Category: Amazon Aurora
Guest Post – Zynga Gets in the Game with Amazon Aurora
![]() Long-time AWS customer Zynga is making great use of Amazon Aurora and other AWS database services. In today’s guest post you can learn about how they use Amazon Aurora to accommodate spikes in their workload. This post was written by Chris Broglie of Zynga.
Long-time AWS customer Zynga is making great use of Amazon Aurora and other AWS database services. In today’s guest post you can learn about how they use Amazon Aurora to accommodate spikes in their workload. This post was written by Chris Broglie of Zynga.
— Jeff;
 Zynga has long operated various database technologies, ranging from simple in-memory caches like Memcached, to persistent NoSQL stores like Redis and Membase, to traditional relational databases like MySQL. We loved the features these technologies offered, but running them at scale required lots of manual time to recover from instance failure and to script and monitor mundane but critical jobs like backup and recovery. As we migrated from our own private cloud to AWS in 2015, one of the main objectives was to reduce the operational burden on our engineers by embracing the many managed services AWS offered.
Zynga has long operated various database technologies, ranging from simple in-memory caches like Memcached, to persistent NoSQL stores like Redis and Membase, to traditional relational databases like MySQL. We loved the features these technologies offered, but running them at scale required lots of manual time to recover from instance failure and to script and monitor mundane but critical jobs like backup and recovery. As we migrated from our own private cloud to AWS in 2015, one of the main objectives was to reduce the operational burden on our engineers by embracing the many managed services AWS offered.
We’re now using Amazon DynamoDB and Amazon ElastiCache (Memcached and Redis) widely in place of their self-managed equivalents. Now, engineers are able to focus on application code instead of managing database tiers, and we’ve improved our recovery times from instance failure (spoiler alert: machines are better at this than humans). But the one component missing here was MySQL. We loved the automation Amazon RDS for MySQL offers, but it relies on general-purpose Amazon Elastic Block Store (EBS) volumes for storage. Being able to dynamically allocate durable storage is great, but you trade off having to send traffic over the network, and traditional databases suffer from this additional latency. Our testing showed that the performance of RDS for MySQL just couldn’t compare to what we could obtain with i2 instances and their local (though ephemeral) SSDs. Provisioned IOPS narrow the gap, but they cost more. For these reasons, we used self-managed i2 instances wherever we had really strict performance requirements.
However, for one new service we were developing during our migration, we decided to take a measured bet on Amazon Aurora. Aurora is a MySQL-compatible relational database offered through Amazon RDS. Aurora was only in preview when we started writing the service, but it was expected to become generally available before production, and we knew we could always fall back to running MySQL on our own i2 instances. We were naturally apprehensive of any new technology, but we had to see for ourselves if Aurora could deliver on its claims of exceeding the performance of MySQL on local SSDs, while still using network storage and providing all the automation of a managed service like RDS. And after 8 months of production, Aurora has been nothing short of impressive. While our workload is fairly modest – the busiest instance is an r3.2xl handling ~9k selects/second during peak for a 150 GB data set – we love that so far Aurora has delivered the necessary performance without any of the operational overhead of running MySQL.
An example of what this kind of automation has enabled for us was an ops incident where a change in traffic patterns resulted in a huge load spike on one of our Aurora instances. Thankfully, the instance was able to keep serving traffic despite 100% CPU usage, but we needed even more throughput. With Aurora we were able to scale up the reader to an instance that was 4x larger, failover to it, and then watch it handle 4x the traffic, all with just a few clicks in the RDS console. And days later after we released a patch to prevent the incident from recurring, we were able to scale back down to smaller instances using the same procedure. Before Aurora we would have had to either get a DBA online to manually provision, replicate, and failover to a larger instance, or try to ship a code hotfix to reduce the load on the database. Manual changes are always slower and riskier, so Aurora’s automation is a great addition to our ops toolbox, and in this case it led to a resolution measured in minutes rather than hours.
Most of the automation we’re enjoying has long been standard for RDS, but using Aurora has delivered the automation of RDS along with the performance of self-managed i2 instances. Aurora is now our first choice for new services using relational databases.
— Chris Broglie, Architect (Zynga)
New – Cross-Region Read Replicas for Amazon Aurora
You already have the power to scale the read capacity of your Amazon Aurora instances by adding additional read replicas to an existing cluster. Today we are giving you the power to create a read replica in another region. This new feature will allow you to support cross-region disaster recovery and to scale out reads. You can also use it to migrate from one region to another or to create a new database environment in a different region.
Creating a read replica in another region also creates an Aurora cluster in the region. This cluster can contain up to 15 more read replicas, with very low replication lag (typically less than 20 ms) within the region (between regions, latency will vary based on the distance between the source and target). You can use this model to duplicate your cluster and read replica setup across regions for disaster recovery. In the event of a regional disruption, you can promote the cross-region replica to be the master. This will allow you to minimize downtime for your cross-region application. This feature applies to unencrypted Aurora clusters.
Before you get actually create the read replica, you need to take care of a pair of prerequisites. You need to make sure that a VPC and the Database Subnet Groups exist in the target region, and you need to enable binary logging on the existing cluster.
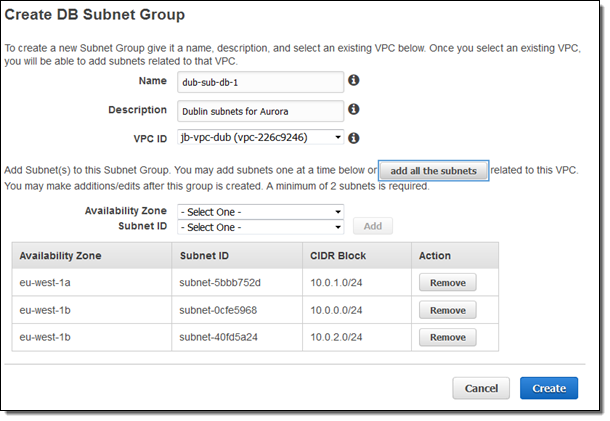
Setting up the VPC
Because Aurora always runs within a VPC, ensure that the VPC and the desired Database Subnet Groups exist in the target region. Here are mine:
Enabling Binary Logging
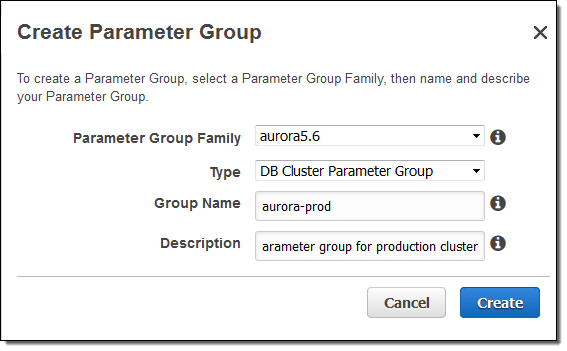
Before you can create a cross region read replica, you need to enable binary logging for your existing cluster. Create a new DB Cluster Parameter Group (if you are not already using a non-default one):
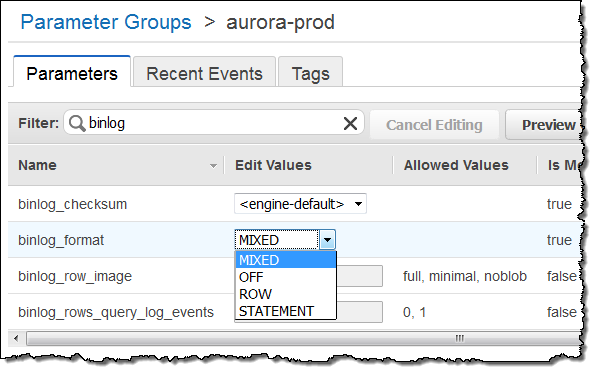
Enable binary logging (choose MIXED) and then click on Save Changes:
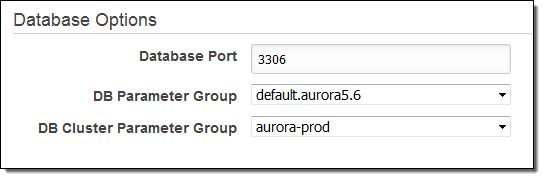
Next, Modify the DB Instance, select the new DB Cluster Parameter Group, check Apply Immediately, and click on Continue. Confirm your modifications, and then click on Modify DB Instance to proceed:
Select the instance and reboot it, then wait until it is ready.
