Category: Amazon Aurora
Sign up Today – Preview of Amazon Aurora with PostgreSQL Compatibility
Last year we announced that we would be bringing PostgreSQL compatibility to Amazon Aurora. At that time I invited you to sign up for our private preview so that you could take a closer look.
The response to that request was strong! Our customers already understood that Amazon Aurora would provide them with high availability and high durability, and were looking forward to running their PostgreSQL 9.6 applications in the AWS Cloud.
Opening up the Preview
Today we are opening up the preview of Amazon Aurora with PostgreSQL Compatibility to all interested customers and you can sign up today. The preview runs in the US East (Northern Virginia) Region and delivers two to three times the performance of PostgreSQL running in traditional environments. It also supports quick, easy creation of fast, low-latency read replicas.
Amazon RDS Performance Insights Included
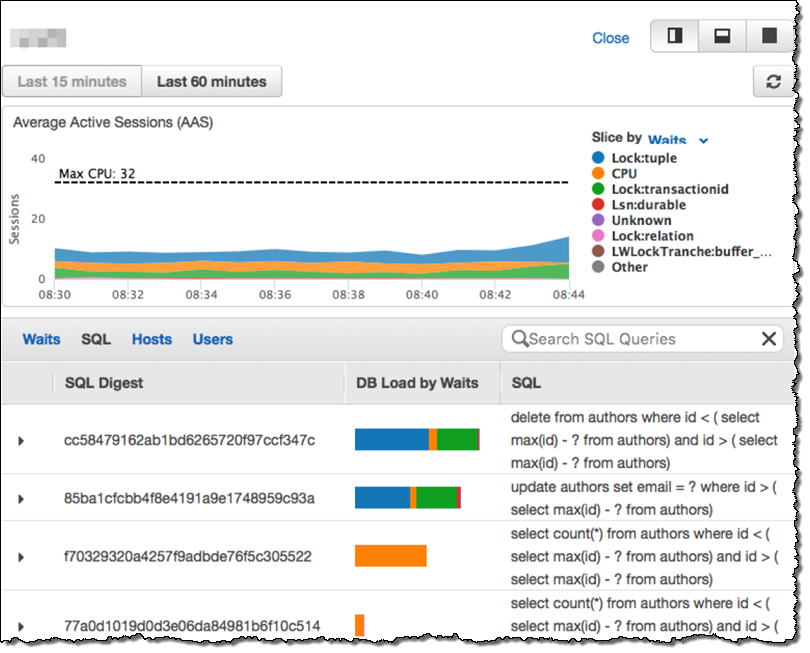
The preview includes our new Amazon RDS Performance Insights tool. You will be able to use this tool to understand your database performance at a very detailed level, up to and including the ability to look inside of each query. You can use the Performance Insights dashboard to visualize the database load and to filter it by SQL statements, waits, users, or hosts:
— Jeff;
Amazon Aurora Update – More Cross Region & Cross Account Support, T2.Small DB Instances, Another Region
I’m in catch-up mode again, and would like to tell you about some recent improvements that we have made to Amazon Aurora. As a reminder, Aurora is our high-performance MySQL-compatible (and soon PostgreSQL-compatible) enterprise-class database (read Now Available – Amazon Aurora and Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS for an introduction).
Here’s are the newest additions to Aurora:
- Cross Region Snapshot Copy
- Cross Region Replication for Encrypted Databases
- Cross Account Encrypted Snapshot Sharing
- Availability in the US West (Northern California) Region
- T2.Small Instance Support
Let’s take a quick look at each one!
Cross Region Snapshot Copy
You can now copy Amazon Aurora snapshots (either automatic or manual) from one region to another. Select the snapshot, choose Copy Snapshot from the Snapshot Actions menu, pick a region, and enter a name for the new snapshot:
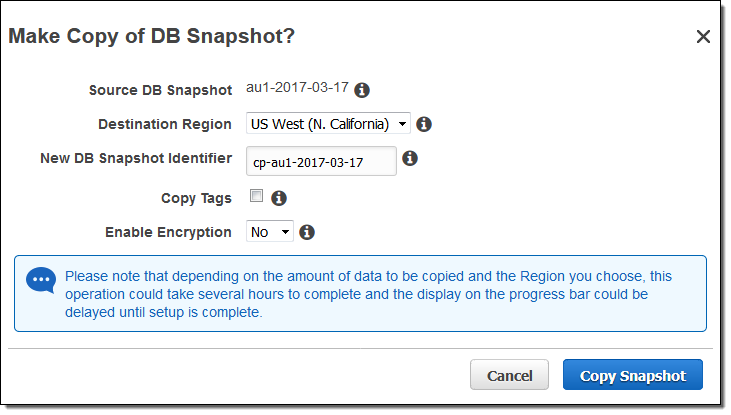
You can also choose to encrypt the snapshot as part of this operation. To learn more, read Copying a DB Snapshot or DB Cluster Snapshot.
Cross Region Replication for Encrypted Databases
You can already enable encryption when you create a fresh Amazon Aurora DB Instance:
You can now create a read replica in another region with a couple of clicks. You can use this to build multi-region, highly available systems or to move the data closer to the user. To create a cross region read replica, simply select the existing DB Instance and choose Create Cross Region Read Replica from the menu:
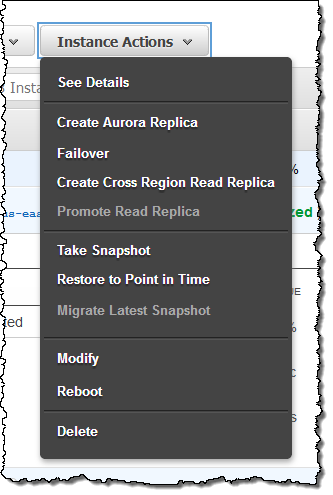
Then you choose the destination region in the Network & Security settings, and click on Create:
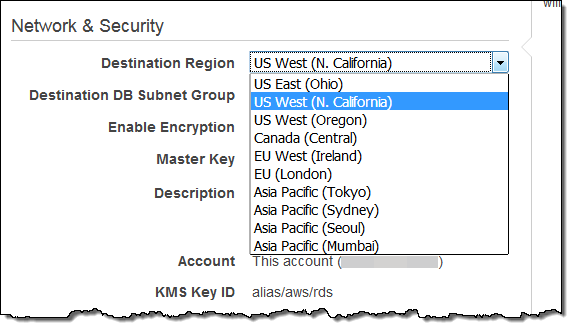
The destination region must include a DB Subnet Group that encompasses 2 or more Availability Zones.
To learn more about this powerful new feature, read Replicating Amazon Aurora DB Clusters Across AWS Regions.
