Category: Auto Scaling
新機能 – EC2 Auto Scalingのターゲットトラッキングポリシー
先日DynamoDBのAuto Scalingについてお伝えし、そこでDynamoDBテーブルのキャパシティ管理を自動化するためにどのように複数のCloudWatchアラームを利用しているかをお見せしました。その裏では、これからいくつかの異なるAWSサービスに渡って利用が予定されている、もっと一般化されたApplication Auto Scalingのモデルを使うことでこの機能を実現しています。
新しいAuto Scalingのモデルはターゲットトラッキングと呼ばれる重要な新しい機能を含んでいます。ターゲットトラッキングを使ってAuto Scalingのポリシーを作成する時には、特定のCloudWatchメトリクスに対してターゲットとなる値を選択します。Auto Scalingはそのメトリクスがターゲットに向かう様に適切な(スピーカーで言う)つまみを回し、合わせて関連するCloudWatchアラームも調整します。どういったメトリクスであれアプリケーションにとって意味のあるもので必要なターゲットを指定するという方法は、元々あるステップスケーリングポリシーの様に手動でメトリクスのレンジと閾値を設定するよりも、一般的にはより簡単で直接的なやりかたです。しかし、より高度なスケーリング戦略を実装するために、ターゲットトラッキングとステップスケーリングを組み合わせることも可能です。例えば、スケールアウトにはターゲットトラッキングを使い、スケールインにはステップスケーリングを使う等が考えられます。
EC2に新しい機能
本日、EC2 Auto Scalingにターゲットトラッキングのサポートを追加しました。Application Load Balancerのリクエスト数、CPU負荷、ネットワークトラフィック、またはカスタムメトリクスによるスケーリングポリシーを作成することができます(ターゲット毎のリクエスト数というメトリクスは新しいもので本日のリリースの一部になります)。
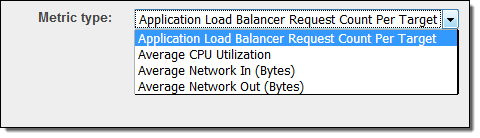
これらメトリクスは重要な特徴が共通しています: EC2インスタンスを追加することで(全体の負荷が変化していない時に)、メトリクスを下げることになります。もしくはその逆もです。
ターゲットトラッキングを使ったAuto Scaling Groupを作るのは簡単で、ポリシーの名前を入力し、メトリクスを選択し、希望するターゲットの値を設定するだけです:
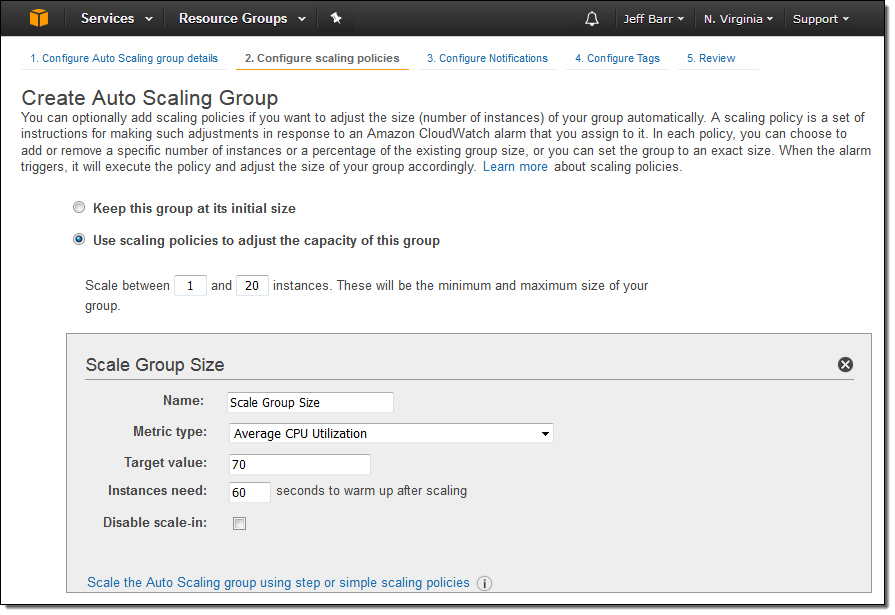
スケールイン側のポリシーを無効にすることもできます。その場合、手動でスケールインしたり、別のポリシーを使うことができます。
ターゲットトラッキングポリシーは、AWS Management Console、AWS Command Line Interface (CLI)、またはAWS SDKでも作成することができます。
以下は、ターゲットトラッキングを使おうとする時に頭にいれておくべき項目になります:
- 1つのAuto Scaling Groupに対して、異なるメトリクスを参照している複数のターゲットを設定することができます。スケーリングは常に一番高いキャパシティを求めるポリシーに従います。
- メトリクスのデータが不十分な時はスケーリングは発動しません。
- Auto Scalingはメトリクスの急速で一時的な変動を補い、関連するキャパシティの急激な変動を最小化しようと努力します。
- カスタムメトリクスでのターゲットトラッキングはAuto Scaling APIやAWS Command Line Interface (CLI)で設定することができます。
