以前に指摘したように、ウィスパー機能を使うと whispered が値に設定された name 属性を持つ SSML amazon:effect タグを使ってささやき声で話される入力テキストを持つことが可能となります。上記の例を利用し、ささやき声を使って話されるように SSML タグを入力します。
Amazon Polly のコンソールに戻り、文章(“My name is Tara“)に新しいささやき声機能を使うため、設定されている現在のテキストを修正します。これを達成するため、次のSSMLタグを使用します: <amazon:effect name=”whispered”>。故、テキストボックスに入力した文章に SSML タグを入れた最終的な文章は次のようになります:
<speak>Hi!<amazon:effect name="whispered">My name is Tara.</amazon:effect>I am excited to talk about Polly's new features.</speak>Listen to speech (音声を聴く) ボタンをクリックすると、文(“My name is Tara“)が本当にささやき声で話されているのが聴けます。
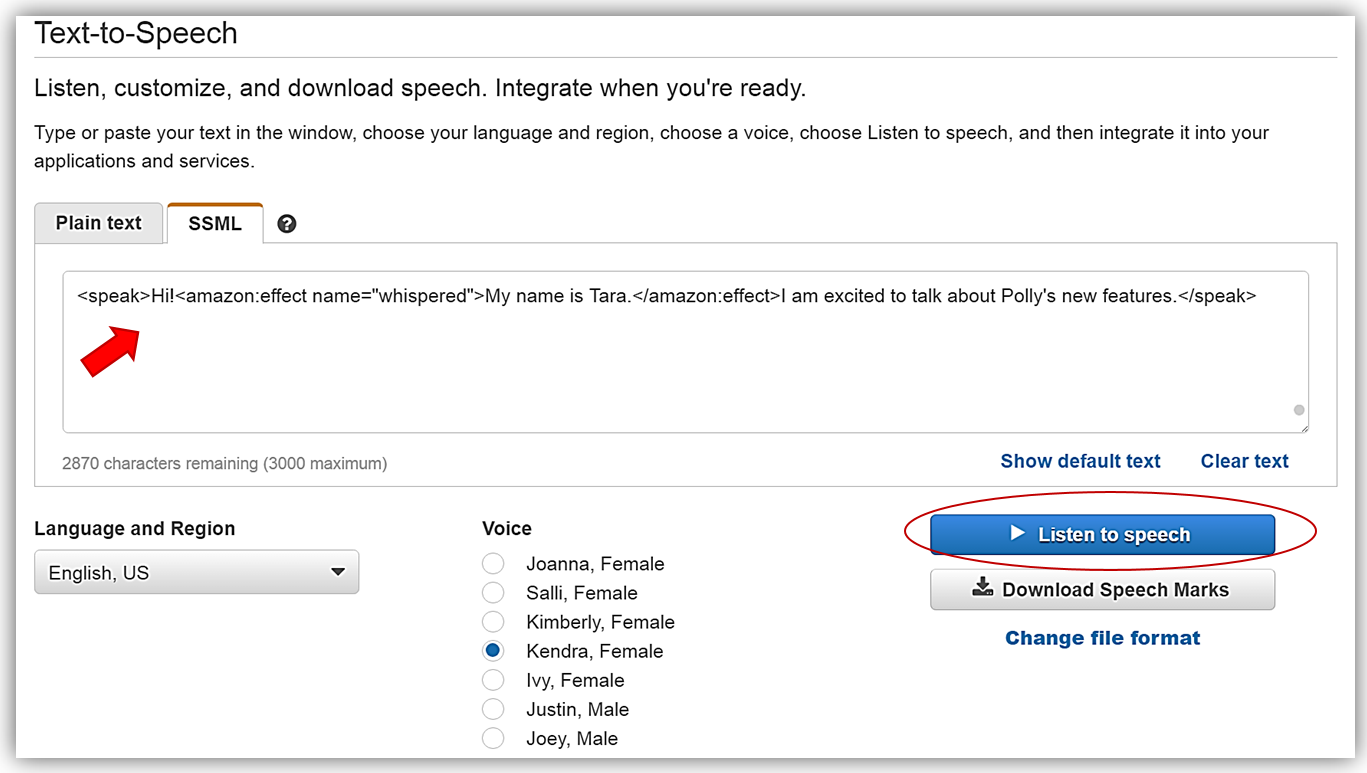
会話出力をダウンロードしたいので、Change file format (ファイル形式を変更) リンクをクリックします。Change file format (ファイル形式を変更) 画面がポップアップするので、File Format (出力形式) セクションの下から MP3 オプションを選択してから Change (変更) ボタンをクリックします。
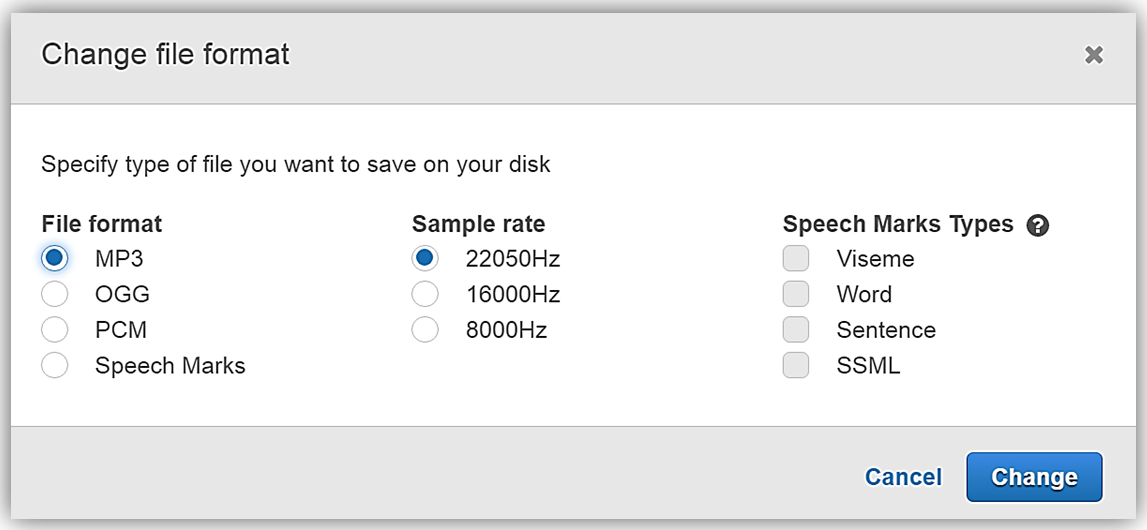
今、私は Download MP3 (MP3 のダウンロード) ボタンをクリックしてファイルをダウンロードするオプションを持っています。
ここをクリックすることにより、新しいささやき声を使った会話出力を聞くことができます。
まとめ
スピーチマークとウィスパー機能は Amazon Polly で本日からご利用いただくことが可能です。これらの機能やその他の機能についてもっと学ぶには、以下のリンクにある Amazon Polly デベロッパーガイドをご確認ください。
http://docs.aws.amazon.com/polly/latest/dg/
Amazon Polly に関する詳細は Amazon Polly の製品ページを参照いただくか、もしくは、Amazon Polly のコンソールでテキストを音声に変換するところから始めてください。
今日、Amazon Polly を使って、あなたのテキストに声の贈り物を与えるべきです。
– Tara
(翻訳: SA川村,原文: Amazon Polly – Announcing Speech Marks and Whispering)