Cross Account Encrypted Snapshot Sharing
You already have the ability to configure periodic, automated snapshots when you create your Amazon Aurora DB Instance. You can also create snapshots at any desired time with a couple of clicks:
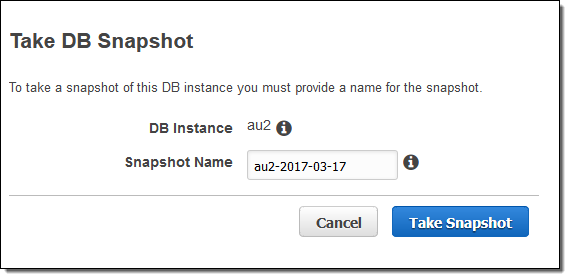
If the DB Instance is encrypted, the snapshot will be as well.
You can now share encrypted snapshots with other AWS accounts. In order to use this feature, the DB Instance (and therefore the snapshot) must be encrypted with a Master Key other than the default RDS key. Select the snapshot and choose Share Snapshot from the Snapshot Actions menu:
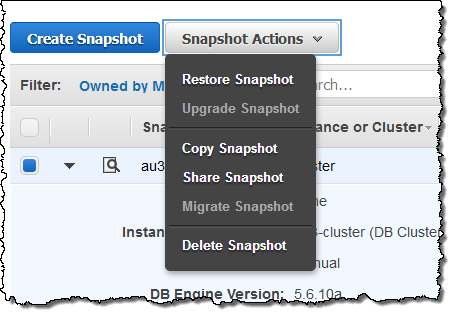
Then enter the target AWS Account ID(s), clicking Add after each one, and click on Save to share the snapshot:
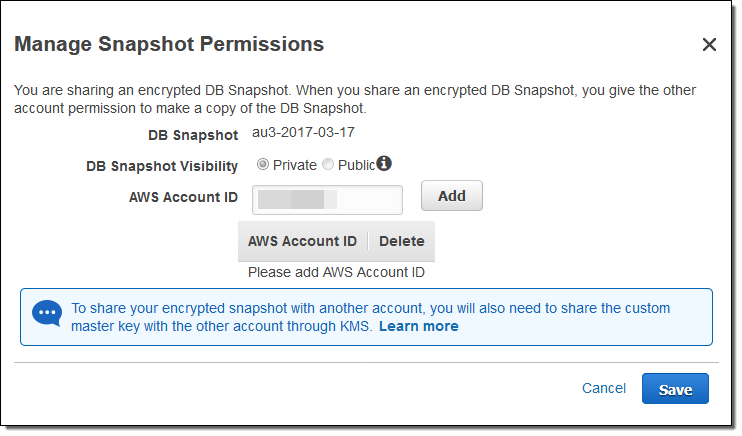
You will also need to share the key that was used to encrypt the snapshot. To learn more about this feature, read Sharing a DB Snapshot or DB Cluster Snapshot.
Availability in the US West (Northern California Region)
You can now launch Amazon Aurora DB Instances in the US West (Northern California) Region. Here’s the full list of regions where Aurora is available:
- US East (Northern Virginia)
- US East (Ohio)
- US West (Oregon)
- US West (Northern California)
- Canada (Central)
- EU (Ireland)
- EU (London)
- Asia Pacific (Tokyo)
- Asia Pacific (Sydney)
- Asia Pacific (Seoul)
- Asia Pacific (Mumbai)
See the Amazon Aurora Pricing page for pricing info in each region.
T2.Small Instance Support
You can now launch t2.small DB Instances:
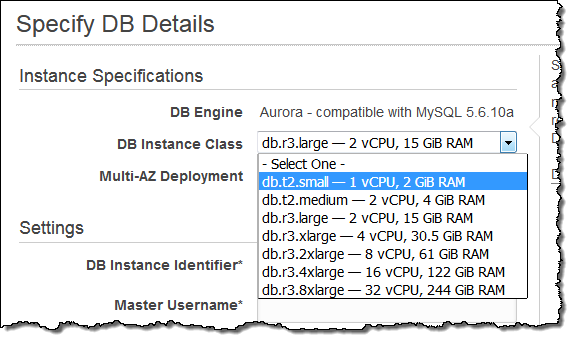
These economical instances are a great fit for dev & test environments and for light production workloads. You can also use them to gain some experience with Amazon Aurora. These instances (along with six others, including the t2.medium that we launched last November) are available in all AWS regions where Aurora is available.
On-Demand pricing for t2.small DB Instances starts at $0.041 per hour in the US East (Northern Virginia) Region, dropping to $0.018 per hour for an All Upfront Reserved Instance with a 3 year term (see the Amazon Aurora Pricing page for more info).
— Jeff;
Amazon RDS – 2016 in Review
Even though we published 294 posts on this blog last year, I left out quite a number of worthwhile launches! Today I would like to focus on Amazon Relational Database Service (RDS) and recap all of the progress that the teams behind this family of services made in 2016. The team focused on four major areas last year:
- High Availability
- Enhanced Monitoring
- Simplified Security
- Database Engine Updates
Let’s take a look at each of these areas…
High Availability
Relational databases are at the heart of many types of applications. In order to allow our customers to build applications that are highly available, RDS has offered multi-AZ support since early 2010 (read Amazon RDS – Multi-AZ Deployments For Enhanced Availability & Reliability for more info). Instead of spending weeks setting up multiple instances, arranging for replication, writing scripts to detect network, instance, & network issues, making failover decisions, and bringing a new secondary instance online, you simply opt for Multi-AZ Deployment when you create the Database Instance. RDS also makes it easy for you to create cross-region read replicas.
Here are some of the other enhancements that we made in 2016 in order to help you to achieve high availability:
- Amazon RDS for MariaDB now covered by RDS SLA.
- Amazon RDS adds Multi-AZ support for SQL Server in Asia Pacific (Seoul) AWS Region.
- Amazon RDS for PostgreSQL now supports cross-region read replicas.
- Amazon RDS for PostgreSQL now supports logical replication.
- Amazon RDS now supports read replicas of encrypted database instances across regions.
- Additional Failover Control for Amazon Aurora.
- Cross-Region Read Replicas for Amazon Aurora.
- Amazon RDS now supports copying encrypted snapshots of encrypted DB instances across regions.
- Amazon RDS for SQL Server supports SQL Server Native Backup/Restore with S3.
Enhanced Monitoring
We announced the first big step toward enhanced monitoring at the end of 2015 (New – Enhanced Monitoring for Amazon RDS) with support for MySQL, MariaDB, and Amazon Aurora and then made additional announcements in 2016:
- Enhanced Monitoring for Amazon RDS now available for MySQL 5.5.
- RDS Enhanced Monitoring is now available in Asia Pacific (Seoul).
- Amazon RDS Enhanced Monitoring is now available in South America (Sao Paulo) and China (Beijing).
- Enhanced Monitoring is now available for Amazon RDS for Oracle.