- 多くのケースで、1分間隔で入ってくるメトリクス(詳細モニタリングとも言われます)に応じてスケールするように選択すべきです。5分間隔のメトリクスをスケーリングの基本にすると、反応時間が遅くなってしまいます。
本日から利用可能です
この新しい機能は本日から利用可能で、追加料金無しに使い始められます。より詳しくは、Auto Scalingユーザガイドのターゲットトラッキングスケーリングをご覧ください。
— Jeff;
原文: New – Target Tracking Policies for EC2 Auto Scaling (翻訳: SA岩永)
Amazon ECS におけるコンテナ インスタンス ドレイニングの自動化方法
同僚のMadhuri Periが素晴らしい記事を書いてくれました。AutoScalingグループのクラスタをスケールダウンする際にインスタンスからタスクを事前に削除するために、コンテナ インスタンス ドレイニングを利用する方法です。
—–
Amazon ECSクラスタでは、クラスタからインスタンスを削除する必要があるタイミングというのがいくつかあります。例えば、システムを更新するとき、Dockerデーモンを更新するとき、あるいはクラスタのサイズをスケールダウンするときなどです。コンテナ インスタンス ドレイニング機能によって、クラスタ上のタスクに影響を与えることなく、コンテナインスタンスを削除することができます。この機能により、コンテナインスタンスがDRAINING状態である間はそのインスタンスに対して新しいタスクの配置がスケジュールされないようになり、利用可能なリソースがあればサービスがタスクをクラスタ上の他のコンテナインスタンスに移動してくれ、インスタンスを削除する前にタスクの移動が成功したことを待機できるようになります。
コンテナインスタンスの状態は、手動でDRAININGに変更することが可能です。しかしこの記事では、これらのプロセスを自動化するためにAutoScalingグループとAWS Lambdaを利用してコンテナ インスタンス ドレイニングを行う方法を説明します。
Amazon ECS オーバービュー
Amazon ECSはコンテナ管理サービスです。クラスタやEC2インスタンスの論理グループ上でDockerコンテナの実行、停止、そして管理を容易にしてくれます。ECSを使ってタスクを実行するとき、タスクはクラスタに配置されます。Amazon ECSは指定されたレジストリからコンテナイメージをダウンロードし、そしてそのイメージをクラスタ内のコンテナインスタンス上で実行します。
コンテナ インスタンス ドレイニングの状態を扱う
AutoScalingグループはライフサイクルフックをサポートしています。ライフサイクルフックは、インスタンスの起動や削除の前に独自の処理を完了するために呼び出されます。今回の例では、ライフサイクルフックは、2つの処理を実行するLambdaファンクションを呼び出します。
- ECSコンテナインスタンスの状態をDRAININGに変更します。
- コンテナインスタンス上にタスクが1つも残っていないことを確認します。もしドレイニング中のタスクがまだ存在する場合は、Lambdaファンクションを再度呼び出すためにSNSにメッセージを送信します。
コンテナインスタンス上で実行中のタスクがなくなるか、あるいはライフサイクルフックのハートビートタイムアウト(サンプルのCloudFormationテンプレートではTTL15分に設定)に達するか、どちらかの状態になるまでLambdaによってステップ2が繰り返されます。その後、制御はオートスケーリングのライフサイクルフックに戻され、そのインスタンスは削除されます。このプロセスを次の図に示します。

試してみましょう!