Pollexy – Amazon Polly と Raspberry Pi で構築した特別なニーズをサポートする音声アシスタント
4 月は Autism Awareness month (自閉症啓発月間) です。米国では 68 人中に 1 人の子供が自閉症スペクトラム障害 (ASD) と診断されています (2014 年 CDC 調査)。 今回のブログでは AWS のシニア DevOps クラウドアーキテクトの Troy Larson が、息子の Calvin をサポートするために取り組んでいるプロジェクトについて紹介します。これまでにも、AWS がどのようにしてこれほどたくさんの様々なアイデアを出し合えるのか聞かれたことがあります。場合によっては、とても個人的な理由で大切な誰かの役に立ちたいという願いからアイデアが浮かぶこともあるのですが、この Pollexy はまさにその例です。まずは Pollexy に関する記事を読んでから、こちらの動画をご覧ください。 -Ana
-Ana
背景
私はここ何年もの間、自閉症で会話の少ない 16 歳のティーンエイジャーの親であるコンピュータプログラマーとして、どうにかテクノロジーを使ってより安全で幸せかつ快適な暮らしをつくることができないかと常に模索していました。このプロジェクトのチャレンジとなる根源は、人との交流におけるすべての基本、つまりコミュニケーションです。息子の Calvin は口頭による指示には反応しますが、責任を持って発言することができません。彼のこれまでの人生において、私達が会話をしたことは一度もないのです。自分の部屋で一人で遊んでいることはできても、すべてのタスクや一連のタスクをこなすには、他の誰かが口頭で彼に促す必要があります。我が家には他にも子供がおり、家庭内で担当するその他の役割もありますから、Calvin にかかりっきりになることで家庭内の雰囲気に負の影響が出てしまうことも否めません。
事の発端
去年開催された re:Invent で Amazon Polly と Amazon Lex のことを初めて耳にしてから、すぐにこうした技術を活用してどのように息子をサポートできるか考え始めました。息子は人による口頭指示に対しては問題なく対応することができますが、デジタル音声を理解することはできるのだろうか? という疑問がありました。そこで、ある土曜日に Raspberry Pi を息子の部屋に設定し、ドアを閉め、息子に気付かれないように家族と一緒に様子をうかがってみることにしました。Raspberry Pi に接続し、聞き慣れた西海岸の発音による Joanna を選び Polly を介して息子に問いかけてみました。「Calvin、トイレ休憩の時間だよ。部屋から出てトイレに行きなさい。」すると、数秒後に息子の部屋のドアノブが回る音がしました。我々家族は思わず隠れていた場所から頭を出して覗いてみると、息子はよく分からないといった顔つきで私をちらりと見て、そのまま Joanna が指示したようにバスルームに向かっていったのでした。