Create Read Replica
With the prerequisites out of the way it is time to create the read replica! From within the AWS Management Console, select the source cluster and choose Create Cross Region Read Replica from the Instance Actions menu:
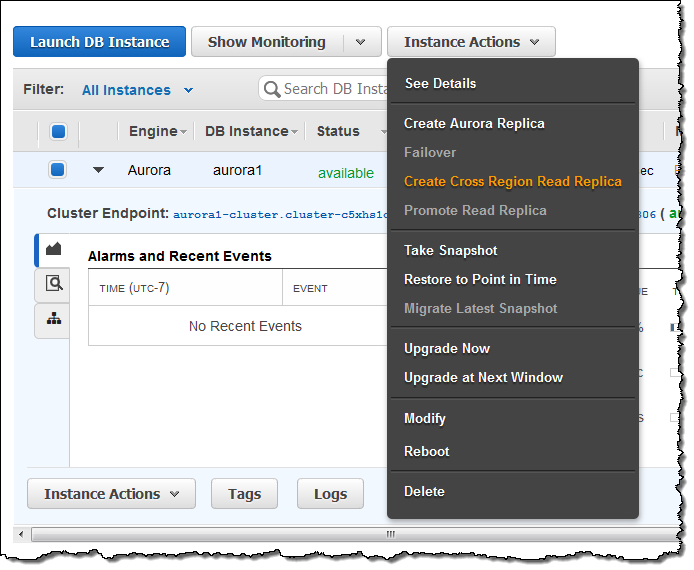
Name the new cluster and the new instance, and then pick the target region. Choose the DB Subnet Group and set the other options as desired, then click Create:
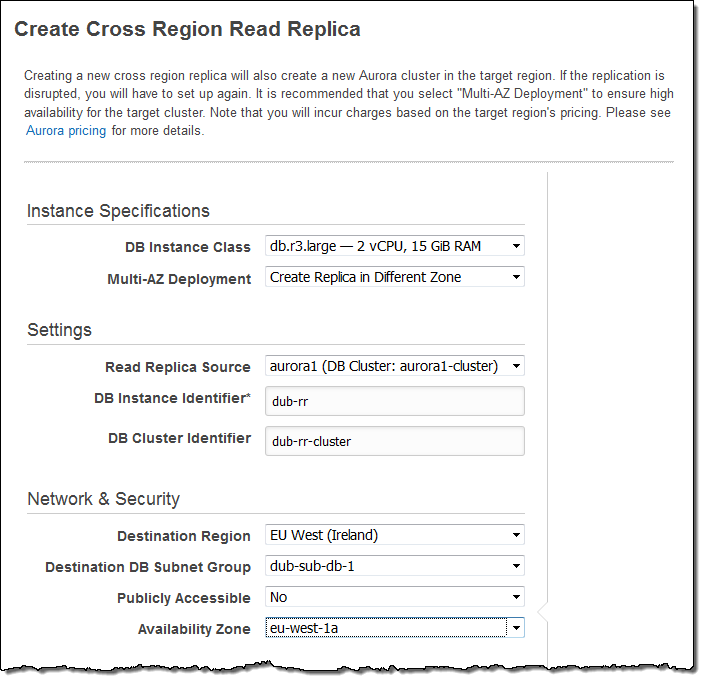
Aurora will create the cluster and the instance. The state of both items will remain at creating until the items have been created and the data has been replicated (this could take some time, depending on amount of data stored in the existing cluster.
This feature is available now and you can start using it today!
— Jeff;
New – Cross-Account Snapshot Sharing for Amazon Aurora
Amazon Aurora is a high-performance, MySQL-compatible database engine. Aurora combines the speed and availability of high-end commercial databases with the simplicity and cost-effective of open source databases (see my post, Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS, to learn more). Aurora shares some important attributes with the other database engines that are available for Amazon RDS including easy administration, push-button scalability, speed, security, and cost-effectiveness.
You can create a snapshot backup of an Aurora cluster with just a couple of clicks. After you have created a snapshot, you can use it to restore your database, once again with a couple of clicks.
Share Snapshots
Today we are giving you the ability to share your Aurora snapshots. You can share them with other AWS accounts and you can also make them public. These snapshots can be used to restore the database to an Aurora instance running in a separate AWS account in the same Region as the snapshot.
There are several primary use cases for snapshot sharing:
Separation of Environments – Many AWS customers use separate AWS accounts for their development, test, staging, and production environments. You can share snapshots between these accounts as needed. For example, you can generate the initial database in your staging environment, snapshot it, share the snapshot with your production account, and then use it to create your production database. Or, should you encounter an issue with your production code or queries, you can create a snapshot of your production database and then share it with your test account for debugging and remediation.
Partnering – You can share database snapshots with selected partners on an as-needed basis.
Data Dissemination -If you are running a research project, you can generate snapshots and then share them publicly. Interested parties can then create their own Aurora databases using the snapshots, using your work and your data as a starting point.
To share a snapshot, simply select it in the RDS Console and click on Share Snapshot. Then enter the target AWS account (or click on Public to share the snapshot publicly) and click on Add:
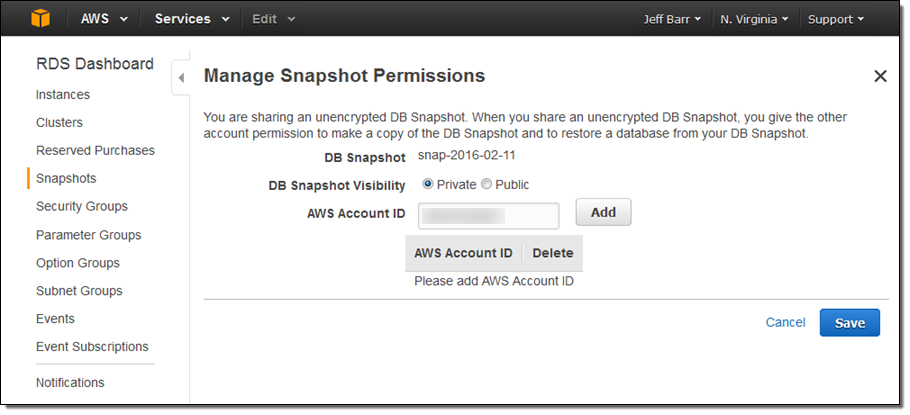
You can share manually generated, unencrypted snapshots with other AWS accounts or publicly. You cannot share automatic snapshots or encrypted snapshots.