この記事で説明した一連のリソースをセットアップするためにCloudFormationテンプレートを使用します。このCloudFormationテンプレートを使用するには、あなたのアカウントのS3バケットにLambdaデプロイメントパッケージをアップロードする必要があります。このテンプレートは次のリソースを作成します。
- VPCと関連するネットワーク要素(サブネット、セキュリティグループ、ルートテーブルなど。)
- ECSクラスタ、ECSサービス、そしてサンプルのECSタスク定義
- 削除のライフサイクルフックと2つのEC2インスタンスが設定されたAutoScalingグループ
- Lambdaファンクション
- SNSトピック
- Lambdaを実行するために必要なIAMロール
CloudFormationスタックを作成し、インスタンスの終了イベントをトリガーすることによってどのようにこのスタックが機能するのか見ていきます。
Amazon EC2のコンソールにおいて、AutoScalingグループを選択し、CloudFormationによって作成されたAutoScalingグループの名前(CloudFormationテンプレートのリソースのセクションから)を選択します。
操作、編集を選択し、インスタンスの希望の数を “1” に減らすようにサービスを更新します。これによって、2つのインスタンスのどちらか一方で終了プロセスが開始されます。
AutoScalingグループのインスタンスタブを選択します。1つのインスタンスのライフサイクルの状態が “Terminating:Wait” という値を示すはずです。

この状態になると、ライフサイクルフックが発火してSNSにメッセージが送信されます。そして、SNSメッセージトリガーに反応してLambdaファンクションが実行されます。
Lambdaファンクションによって、ECSコンテナインスタンスの状態がDRAININGに変更されます。その後、ECSサービススケジューラによってこのインスタンス上のタスクは停止され、利用可能なインスタンス上でタスクが起動されます。
ECSのコンソールに移動すれば、コンテナインスタンスの状態がDRAININGになっていることを確認できます。

タスクが全て完了すると、AutoScalingグループのアクティビティ履歴でEC2インスタンスの削除を確認できます。

どのように動作しているか
少しLambdaファンクションの内部的な動作を見てみましょう。ファンクションはまず最初に、受け取ったイベントのLifecycleTransitionの値が autoscaling:EC2_INSTANCE_TERMINATING にマッチするかをチェックします。
マッチする場合は “checkContainerInstanceTaskStatus” という関数が呼び出されます。この関数は、受け取ったEC2インスタンスIDのコンテナインスタンスIDを取得しコンテナインスタンスの状態を ‘DRAINING’ に変更します。
続いてインスタンス上で実行中のタスクがあるかがチェックされます。実行中のタスクが存在する場合、このLabmdaファンクションを再度トリガーするためにSNSトピックにメッセージが発行され、このLambdaファンクションのプロセスは終了となります。
Lambdaファンクションは、コンテナインスタンス上に実行中のタスクがない時には、ライフサイクルフックを終了しこのEC2インスタンスの削除に進みます。
まとめ
コンテナ インスタンス ドレイニングによって、クラスタのスケールダウンや新しいAMIのロールアウトのような運用業務がシンプルになります。例えばこの記事で説明された構成に加えて、CloudFormationやCodePipelineを利用して、新しいインスタンスの起動や終了を一括実行するローリングデプロイメントの環境を構築することもできます。
コンテナ インスタンス ドレイニングについてもっと知りたい場合は、Amazon ECS 開発者ガイドを参照してください。
ご質問やご提案があれば、ぜひ以下にコメントしてください。
(翻訳はSA畑が担当しました。原文はこちら)
Amazon ECSでAuto Scaling
Amazon EC2 Container Service (Amazon ECS)のClusterを自動的にスケールさせる方法はありましたが、本日Auto ScalingとAmazon CloudWatchのAlarmに追加された新機能により、ECSのServiceにScaling Policyを利用することができます。ServiceのAuto Scalingにより、需要が高まった時にスケールアウトさせて高い可用性を実現したり、需要が下がったらServiceとClusterをスケールインさせることでコストを最適化するのを、全て自動でリアルタイムに行うことができます。
この記事では、Clusterを需要に合わせて自動的にリサイズさせつつ、この新しい機能がどうやって利用できるかをお見せします。
Service Auto Scalingの概要