Calvin が聞いたことも見たこともない人物の声による指示を聞き、それに応えたことを目の当たりにした私達は驚きで顔を見合わせたほどです。この一件に関するアイデアを同僚達と話し合ったところ、そのうちの一人が、毎年恒例の AWS Sales Kick-Off ミーティングで開催される IoT と AI のサイエンスフェアに参加してみたらどうだろう、と提案してきました。Polly と Lex のリリースから 2 か月そして 3500 ものコードを作成後、Pollexy は (Calvin 同伴) サイエンスフェアでデビューを飾りました。
概要
Pollexy (“Polly” + “Lex”) は Raspberry Pi とモバイルベースの特別なニーズに応える音声アシスタントです。ヘルパーは Pollexy を使用して、音声によるタスクの指示や、定期的に行うスケジュールもしくはオンデマンドのスケジュールに関するメッセージを再生するように設定できます。たとえば、ヘルパーは定期的に服用する薬のリマインダーメッセージをスケジュールしたり、毎時間のトイレ休憩を促すメッセージを設定することができます。また、同時に Amazon Echo とモバイルデバイスを使用して特定のメッセージをすぐに再生するようにリクエストすることも可能です。ヘルパーは相手がメッセージを聞いたか確認するように設定することもできます。たとえば、Pollexy が最初に「青いボタンを押してください (Push the blue button)」と言わない限り、息子は Pollexy に反応しません。息子が青いボタンを押すまで、Pollexy はメインのメッセージを再生しないようになっています。また他の状況では Lex を使用して口頭で応答したり、確認が不要なユーザーもいるでしょう。どちらにしても、自分のニーズに適うように Pollexy をカスタマイズすることができるのです。そしてもっとも重要かつチャレンジとなるポイントは、大きな家に住んでいる場合、メッセージを再生する部屋に相手がいるか確認するにはどうしたらいいのか? という点です。特別なニーズのある大人が離れに住んでいる場合はどうでしょう?リビングにいるのかキッチンにいるのか分からない場合は?相手が複数人いる場合は?屋内にいる複数の人物がそれぞれ別の部屋にいた場合、各自にそれぞれ別のメッセージを送りたい場合はどうでしょう?では、次に基本的な要素と全容についてご説明します。
Pollexy の基本的要素
Amazon のリーダーシッププリンシプルは「Invent and Simplify (発明と簡素化)」です。Amazon では Pollexy アーキテクチャの複雑性を最小限に抑えたいと考えています。Pollexy で連係しているオブジェクトとコンポーネントは、簡単に説明できる方法でそれぞれ 3 つのタイプに分けることができます。

オブジェクト #1: ユーザー