The shared snapshot becomes visible in the other account right away:
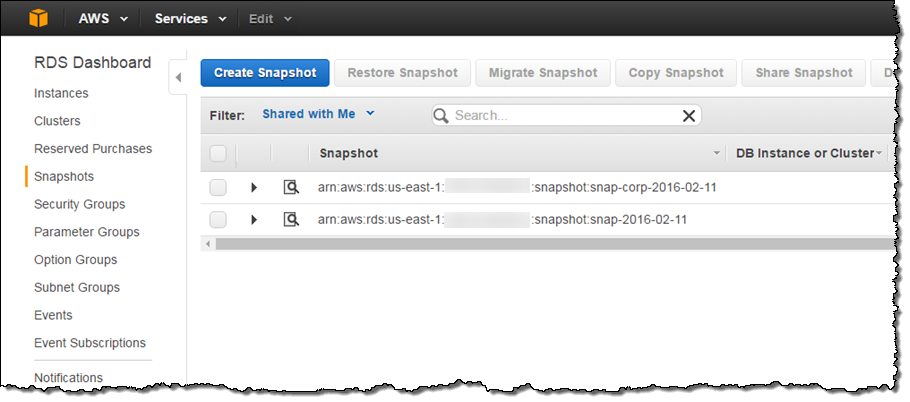
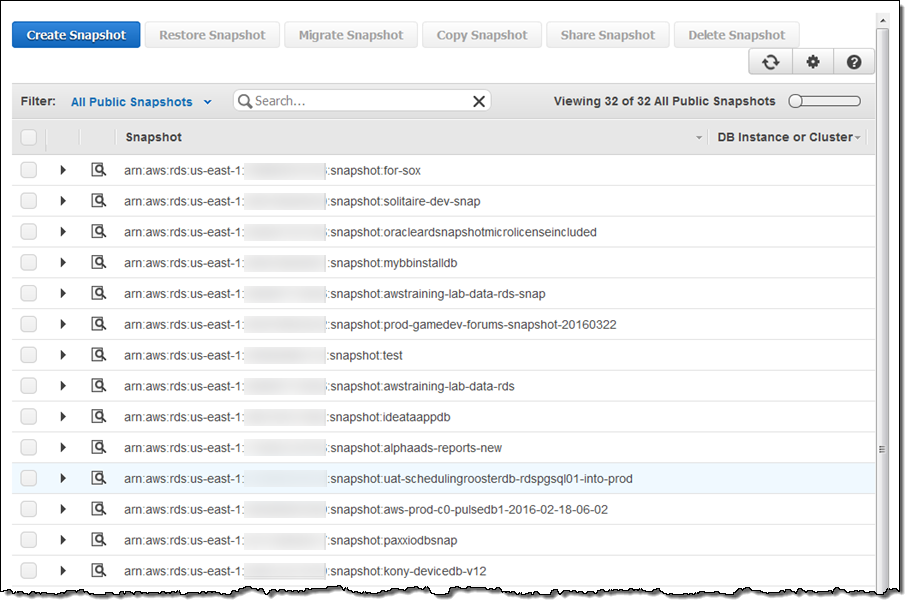
Public snapshots are also visible (select All Public Snapshots as the Filter):
Available Now
This feature is available now and you can start using it today.
— Jeff;
Additional Failover Control for Amazon Aurora
Amazon Aurora is a fully-managed, MySQL-compatible, relational database engine that combines the speed and availability of high-end commercial databases with the simplicity and cost-effectiveness of open source database (read my post, Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS, to learn more).
Aurora allows you create up to 15 read replicas to increase read throughput and for use as failover targets. The replicas share storage with the primary instance and provide lightweight, fine-grained replication that is almost synchronous, with a replication delay on the order of 10 to 20 milliseconds.
Additional Failover Control
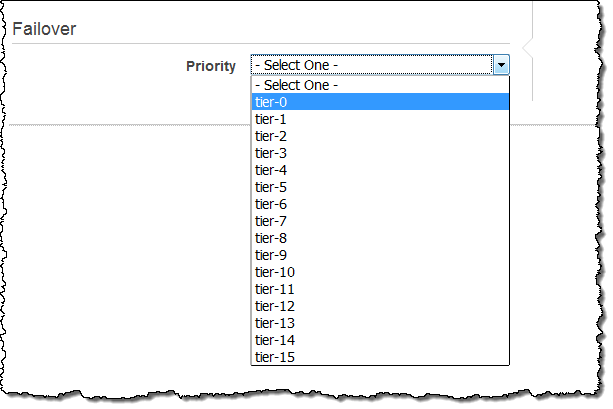
Today we are making Aurora even more flexible by giving you control over the failover priority of each read replica. Each read replica is now associated with a priority tier (0-15). In the event of a failover, Amazon RDS will promote the read replica that has the highest priority (the lowest numbered tier). If two or more replicas have the same priority, RDS will promote the one that is the same size as the previous primary instance.
You can set the priority when you create the Aurora DB instance:
This feature is available now and you can start using it today. To learn more, read about Fault Tolerance for an Aurora DB Cluster.
— Jeff;
AWS Database Migration Service
 Do you currently store relational data in an on-premises Oracle, SQL Server, MySQL, MariaDB, or PostgreSQL database? Would you like to move it to the AWS cloud with virtually no downtime so that you can take advantage of the scale, operational efficiency, and the multitude of data storage options that are available to you?
Do you currently store relational data in an on-premises Oracle, SQL Server, MySQL, MariaDB, or PostgreSQL database? Would you like to move it to the AWS cloud with virtually no downtime so that you can take advantage of the scale, operational efficiency, and the multitude of data storage options that are available to you?
If so, the new AWS Database Migration Service (DMS) is for you! First announced last fall at AWS re:Invent, our customers have already used it to migrate over 1,000 on-premises databases to AWS. You can move live, terabyte-scale databases to the cloud, with options to stick with your existing database platform or to upgrade to a new one that better matches your requirements. If you are migrating to a new database platform as part of your move to the cloud, the AWS Schema Conversion Tool will convert your schemas and stored procedures for use on the new platform.
The AWS Database Migration Service works by setting up and then managing a replication instance on AWS. This instance unloads data from the source database and loads it into the destination database, and can be used for a one-time migration followed by on-going replication to support a migration that entails minimal downtime. Along the way DMS handles many of the complex details associated with migration, including data type transformation and conversion from one database platform to another (Oracle to Aurora, for example). The service also monitors the replication and the health of the instance, notifies you if something goes wrong, and automatically provisions a replacement instance if necessary.
The service supports many different migration scenarios and networking options One of the endpoints must always be in AWS; the other can be on-premises, running on an EC2 instance, or running on an RDS database instance. The source and destination can reside within the same Virtual Private Cloud (VPC) or in two separate VPCs (if you are migrating from one cloud database to another). You can connect to an on-premises database via the public Internet or via AWS Direct Connect.
Migrating a Database
You can set up your first migration with a couple of clicks! You simply create the target database, migrate the database schema, set up the data replication process, and initiate the migration. After the target database has caught up with the source, you simply switch to using it in your production environment.
I start by opening up the AWS Database Migration Service Console (in the Database section of the AWS Management Console as DMS) and clicking on Create migration.