すぐに利用できるECS Serviceのスケーリング機能はずっと一番要望を受けていて、ついに今日この機能をアナウンスでき嬉しいです。自動でスケールするServiceの作成手順はとても簡単で、ECSコンソールやCLI、SDKでもサポートされています。希望するTaskの数とその最小・最大数を選択し、1つ以上のScaling Policyを作成すると、後はService Auto Scalingが面倒を見てくれます。Service SchedulerはAvailability Zoneを意識してくれるので、ECSのTaskを複数のZoneに渡って分散するように心配する必要もありません。
それに加えて、ECS Taskを複数AZ Cluster上で実行することも非常に簡単です。ECS ClusterのAuto Scaling Groupが、複数Zoneに渡る可用性を管理してくれるので、必要とされる回復力や信頼性を持つことができ、ECSがTaskのZone間の分散を管理してくれるので、皆さんはビジネスロジックに集中することができます。
利点:
- 来ているアプリケーションの負荷にキャパシティを対応させる: ECS ServiceとECS ClusterのAuto Scaling Groupを両方にScaling Policyを使います。必要に応じて、Cluster InstanceとService Taskをスケールアウトさせ、需要が落ち着いたら安全にスケールインさせることで、キャパシティの推測ゲームから抜け出せます。これによって、ロングランな環境で低コストな高可用性を実現できます。
- 複数AZのClusterでECSの基盤に高い可用性を持たせる: Zone障害という可能性から守ることができます。Availability Zoneを考慮しているECS SchedulerはCluster上のTaskを管理し、スケールし、分散してくれるので、アーキテクチャは高い可用性を持ちます。
Service Auto Scalingのデモ
この記事では、これらの機能を使い真にスケーラブルで高い可用性を持ったMicroservicesアーキテクチャを作成する手順を辿りたいと思います。このゴールに到達するために、以下の様な手順をお見せします:
- Auto Scaling Groupで2つ以上のZoneにECS Clusterを作成する。
- そのCluster上にECS Serviceを設定し、希望するTaskの数を定義する。
- ECS Serviceの前段にElastic Load Balancingのロードバランサを設定する。これが負荷の入り口になります。
- ECS Service用のスケールインとスケールアウトのCloudWatch Alarmを設定する。
- ECS Cluster用のスケールインとスケールアウトのCloudWatch Alarmを設定する 。(注: 前のステップで作成したものとは別のAlarmになります)
- ECS Service用のScaling Policyを作成し、スケールアウトとスケールインする時のScaling Actionを定義する。
- ECS Clusterが動いているAuto Scaling Group用のScaling Policyを作成する。これらのPolicyはECS Clusterのスケールイン・アウトで利用されます。
- 負荷を徐々に増やしたり減らしたりすることで、スケーラブルなECS ServiceとClusterの高可用性をテストする。
この記事では、Cluster上に1つのECS Serviceを設定する手順をお見せしますが、このパターンは同じCluster上で複数のECS Serviceを実行する時にも適応できます。
注意: この例を実行した結果、発生した如何なるAWSのコストも支払う必要があります。
概念図

ECS ServiceのAuto Scalingを設定する
Auto Scalingを設定する前に、複数AZ (2 Zone)のCluster上で実行されていて、ロードバランサを前段に持つECS Serviceを作っておく必要があります。
- ECS ClusterとServiceをロードバランサも一緒に構築します。このデモではClusterの名前は”anyscale”とします。
CloudWatch Alarmを設定する
- Amazon CloudWatchのコンソール上で、ECS Serviceのスケールインとスケールアウト時に使われるCloudWatch Alarmを設定します。このデモではCPUUtilization (ECS, ClusterName, ServiceNameのカテゴリから選びます)を使いますが、他のMetricsを使うこともできます。(注: 他のやり方として、Service用のScaling Policyを設定する時にはECSのコンソール上でこれらのAlarmを設定することもできます。)

- AlarmにECSServiceScaleOutAlarmという名前をつけ、CPUUtilizationの閾値を75に設定します。
- Actionの所でNotificationを削除します。このデモではECSとAuto Scalingのコンソールを使ってActionを設定します。