- Enhanced Monitoring and option to enforce SSL connections is now available for Amazon RDS for PostgreSQL.
- Enhanced Monitoring for SQL Server.
Simplified Security
We want to make it as easy and simple as possible for you to use encryption to protect your data, whether it is at rest or in motion. Here are the enhancements that we made in this area last year:
- MariaDB audit plug-in now available for RDS MySQL and MariaDB.
- Amazon RDS for SQL Server supports Windows Authentication.
- Secure Sockets Layer (SSL) and Oracle Native Network Encryption (NNE) in all Amazon RDS for Oracle editions.
- Amazon RDS for Oracle now supports the Oracle Label Security (OLS) option.
- RDS now supports sharing encrypted database snapshots with other AWS accounts.
- RDS now allows specifying the VPC for your Amazon RDS DB Instance.
- Cross-account snapshot sharing for Amazon Aurora.
Database Engine Updates
The open source community and the vendors of commercial databases add features and produce new releases at a rapid pace and we track their work very closely, aiming to update RDS as quickly as possible after each significant release. Here’s what we did in 2016:
- MariaDB:
- MySQL:
- SQL Server:
- Support for SQL Server 2008 R2 SP3 and SQL Server 2012 SP3.
- Support Microsoft SQL Server 2016.
- Oracle:
- Outbound network access using custom DNS servers.
- January PSU patches, improved custom Oracle directories and read privileges support.
- Oracle Repository Creation Utility (RCU) and April PSU patches.
- 11g to 12c major version upgrade.
- Oracle Enterprise Manager (OEM) Cloud Control.
- License included offering for Oracle Standard Edition Two (SE2).
- Amazon Aurora:
- Cluster creation from a MySQL Backup.
- NUMA-aware scheduling.
- Parallel read-ahead.
- Single reader endpoint.
- Lambda integration.
- Data loading from S3.
- Spatial indexing & zero-downtime patching.
- Efficient storage of binary logs.
- Cluster-level Maintenance and Patching.
- Lock compression, performance schema, hot row contention improvements, improved memory handling, and smart read selector.
- HIPAA-eligibility.
- PostgreSQL:
Stay Tuned
We’ve already made some big announcements this year (you can find them in the AWS What’s New for 2017) with plenty more in store including the recently announced PostgreSQL-compatible version of Aurora, so stay tuned! You may also want to subscribe to the AWS Database Blog for detailed posts that will show you how to get the most from RDS, Amazon Aurora, and Amazon ElastiCache.
— Jeff;
PS – This post does not include all of the enhancements that we made to AWS Database Migration Service or the Schema Conversion Tool last year. I’m working on another post on that topic.
New – Create an Amazon Aurora Read Replica from an RDS MySQL DB Instance
Migrating from one database engine to another can be tricky when the database is supporting an application or a web site that is running 24×7. Without the option to take the database offline, an approach that is based on replication is generally the best solution.
Today we are launching a new feature that allows you to migrate from an Amazon RDS DB Instance for MySQL to Amazon Aurora by creating an Aurora Read Replica. The migration process begins by creating a DB snapshot of the existing DB Instance and then using it as the basis for a fresh Aurora Read Replica. After the replica has been set up, replication is used to bring it up to date with respect to the source. Once the replication lag drops to 0, the replication is complete. At this point, you can make the Aurora Read Replica into a standalone Aurora DB cluster and point your client applications at it.