The Console provides me with an overview of the migration process:
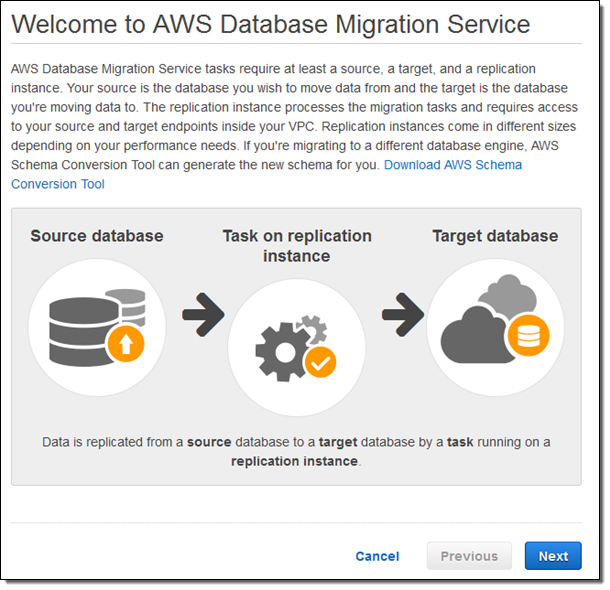
I click on Next and provide the parameters that are needed to create my replication instance:
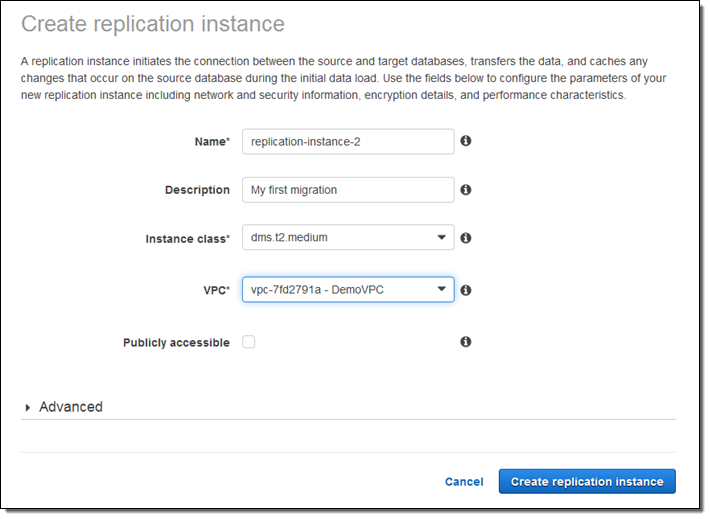
For this blog post, I selected one of my existing VPCs and unchecked Publicly accessible. My colleagues had already set me up with an EC2 instance to represent my “on-premises” database.
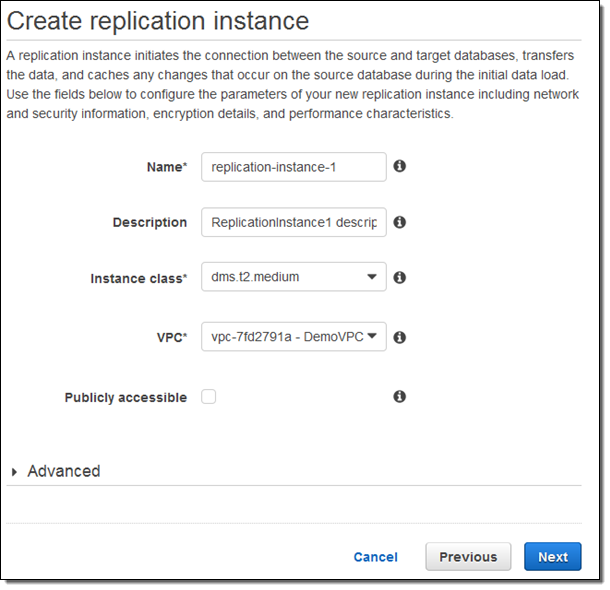
After the replication instance has been created, I specify my source and target database endpoints and then click on Run test to make sure that the endpoints are accessible (truth be told, I spent some time adjusting my security groups in order to make the tests pass):
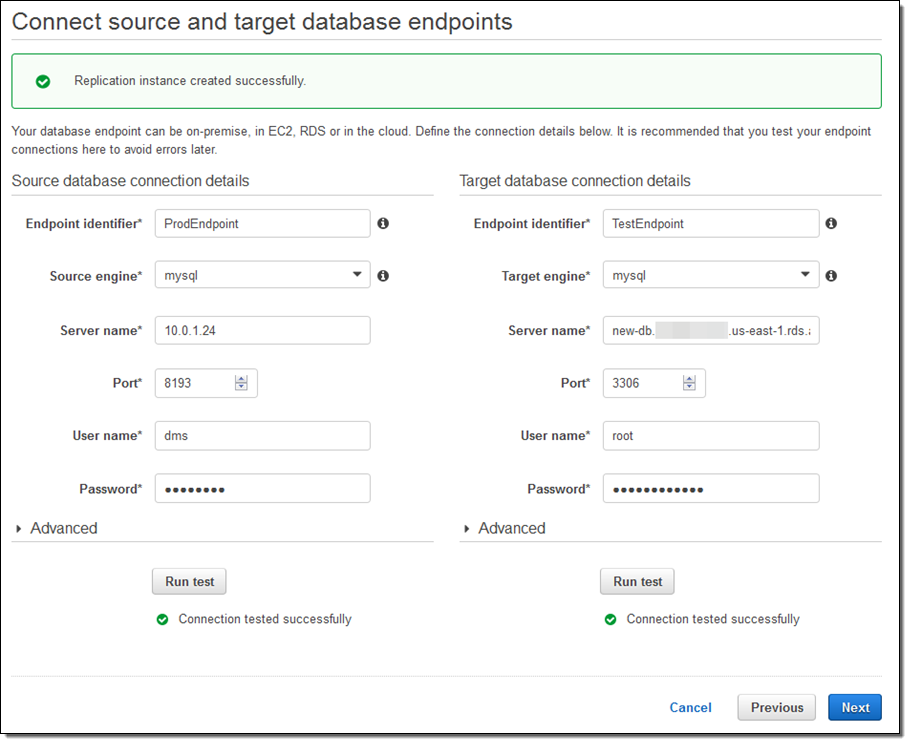
Now I create the actual migration task. I can (per the Migration type) migrate existing data, migrate and then replicate, or replicate going forward:
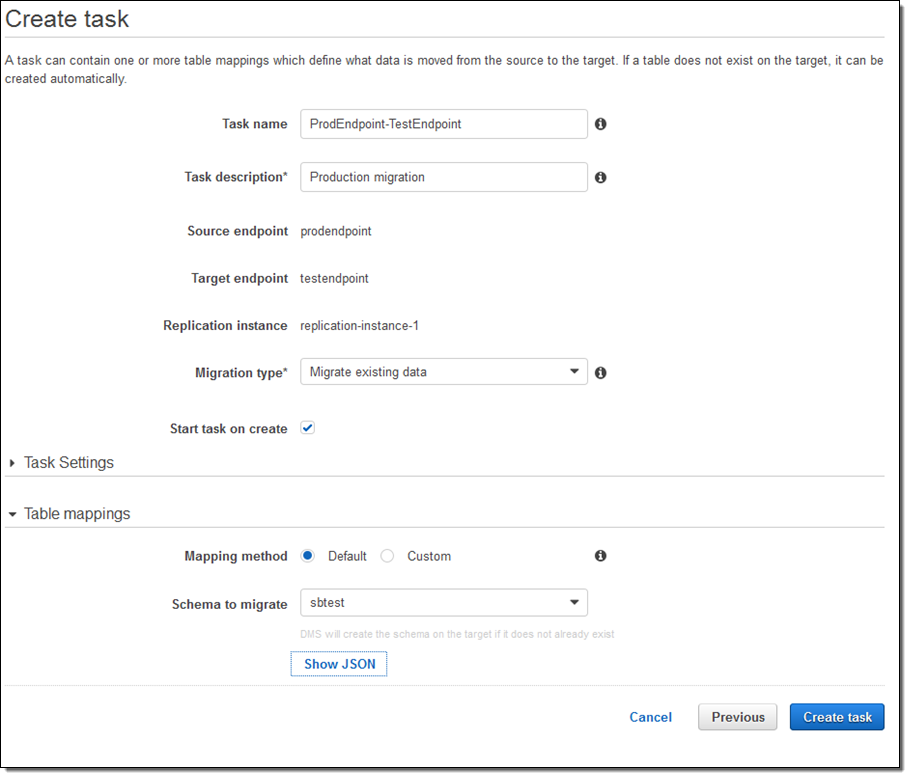
I could have clicked on Task Settings to set some other options (LOBs are Large Objects):
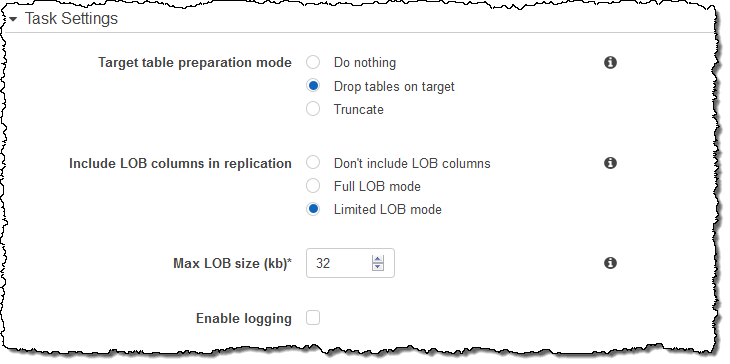
The migration task is ready, and will begin as soon as I select it and click on Start/Resume:
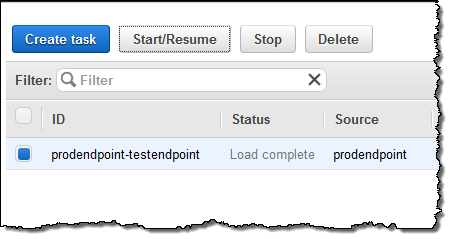
I can watch for progress, and then inspect the Table statistics to see what happened (these were test tables and the results are not very exciting):
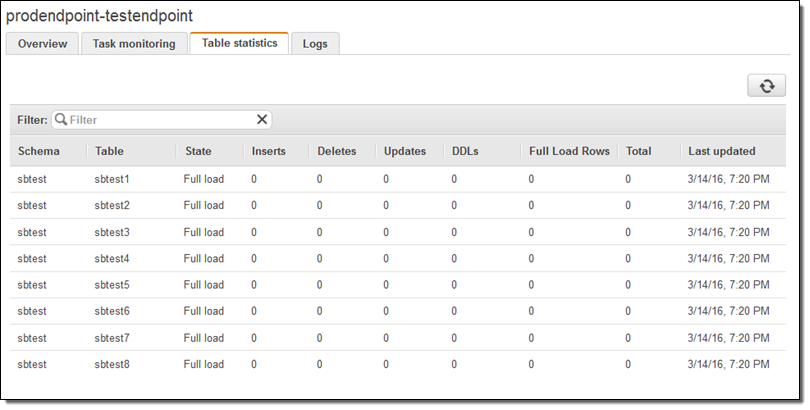
At this point I would do some sanity checks and then point my application to the new endpoint. I could also have chosen to perform an ongoing replication.
The AWS Database Migration Service offers many options and I have barely scratched the surface. You can, for example, choose to migrate only certain tables. You can also create several different types of replication tasks and activate them at different times. I highly recommend you read the DMS documentation as it does a great job of guiding you through your first migration.
If you need to migrate a collection of databases, you can automate your work using the AWS Command Line Interface (CLI) or the Database Migration Service API.
Price and Availability
The AWS Database Migration Service is available in the US East (Northern Virginia), US West (Oregon), US West (Northern California), EU (Ireland), EU (Frankfurt), Asia Pacific (Tokyo), Asia Pacific (Singapore), and Asia Pacific (Sydney) Regions and you can start using it today (we plan to add support for other Regions in the coming months).
Pricing is based on the compute resources used during the migration process, with a charge for longer-term storage of logs. See the Database Migration Service Pricing page for more information.
— Jeff;
Migrating to Amazon Aurora: The View from the Other Side
Today I have a new guest post, this one written by AWS customer Safe Software. They were an early adopter of Amazon Aurora and have a great story to tell.
— Jeff;
 Being in the business of moving data, Safe Software is always working to support leading edge database technology. This focus naturally led us to us being aware of Amazon Aurora.
Being in the business of moving data, Safe Software is always working to support leading edge database technology. This focus naturally led us to us being aware of Amazon Aurora.
In addition to leveraging the power of AWS and Aurora for our clients, we also evaluate new technologies from the perspective of improving our internal processes. When Aurora was released in beta, we immediately thought of migrating to it for our own systems. That decision has proven to be worthwhile. The move to Aurora has increased our productivity while providing an annual 40% cost reduction in systems costs.
Now that the migration is behind us, I’d like to share some tips and insights to those considering taking the leap. While I’d like to include the migration details, there is not much to say as it only took the click of a button. Instead I will share what we tried first, how we prepared, and how we optimized our systems further once they were operating in Aurora.
Why We Needed The Cloud
To ensure high quality of our spatial data transformation technology, FME, we run a grueling automated test suite. The platform supports 365+ data formats and limitless transformations, making the automated daily testing demanding: 15,000 tests x 4 operating systems x 3 products, running 24/7.