- 上記の2ステップを繰り返してスケールインのAlarmを作成し、CPUUtilizationの閾値を25にして、演算子を”<=”に設定します。
- Alarmsの所で、スケールインのAlarmがALARM状態にあるはずです。今のところECS Serviceに負荷がかかっていないので、これは期待した状態です。

- ECS Cluster用のCloudWatch Alarmを設定するために、前のステップと同じことをします。今度は、CPUReservation (ECS, ClusterNameから選びます)をMetricとして利用します。前のステップの様に2つのAlarmを作成し、1つがECS Clusterのスケールアウト用、他方がスケールイン用とします。それらにECSClusterScaleOutAlarmとECSClusterScaleInAlarm という名前(または自由な名前)を設定します。
注: これはCluster固有のMetricですが(Cluster-Service固有のMetricと対照的)、このパターンでも有効的ですし、複数ECS Serviceのシナリオでも有効です。ECS Clusterはどれが起因であってもClusterの負荷に応じて常にスケールします。
ECS ServiceのスケールはECS Clusterのスケールに比べてとても速いので、ECS ClusterのスケーリングのAlarmをECS ServiceのAlarmよりも敏感にしておくことをお勧めします。こうすることで、スケーリングの間Clusterに余分なキャパシティが常にあることを保証でき、一瞬の負荷のピークに対応することができます。もちろん気をつけるべきは、この余分なEC2のキャパシティでコストは増えるので、Clusterのキャパシティを確保するのとコストの間で良いバランスを見つける必要がありますが、それはアプリケーション毎に異なるでしょう。
ECS ServiceにScaling Policyを追加する
Add a scale out and a scale in policy on the ECS service created earlier.
先ほど作成したECS ServiceにスケールアウトとスケールインのPolicyを追加します。
- ECSコンソールにサインインし、Serviceが動いているClusterを選択、Servicesを開いてServiceを選択します
- Serviceのページでは、Updateを選択します。
- Taskの数が2になっていることを確認します。これはそのServiceが実行する時のデフォルトのTask数です。
- Update ServiceのページのOptional configurationsの下にある、Configure Service Auto Scalingを選択します。

- Service Auto Scaling (optional)のページのScalingの下にある、Configure Service Auto Scaling to adjust your service’s desired countを選択します。Minimum number of tasksとDesired number of tasksの両方に2と入力します。Maximum number of tasksには10を入力します。ECS Serviceの作成時にホスト(EC2インスタンス)上の80番ポートをECS Containerの80番ポートにマッピングしているので、Auto Scaling GroupとECS Taskが両方共同じ数値になっていることを確認しておいて下さい。
- Automatic task scaling policiesセクションの下の、Add Scaling Policyを選択します。
- Add Policyのページでは、Policy Nameに値を入力します。Execute policy whenには、前に作成したCloudWatch Alarm (ECSServiceScaleOutAlarm)を入力します。ActionではAdd 100 percentを設定し、Saveを選択します。
- 上の2つのステップの繰り返しで、前に作成したスケールインのCloudWatch Alarm (ECSServiceScaleInAlarm)を使ってスケールインのPolicyを作成します。ActionではRemove 50 percentを設定し、Saveを選択します。
- Service Auto Scaling (optional)ページで、Saveを選択します。
ECS ClusterにScaling Policyを追加する
ECS Cluster (Auto Scaling Group)にスケールアウトとスケールインのPolicyを追加します。
- Auto Scalingのコンソールにサインインしてこのデモ用に作成したAuto Scaling Groupを選択します。
- DetailsからEditを選択します。
- DesiredとMinが2に、Maxが10に設定されていることを確認して、Saveを選択します。
- Scaling PoliciesからAdd Policyを選択します。