Migration takes several hours per terabyte of data, and works for MySQL DB Instances of up to 6 terabytes. Replication runs somewhat faster for InnoDB tables than it does for MyISAM tables, and also benefits from the presence of uncompressed tables. If migration speed is a factor, you can improve it by moving your MyISAM tables to InnoDB tables and uncompressing any compressed tables.
To migrate an RDS DB Instance, simply select it in the AWS Management Console, click on Instance Actions, and choose Create Aurora Read Replica:
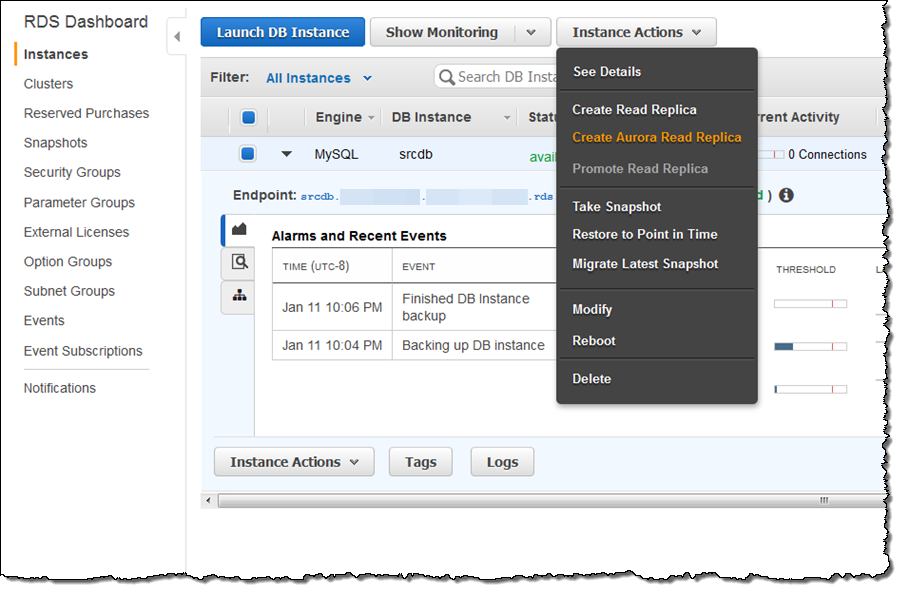
Then enter your database instance identifier, set any other options as desired, and click on Create Read Replica:
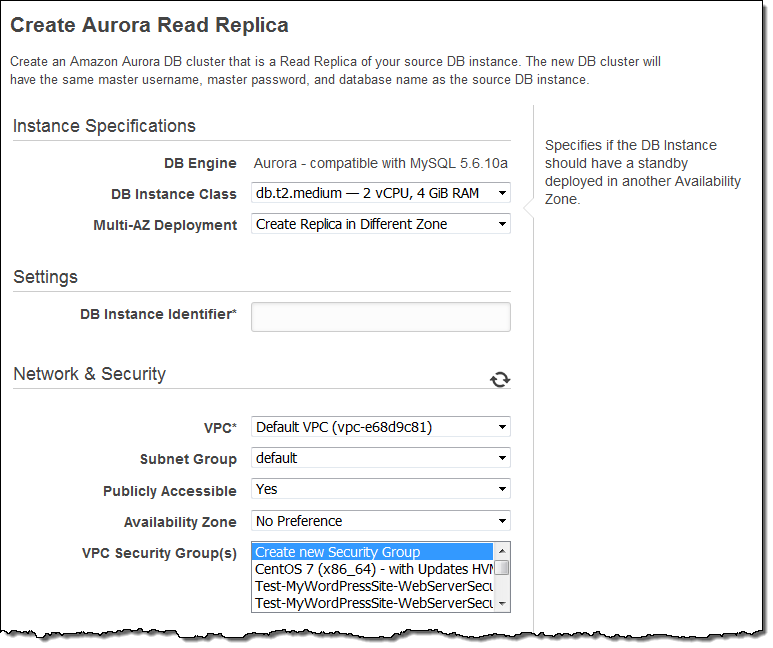
You can monitor the progress of the migration in the console:
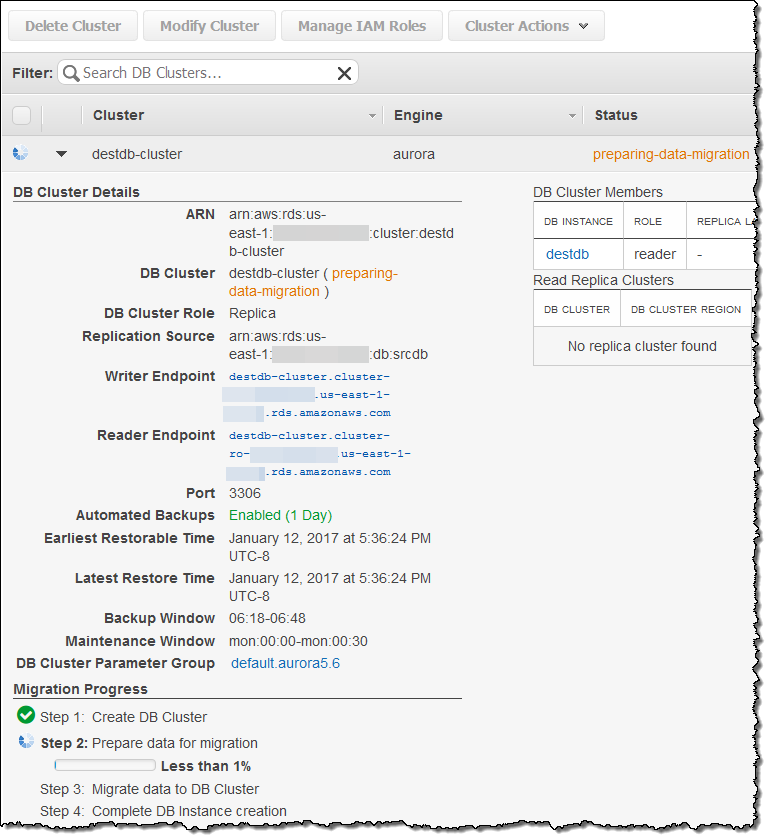
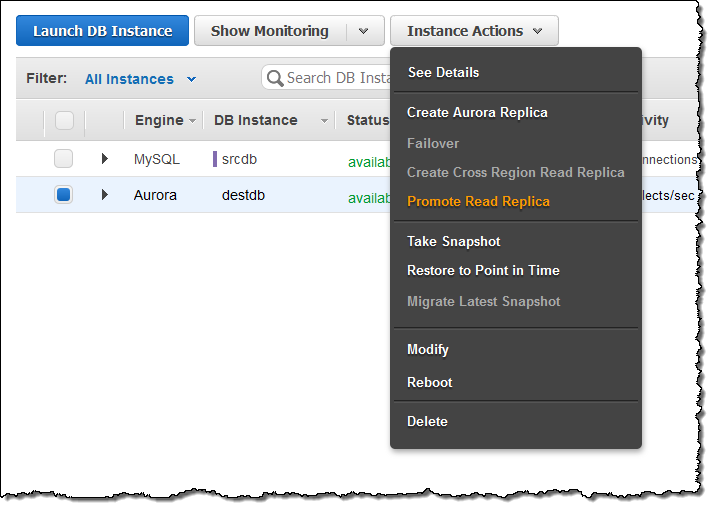
After the migration is complete, wait for the Replica Lag to reach zero on the new Aurora Read Replica (use the SHOW SLAVE STATUS command on the replica and look for “Seconds behind master”) to indicate that the replica is in sync with the source, stop the flow of new transactions to the source MySQL DB Instance, and promote the Aurora Read Replica to a DB cluster:
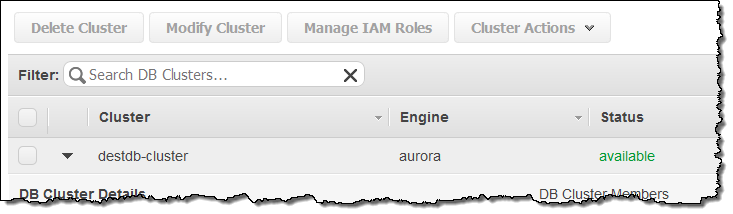
Confirm your intent and then wait (typically a minute or so) until the new cluster is available:
Instruct your application to use the cluster’s read and write endpoints, and you are good to go!
— Jeff;
Amazon Aurora Update – Spatial Indexing and Zero-Downtime Patching
Despite stiff competition from many other AWS services, Amazon Aurora is still the fastest-growing service in AWS history! Our customers love the speed, performance, and availability. They are making great use of the MySQL compatible side of Aurora today, and are looking forward to using the PostgreSQL compatible side in the future (read Amazon Aurora Update – PostgreSQL Compatibility to learn more and to see a list of other recent additions to Aurora).
Today we are launching two features that were announced at AWS re:Invent: spatial indexing and zero-downtime patching.
Spatial Indexing
Amazon Aurora already allows you to use the GEOMETRY data type to represent points and areas on a sphere. You can create columns of this type and then use functions such as ST_Contains, ST_Crosses, and ST_Distance (and many others) to perform spatial queries. These queries are powerful, but can be inefficient to process at scale, limiting their usefulness for large data sets.
In order to allow you to build large-scale, location-aware applications using Aurora, you can now create a specialized, highly-efficient index on your spatial data. Aurora uses a a dimensionally ordered space-filling curve (for you mathematical types) to make your retrievals fast, accurate, and scalable. The index uses a b-tree and delivers performance that is up to two orders of magnitude better than MySQL 5.7 (watch this segment of the Amazon Aurora Deep Dive video or review the presentation for details).
You will need to enable Aurora Lab Mode in order to make use of this new feature. After you have done this, you can add spatial indexes to existing tables or create new tables that include spatial indexes (read Amazon Aurora and Spatial Data to learn more).