![]()
The problem: We couldn’t keep provisioning hardware to keep the system happy. Never mind keeping up with our expectation of a 1-second response time.
Our internal production database runs on a high traffic system with 140+ tables containing ~100 million rows of data. It is the primary operational repository for our build and test systems, as well as our internal intranet and reporting framework, supporting our server farms upwards of 150 machines. Over 100 users rely on this system.
What We Tried Before Aurora
We initially tried moving everything to MySQL on RDS, but found that we needed to run a read replica on a sizable instance to manage load. Even still, we were crowding ourselves against the productivity ceiling for the number of connections we could handle for most queries. We struggled to meet the needed response times. This solution had also immediately doubled our costs.
We’d spent so much time getting good at MySQL that the idea of having to relearn all of that in a new system was painful. Having something you treat like an appliance is much better.
Fail-Safe Preparations and Migration
We heard Aurora mirrors the MySQL experience, so we figured it was worth trying. To ensure we had nothing to lose we decided to keep the production system running in its existing form, while we tested Aurora.
One of the benefits of moving to a higher performance system is you have a good opportunity to re-assess a system that dates back years. During this migration we did some housekeeping. We looked at indexes, table structures, and many other relational aspects of the database. We were able to combining multiple schemas into just two for simpler logic.
The actual move into Aurora was trivial. Within the Amazon control panel, we chose to migrate – clicking a button. It happened in the background, and we ended up with a copy in Aurora of what we had running in MySQL! It was that simple!
Managing the cutover is a fairly big thing in terms of scheduling, to make sure we’re not impacting operations and meanwhile capturing a current snapshot of the data. We were wary that things could get out of sync; that by the time the migration was done the read dates may be out of date. We knew it would take a few hours to migrate the production system that was still operating, and during that time, data could change.
We chose to do the migration overnight on the live system while it was still running. We followed up with our own FME product to capture changes that had taken place in volatile tables during the migration (about 2-3% of our data), and port them over.
Our build and release team was able to manage the migration ourselves, and only involved the IT department to configure identity and access management and then change the DNS on our network once we’d verified that everything was a go.
We had checked a few examples for sanity first, but it was kind of a leap in the dark because we were early adopters. But we knew that we could just roll back to the old system if needed.
Optimizing The Experience Post-Migration
We thoroughly tested all of our processes afterward. There was some head-scratching after the first couple of days of monitoring; we experienced patches of heavy CPU load and slow-downs in Aurora during operations that had previously been unremarkable in MySQL.
We tracked these down to a set of inefficient queries using deeply nested SELECTs which were not readily modifiable. We resolved these issues with some simple schema changes, and pre-canning some of the more complex relationships using our own product, FME. Bottom Line: Schema design is still important.
No other issues were experienced during or since, and tuning these queries and indexes was ultimately beneficial. In operation we now have enterprise scale with the familiar interfaces we are used to.
For almost all operations, Aurora has proven faster, and it gives us more scalability. We’re running a relatively modest setup now, knowing that we can expand, and it’s saving us about $8,000 per year (60% cheaper). In fact, we could double our performance using Aurora and it would still be less than we paid last year. We save another $2,000 by reserving the instance for annual operations.