- まず、スケールアウトのPolicyを作成します。Nameに値を入力し、Execute policy whenは前に作成したスケールアウトのAlarm (ECSClusterScaleOutAlarm)を選択します。ActionではAdd 100 percent of groupを設定し、Createを選択します。

- 上のステップを繰り返して、スケールインのPolicyをスケールインのAlarm (ECSClusterScaleInAlarm)を使って、ActionにはRemove 50 percent of groupを設定します。
Auto Scaling Group用のスケールインとスケールアウトのPolicyを見ることができるはずです。これらのPolicyを使って、Auto Scaling GroupはECS Serviceが動いているClusterのサイズを大きくしたり小さくしたりできます。
注: ClusterのScaling Policyをこの様に設定することで、Clusterに幾つかの余分なキャパシティを確保することになります。これによってECS Serviceのスケールアウトはより高速になりますが、同時に、需要に依ってはいくつかのEC2インスタンスが利用されない状態になることがあります。
以上でECS ServiceとAuto Scaling Groupに対して、今回はそれぞれ異なるCloudWatch Alarmによって発動するようにAuto Scalingの設定が完了しました。異なるCloudWatch Alarmsの異なる組み合わせを使ってそれぞれのPolicyをもっと凝ったScaling Policyとすることもできます。
これでスケールアウトできるキャパシティを持ったCluster上で動作するServiceができあがったので、Alarmが発動するようにロードバランサにトラフィックを流してみましょう。
ECS Serviceスケーリングの負荷試験
それでは、Apache abツールを使いECS Serviceに負荷試験をして、スケーリングの設定が動作するかを確認してみます(負荷試験インスタンスの作成の章をご覧ください)。CloudWatchのコンソールで、Serviceがスケールアウト・インする様子が見られます。Auto Scaling Groupが2つのAvailability Zoneを使う用に設定されているので、各Zoneに5つのEC2インスタンスを見ることができるはずです。また、ECS Service SchedulerもAvailability Zoneを意識するので、Taskも2つのZoneに渡って分散しているでしょう。
EC2コンソールから、手動でEC2インスタンスを終了させることで高可用性の試験もできます。Auto Scaling GroupとECS Service Schedulerが、追加のEC2インスタンスを起動しTaskも起動してくれるはずです。
追加で考慮すべきこと
- キャパシティの確保: 既に書いた様に、ECS Clusterに余分なキャパシティを確保しておくことで、Clusterが新しいインスタンスを準備するのを待たなくて良いので、ECS Serviceのスケールアウトがとても高速になります。こちらはCloudWatch Alarmが発動する値を変更するか、Scaling Policyの値を変更することで簡単に実現できます。
- インスタンスの終了保護: いくつかのスケールインのケースでは、利用できるECS Clusterのキャパシティが減少することで、強制的にTaskが終了したり他のホストに移動してしまいます。こちらはECS ClusterのスケールインのPolicyを需要に対して敏感に反応しないように調整するか、EC2のホストが終了する前にうまくTaskが終了できるようにすることで軽減できます。そのためには、別の記事で解説されているAuto Scaling Lyfecycle Eventやインスタンスの終了保護をご覧頂くと良いと思います。
今回のデモではAWSコーンソールを使いましたが、もちろん同じことをAWS SDKやCLIを使って実現することも可能です。
まとめ
ミッションクリティカルなMicroservicesアーキテクチャを動かす時には、トータルでかかるコストを下げることは非常に重要ですし、加えて負荷を複数のZoneに分散できることや、ECS ServiceとClusterのキャパシティを負荷の変化に合わせて調整できることが必要になります。この記事でご紹介した手順では、2軸でのスケーリングを活用することでこれを実現することができます。
補足
2016年7月21日に全てのリージョンで利用可能となりました。 https://aws.amazon.com/about-aws/whats-new/2016/07/amazon-ec2-container-service-automatic-service-scaling-region-expansion/
原文: https://aws.amazon.com/blogs/compute/automatic-scaling-with-amazon-ecs/ (翻訳: SA岩永)