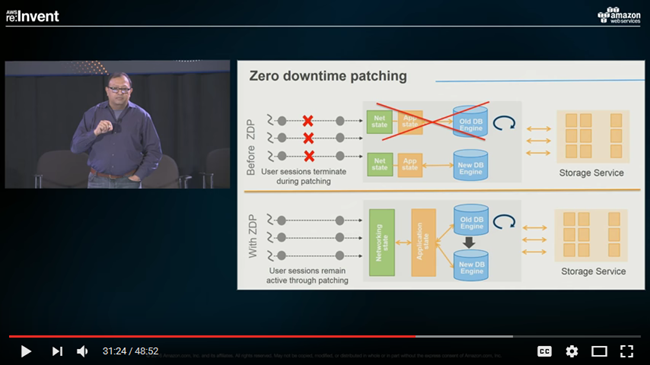
Zero-Downtime Patching
In today’s 24×7 world, there’s never a good time to take a database offline for patches and other updates. Although it is possible to maintain high availability by using read replicas and promotion, there’s always room to do better.
Our new zero-downtime patching feature allows Aurora instances to be updated in place, with no downtime and no affect on availability. This feature works with instances that are running the current (1.10) version of Aurora, and works on a best-effort basis. It works for both single node clusters and for the writer instance in multi-node clusters, but cannot function if binary logging is active.
The patching mechanism pauses while waiting for open SSL connections, active locks, pending transactions, and temporary tables to clear up. If a suitable time window appears, the patch is made in zero-downtime fashion. Application sessions are preserved and the database engine restarts while the patch is in progress, leading to a transient (5 second or so) drop in throughput. If no suitable time window becomes available, patching reverts to the standard behavior.
To learn more about how this works and how we implemented it, watch this segment of the Amazon Aurora Deep Dive video.
Available Now
These new features are available now and you can start using them today!
— Jeff;
Amazon Aurora Update – PostgreSQL Compatibility
Just two years ago (it seems like yesterday), I introduced you to Amazon Aurora in my post Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS. In that post I told you how the RDS team took a fresh, unconstrained look at the relational database model and explained how they built a relational database for the cloud.
The feedback that we have received from our customers since then has been heart-warming. Customers love the MySQL compatibility, the focus on high availability, and the built-in encryption. They count on the fact that Aurora is built around fault-tolerant, self-healing storage that allows them to scale from 10 GB all the way up to 64 TB without pre-provisioning. They know that Aurora makes six copies of their data across three Availability Zones and backs it up to Amazon Simple Storage Service (S3) without impacting performance or availability. As they scale, they know that they can create up to 15 low-latency read replicas that draw from common storage. To learn more about how our customers are using Aurora in world-scale production environments, take some time to read our Amazon Aurora Testimonials.
Of course, customers are always asking for more, and we do our best to understand their needs and to oblige. Here is a look back at some recent updates that were made in response to specific feedback from customers:
- October – Call Lambda Functions from Stored Procedures.
- October – Load Data from S3.
- September – Reader Endpoint for Load Balancing and Higher Availability.
- September – Parallel Read Ahead, Faster Indexing, NUMA Awareness.
- July – Create Cluster from MySQL Backup.
- June – Cross-Region Read Replicas.
- May – Cross-Account Snapshot Sharing.
- April – Cluster View in RDS Console.
- March – Additional Failover Control.
- March – Local Time Zone Support.
- March – Availability in Asia Pacific (Seoul).
- February – Availability in Asia Pacific (Sydney).
And Now, PostgreSQL Compatibility
 In addition to the feature-level feedback, we received many requests for additional database compatibility. At the top of the list was compatibility with PostgreSQL. This open source database has been under continuous development for 20 years and has found a home in many enterprises and startups. Customers like the enterprise features (similar to those offered by SQL Server and Oracle), performance benefits, and the geospatial objects associated with PostgreSQL. They would love to have access to these capabilities while also taking advantage of all that Aurora has to offer.
In addition to the feature-level feedback, we received many requests for additional database compatibility. At the top of the list was compatibility with PostgreSQL. This open source database has been under continuous development for 20 years and has found a home in many enterprises and startups. Customers like the enterprise features (similar to those offered by SQL Server and Oracle), performance benefits, and the geospatial objects associated with PostgreSQL. They would love to have access to these capabilities while also taking advantage of all that Aurora has to offer.
Today we are launching a preview of Amazon Aurora PostgreSQL-Compatible Edition. It offers all of the benefits that I listed above, including high durability, high availability, and the ability to quickly create and deploy read replicas. Here are some of the things you will love about it:
Performance – Aurora delivers up to 2x the performance of PostgreSQL running in traditional environments.
Compatibility – Aurora is fully compatible with the open source version of PostgreSQL (version 9.6.1). On the stored procedure side, we are planning to support Perl, pgSQL, Tcl, and JavaScript (via the V8 JavaScript engine). We are also planning to support all of the PostgreSQL features and extensions that are supported in Amazon RDS for PostgreSQL.
Cloud Native – Aurora takes full advantage of the fact that it is running within AWS. Here are some of the touch points:
- AWS Key Management Service (KMS) – Encryption at rest.
- AWS Identity and Access Management (IAM) – Fine-grained access control to Aurora APIs and resources.
- Amazon Simple Storage Service (S3) – Aurora backs up your database to Amazon S3 continuously, and uses it for almost instant recovery.
- Amazon Relational Database Service (RDS) – Provisioning, backup management, monitoring, scaling of compute resources, managing database configurations.
- AWS Database Migration Service – Easy migration from on-premises or EC2-hosted PostgreSQL, Oracle, or SQL Server.
- AWS Schema Conversion Tool – Easy conversion from one database schema to another as part of a migration.
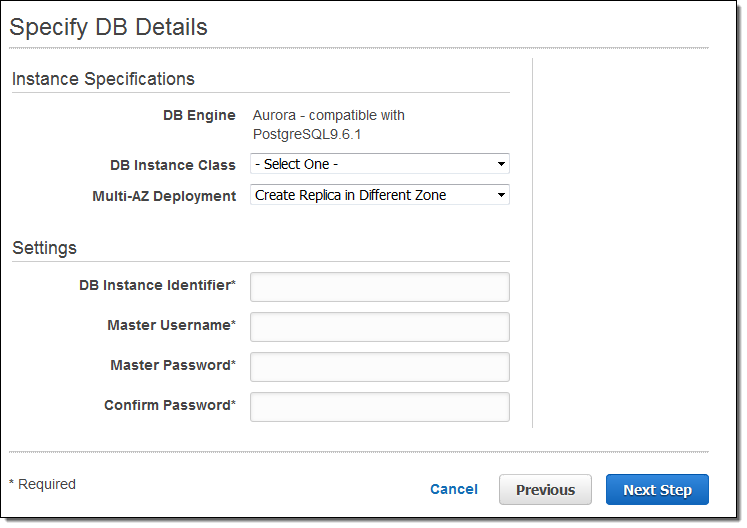
Here’s how you access all of this from the RDS Console. You start by selecting the PostgresSQL Compatible option:
Then you choose your database instance type, decide on Multi-AZ deployment, name your database instance, and set up a user name & password:
We are making a preview of PostgreSQL compatibility for Amazon Aurora available in the US East (Northern Virginia) Region today and you can sign up now for access!