Operation management is pretty critical stuff, so it’s a relief not to worry about backups or database failures. The managed database saves us a lot of headaches. To achieve this performance ourselves would have a required huge investment in both hardware and personnel.
With Aurora, we can create our FME product builds better, faster, and the test results come through quickly, which ultimately means we can provide a higher quality product.
— Iain McCarthy, Product Release Manager at Safe Software Inc.
New – Enhanced Monitoring for Amazon RDS (MySQL 5.6, MariaDB, and Aurora)
Amazon Relational Database Service (RDS) makes it easy for you to set up, run, scale, and maintain a relational database. As is often the case with the high-level AWS model, we take care of all of the details in order to give you the time to focus on your application and your business.
Enhanced Monitoring
Advanced RDS users have asked us for more insight into the inner workings of the service and we are happy to oblige with a new Enhanced Monitoring feature!
After you enable this feature for a database instance, you get access to over 50 new CPU, memory, file system, and disk I/O metrics. You can enable these features on a per-instance basis, and you can choose the granularity (all the way down to 1 second). Here is the list of available metrics:
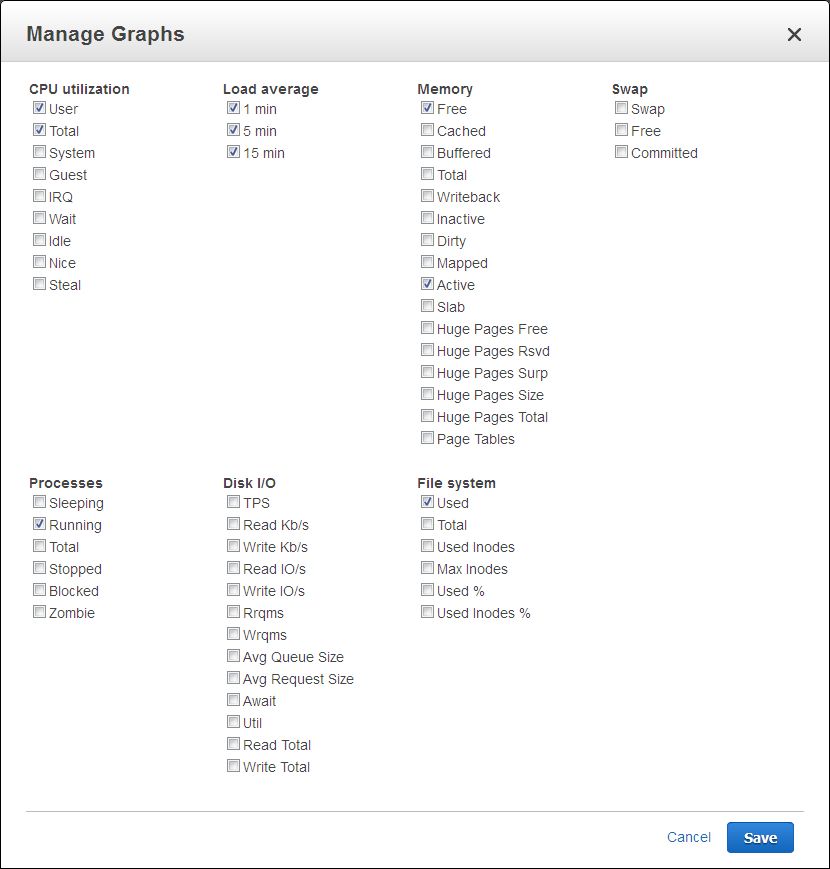
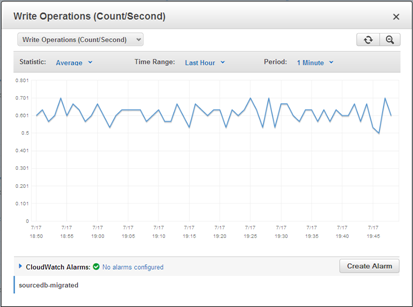
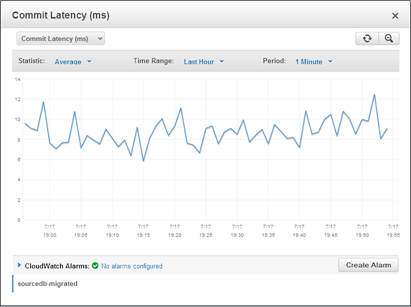
And here are some of the metrics for one of my database instances:
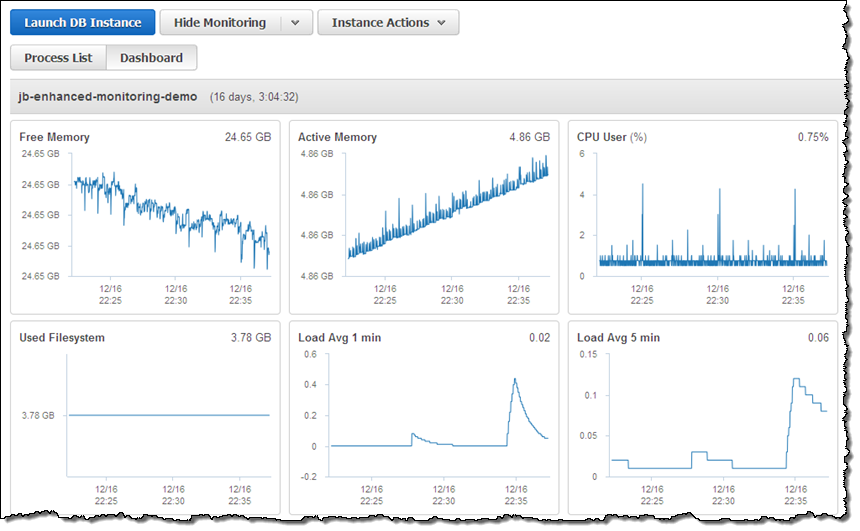
You can enable this feature for an existing database instance by selecting the instance in the RDS Console and then choosing Modify from the Instance Options menu:
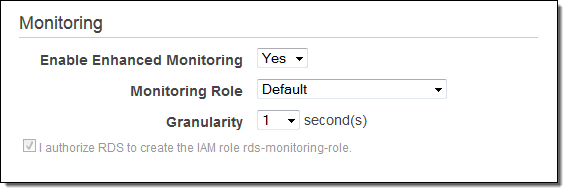
Turn the feature on, pick an IAM role, select the desired granularity, check Apply Immediately, and then click on Continue.
The Enhanced Metrics are ingested into CloudWatch Logs and can be published to Amazon CloudWatch. To do this you will need to set up a metrics extraction filter; read about Monitoring Logs to learn more. Once the metrics are stored in CloudWatch Logs, they can also be processed by third-party analysis and monitoring tools.
Available Now
The new Enhanced Metrics feature is available today in the US East (Northern Virginia), US West (Northern California), US West (Oregon), EU (Ireland), EU (Frankfurt), Asia Pacific (Singapore), Asia Pacific (Sydney), and Asia Pacific (Tokyo) regions. It works for MySQL 5.6, MariaDB, and Amazon Aurora, on all instance types except t1.micro and m1.small.
You will pay the usual ingestion and data transfer charges for CloudWatch Logs (see the CloudWatch Logs Pricing page for more info).
— Jeff;
InfoWorld Review – Amazon Aurora Rocks MySQL
 Back when I was young, InfoWorld was a tabloid-sized journal that chronicled the growth of the PC industry. Every week I would await the newest issue and read it cover to cover, eager to learn all about the latest and greatest hardware and software. I always enjoyed and appreciated the reviews — they were unfailingly deep, objective, and helpful.
Back when I was young, InfoWorld was a tabloid-sized journal that chronicled the growth of the PC industry. Every week I would await the newest issue and read it cover to cover, eager to learn all about the latest and greatest hardware and software. I always enjoyed and appreciated the reviews — they were unfailingly deep, objective, and helpful.