Pollexy でサポートできるユーザー数には制限がありません。ユーザーは独自の特定できる名前です。「確認する」など基本的な事項を設定できます。さらに大きなポイントは場所をスケジュールで特定できることです。つまり、誰かがいる家の特定の場所に対して Outlook のようなスケジュールを作成することができるのです。
オブジェクト #2: 場所
場所はデバイスが物理的に設置されている独自の場所を識別します。ユーザーのロケーションスケジュールをベースに、Pollexy はどのデバイスを順次に使用して連絡するか把握することができます。必要に応じてデバイスを「消音」モードにすることもできます (お昼寝中など)。
オブジェクト #3: メッセージ
もちろん、これが本来の目的です。各メッセージには、ユーザーそして定期的に実行するスケジュールが連携されます (1 回限りのメッセージを除く)。Pollexy はメッセージの再生準備が整うと、ユーザーの場所を確認することができるのでメッセージには場所情報は保存されません。
コンポーネント #1: スケジューラー
メッセージはどれもスケジュールする必要があります。これはコマンドラインツールです。たとえば「Calvin に「午後 8 時までに歯を磨くこと」と伝えてください」と言った場合、このメッセージは DynamoDB に保管され、Lambda 関数のキューイングを待つことになります。
コンポーネント #2: キューイングエンジン
Lambda はスケジューラーを毎秒ごとに実行しチェックして、メッセージがあるか、また再生できるメッセージがあるか確認します。再生するメッセージがある場合、ユーザーの場所のスケジュールを確認してメッセージを再生またはその場所に SQS キューを送ります。
コンポーネント #3: スピーカーエンジン
Raspberry Pi デバイスでは毎分ごとにスピーカーエンジンが起動し、その場所の SQS を確認します。メッセージがある場合、スピーカーエンジンはユーザーの設定を確認しメッセージを再生するためにコミュニケーションを開始します。相手が応答しない場合、スピーカーエンジンはスケジュールでそのユーザーに別の場所が指定されているか確認し、その 2 番目の場所の SQS キューにメッセージを送ります。結果としてメッセージは再生されるか、タイムアウトになります (そのユーザーが 1 日中留守にしている場合など)。
ユーザーへの配慮と自由がキーポイント
私達は大方、個人のプライバシーや個人情報への配慮というものはごく普通のことだと捉えていると思います。特別なサポートを必要としている人達にとって、常に誰かに見られているということは、プライバシーや自由というものがどれだけ欠如している状況であるのか想像してみてください。自閉症と向き合っている人達にとっては、他者が個人のスペースに入り込むことを強く疎ましく思い、場合によってはそれが怒りや不満に繋がることもあります。Pollexy は不満をもたらすことがなく、穏やかな友達といった存在として日常におけるサポートを提供し、ユーザーに自信を持たせながら、誰もが望む個人のプライバシーや自由が尊重されていると思わせることができるツールです。
-Troy Larson