A Quick Comparison
My colleagues David Wein and Grant McAlister ran some tests that compared the performance of PostgreSQL compatibility for Amazon Aurora against PostgreSQL 9.6.1. The database servers were run on m4.16xlarge instances and the test clients were run on c4.8xlarge instances.
PostgreSQL was run using 45K of Provisioned IOPS storage consisting of three 15K IOPS EBS volumes striped into one logical volume, topped off with an ext4 file system. They enabled WAL compression and aggressive autovacuum, both of which improve the performance of PostgreSQL on the workloads that they tested.
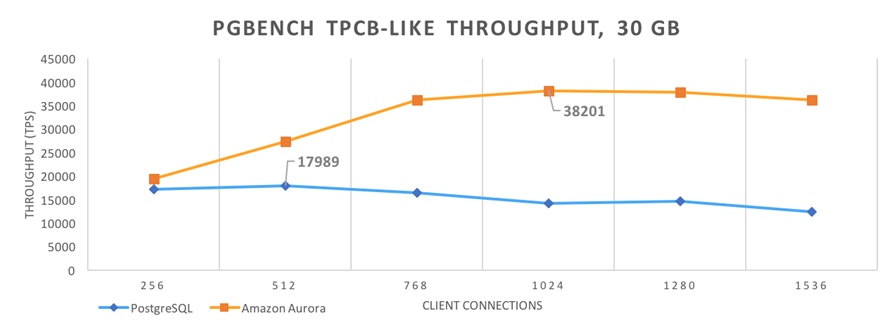
David & Grant ran the standard PostgreSQL pgbench benchmarking tool. They used a scaling factor of 2000 which creates a 30 GiB database and uses several different client counts. Each data point ran for one hour, with the database recreated before each run. The graph below shows the results:
David also shared the final seconds of one of his runs:
progress: 3597.0 s, 39048.4 tps, lat 26.075 ms stddev 9.883
progress: 3598.0 s, 38047.7 tps, lat 26.959 ms stddev 10.197
progress: 3599.0 s, 38111.1 tps, lat 27.009 ms stddev 10.257
progress: 3600.0 s, 34371.7 tps, lat 29.363 ms stddev 14.468
transaction type:
scaling factor: 2000
query mode: prepared
number of clients: 1024
number of threads: 1024
duration: 3600 s
number of transactions actually processed: 137508938
latency average = 26.800 ms
latency stddev = 19.222 ms
tps = 38192.805529 (including connections establishing)
tps = 38201.099738 (excluding connections establishing)
They also shared a per-second throughput graph that covered the last 40 minutes of a similar run:
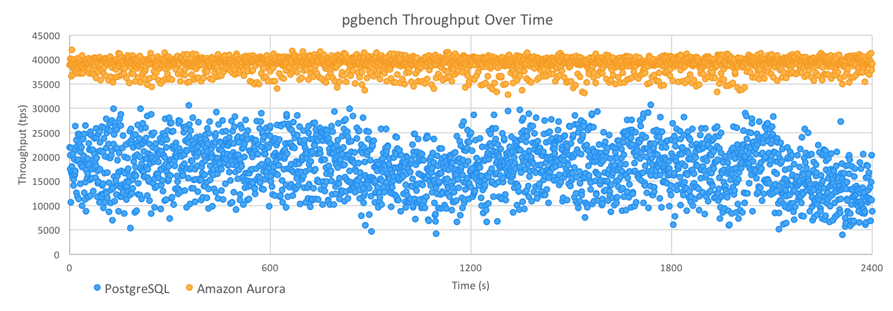
As you can see, Amazon Aurora delivered higher throughput than PostgreSQL, with about 1/3 of the jitter (standard deviations of 1395 TPS and 5081 TPS, respectively).
David and Grant are now collecting data for a more detailed post that they plan to publish in early 2017.
Coming Soon – Performance Insights
We are also working on a new tool that is designed to help you to understand database performance at a very detailed level. You will be able to look inside of each query and learn more about how your database handles it. Here’s a sneak preview screen shot:
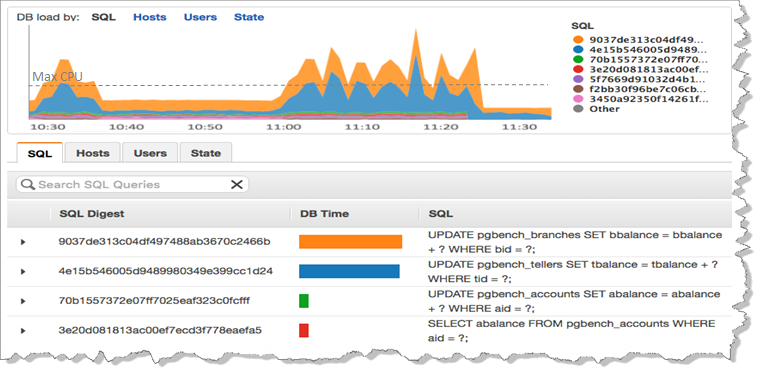
You will be able to access the new Performance Insights as part of the preview. I’ll have more details and a full tour later.
— Jeff;
Update! We have a webinar coming up on January 16th. Register for it here.
Use Amazon Aurora for Dev & Test Workloads with new T2.Medium DB Instance Class
Amazon Aurora already allows you to make your choice of five DB instance classes ranging from the db.r3.large (2 vCPUs and 15 GiB of RAM) up to the db.r3.8xlarge (32 vCPUs and 244 GiB of RAM). These instances support a very wide range of production-scale applications and use cases.
Today we giving you a sixth choice, the new db.t2.medium DB instance class with 2 vCPUs and 4 GiB of RAM. Steady-state, this instance class has access to 40% of the performance of a single core, and can burst to full-core performance when processing CPU-intensive queries and other database tasks. Like the similarly-named EC2 instances, this new instance class starts out with a full allocation of CPU Credits, which are spent when the instance is active and accumulate when it is not (my post, New Low Cost EC2 Instances with Burstable Performance, contains a full explanation).
The db.t2.medium should be a great fit for many of your development and test scenarios, and you should also consider them for some of your less-demanding production workloads. You can monitor the CPUCreditUsage and CPUCreditBalance metrics to track the usage and accumulation of credits over time.
Now Available
You can create Amazon Aurora database instances that make use of this new DB instance class today. It is available in all regions where Amazon Aurora is currently available. Prices start at $0.082 per hour.