With this as background, I am really happy to be able to let you know that the team at InfoWorld recently put Amazon Aurora through its paces, wrote a detailed review, and named it an Editor’s Choice. They succinctly and accurately summarized the architecture, shared customer feedback from AWS re:Invent, and ran an intensive benchmark, concluding that:
This level of performance is far beyond any I’ve seen from other open source SQL databases, and it was achieved at far lower cost than you would pay for an Oracle database of similar power.
We’re very proud of Amazon Aurora and I think you’ll understand why after you read this review.
— Jeff;
New – Encryption at Rest for Amazon Aurora
We launched Amazon Aurora a little over a year ago (see my post, Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS, to learn more). Customer adoption of Amazon Aurora has been strong and it is now the fastest-growing AWS service! We recently made Amazon Aurora available in the Asia Pacific (Tokyo) region for our customers in Japan and the surrounding area (it was already available in the US East (Northern Virginia), US West (Oregon), and EU (Ireland) regions).
Encryption at Rest
Encryption is an important part of any data protection strategy. Today we are making it easier for you to encrypt the data that you store in Amazon Aurora (this is often known as “encryption at rest”). As is the case with the other encryption options for RDS, you simply choose a key (either AWS-managed or customer-managed) from AWS Key Management Service (KMS) when you create the database instance:
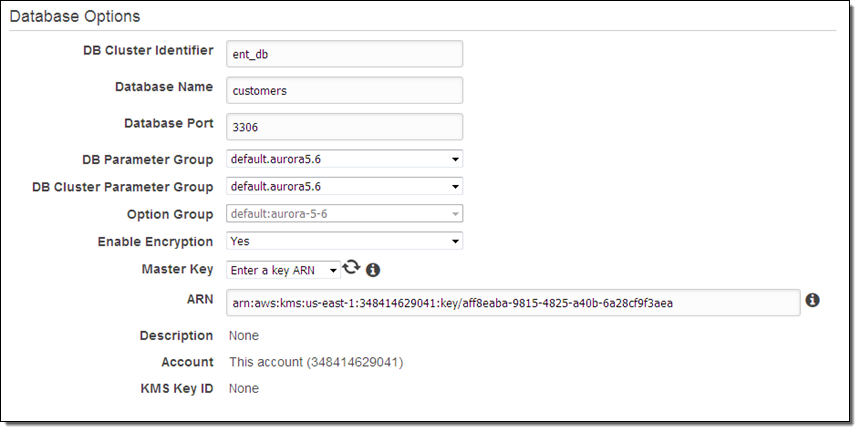
Encryption (AES-256) applies to the data in the database, logs, backups, snapshots, and read replicas. You must specify encryption when you create the database instance; you cannot enable or disable it for a running instance. Read about Encrypting Amazon RDS Resources to learn more.
If you choose to create your own key, you can request annual rotation:
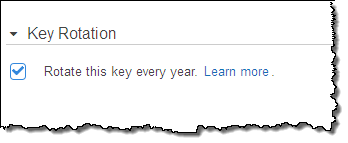
You can also enable AWS CloudTrail logging for your AWS account. This will allow you to track all of the calls made to KMS (including all Encrypt and Decrypt operations) for auditing purposes. To learn how do to this, read Logging AWS KMS API Calls Using AWS CloudTrail.
— Jeff;
PS – Before you ask, Amazon Aurora uses AES-256 to encrypt data in transit.
Now Available – Amazon Aurora
We announced Amazon Aurora last year at AWS re:Invent (see Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon for more info). With storage replicated both within and across three Availability Zones, along with an update model driven by quorum writes, Amazon Aurora is designed to deliver high performance and 99.99% availability while easily and efficiently scaling to up to 64 TB of storage.
In the nine months since that announcement, a host of AWS customers have been putting Amazon Aurora through its paces. As they tested a wide variety of table configurations, access patterns, and queries on Amazon Aurora, they provided us with the feedback that we needed to have in order to fine-tune the service. Along the way, they verified that each Amazon Aurora instance is able to deliver on our performance target of up to 100,000 writes and 500,000 reads per second, along with a price to performance ratio that is 5 times better than previously available.
Now Available
Today I am happy to announce that Amazon Aurora is now available for use by all AWS customers, in three AWS regions. During the testing period we added some important features that will simplify your migration to Amazon Aurora. Since my original blog post provided a good introduction to many of the features and benefits of the core product, I’ll focus on the new features today.
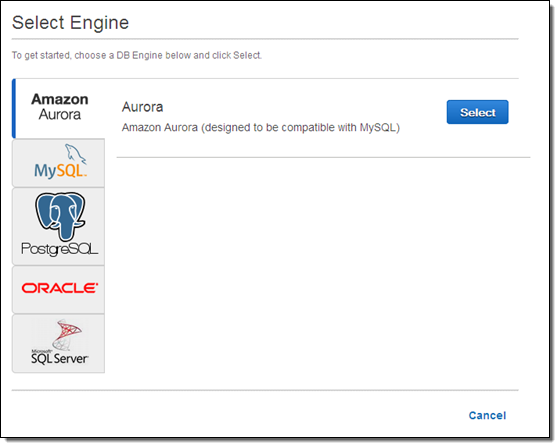
Zero-Downtime Migration
If you are already using Amazon RDS for MySQL and want to migrate to Amazon Aurora, you can do a zero-downtime migration by taking advantage of Amazon Aurora’s new features. I will summarize the process here, but I do advise you to read the reference material below and to do a practice run first! Immediately after you migrate, you will begin to benefit from Amazon Aurora’s high throughput, security, and low cost. You will be in a position to spend less time thinking about the ins and outs of database scaling and administration, and more time to work on your application code.
If the database is active, start by enabling binary logging in the instance’s DB parameter group (see MySQL Database Log Files to learn how to do this). In certain cases, you may want to consider creating an RDS Read Replica and using it as the data source for the migration and replication (check out Replication with Amazon Aurora to learn more).
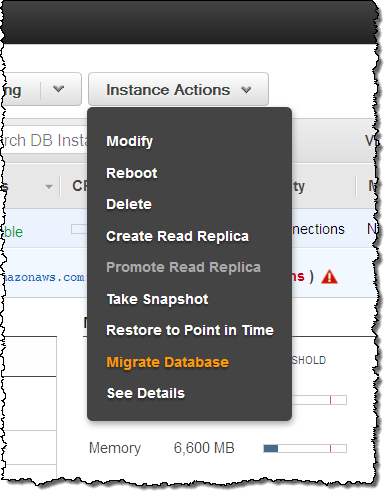
Open up the RDS Console, select your existing database instance, and choose Migrate Database from the Instance Actions menu:
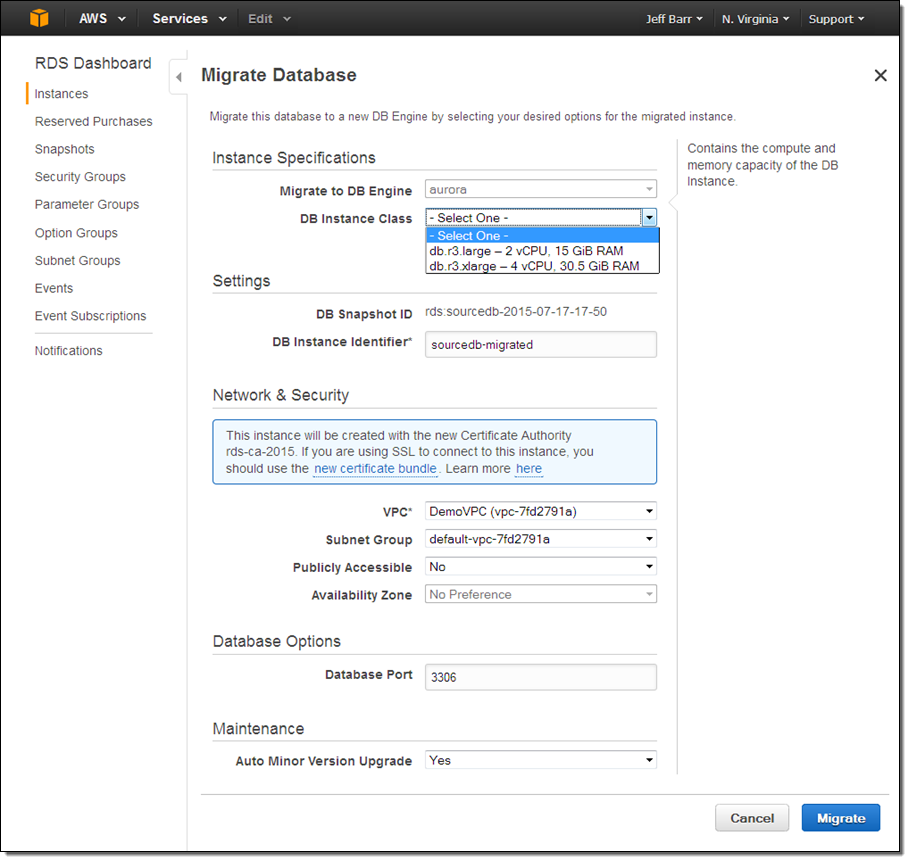
Fill in the form (in most cases you need do nothing more than choose the DB Instance Class) and click on the Migrate button:
Aurora will create a new DB instance and proceed with the migration:
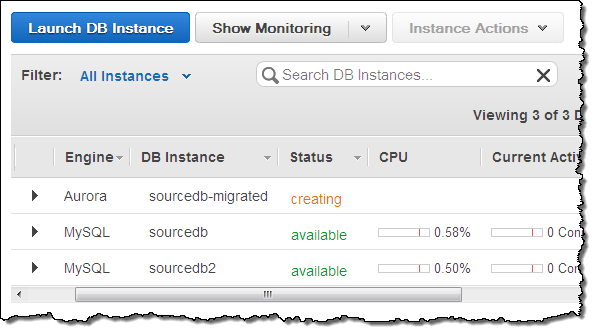
A little while later (a coffee break might be appropriate, depending on the size of your database), the Amazon Aurora instance will be available:
Now (assuming that the source database was actively changing) while you were creating the Amazon Aurora instance, replicate the changes to the new instance using the mysql.rds_set_external_master command, and then update your application to use the new Aurora endpoint!
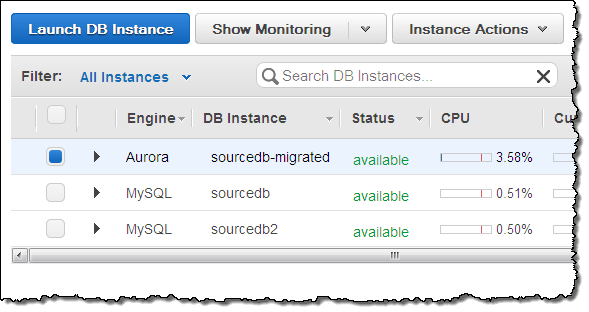
Metrics Galore
Each Amazon Aurora instance reports a plethora of metrics to Amazon CloudWatch. You can view these from the Console and you can, as usual, set alarms and take actions as needed:
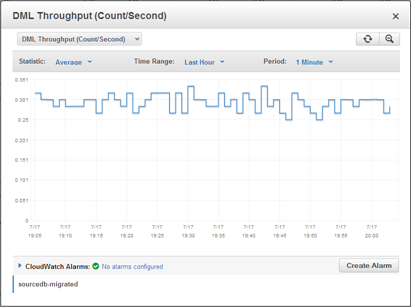
Easy and Fast Replication
Each Amazon Aurora instance can have up to 15 replicas, each of which adds additional read capacity. You can create a replica with a couple of clicks:
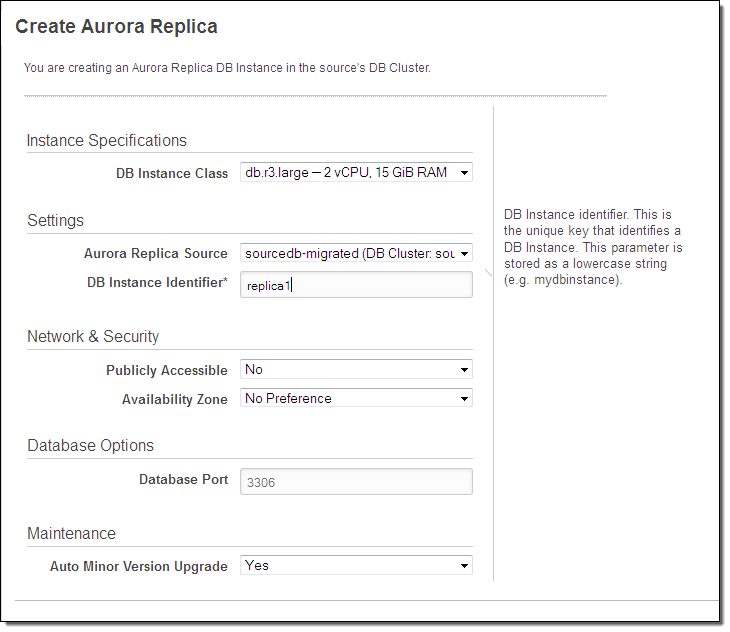
Due to Amazon Aurora’s unique storage architecture, replication lag is extremely low, typically between 10 ms and 20 ms.
5x Performance
When we first announced Amazon Aurora we expected to deliver a service that offered at least 4 times the price-performance of existing solutions. Now that we are ready to ship, I am happy to report that we’ve exceeded this goal, and that Amazon Aurora can deliver 5x the price-performance of a traditional relational database when run on the same class of hardware.
In general, this does not mean that individual queries will run 5x as fast as before (although Amazon Aurora’s fast, SSD-based storage certainly speeds things up). Instead, it means that Amazon Aurora is able to handle far more concurrent queries (both read and write) than other products. Amazon Aurora’s unique, highly parallelized access to storage reduces contention for stored data and allows it to process queries in a highly efficient fashion.
From our Partners
Members of the AWS Partner Network (APN) have been working to test their offerings and to gain operational and architectural experience with Amazon Aurora. Here’s what I know about already:
- Business Intelligence – Tableau, Zoomdata, and Looker.
- Data Integration – Talend, Attunity, and Informatica.
- Query and Monitoring – Webyog, Toad, and Navicat.
- SI and Consulting – 8K Miles, 2nd Watch, and Nordcloud.
- Content Management – Alfresco.
Ready to Roll
Our customers and partners have put Amazon Aurora to the test and it is now ready for your production workloads. We are launching in the US East (Northern Virginia), US West (Oregon), and EU (Ireland) regions, and will expand to others over time.
Pricing works like this:
- Database Instances – You pay by the hour for the primary instance and any replicas. Instances are available in 5 sizes, with 2 to 32 vCPUs and 15.25 to 244 GiB of memory. You can also use Reserved Instances to save money on your steady-state database workloads.
- Storage – You pay $0.10 per GB per month for storage, based on the actual number of bytes of storage consumed by your database, sampled hourly. For this price you get a total of six copies of your data, two copies in each of three Availability Zones.
- I/O – You pay $0.20 for every million I/O requests that your database makes.
See the Amazon Aurora Pricing page for more information.
Go For It
To learn more, visit the Amazon Aurora page and read the Amazon Aurora Documentation. You can also attend the upcoming Amazon Aurora Webinar to learn more and to see Aurora in action.
— Jeff;