— Jeff;
Amazon Aurora Update – Call Lambda Functions From Stored Procedures; Load Data From S3
Many AWS services work just fine by themselves, but even better together! This important aspect of our model allows you to select a single service, learn about it, get some experience with it, and then extend your span to other related services over time. On the other hand, opportunities to make the services work together are ever-present, and we have a number of them on our customer-driven roadmap.
Today I would like to tell you about two new features for Amazon Aurora, our MySQL-compatible relational database:
Lambda Function Invocation – The stored procedures that you create within your Amazon Aurora databases can now invoke AWS Lambda functions.
Load Data From S3 – You can now import data stored in an Amazon Simple Storage Service (S3) bucket into a table in an Amazon Aurora database.
Because both of these features involve Amazon Aurora and another AWS service, you must grant Amazon Aurora permission to access the service by creating an IAM Policy and an IAM Role, and then attaching the Role to your Amazon Aurora database cluster. To learn how to do this, see Authorizing Amazon Aurora to Access Other AWS Services On Your Behalf.
Lambda Function Integration
Relational databases use a combination of triggers and stored procedures to enable the implementation of higher-level functionality. The triggers are activated before or after some operations of interest are performed on a particular database table. For example, because Amazon Aurora is compatible with MySQL, it supports triggers on the INSERT, UPDATE, and DELETE operations. Stored procedures are scripts that can be run in response to the activation of a trigger.
You can now write stored procedures that invoke Lambda functions. This new extensibility mechanism allows you to wire your Aurora-based database to other AWS services. You can send email using Amazon Simple Email Service (SES), issue a notification using Amazon Simple Notification Service (SNS), insert publish metrics to Amazon CloudWatch, update a Amazon DynamoDB table, and more.
At the appliction level, you can implement complex ETL jobs and workflows, track and audit actions on database tables, and perform advanced performance monitoring and analysis.
Your stored procedure must call the mysql_lambda_async procedure. This procedure, as the name implies, invokes your desired Lambda function asynchronously, and does not wait for it to complete before proceeding. As usual, you will need to give your Lambda function permission to access any desired AWS services or resources.
To learn more, read Invoking a Lambda Function from an Amazon Aurora DB Cluster.
Load Data From S3
As another form of integration, data stored in an S3 bucket can now be imported directly in to Aurora (up until now you would have had to copy the data to an EC2 instance and import it from there).
The data can be located in any AWS region that is accessible from your Amazon Aurora cluster and can be in text or XML form.
To import data in text form, use the new LOAD DATA FROM S3 command. This command accepts many of the same options as MySQL’s LOAD DATA INFILE, but does not support compressed data. You can specify the line and field delimiters and the character set, and you can ignore any desired number of lines or rows at the start of the data.
To import data in XML form, use the new LOAD XML from S3 command. Your XML can look like this:
<row column1="value1" column2="value2" />
...
<row column1="value1" column2="value2" />
Or like this:
<row>
<column1>value1</column1>
<column2>value2</column2>
</row>
...Or like this:
<row>
<field name="column1">value1</field>
<field name="column2">value2</field>
</row>
...To learn more, read Loading Data Into a DB Cluster From Text Files in an Amazon S3 Bucket.
Available Now
These new features are available now and you can start using them today!
There is no charge for either feature; you’ll pay the usual charges for the use of Amazon Aurora, Lambda, and S3.
— Jeff;
New Reader Endpoint for Amazon Aurora – Load Balancing & Higher Availability
Feature-by-feature, Amazon Aurora has become more powerful and easier to use. Over the past months we have given you the ability to create a cluster from a MySQL backup, create cross-region read replicas, share snapshots across accounts, exercise additional control over failover, and migrate from other in-cloud or on-premises databases to Aurora.
Today, as an extension of Aurora’s existing read replica model, we are introducing a new cluster-level read endpoint. Your application can continue to direct read queries to the individual replicas as before. However, you can also update it to make use of the new endpoint. Doing so will give you two important advantages: load balancing and higher availability:
Load Balancing – Connecting to the cluster endpoint allows Aurora to load-balance connections across the replicas in the DB cluster. This helps to spread the read workload around and can lead to better performance and more equitable use of the resources available to each replica. In the event of a failover, if the replica that you are connected to is promoted to the primary instance, the connection will be dropped. You can then reconnect to the reader endpoint in order to send your read queries to the other replicas in the cluster.
Higher Availability – You can place multiple Aurora replicas in distinct Availability Zones and connect to them via the new endpoint. In the unlikely event that an Availability Zone fails, applications that make use of the new endpoint will continue to send read traffic to the other replicas with minimal disruption.
Find the Endpoint
You can find the new Reader Endpoint in the Aurora Console:
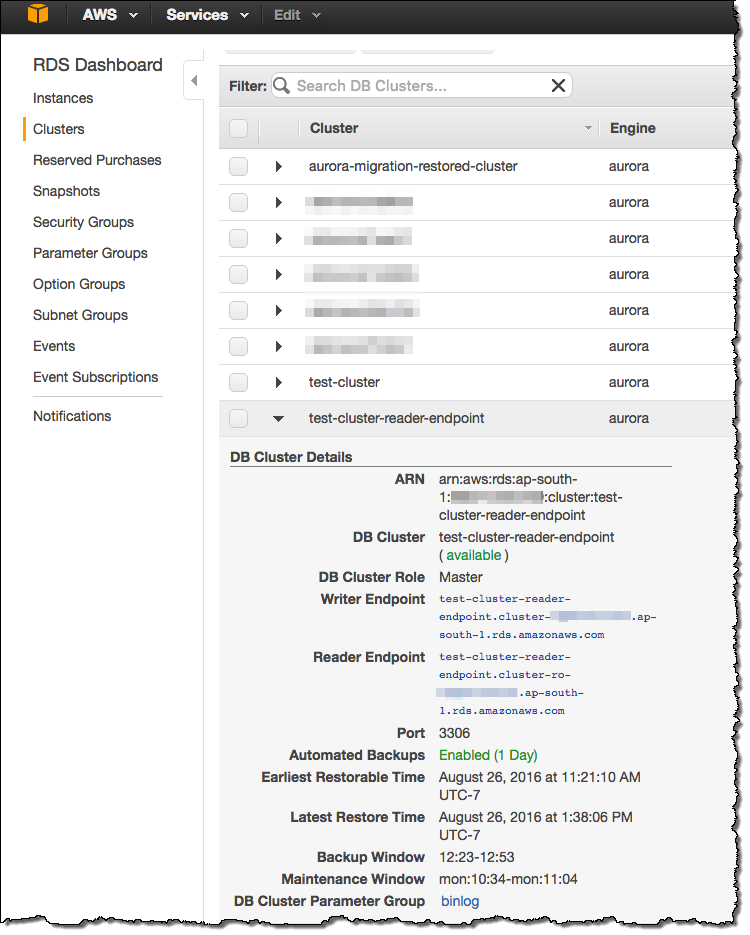
This handy new feature is available now and you can start using it today!
To learn more about this and other new Amazon Aurora features, attend our Amazon Aurora – New Features webinar on September 28th.
— Jeff;
Amazon Aurora Update – Parallel Read Ahead, Faster Indexing, NUMA Awareness
Amazon Aurora is currently the fastest-growing AWS service!
As a relational database designed for the cloud (read Amazon Aurora – New Cost-Effective MySQL-Compatible Database Engine for Amazon RDS to learn more), Aurora offers great performance, effortless storage scaling all the way up to 64 TB, durability, and high availability. Because Aurora was designed to be compatible with MySQL, our customers have been able to move existing applications and to build new ones with ease.
With MySQL compatibility “on top” and the unique, cloud-native Aurora architecture underneath, we have a lot of room to innovate. We can continue to make Aurora more efficient while still remaining compatible with all of those applications.
Today we are making three such performance improvements to Aurora, each one aimed at making Aurora more performant on a wide range of workloads commonly run by AWS customers. Here’s an overview:
Parallel Read Ahead – Range selects, full table scans, table alterations, and index generation are now up to 5x faster.
Faster Index Build – Generation of indexes is now about 75% faster.
NUMA-Aware Scheduling – When run on instances with more than one CPU chip, reads from the query cache and the buffer cache are faster, improving overall throughput by up to 10%.
Let’s dive in…
Parallel Read Ahead
The InnoDB storage engine used by MySQL organizes table rows and the underlying storage (disk pages) using the index keys. This makes sequential scans over full tables fast and efficient for freshly created tables. However, as rows are updated, inserted, and deleted over time, the storage becomes fragmented, the pages are no longer physically sequential, and scans can slow down dramatically. InnoDB’s Linear Read Ahead feature attempts to deal with this fragmentation by bringing up to 64 pages in to memory before they are actually needed. While well-intentioned, this feature does not provide a meaningful performance improvement on enterprise-scale workloads.
With today’s update, Aurora is now a lot smarter about handling this very common situation. When Aurora scans a table, it logically (as opposed to physically) identifies and then performs a parallel prefetch of the additional pages. The parallel prefetch takes advantage of Aurora’s replicated storage architecture (two copies in each of three Availability Zones) and helps to ensure that the pages in the database cache are relevant to the scan operation.
As a result of this change, range selects, full table scans, the ALTER TABLE operation, and index generation are up to 5x faster than before.
You will see the improved performance as soon as you upgrade to Aurora 1.7 (see below for more information).
Faster Index Build
When you create a primary or secondary index on a table, the storage engine creates a tree structure that contains the new keys. This process entails a lot of top-down tree searching and plenty of page-splitting as the tree is restructured to accommodate more and more keys.
Aurora now builds the trees in a bottom-up fashion, building the leaves first and then adding parent pages as needed. This reduces the amount of back-and-forth to storage, and also obviates the need to split pages since each page is filled once.
With this change, adding indexes and rebuilding tables is now up to 4x faster than before, depending on the table schema. For example, the Aurora team created a table with the following schema, and added 100 million rows, resulting in a 5 GB table:
create table test01 (id int not null auto_increment primary key, i int, j int, k int);
Then they added four additional indexes:
alter table test01 add index (i), add index (j), add index (k), add index comp_idx(i, j, k);
On a db.r3.large instance, the time to run this query dropped from 67 minutes to 25 minutes. On a db.r3.8xlarge instance, the time dropped from 29 minutes to 11.5 minutes.
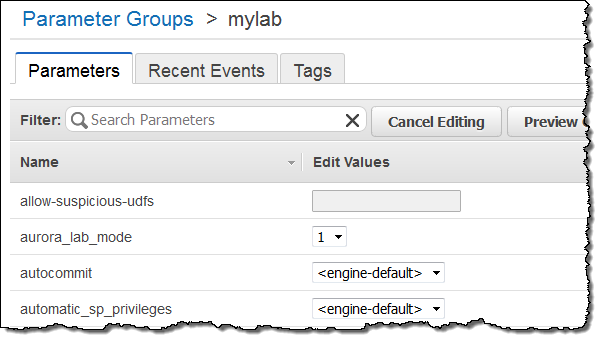
This is a brand new feature and we would like you to try it out on your non-production workloads. You’ll need to upgrade to Aurora 1.7 and then set aurora_lab_mode to 1 in the DB Instance Parameter group (see DB Cluster and DB Instance Parameters to learn more):
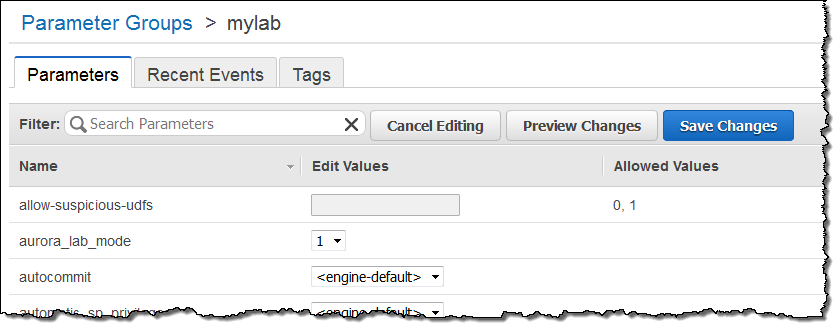
The team is very interested in your feedback on this performance enhancement. Please feel free to post your observations in the Amazon RDS Forum.
NUMA-Aware Scheduling
The largest DB Instance (db.r3.8xlarge) has two CPU chips and a feature commonly known as NUMA, short for Non-Uniform Memory Access. On systems of this type, each an equal fraction of main memory is directly and efficiently accessible to each CPU. The remaining memory is accessible via a somewhat less efficient cross-CPU access path.
Aurora now does a better job of scheduling threads across the CPUs in order to take advantage of this disparity in access times. The threads no longer need to fight against each other for access to the less-efficient memory attached to the other CPUs. As a result, CPU-bound operations that make heavy use of the query cache and the buffer cache now run up to 10% faster. The performance improvement will be most apparent when you are making hundreds or thousands of connections to the same database instance. As an example, performance on the Sysbench oltp.lua benchmark grew from 570,000 reads/second to 625,000 reads/second. The test was run on a db.r3.8xlarge DB Instance with the following parameters:
oltp_table_count=25oltp_table_size=10000num-threads=1500
You will see the improved performance as soon as you upgrade to Aurora 1.7.
Upgrading to Aurora 1.7
Newly created DB Instances will run Aurora 1.7 automatically. For exiting DB Instances, you can choose to install the update immediately or during your next maintenance window.
You can confirm that you are running Aurora 1.7 by running the following query:
mysql> show global variables like "aurora_version";
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| aurora_version | 1.7 |
+----------------+-------+
— Jeff;